原文标题:英伟达神操作!剪枝、蒸馏让 Llama 3.1 8B参数减半,同尺寸最强!
原文作者:机器学习算法与Python学习
冷月清谈:
-
结合剪枝和蒸馏技术,英伟达将庞大模型Llama 3.1 8B的参数量减半,创造同尺寸最强语言模型Llama-3.1-Minitron 4B。
-
剪枝去除模型中的冗余成分,蒸馏将大型模型的知识迁移到小模型中,实现高效压缩。
具体过程:
- 根据激活重要性评估模型各个维度(层、神经元、注意力头)的重要性,优先进行宽度剪枝。
- 使用蒸馏损失对剪枝后的模型进行轻度再训练,从小模型逐步剪枝和蒸馏至目标大小。
最佳实践:
- **调整大小:**逐步剪枝和蒸馏,从最大模型开始训练,直至达到目标规模。
- **剪枝:**优先宽度剪枝,使用单次重要性估计。
- **重新训练:**仅用蒸馏损失重新训练,深度无明显减少时采用logit-only蒸馏法。
该研究表明,剪枝和蒸馏相结合是构建小语言模型的高效方法,具有高准确性、数据效率好等优点。
怜星夜思:
2、如何理解文中提到的重要性评估策略在剪枝过程中的作用?
3、英伟达的最佳实践中提到的logit-only蒸馏法在什么时候使用?
原文内容

Llama 3.1 被认为是引领了开源新时代。然而,新一代的模型虽然性能强大,但部署时仍需要大量计算资源。
最近,英伟达研究表明,结构化权重剪枝与知识蒸馏相结合,可以从初始较大的模型中逐步获得较小的语言模型。
图灵奖得主、Meta 首席 AI 科学家 Yann LeCun 也点赞转帖了该研究。
经过剪枝和蒸馏,英伟达研究团队将 Llama 3.1 8B 提炼为 Llama-3.1-Minitron 4B 开源了出来。这是英伟达在 Llama 3.1 开源系列中的第一个作品。
Llama-3.1-Minitron 4B 的表现优于类似大小的最先进的开源模型,包括 Minitron 4B、Phi-2 2.7B、Gemma2 2.6B 和 Qwen2-1.5B。
这项研究的相关论文早在上个月已经放出了。

-
论文链接:https://www.arxiv.org/pdf/2407.14679
-
论文标题:Compact Language Models via Pruning and Knowledge Distillation
剪枝和蒸馏
剪枝使模型变得更小、更精简,可以通过删除层(深度剪枝)或删除神经元和注意力头以及嵌入通道(宽度剪枝)来实现。剪枝通常伴随着一定程度的再训练,以恢复准确率。
模型蒸馏是一种将知识从大型复杂模型(通常称为教师模型)迁移到较小、较简单的学生模型的技术。目标是创建一个更高效的模型,该模型保留了原始较大模型的大部分预测能力,同时运行速度更快且资源消耗更少。
蒸馏方式主要包括两种:SDG 微调与经典知识蒸馏,这两种蒸馏方式互补。本文主要关注经典知识蒸馏方法。
英伟达采用将剪枝与经典知识蒸馏相结合的方式来构造大模型,下图展示了单个模型的剪枝和蒸馏过程(上)以及模型剪枝和蒸馏的链条(下)。具体过程如下:
-
英伟达从 15B 模型开始,评估每个组件(层、神经元、头和嵌入通道)的重要性,然后对模型进行排序和剪枝,使其达到目标大小:8B 模型。
-
接着使用模型蒸馏进行了轻度再训练,原始模型作为老师,剪枝后的模型作为学生。
-
训练结束后,以小模型(8B)为起点,剪枝和蒸馏为更小的 4B 模型。
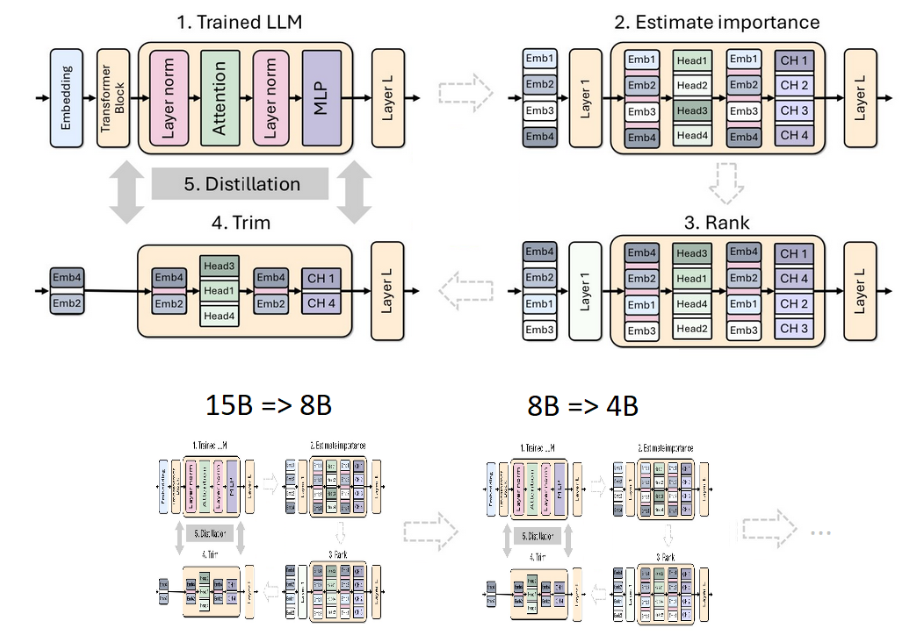
从 15B 模型进行剪枝与蒸馏的过程。
需要注意的点是,在对模型剪枝之前,需要先了解模型的哪部分是重要的。英伟达提出了一种基于激活的纯重要性评估策略,该策略可以同时计算所有相关维度(深度、神经元、头和嵌入通道)的信息,使用一个包含 1024 个样本的小型校准数据集,并且只需要前向传播。这种方法相比依赖梯度信息并需要反向传播的策略更加简单且具有成本效益。
在剪枝过程中,你可以针对给定轴或轴组合在剪枝和重要性估计之间进行迭代交替。实证研究显示,使用单次重要性估计就足够了,迭代估计不会带来额外的好处。
利用经典知识蒸馏进行重新训练
下图 2 展示了蒸馏过程,其中 N 层学生模型(剪枝后的模型)是从 M 层教师模型中(原始未剪枝模型)蒸馏而来。学生模型通过最小化嵌入输出损失、logit 损失以及映射到学生块 S 和教师块 T 的 Transformer 编码器特定损失组合来学习。
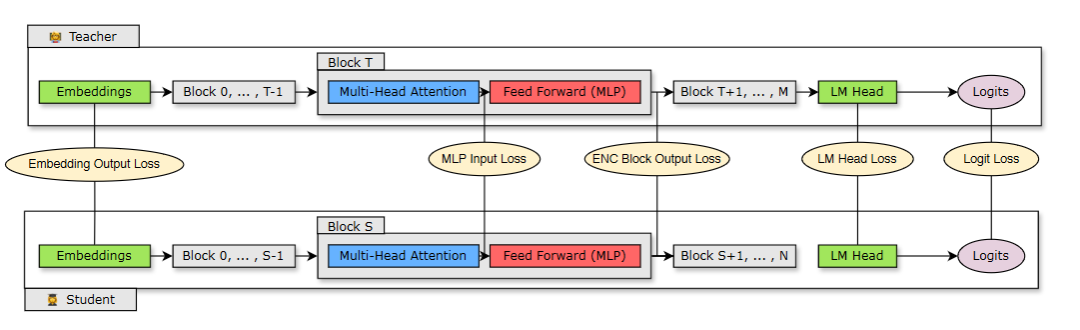
图 2:蒸馏训练损失
剪枝和蒸馏最佳实践
英伟达基于紧凑语言模型中剪枝和知识蒸馏的广泛消融研究,将自己的学习成果总结为以下几种结构化压缩最佳实践。
一是调整大小。
-
要训练一组 LLM,首先训练最大的一个,然后迭代地剪枝和蒸馏以获得较小的 LLM。
-
如果使用多阶段训练策略来训练最大的模型,最好剪枝并对训练最后阶段获得的模型进行重新训练。
-
对最接近目标大小的可用源模型进行剪枝。
二是剪枝。
-
优先考虑宽度剪枝而不是深度剪枝,这对于 15B 参数规模以下的模型效果很好。
-
使用单样本(single-shot)重要性估计,因为迭代重要性估计没有任何好处。
三是重新训练。
-
仅使用蒸馏损失进行重新训练,而不是常规训练。
-
当深度明显减少时,使用 logit、中间状态和嵌入蒸馏。
-
当深度没有明显减少时,使用 logit-only 蒸馏。
结论
剪枝和经典知识提炼是一种非常经济高效的方法,可以逐步获得更小尺寸的 LLM,与在所有领域从头开始训练相比,可实现更高的准确性。与合成数据式微调或从头开始预训练相比,这是一种更有效且数据效率更高的方法。
Llama-3.1-Minitron 4B 是英伟达首次尝试使用最先进的开源 Llama 3.1 系列完成的探索。要在 NVIDIA NeMo 中使用 Llama-3.1 的 SDG 微调,可参阅 GitHub 上的 /sdg-law-title-generation 部分。
往期推荐
商务合作 | 交流学习 | 送书活动
添加vx:yuliang-bj(备注姓名-单位)