原文标题:超越 Transformer 与 Mamba,Meta 联合斯坦福等高校推出最强架构 TTT
原文作者:AI前线
冷月清谈:
摘要:
近期,斯坦福、UCSD、UC伯克利和Meta的研究人员提出了一种全新的序列建模架构TTT,旨在用机器学习模型取代RNN的隐藏状态,以解决自注意力机制复杂度高和RNN在长上下文表现受限的问题。
TTT架构的关键思路是,将隐藏状态本身变成一个机器学习模型,并将其更新规则设为自监督学习的一步。研究人员提出了两种TTT实例:TTT-Linear和TTT-MLP,评估结果显示,与现有的RNN模型Mamba相比,TTT-Linear在困惑度和FLOP上均有优势,并且对长上下文的利用也更好。
总体来看,TTT层在理论和实验评估中均表现出色,在长上下文处理和硬件效率方面具有潜在优势。如果能够解决大规模部署和集成等工程挑战,TTT层有望在工业界得到广泛应用。
怜星夜思:
2、TTT架构在落地应用时可能会遇到哪些挑战?
3、TTT架构的提出对未来序列建模领域发展有何启示?
原文内容

作者 | 赵明华
近日,斯坦福、UCSD、UC 伯克利和 Meta 的研究人员提出了一种全新架构,用机器学习模型取代 RNN 的隐藏状态。

图 1 所有序列建模层都可以表示为一个根据更新规则转换的隐藏状态
这个模型通过对输入 token 进行梯度下降来压缩上下文,这种方法被称为「测试时间训练层(Test-Time-Training layers,TTT)」。该研究作者之一 Karan Dalal 表示,他相信这将根本性地改变语言模型方法。
自注意力机制在处理长上下文时表现良好,但其复杂度是二次的。现有的 RNN 层具有线性复杂度,但其在长上下文中的表现受限于其隐藏状态的表达能力。随着上下文长度的增加,成本也会越来越高。
作者提出了一种具有线性复杂度和表达能力强的隐藏状态的新型序列建模层。关键思路是让隐藏状态本身成为一个机器学习模型,并将更新规则设为自监督学习的一步。
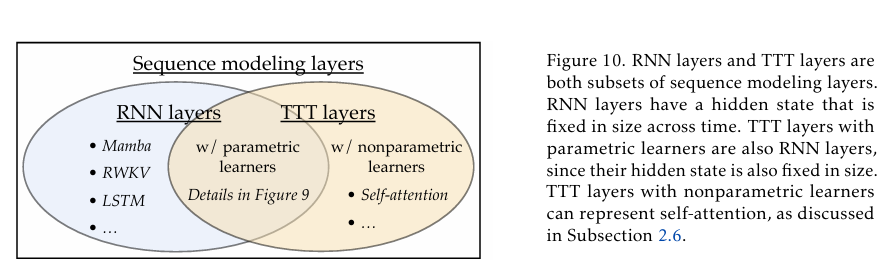
图 2,RNN 层与 TTT 层的关系
论文中提出了两种实例:TTT-Linear 和 TTT-MLP,它们的隐藏状态分别是线性模型和两层 MLP。团队在 125M 到 1.3B 参数规模上评估了实例,并与强大的 Transformer 和现代 RNN Mamba 进行了比较。结果显示,与 Mamba 相比,TTT-Linear 的困惑度更低,FLOP 更少(左),对长上下文的利用更好(右):
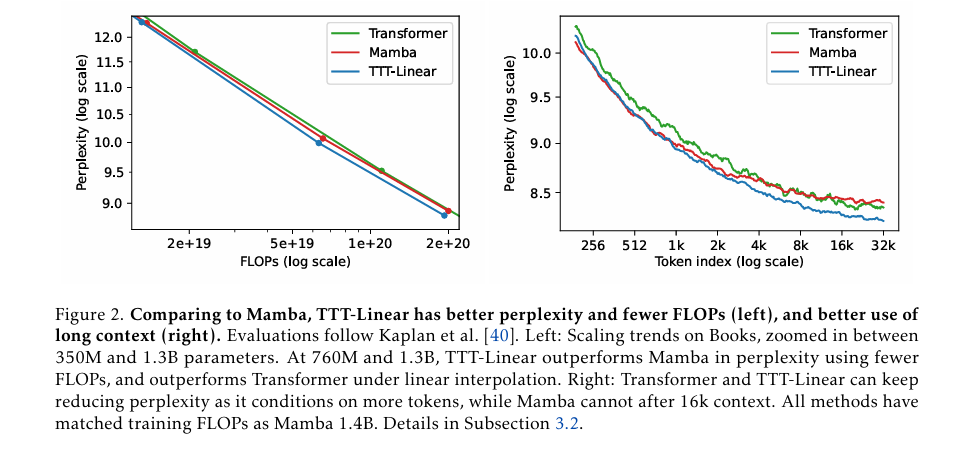
图 3 TTT-Linear 与 Mamba 对比
这个结果代表了现有 RNN 的尴尬现实。一方面,RNN(与 Transformer 相比)的主要优点是其线性(与二次型)复杂性。这种渐近优势只有在长上下文的实践中才能实现,根据下图,这个长度是 8k。另一方面,一旦上下文足够长,现有的 RNN(如 Mamba)就很难真正利用所依赖的额外信息。

图 4 TT Linear 在 8k 环境下已经比 Transformer 更快
并且,大量的实验结果表明:TTT-Linear 和 TTT-MLP 都匹配或超过基线。与 Transformer 类似,它们可以通过限制更多的代币来不断减少困惑,而 Mamba 在 16k 上下文后则不能。经过初步的系统优化,TTT Linear 在 8k 环境下已经比 Transformer 更快,并且在 wall-clock 时间上与 Mamba 相匹配。
TTT 层在理论上和实验评估中表现出色,尤其是在长上下文处理和硬件效率方面。如果在实际应用中能够解决一些潜在的工程挑战,如大规模部署和集成问题,工业界对 TTT 层的接受度也将逐步提升。
论文链接:https://arxiv.org/pdf/2407.04620v1

在主题演讲环节,我们已经邀请到了「蔚来创始人 李斌」,分享基于蔚来汽车 10 年来创新创业过程中的思考和实践,聚焦 SmartEV 和 AI 结合的关键问题和解决之道。大会火热报名中,7 月 31 日前可以享受 9 折优惠,单张门票节省 480 元(原价 4800 元),详情可联系票务经理 13269078023 咨询。

今日荐文
