原文标题:字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果
原文作者:机器之心
冷月清谈:
为了提升视觉语言模型(VLM)中图像和文本模态间的对齐效果,来自武汉大学、字节跳动和中国科学院大学的研究人员提出了 CAL(Contrastive Alignment of Language)。CAL 是一种基于对比学习的文本 token 筛选方法,可以从文本中筛选出与图像高度相关的 token,并在训练过程中加大这些 token 的损失函数权重,从而实现更精准的多模态对齐。CAL 的优势在于:
- 无需额外的预训练阶段,可以直接嵌套到 VLM 训练过程中。
- 在 OCR 和 Caption 等基准测试上取得了显著提升,可视化结果表明 CAL 提高了图像模态对齐的质量。
- 增强了模型对噪声数据的抵抗能力。
CAL 的工作原理:
- 通过 condition contrastive 的方式,计算在有无图像输入的情况下每个文本 token 的 logit 变化量,衡量图像对 token 的影响程度。
- logit 变化量大的 token 被视为与图像高度相关,在训练中赋予更大的权重,促使模型关注这些 token,进而提升模态对齐效果。
实验结果显示,CAL 在 LLaVA 和 MGM 等不同规模的 VLM 模型上均取得了性能提升,并在抗噪性、注意力分布和图像 token 映射等方面表现出优势。
怜星夜思:
1、CAL 方法在实际应用中有哪些潜在挑战?
2、除了视觉相关 token,还有哪些其他因素可能影响 VLM 中的多模态对齐效果?
3、除了 CAL 方法之外,还有什么其他方法可以增强 VLM 中的多模态对齐效果?
2、除了视觉相关 token,还有哪些其他因素可能影响 VLM 中的多模态对齐效果?
3、除了 CAL 方法之外,还有什么其他方法可以增强 VLM 中的多模态对齐效果?
原文内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。
在这个过程中,模态的对齐是通过文本 token 隐式实现的,如何做好这一步的对齐非常关键。
针对这一问题,武汉大学、字节跳动豆包大模型团队和中国科学院大学的研究人员提出了一种基于对比学习的文本 token 筛选方法(CAL),从文本中筛选出与图像高度相关的 token,并加大其损失函数权重,从而实现更精准的多模态对齐。

-
论文链接:https://arxiv.org/pdf/2405.17871
-
代码链接:https://github.com/foundation-multimodal-models/CAL
CAL 有以下几个亮点:
-
可以直接嵌套到训练过程,无需额外预训练阶段。
-
在 OCR 和 Caption benchmarks 上获得了明显的提升,从可视化中可以发现 CAL 使得图片模态对齐效果更好。
-
CAL 使得训练过程对噪声数据抵抗能力更强。
研究动机
目前视觉语言模型依赖于图片模态的对齐,如何做好对齐非常关键。目前主流的方法是通过文本自回归的方式进行隐式对齐,但是每个文本 token 对图像对齐的贡献是不一致的,对这些文本 token 进行区分是非常有必要的。
CAL 提出,在现有的视觉语言模型(VLM)训练数据中,文本 token 可以被分为三类:
-
与图片高度相关的文本:如实体(例如人、动物、物体)、数量、颜色、文字等。这些 token 与图像信息直接对应,对多模态对齐至关重要。
-
与图片低相关度的文本:如承接词或可以通过前文推断出的内容。这些 token 实际上主要是在训练 VLM 的纯文本能力。
-
与图片内容相悖的文本:这些 token 与图像信息不一致,甚至可能提供误导信息,对多模态对齐过程产生负面影响。

图一:绿色标记为与图片高度相关 token,红色为内容相悖,无色为中性 token
在训练过程中,后两类 token 整体而言实际上占据了较大比例,但由于它们并不强依赖于图片,对图片的模态对齐作用不大。因此,为了实现更好的对齐,需要加大第一类文本 token,即与图片高度相关部分 token 的权重。如何找出这一部分 token 成为了解决这个问题的关键所在。
方法
找出与图片高度相关 token 这个问题可以通过 condition contrastive 的方式来解决。
-
对于训练数据中的每个图文对,在没有图片输入的情况下,每个文本 token 上的 logit 代表着 LLM 基于上下文情况和已有知识对这种情况出现的估计值。
-
如果在前面添加图片输入,相当于提供额外的上下文信息,这种情况下每个 text token 的 logit 会基于新的情况进行调整。这两种情况的 logit 变化量代表着图片这个新的条件对每个文本 token 的影响大小。
具体来说,在训练过程中,CAL 将图文序列和单独的文本序列分别输入到大语言模型(LLM)中,得到每个文本 token 的 logit。通过计算这两种情况下的 logit 差值,可以衡量图片对每个 token 的影响程度。logit 差值越大,说明图片对该 token 的影响越大,因此该 token 与图像越相关。下图展示了文本 token 的 logit diff 和 CAL 方法的流程图。
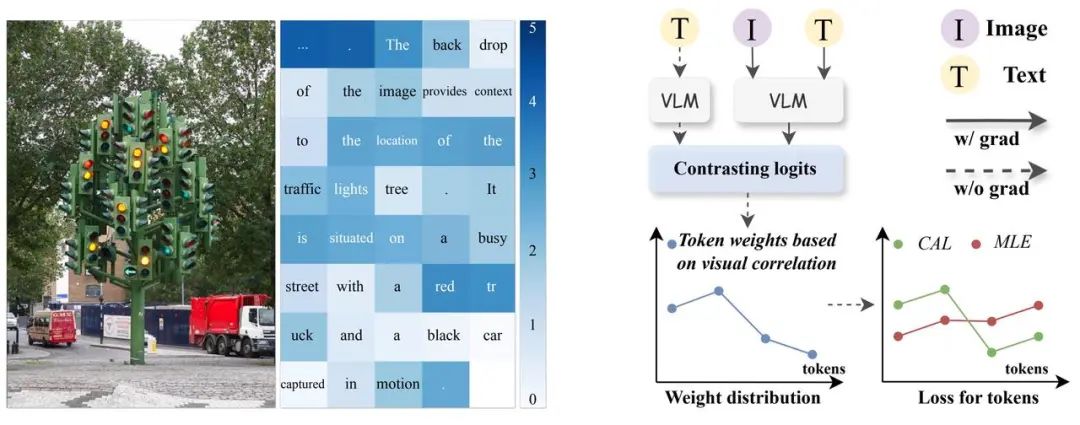
图二:左图是对两种情形下 token logit diff 的可视化,右图是 CAL 方法流程的可视化
实验
CAL 在 LLaVA 和 MGM 两个主流模型上进行了实验验证,在不同规模的模型下均实现了性能提升。
包含以下四个部分的验证:
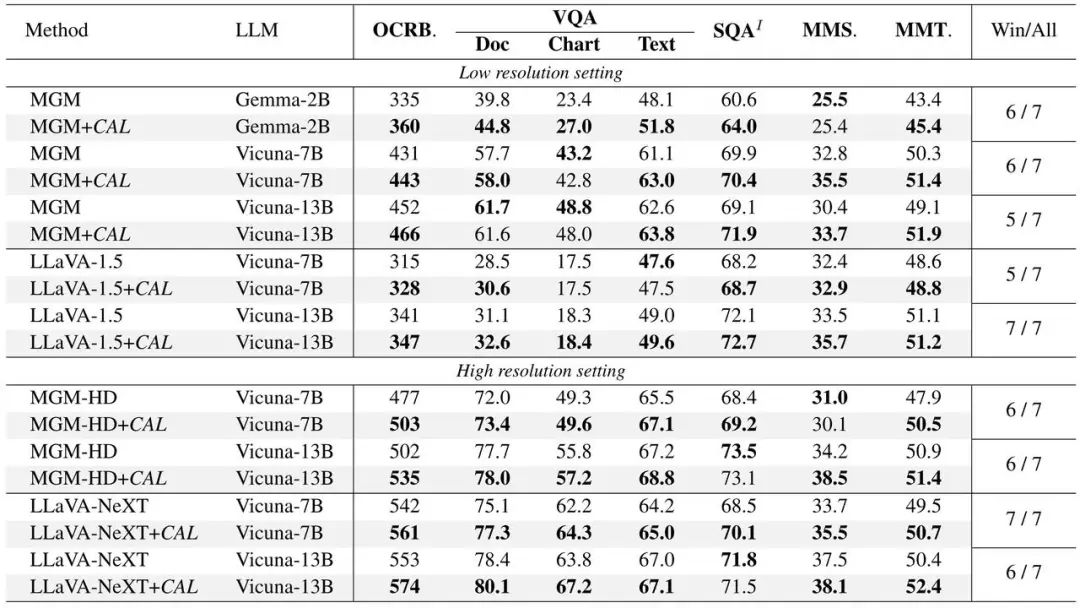
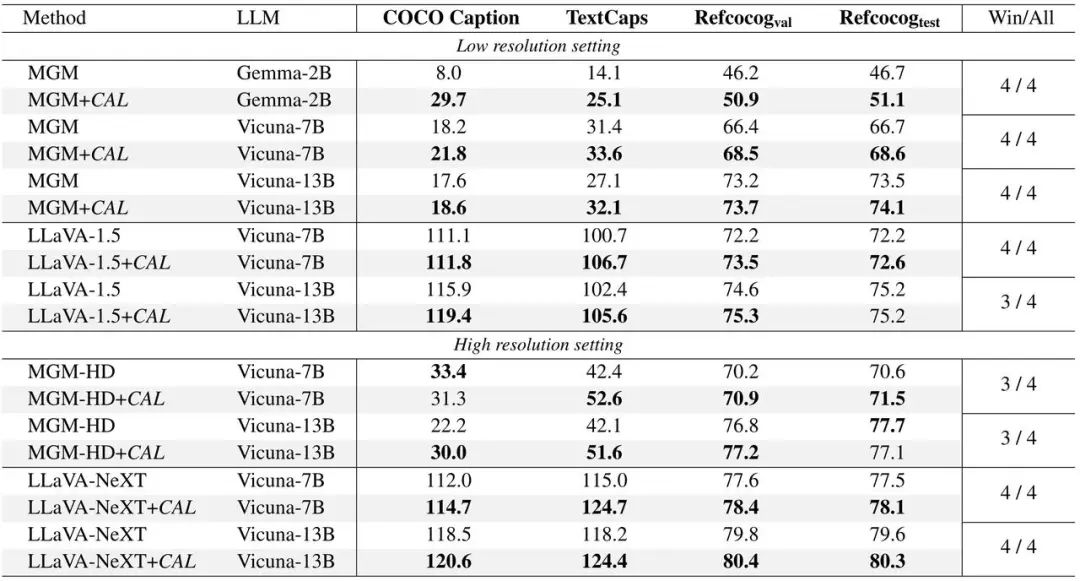
(1)使用 CAL 的模型在各项基准测试指标上表现更佳。
(2) 通过按比例随机交换两个图文对中的文本来制造一批噪声数据(图文错配),并用于模型训练,CAL 使得训练过程具有更强的数据抗噪性能。
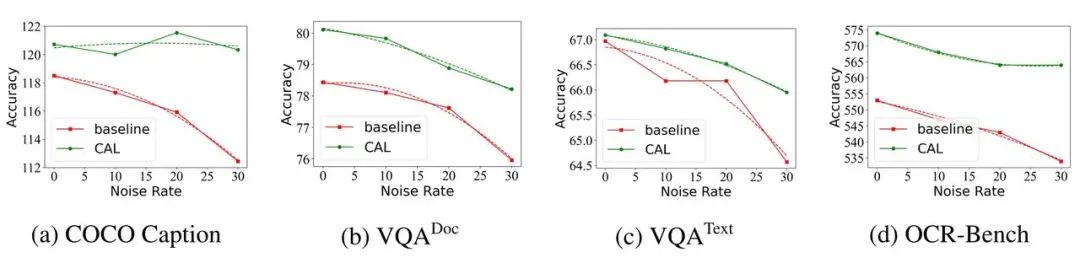
图三:在不同强度训练噪声情况下,CAL 与基线的性能表现
(3)对 QA case 中的答案部分计算其与图片 token 的注意力分数分布,并将其绘制在原图上,CAL 训练的模型拥有更清晰的注意力分布图。

图四:基线与 CAL 的 attention map 可视化,每对中的右边为 CAL
(4)将每个图片 token 映射为它最相似 LLM 词表中的文本 token,将其绘制到原图上,CAL 训练的模型映射内容更接近图片内容。

图五:将 image token 映射为最相似词表 token,并对应到原图上
团队介绍:
字节跳动豆包大模型团队成立于 2023 年,致力于开发业界最先进的 AI 大模型技术,成为世界一流的研究团队,为科技和社会发展作出贡献。
豆包大模型团队在 AI 领域拥有长期愿景与决心,研究方向涵盖 NLP、CV、语音等,在中国、新加坡、美国等地设有实验室和研究岗位。团队依托平台充足的数据、计算等资源,在相关领域持续投入,已推出自研通用大模型,提供多模态能力,下游支持豆包、扣子、即梦等 50 + 业务,并通过火山引擎开放给企业客户。目前,豆包 APP 已成为中国市场用户量最大的 AIGC 应用。欢迎加入字节跳动豆包大模型团队。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com