μ₀ 用 3D 交互轨迹替代像素预测,探索机器人可复用的“物理语言”。
原文标题:机器人不该只在像素里做梦:μ?和我们想找的「物理语言」
原文作者:机器之心
冷月清谈:
怜星夜思:
2、像素级 world model 和结构化 world model,哪条路线更可能跑出通用机器人?
3、μ₀ 不用 action labels 预训练,这对普通实验室和开源机器人研究意味着什么?
4、可解释性在机器人 world model 里到底有多重要?只要成功率高,是不是黑盒也可以接受?
原文内容

最近具身智能很热,world model 也很热。热到什么程度呢?热到大家一说机器人要有 world model,第一反应往往就是:那我们是不是要训练一个更大的视频预测模型,让机器人在 pixel space 里面 “做梦”?
这个直觉确实有道理。毕竟互联网最不缺的就是视频。人类开门、倒水、切菜、叠衣服、拧瓶盖、用工具,什么都有。如果语言模型可以从全网文本中学到知识,那机器人是不是也可以从全网视频中学到物理世界?
这个愿景很美。但我们一直有一个挥之不去的疑问:机器人真的应该在像素里学习物理吗?
像素当然是最直接的数据形式。视频打开就是 pixels,数据量巨大,天然 scalable。但问题也在这里:pixels 太低层了。一个机器人真正关心的,不是桌布上那朵花的纹理,也不是背景里某个椅子的颜色,更不是摄像机轻微抖动后每个像素应该怎么变。机器人关心的是:物体怎么动?哪里发生了接触?工具和目标之间的关系怎么变化?手推了哪里?杯子为什么倒了?门把手到底是旋转还是平移?

如果我们训练一个 pixel-space world model,让它预测未来画面,它可能花了很多力气学会了光照、纹理、背景和相机运动。很厉害,很贵,也很可能不是机器人最需要的东西。
这就带来一个很朴素、甚至有点 “不讲武德” 的问题:如果要训练一个真正适合 robotics 的 pixel world model,本身就需要大量 robotics data;那如果已经有这么多 robotics data,为什么不直接训练 policy?world model 不是应该帮助我们解决 action-labeled robotics data 不 scalable 的问题吗?怎么绕了一圈,又回到了 “请给我更多机器人数据”?
这就是一个鸡生蛋、蛋生鸡问题。机器人学界已经有很多鸡和蛋了,真的不缺这一枚。
另一条路线是 latent world model。这个方向看起来更优雅:不要预测每个像素,把世界压到一个 compact latent space 里,再预测 latent dynamics。听起来很合理。我也承认,latent representation 是机器学习里非常强大的工具。
但我们对纯黑盒 latent space 一直保持一点职业性怀疑。这个怀疑不是凭空来的。做 spectral methods、representation learning、latent variable models 很多年,一个反复被教育的经验是:latent space 在 paper 里常常很漂亮,在 benchmark 上也常常很能打,但一旦你想解释它、干预它、纠正它,它就开始露出脾气。
有时候 latent space 像一个很聪明但不愿意解释作业过程的小孩。答案可能对,但你不知道它为什么对;错了你也不知道从哪里改。更糟糕的是,它还可能 collapse。机器人系统偏偏又不是写诗,它需要和真实世界发生接触,需要可靠、可控、可纠错。一个 “我也不知道里面发生了什么,但 loss 降了” 的 world model,对机器人来说有点危险。
所以作者们在 μ₀ 里问了一个问题:有没有一种表示,既不像 pixels 那么低层、昂贵、冗余,又不像黑盒 latent 那么不可解释、难干预?
μ₀ 的答案是:3D interaction traces。
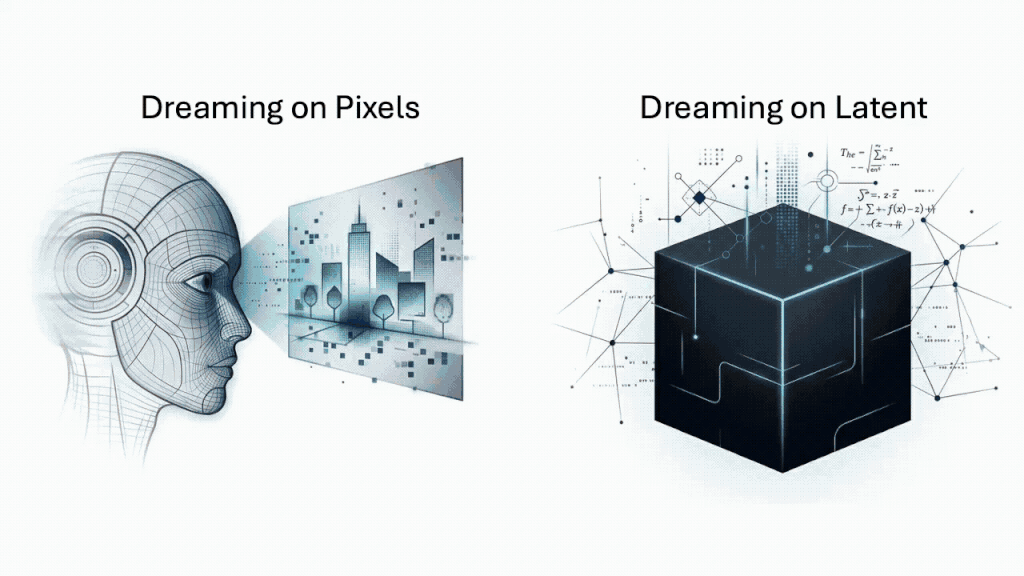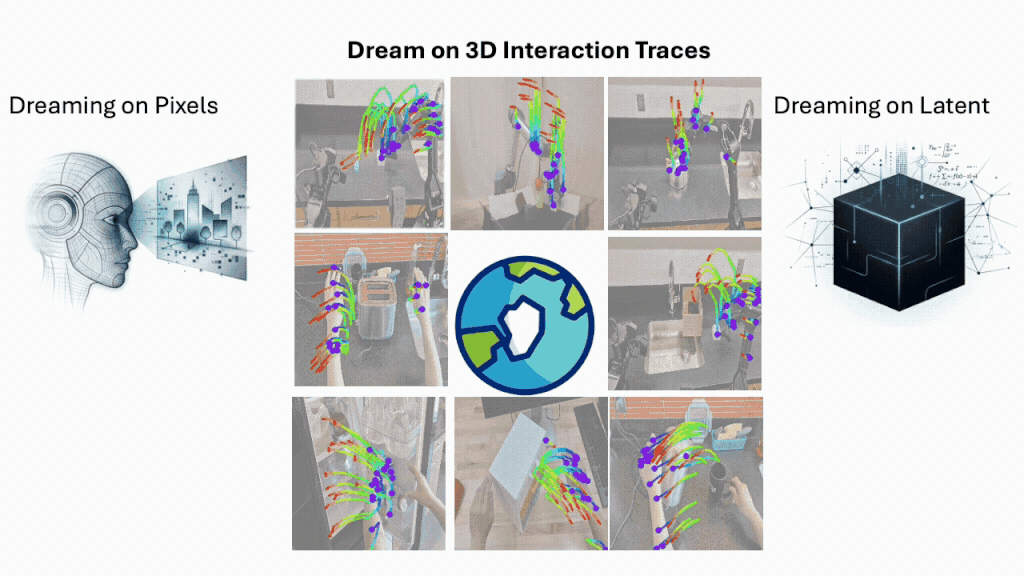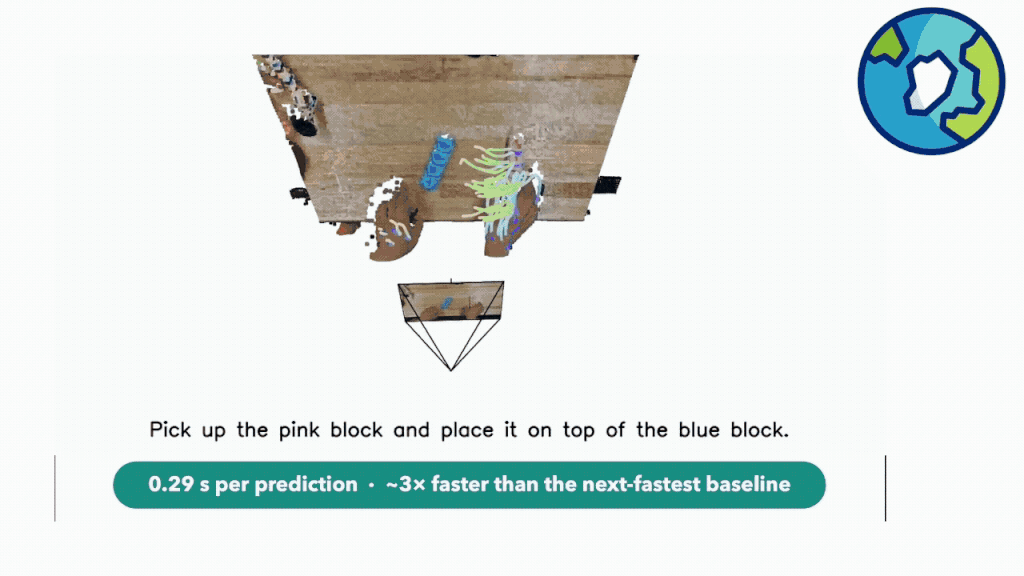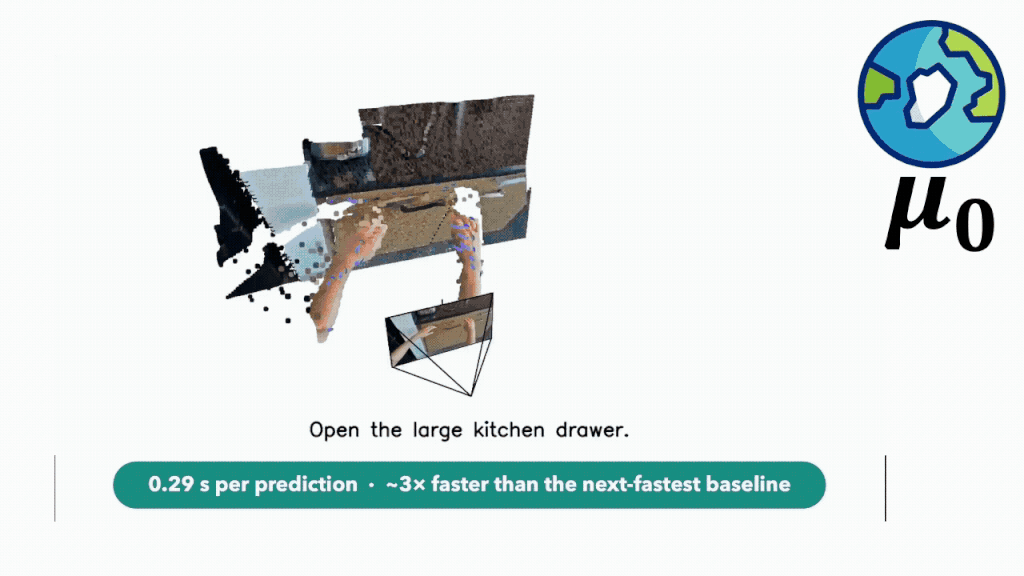
μ₀ 不是一个 pixel world model,也不是一个纯 latent world model。它是一个 symbolic /structured world model,预测的是物理交互中的三维运动轨迹。
更具体一点,μ₀ 预测的是少量语义交互点的运动:物体部件、工具、手、接触区域。这些点怎么动,往哪里动,如何随时间变化。我们把它们叫做 3D interaction traces。

这个表示很 “小”。它不需要生成整张未来图像,不需要把背景、纹理、光照都复原出来。但它又不是一个完全黑盒的 latent。每一条 trace 都对应真实世界中某个有意义的东西:一个物体边缘,一个工具端点,一个手指附近的接触区域,一个正在被推动的部件。
这就是 μ₀的可爱之处:compact enough to scale, structured enough to interpret。
如果说得更 “宏大” 一点,μ₀ 作者们认为机器人需要自己的符号空间。
LLM 为什么能 scale?一个很重要的原因是人类已经替它发明好了 words。文字是一个统一空间。我们用文字记录、压缩、交换、复用知识。几千年文明活动,最后都可以被搬进一个 shared token space:书、论文、网页、代码、聊天记录。LLM 站在这个人类文明的 “便宜大碗数据格式” 上训练,当然很幸福。
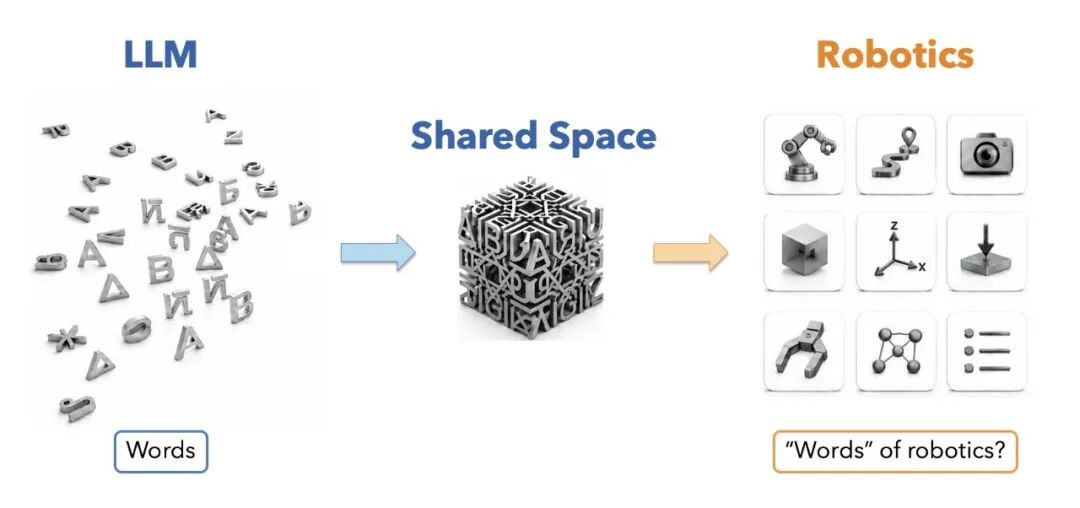
机器人就没这么幸运。机器人世界太 heterogeneous 了。不同 embodiment,不同 action space,不同传感器,不同工具,不同任务,不同环境。一个 Franka 的 action label,并不会自动变成灵巧手的 action label;人类手部视频,也不会天然变成机器人可执行的 joint command。
所以对 robotics 来说,真正的问题可能不是 “我们要不要 world model”,而是:什么是 robotics 的 words?什么样的 symbol space 可以让机器人跨 embodiment、跨场景、跨任务复用物理知识?
μ₀ 给出的第一个探索性答案是:motion traces 可能是一种物理语言。
不是语言意义上的 language,而是物理交互意义上的 language。它描述的不是 “这个物体叫什么”,而是 “它在交互中如何运动”。它把人类视频和机器人视频中共同的部分抽出来:不是谁的手、谁的关节、谁的 motor command,而是物体、工具、接触点的三维运动结构。
为了学这个表示,μ₀ 的作者做了个数据引擎 TraceExtract。简单说,它把普通视频转成 trace supervision。先找 “什么在动”,再估 “它在哪里动”,最后分解 “它怎么动”。这个过程让我们可以从 video-only data 中学习 physical interaction,而不是一上来就依赖昂贵的机器人 action labels。
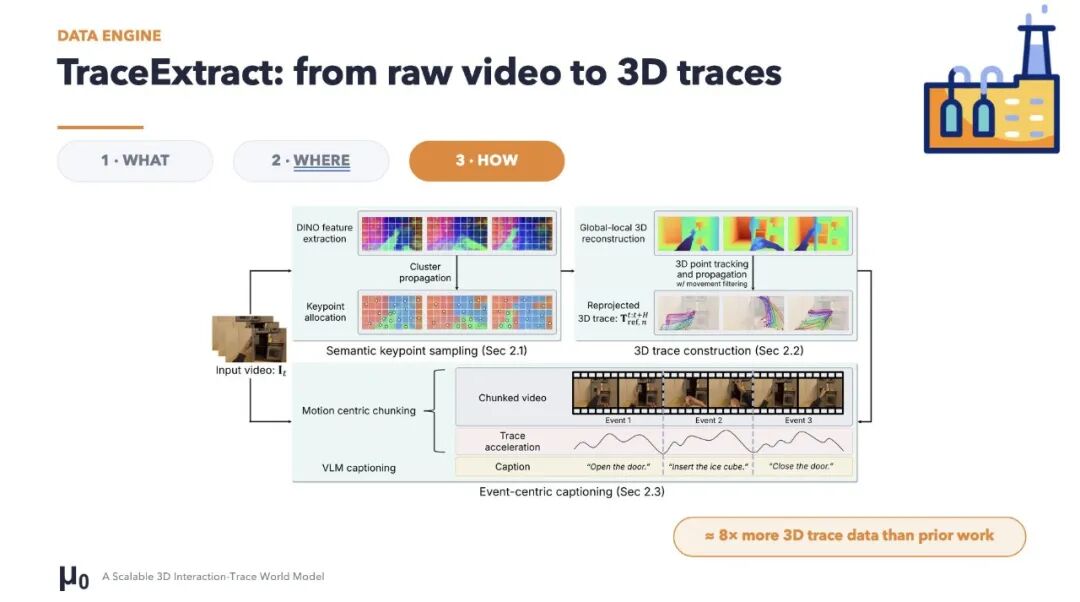
这对 academic lab 很重要:没有工业级 compute,没有内部私有大数据资产,没有一屋子的机器人昼夜不停采数据。有的只是开源数据、学校 compute cluster、学生的毅力,以及导师偶尔半夜发 Slack 的热情。听起来不豪华,但也正因为如此,academic lab 必须认真思考什么样的 representation 才是真的高效。
这也是 μ₀ 有意思的地方。它不是靠 “我比你更大” 来讲故事。μ₀ 的预训练数据大约是 200K episodes、13M frames、15.7TB。听起来不少,对一个 academic cluster 来说也确实不少 —— 有些 job 跑起来的时候,我都觉得 cluster 风扇声里带着一点控诉。但和工业级 VLA 模型的数据规模相比,这远不是一个 “大力出奇迹” 的设置。
μ₀ 的策略是:让已有 vision-language backbone 保留语义知识,让单独的 trace expert 学物理运动。也就是说,语义和 dynamics 不要混在一起煮成一锅 latent 粥。语义交给 pretrained foundation model,运动交给 trace-space world model。
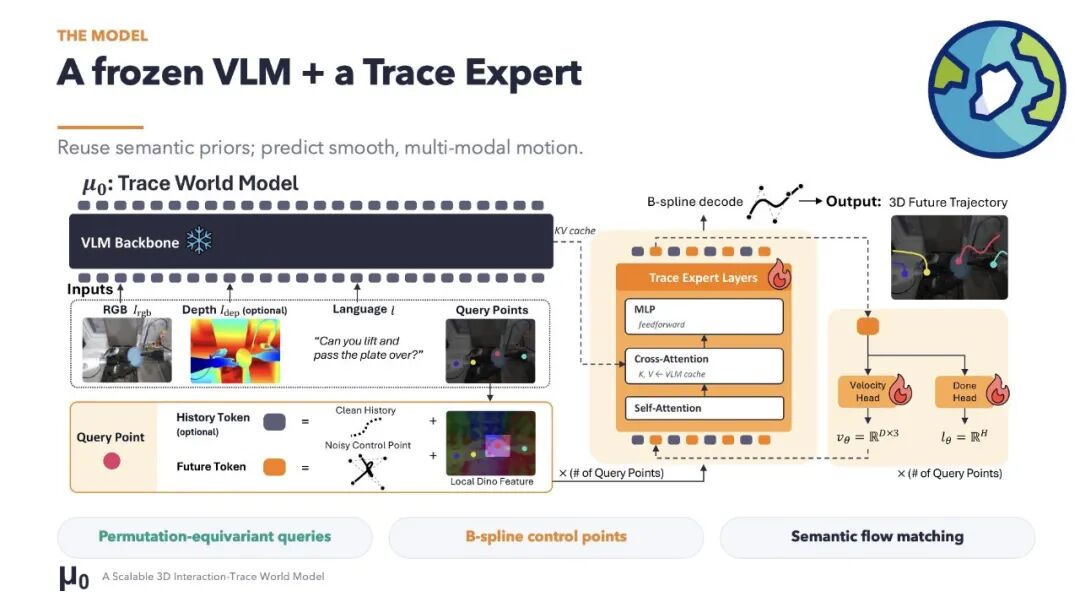
更关键的是,μ₀ 的 world model 预训练阶段不需要 action labels。之后把 μ₀ freeze,只在上面训练一个很轻量的 action expert,把 trace features 转换成机器人动作。这个设计其实很朴素:如果 trace-space world model 真的学到了可复用的物理运动先验,那么下游机器人控制应该能用得上它,而不只是看起来像个漂亮的预测任务。
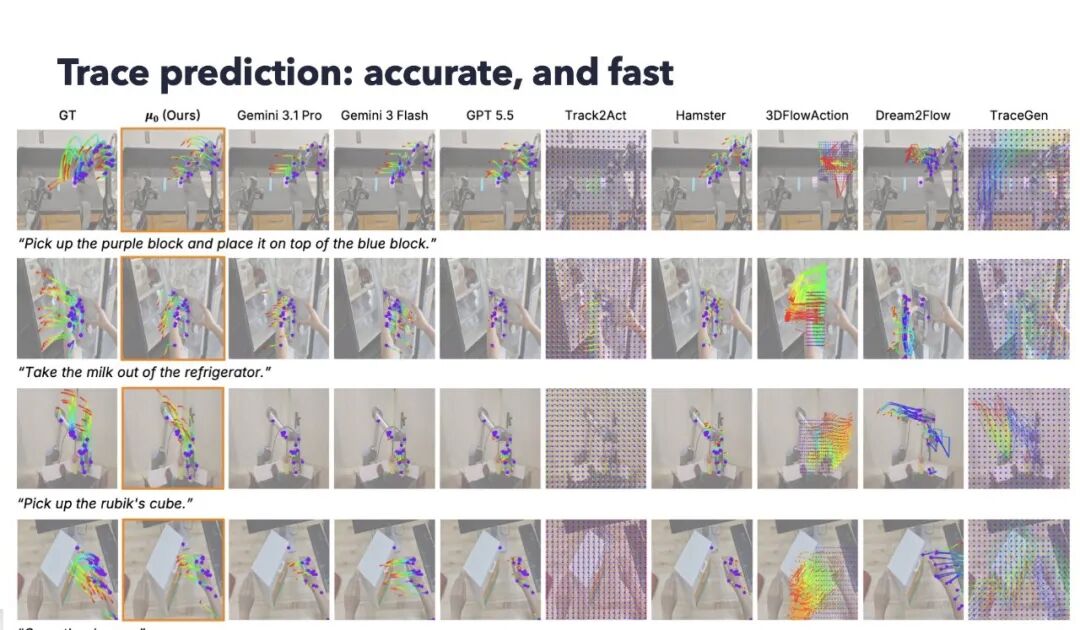
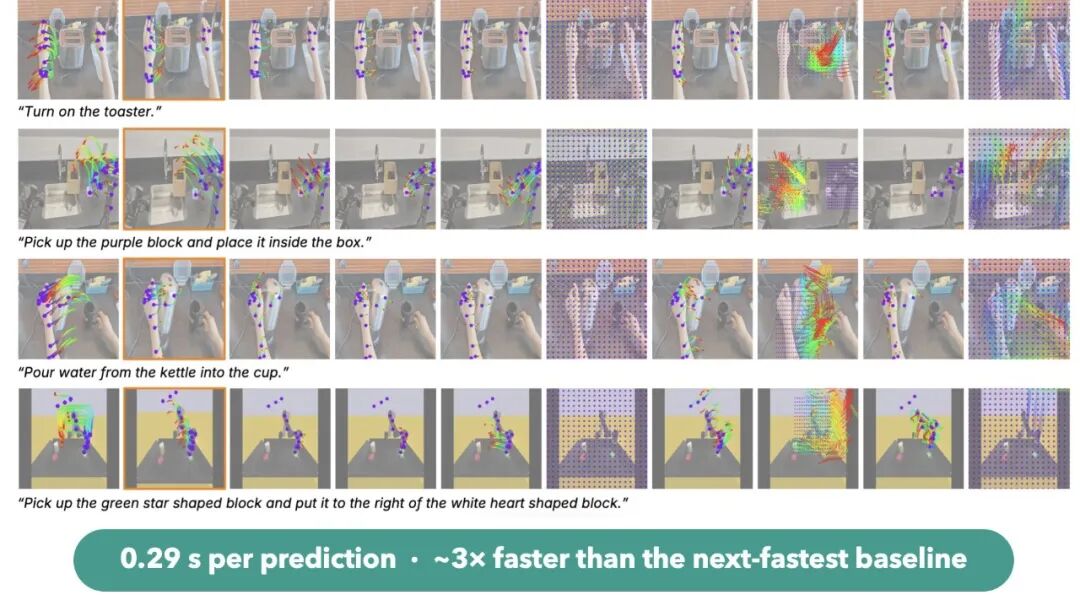
实验结果让人很兴奋。在 trace forecasting 上,μ₀ 在多个指标和预测 horizon 上表现很好,也比一些强 API 模型更擅长这个具体的物理预测问题。它的推理速度也很快,单次预测大约 0.29 秒。
更重要的是,在仿真和真实机器人实验中,冻结 μ₀ 后接一个轻量 action expert,仍然能达到和强 VLA policy 相当的机器人表现;在真实机器人评测里,μ₀ + action expert 的平均成功率超过了 π₀.₅。
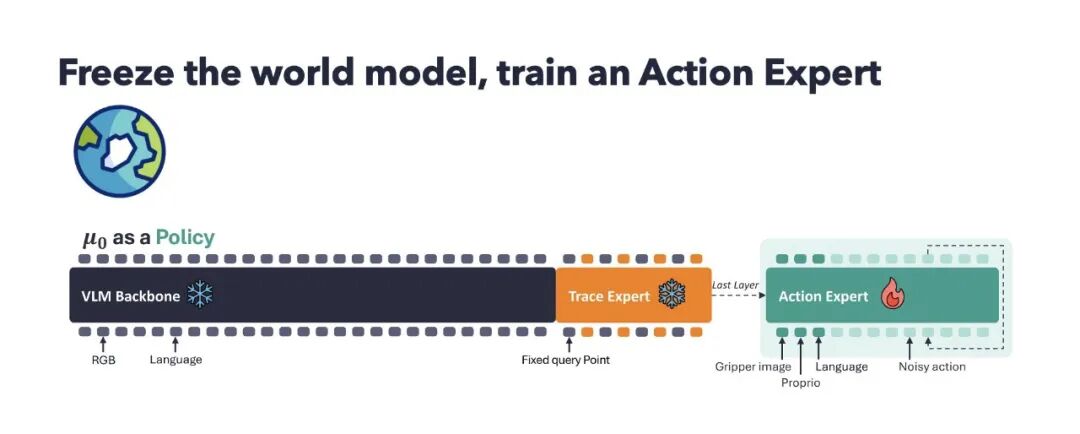
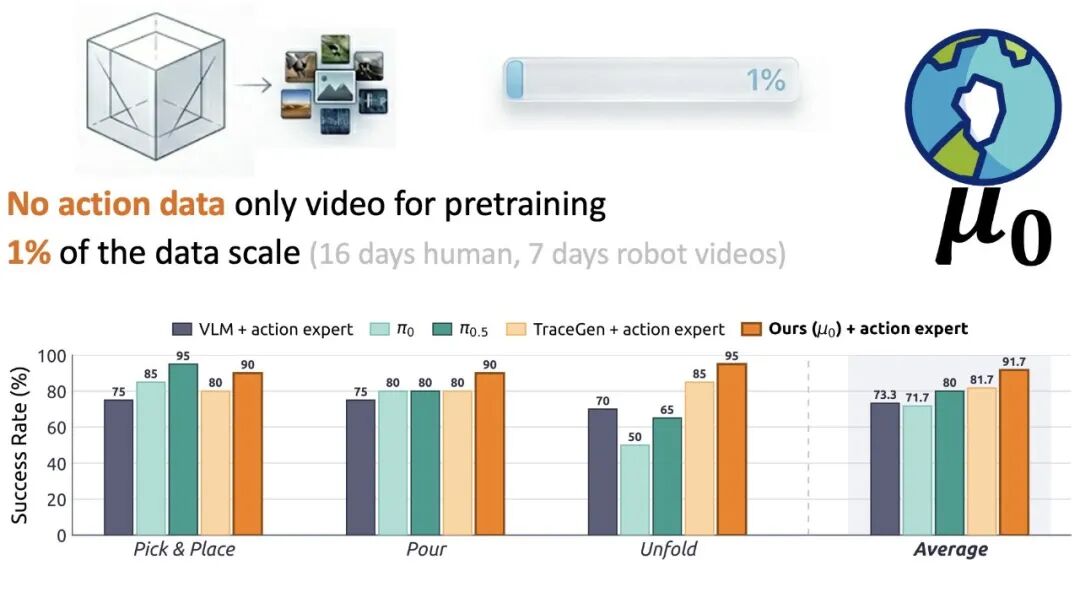
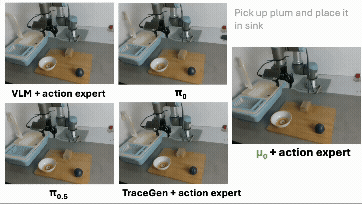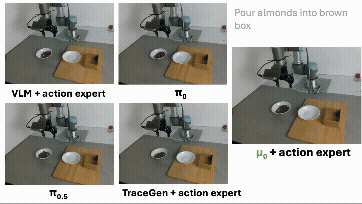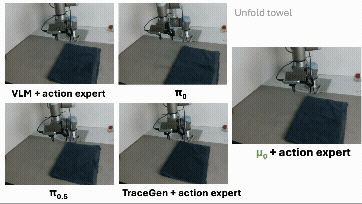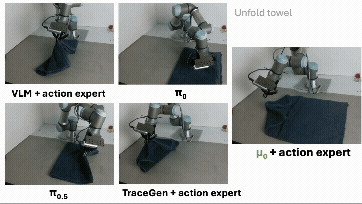
这里最重要的不是 “做出了一个最终 robot policy”。没有。μ₀ 还不是终点,也远远不是一个完整机器人系统的全部答案。更重要的是:trace-space prediction 学到的东西,确实能被机器人控制复用。
这件事如果成立,就说明 world model 的价值不一定在于生成更逼真的视频。机器人不一定需要在像素里做更高清的梦。它可能更需要一种可迁移、可解释、可干预的物理表示。
当然,3D interaction traces 也不是唯一可能的物理语言。它只是第一步。未来还能继续加入更多 physical priors:contact graphs、force/torque traces、tactile fields、object-centric affordance graphs、constraints、energy landscapes…… 这些东西听起来不像 pixels 那么 “万能”,但可能更接近机器人真正需要理解的世界。
具身智能的 scaling 不会只是 “更多数据、更大模型、更长训练”。当然,我们也想 scale data,而且非常想。只是作为一个没有无限 compute 的 academic lab,甚至本着对资源使用负责的态度的 frontier lab, 可能更需要问:在 scaling 之前,表示空间选对了吗?如果 symbol space 选错了,scale 得越大,可能只是越快地把资源烧到错误方向上。
这也是 μ₀ 想表达的一个小小立场:
机器人学习不该只是在 pixels 里复刻视频世界,也不该把物理交互全部塞进不可解释的 latent。我们需要寻找 robotics 自己的 symbol space。

LLM 有 words。
Robots 也许需要 traces。
μ₀ 是我们朝这个方向迈出的一步。不是最后一步,但至少这一步,让我觉得我们离 robotics 的 GPT-3.5 moment,好像又近了一点点。
项目页:https://mu0-wm.github.io/
作者简介
Furong Huang,马里兰大学计算机科学系副教授,研究方向包括机器学习、具身智能、机器人学习、表示学习与高效大模型。她长期关注如何在有限数据与计算资源下构建可扩展、可解释、可迁移的智能系统。近期工作 μ₀ 探索以 3D interaction traces 作为机器人世界模型的符号空间。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com