OpenAI 限量预览 GPT-5.6,三档模型主打编程、安全与生物任务,同时引发监管争议。
原文标题:GPT-5.6突然上线:比Mythos强,普通用户彻底无缘
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Sol 的 ultra 模式通过多个子 Agent 协作处理任务,这会不会让 AI 更像一个“小团队”而不是单个助手?
3、GPT-5.6 在网络安全任务上变强,是更有利于防御方,还是反而会拉高攻击风险?
4、OpenAI 公开表示不希望政府审查成为长期惯例,这种态度是在维护创新速度,还是在回避监管责任?
原文内容
GPT-5.6,猝不及防地来了。
周五,OpenAI 发布了这一新系列的限量预览版,涵盖三款定位各异的模型:旗舰级的 Sol、面向高频日常工作的 Terra,以及主打性价比的 Luna。
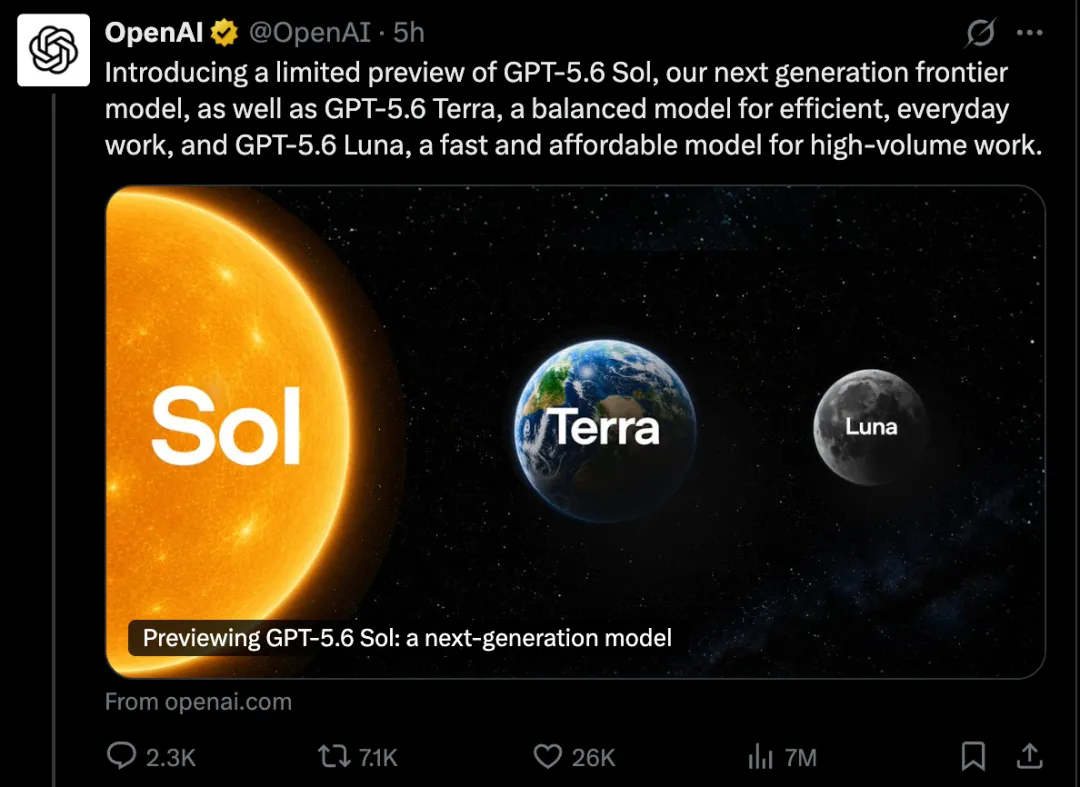
OpenAI 表示,该系列在编程、网络安全和生物学领域表现尤为突出,同时在需要持续专注的长链式智能体任务中也展现出更强的稳定性。
此次发布恰在美国政府介入 AI 监管话题引发广泛关注后不到 24 小时,背景之复杂,使这次产品发布远不止于一次常规的技术迭代。
这三档产品,覆盖不同需求层次。
在能力定位上,Sol 是三款中综合实力最强的,具备最深度的推理能力,并新增了两种增强模式:
-
面向复杂任务的「max」模式可让模型投入更多时间进行深度推理。
-
「ultra」模式则通过调度多个子 Agent 协同工作,以应对超出单一 Agent 处理上限的复杂任务。
Terra 的综合性能与上一代 GPT-5.5 相当,但价格降至 Sol 的一半;Luna 则定位于轻量高速场景,成本进一步压缩。
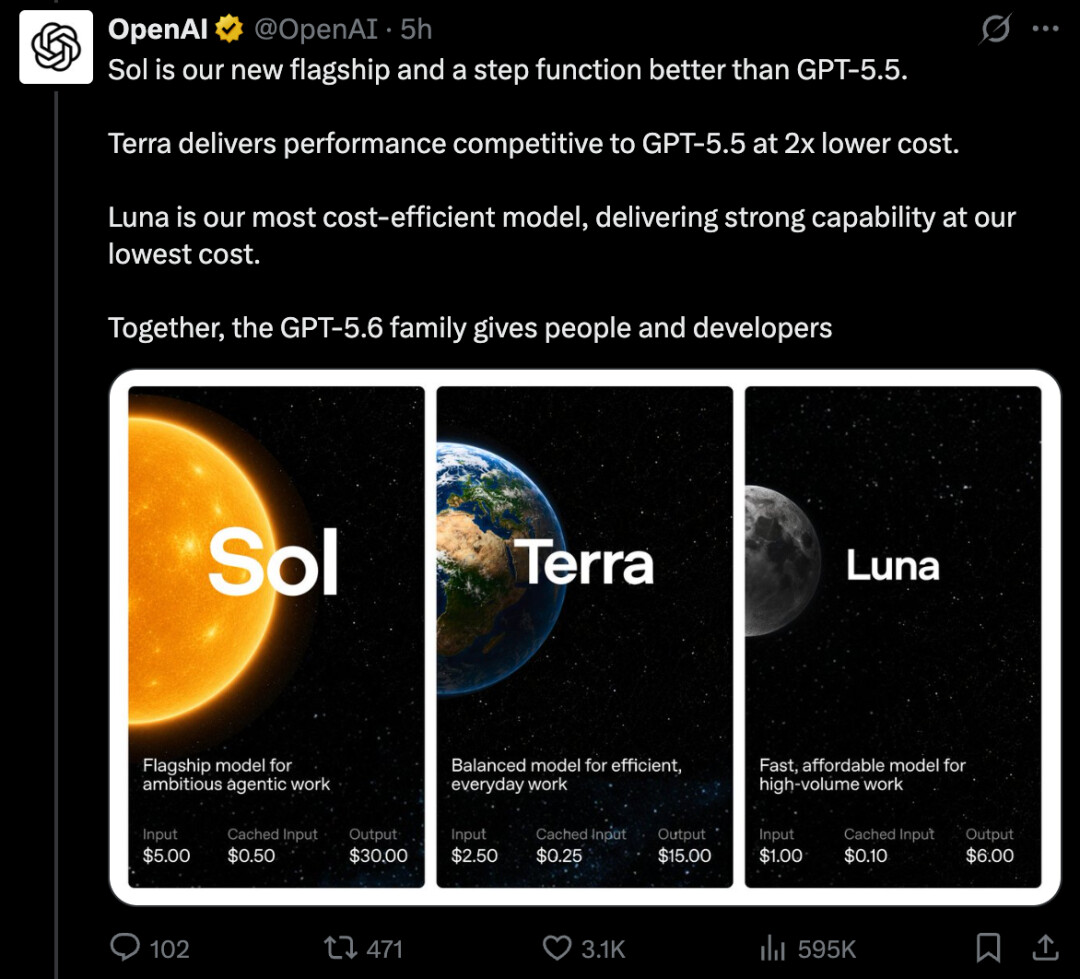
定价方面,Sol 按每百万 token 计费,输入 5 美元、输出 30 美元,约为 Anthropic Claude Fable 5 对应价格的一半。Terra 的输入输出分别为 2.5 美元和 15 美元,Luna 则低至 1 美元输入、6 美元输出。
OpenAI 还对 GPT-5.6 引入了更灵活的提示缓存机制,支持自定义缓存断点,最低缓存有效期为 30 分钟,缓存写入按未缓存输入价格的 1.25 倍计费,缓存读取维持九折优惠。
有网友对比了 GPT-5.6 Sol 和 Anthropic 的 Mythos 级模型。
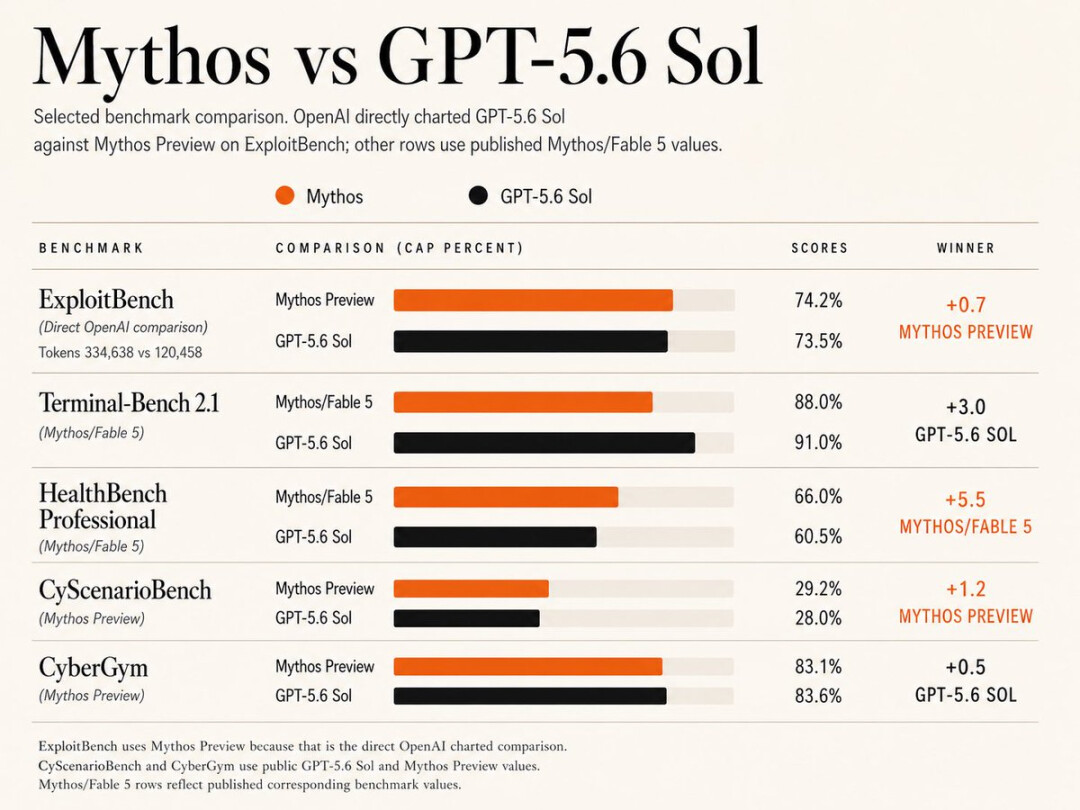
他认为互有胜负,在当前基准上大约一半左右打平或小胜,但整体还没达到 Fable 的全面水平。
此外,OpenAI 宣布将于 7 月在 Cerebras 硬件上部署 Sol,推理速度可达每秒 750 个 token,初期面向特定客户开放。
能力表现
GPT-5.6 Sol 是 OpenAI 迄今最强的模型。为了展示模型性能,OpenAI 公布了一组评测结果,重点体现其在编程、生物学和网络安全等方向上更强的 Agent 能力。
在 GPT-5.6 中,OpenAI 引入了新的最高推理强度,让 Sol 能够获得更多时间进行深度推理。此外,他们还推出了新的 ultra mode,它通过调用子 Agent 来加速复杂任务,能力超出了单个 Agent 的边界。
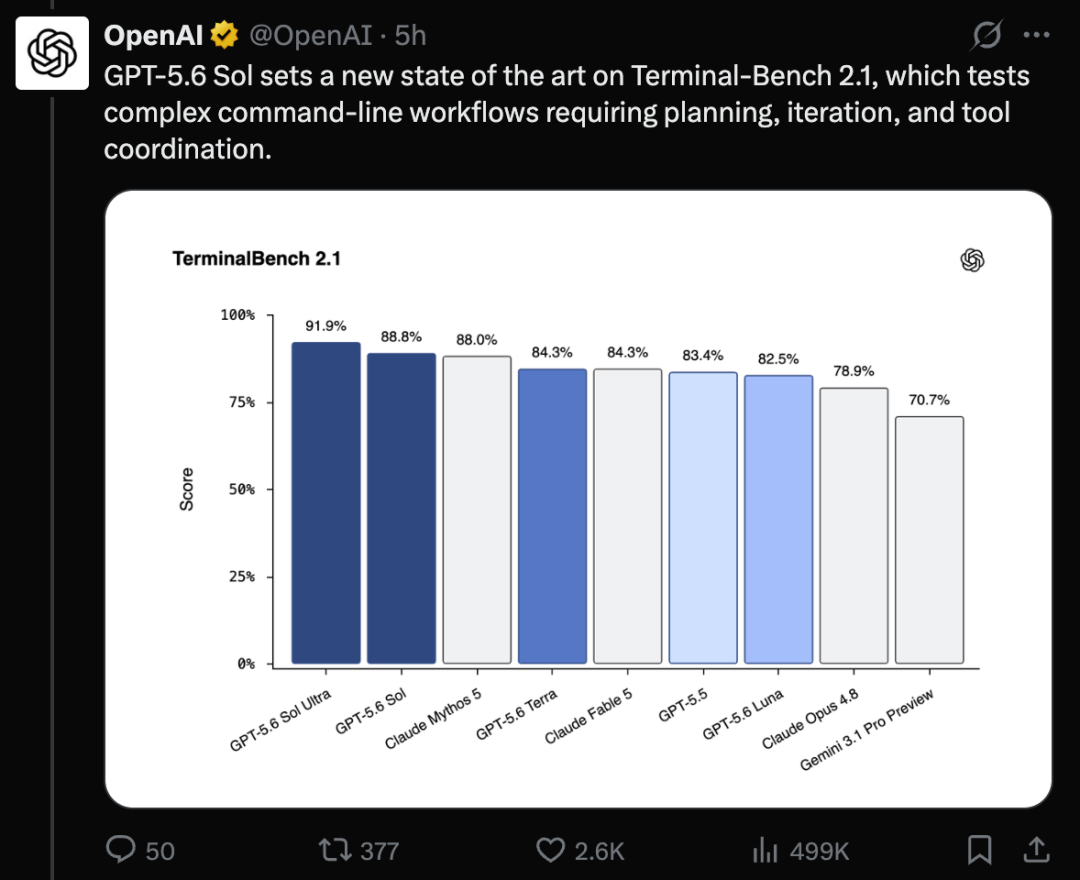
在编程工作流方面,GPT-5.6 Sol 在 Terminal-Bench 2.1 上取得新的 SOTA。GPT-5.6 Sol UItra 达到 91.95%,GPT-5.6 Sol 则达到 88.8%,超过了 Anthropic Mythos 5 和 Claude Fable 5。该基准主要测试命令行工作流,要求模型具备规划、迭代和工具协调能力。
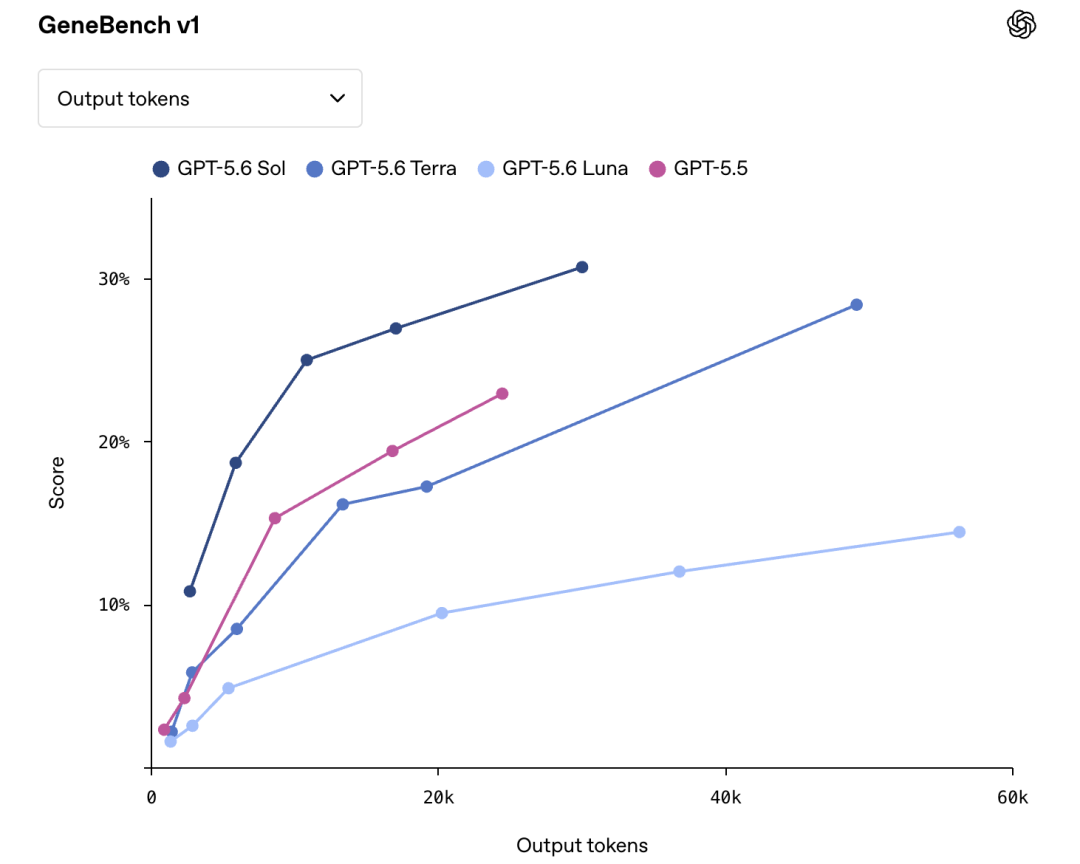
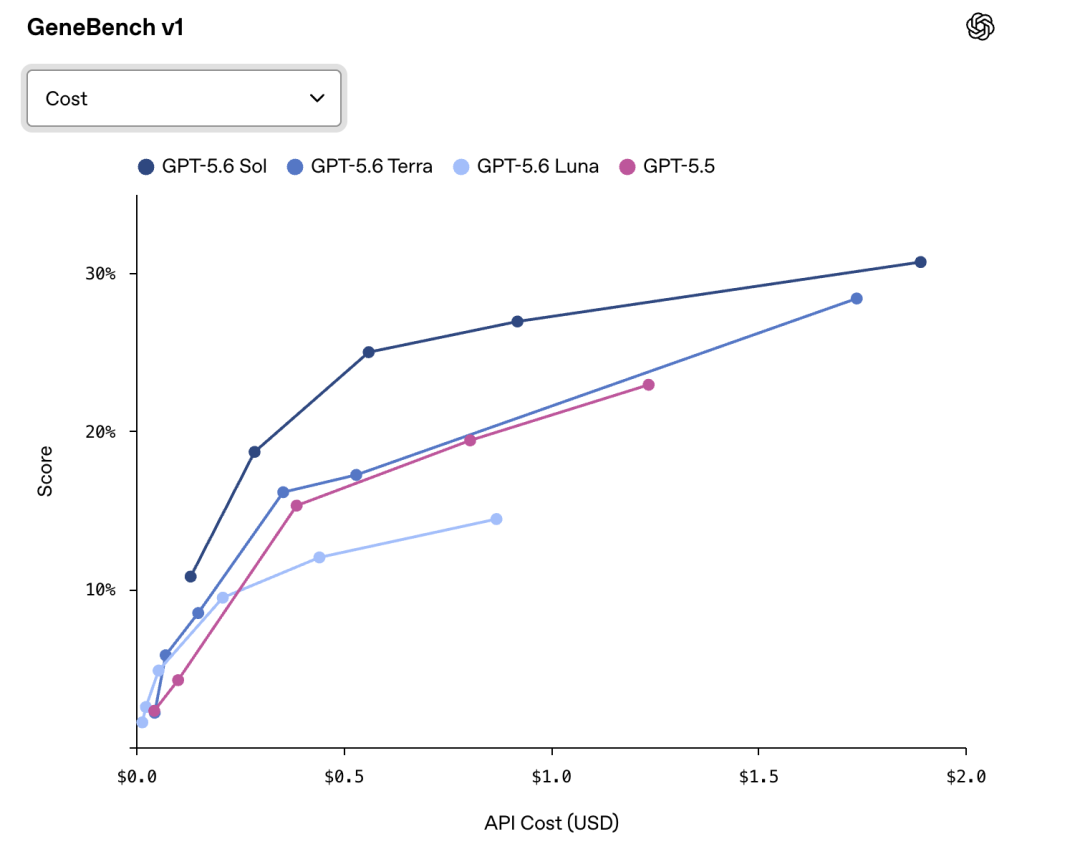
GPT-5.6 Sol 在生物学工作流上也有全面提升。在 GeneBench v1 上,它取得了强于 GPT-5.5 的结果,同时消耗的 token 更少。GeneBench v1 主要评估长周期基因组学和定量生物学分析能力。
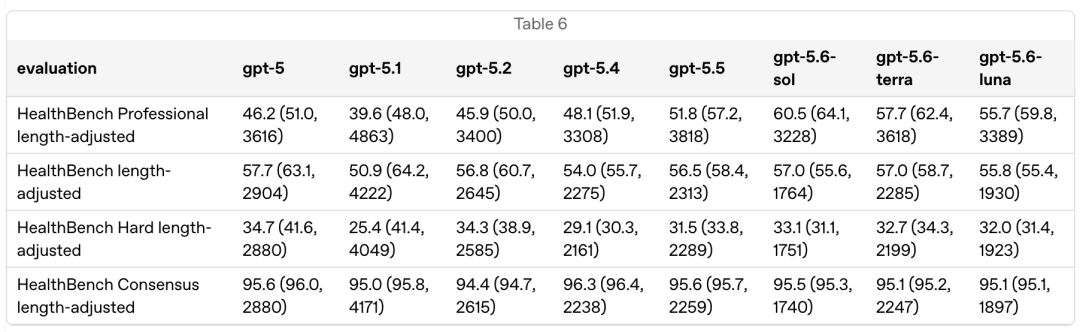
相比 GPT-5.5,GPT-5.6 Sol 在 HealthBench Professional 和 HealthBench Hard 上表现有所提升,而在 HealthBench 和 HealthBench Consensus 上基本持平。
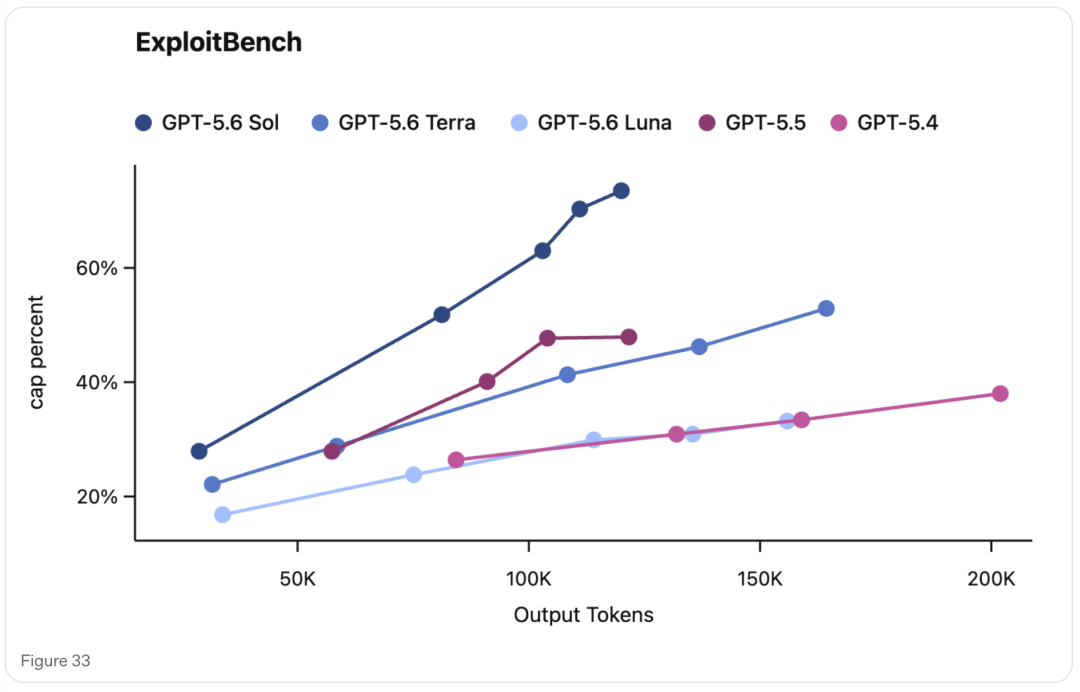
GPT-5.6 Sol 也是迄今在网络安全方向能力最强的模型。它推动了长周期安全任务的性能与效率边界,包括漏洞研究和漏洞利用。
在 ExploitBench 上,GPT-5.6 Sol 只使用约三分之一的输出 token,就能达到与 Mythos Preview 相当的表现。
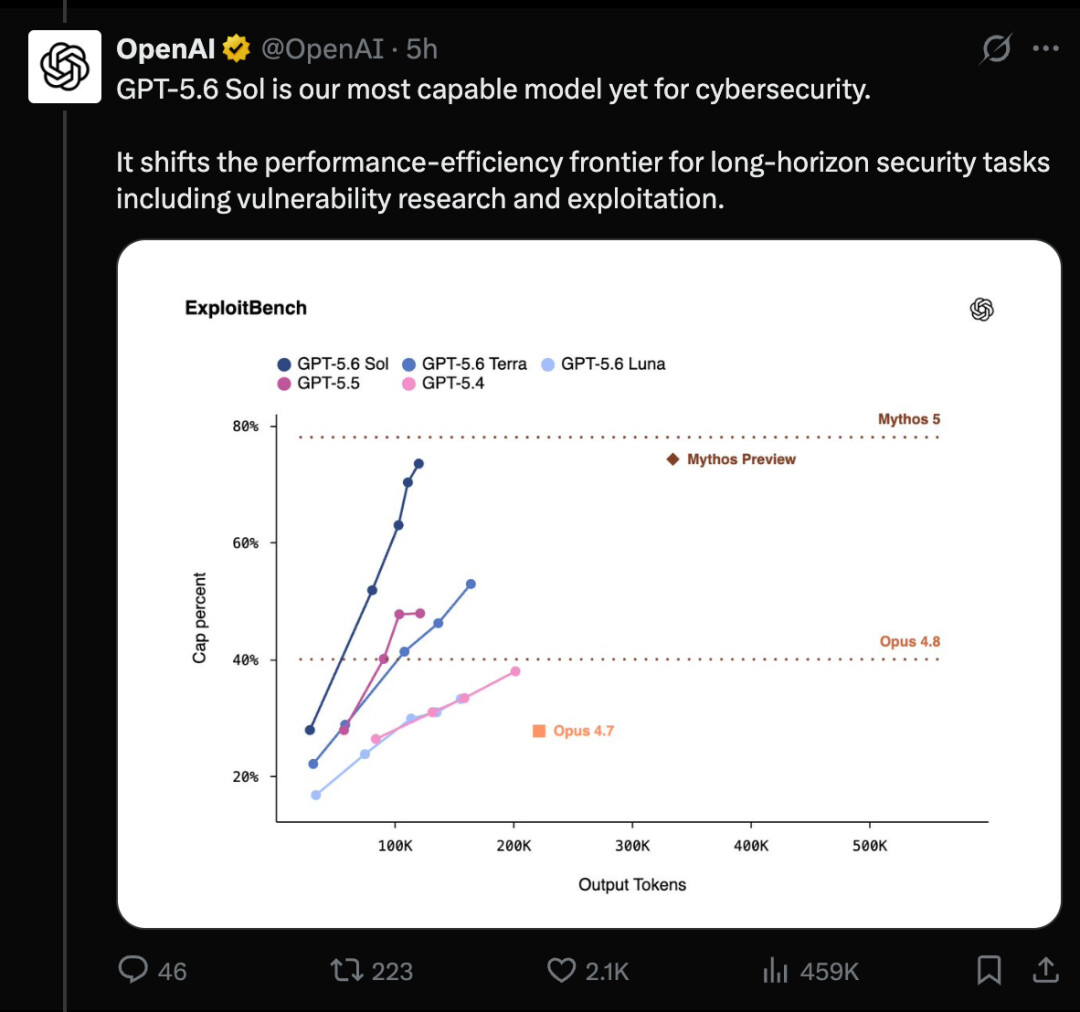
在 ExploitGym 上,GPT-5.6 Sol、Terra 和 Luna 随着推理强度提升,都展现出明显增强的网络安全能力。ExploitGym 是由加州大学伯克利分校研究人员与 OpenAI 及其他前沿实验室共同创建的基准。
强化安全体系
在技术能力层面,GPT-5.6 Sol 在终端操作基准 Terminal-Bench 2.1 和生物信息学基准 GeneBench v1 上均优于前代,在网络安全领域的长链任务处理上也展现出显著进步。尽管如此,OpenAI 明确指出 Sol 在受控测试条件下虽能识别 Chromium 和 Firefox 中的漏洞及利用原语,但尚未能自主生成完整的漏洞利用链,因此未触及其「网络安全关键」评估阈值。
正是这种能力边界的模糊性,促使 OpenAI 在此次发布中将安全体系的构建置于显著位置。
整套防护框架采用多层叠加设计:模型层面训练了对违禁网络攻击请求的拒绝能力,包括针对伪装意图和越狱尝试的识别;生成过程中部署了实时分类器,一旦检测到潜在违规,系统将暂停生成并由更大规模的推理模型进行审查,确认违规后输出内容将在到达用户前被拦截;与此同时,账户层面的风险信号监控可跨会话识别持续性恶意行为模式,将其与合法的双重用途安全研究区分开来。
为验证防护体系的鲁棒性,OpenAI 投入了超过 70 万 A100 等效 GPU 小时用于自动化红队测试,重点针对可跨场景泛化的「通用越狱」攻击路径,并辅以第三方人工专家红队测试,后者将持续覆盖整个预览期。
分阶段发布
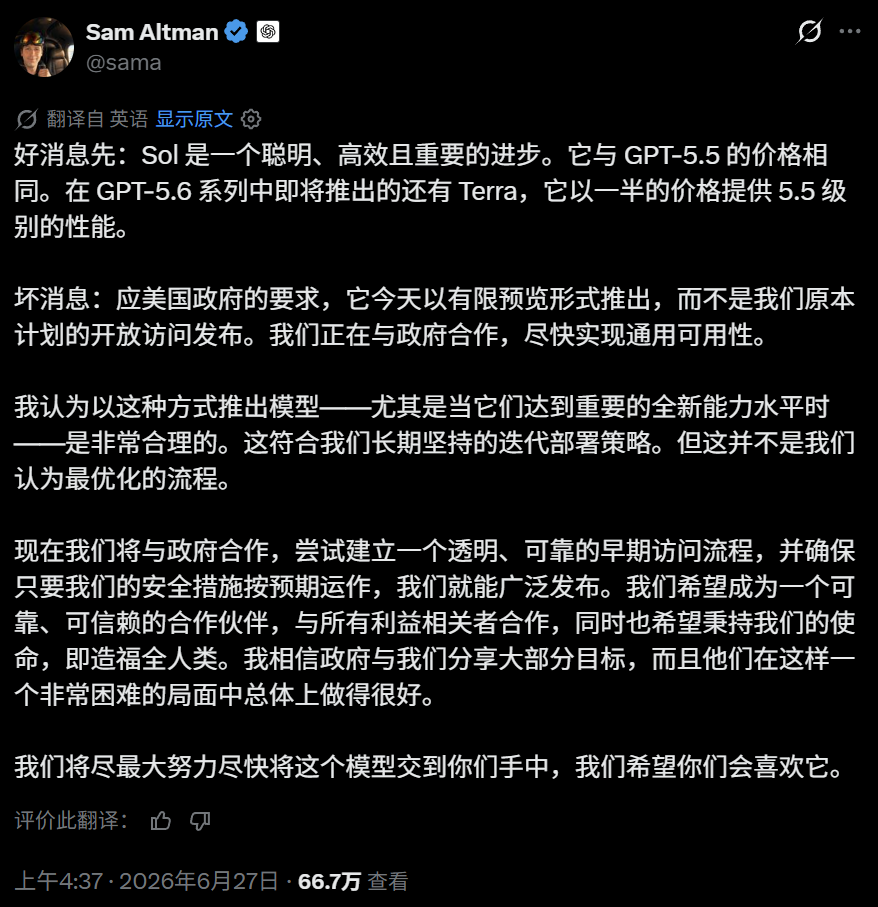
此次发布采用受限预览形式,初期仅向少数受信任的合作伙伴和机构开放 API 及 Codex 访问权限,随后逐步推向 ChatGPT 及更广泛用户群体。这一安排并非 OpenAI 主动选择,而是源于美国政府的介入。
OpenAI 表示,已提前向美方通报了发布计划及模型能力,应其要求先行对小范围受信任合作伙伴开放。
对于这种干预模式,OpenAI 措辞明确地表达了保留意见。公司在公告中写道,此类政府审查流程不应成为长期惯例,因为这会延误开发者、企业、网络安全防御方及全球合作伙伴获取先进工具。OpenAI 将此次配合定性为阶段性让步。
参考链接:
https://openai.com/index/previewing-gpt-5-6-sol/
https://www.theverge.com/ai-artificial-intelligence/957845/openai-gpt-5-6-trump-administration-ai-preview
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com