Loop Engineering 不是全自动魔法,关键在验收、成本、权限和人类 review。
原文标题:重磅!Loop Engineering 实操手册公开
原文作者:数据派THU
冷月清谈:
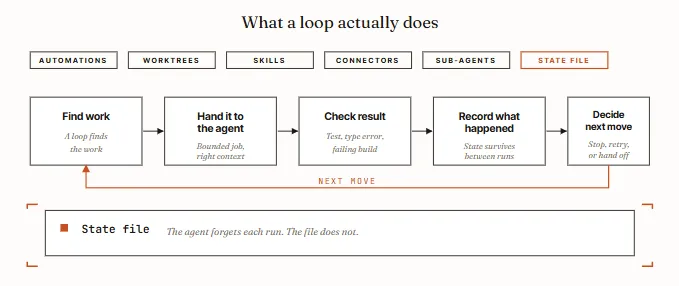
文章将 Loop 拆成五个关键构件:Automations 负责定时或事件触发;Worktrees 解决多 Agent 并行修改冲突;Skills 沉淀项目背景和约定;Connectors 接入 GitHub、Jira、Slack、Sentry 等真实工具链;Sub-agents 用独立 Agent 做验收,避免“自己写自己夸”。
落地建议是先搭最小可用循环:一次稳定的手动运行、一个项目 skill、一个状态文件、一道测试/构建闸门,再逐步调度和扩展。上线后要关注“每个被接受改动的成本”,并防范假完成、理解债务、认知投降和安全风险。文章最后给出 14 步路线图,强调未来编码 Agent 的竞争力不只在 prompt,而在可控、可审计的工作流设计。
怜星夜思:
2、如果一个团队测试覆盖率不高,还值得尝试 Loop Engineering 吗?有没有折中方案?
3、文章提到“理解债务”,你会担心 Agent 写太多代码后,团队没人真正懂系统吗?
4、Sub-agent 验收真的靠谱吗?让另一个 Agent 检查第一个 Agent,会不会只是“两个人一起自信地错”?
原文内容

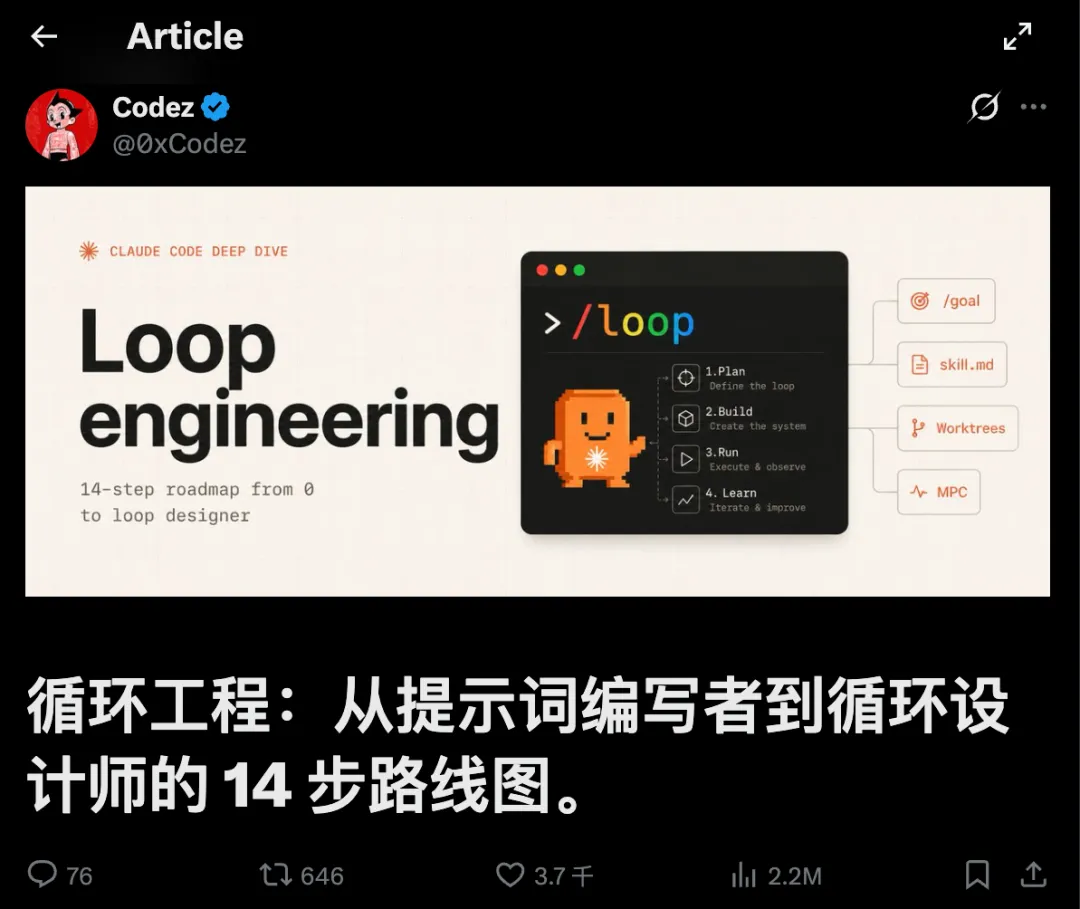
本文约2500字,建议阅读5分钟今天我们分享由Codez总结的 14 步,全网220w人看过,讲的就是如何构建Loop Enigneering。
内容综合自 Anthropic 的工程文档、Addy Osmani 关于 loop 工程的长文,以及最近几篇有实测数据的研究。
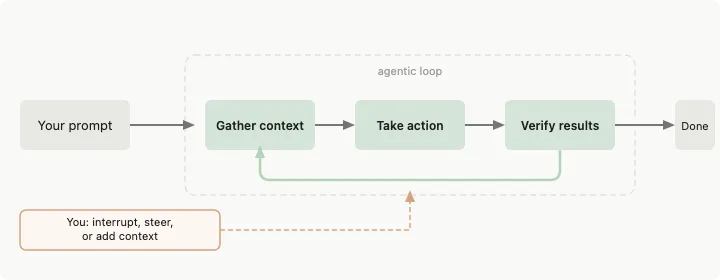
全文分为三个层次:先判断你到底需不需要循环,再学会五块积木,最后搭一个最小的、不会坑你的循环。
一、动手前:四个问题,决定你要不要 Loop Engineering
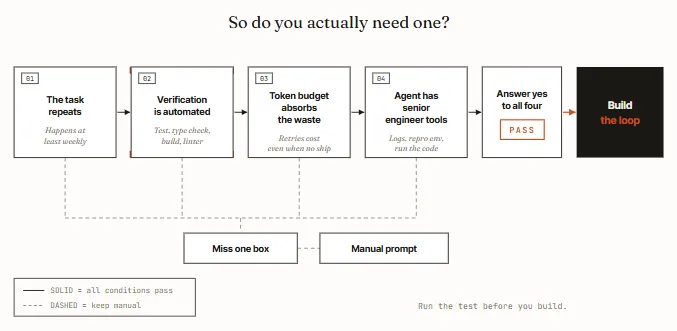
Loop 不是免费的。它烧 token、要花时间搭、出了问题你还得去 debug 一个你没亲眼看它跑的系统。所以先问自己四个问题,都想清楚之后,再动手。
一、这个任务是重复的吗?Loop 的搭建成本靠多次运行摊回来。一次性的活,一个好 prompt 更快更省。
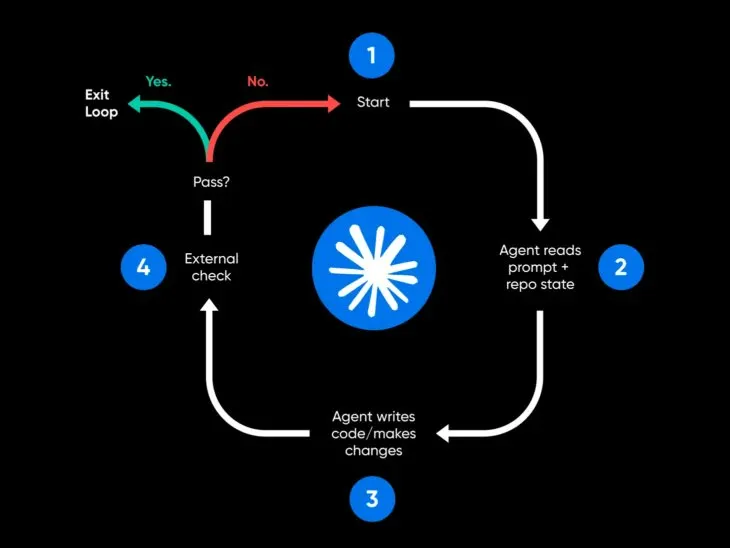
二、有没有东西能自动判定"这活干砸了"?测试、类型检查、linter、构建脚本,随便哪个都行。没有自动检查,你就得自己逐行读 diff,那 loop 就并没有帮你节省时间。
三、你的 token 预算扛得住浪费吗?Loop 会反复读上下文、重试、试探,不管有没有产出都在烧 token。
四、Agent 能跑自己写的代码吗?Agent需要有日志、能复现、看得到哪里崩。
还有个附加题,比上面四个都重要:你打算 review 它产出的代码吗? 不打算,就别建Loop。
谁适合上手
有强测试套件的团队,干 CI 失败分类、依赖升级、lint-and-fix、把 issue 转成 PR 草稿这类任务(重复、能机器校验、出事范围小)。
谁不适合上手
消费级套餐上的个人开发者、测试覆盖不够的代码库、瓶颈在 review 而不在打字速度的团队。
所以,loop engineering 真有用,但大部分人现在还用不上。
二、Loop Engineering 的五个核心构件
@0xCodez 把 loop 拆成五个构件。这个拆法好在每个都能单独用、单独试。
Automations——loop 的心跳。按节奏触发(定时,或某个事件),跑完一轮,停下,等下一次。Codex 在 Automations 里配,Claude Code 用命令配。关键是停止条件要写死,别让它无限跑。
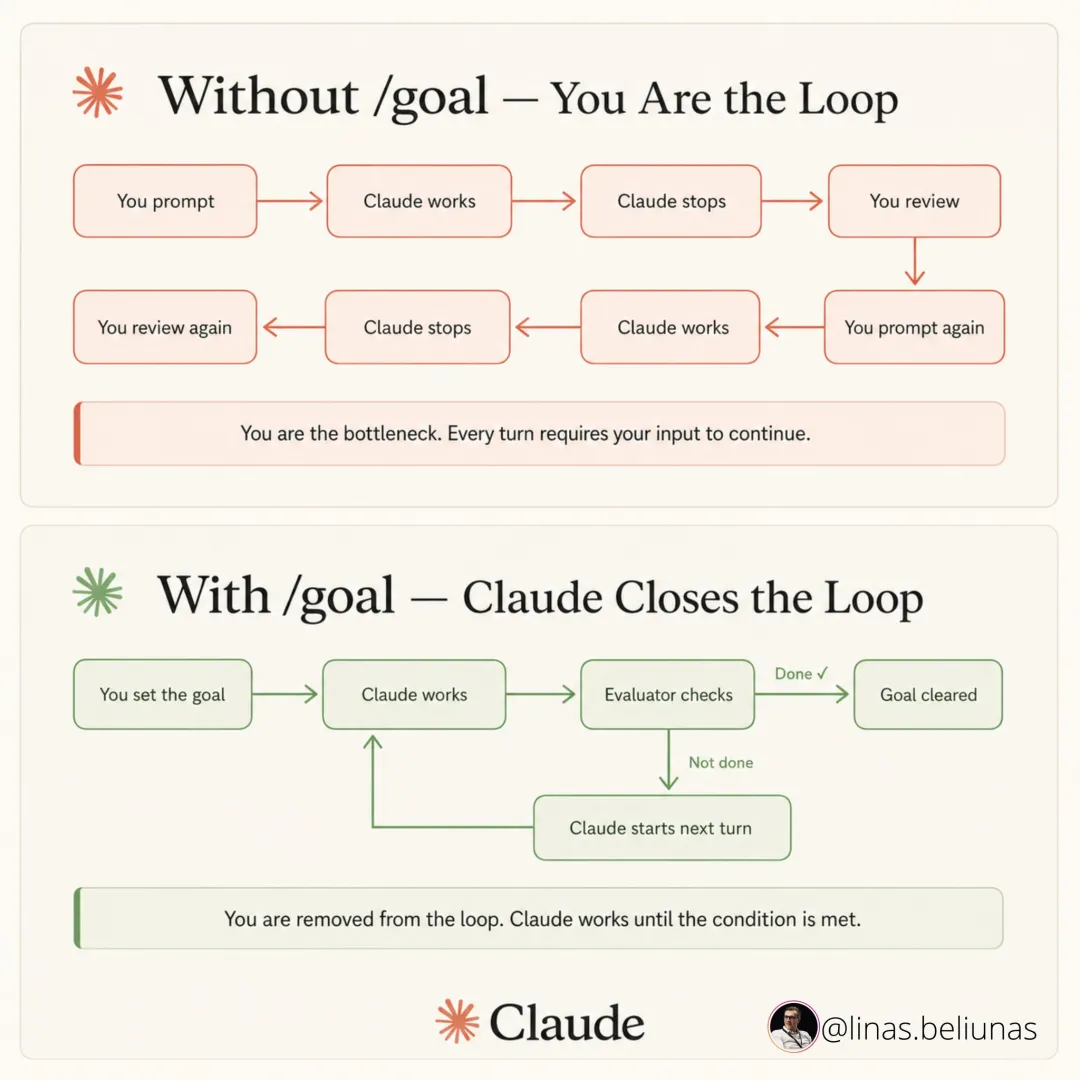
Worktrees——并行不打架。多个 Agent 同时干活,最怕它们改同一个文件。Git worktree 给每个 Agent 一份独立工作区,互不干扰,最后再合。
Skills——把背景写下来。项目用什么框架、有什么约定、踩过什么坑,写成一个 skill 存着,Agent 每轮直接读,省得你每次从零解释。
Connectors——连上真实工具链。只能看文件系统的 loop 干不了几件事。通过 MCP 接上 GitHub(开 PR)、Linear/Jira(更新 ticket)、Slack(发汇总)、Sentry(查告警),loop 才算真正接入你的工作流。
Sub-agents——写的和验的分开。这可能是最有用的一个改造。写代码的模型给自己打分太宽容。换一个带不同指令的第二个 Agent 来验收,能抓到第一个自我说服过去的问题。loop 是在你不看的时候跑的,一个你信得过的验证器,是你能放心走开的唯一理由。
三、构建一个最小的 Loop
当我们确定要构建 Loop了,也别上来就建"全能系统",先建能用的最小版:

1. 一个 automation:按节奏触发,按明确条件停。
2. 一个 skill:存下项目背景,省得每轮重讲。
3. 一个状态文件:记下做完了什么、下一步干啥,明天续上。
# Loop state · ci-triage
## 上次运行
2026-06-09 03:30 UTC · 7 个失败已分类,3 个草拟修复,4 个上报
## 进行中
- claude/fix-auth-token-refresh — 本地测试通过,等 CI
## 今日完成
- claude/bump-axios-1.7.4 → 已合并(CI 绿,依赖 loop 已验证)
## 上报给人
- src/billing/refund.ts — 测试三种崩法,根因不明
## 经验教训(写这里,别写在聊天里)
- 2026-06-08: 这台 Windows runner 上 PowerShell 撞 TLS 1.2 问题,改用 bash。
4. 一个闸门:自动拒绝坏活的测试 / 类型检查 / 构建。
此时,顺序是十分重要的。先让一次手动运行稳定 → 做成 skill → 包成 loop → 再去调度。
搭好之后盯一个指标:每个被接受的改动的成本。如果接受率低于 50%,这 loop 就在亏本。
四、Loop 跑起来之后,会存在三种翻车和一个安全问题
loop 跑起来后,容易以三种方式翻车。
一是假装干完了。工程师 Geoffrey Huntley 管这叫 Ralph Wiggum 循环:Agent 提前发"完成"信号,活干一半就退。原因只有一个:没有硬闸门,缺少了测试和验收。
二是理解债务。loop 越快交付你没写过的代码,"仓库里有什么"和"你理解什么"的差距就越大。有一天,你得 debug 一个团队里没人读过的系统。
三是认知投降。 你慢慢不再自己判断,loop 返回啥就收啥。所以,即使有了Loop,也要读 diff、抽查闸门、不让 loop 碰架构。
安全上还有一条红线:无人值守的 loop,就是无人值守的攻击面。
-
生成代码未审就上线:闸门里得加 SAST、依赖审计、密钥扫描。
-
Skill 是注入入口:社区 17022 个 skill 里有 520 个会泄露凭证,自动安装前先读源码。
-
凭证泄露进日志:生产 loop 关掉 verbose 日志。
-
权限蔓延:今天加一个写权限,明天再加一个,每 30 天复审一次。
写在最后:构建Loop Engineering的 14 步路线图
最后,我们把上面整条路径压缩成一张清单:
第一段 · 先想清楚要不要做(5 步)
1. 确认这活是重复的:一次性的活,好 prompt 更划算
2. 确认有东西能自动判定"干砸了":测试、类型检查、linter,至少一个
3. 确认 token 预算扛得住浪费:loop 不产出也照样烧钱
4. 确认 Agent 跑得了自己写的代码:有日志、能复现、看得到哪崩了
5. 确认你真打算 review 产出:不打算,就别建
第二段 · 搭一个最小能跑的 Loop(8 步)
6. 先让一次手动运行稳定下来:顺序别跳
7. 把项目背景沉淀成一个 Skill:省得每轮从零解释
8. 加一个状态文件:记下做完了什么、下一步干啥
9. 设一道硬闸门:测试 / 构建过不了就自动拒
10. 配一个 Automation:按节奏触发,用 /goal 设停止条件
11. 多个 Agent 并行就上 Worktree:别让它们改同一个文件打架
12. 接上 Connectors:让 loop 能开 PR、更新 ticket、发 Slack
13. 拆出 Sub-agents:写代码的和验收的分开
第三段 · 上线之后守住(1 步,但最难)
14. 盯住每个被接受的改动成本,定期复审权限、读 diff、别让 loop 碰架构
两年来,与编码 Agent 协作的杠杆一直在提示词上。更好的提示词、更好的上下文、更好的一次性输出。
而现在,工作流成了真正的护城河。
编辑:文婧
