豆包大模型 2.1 发布,主攻代码、智能体与多模态,日均调用达 180 万亿 Tokens。
原文标题:刚刚,豆包大模型2.1发布,又一次跨越生产级质变点
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章里反复提到“生产级质变点”,大家觉得大模型真正进入生产力阶段的标志是什么?
3、模型价格越来越低,会不会让企业更倾向于“狂用 AI”,反而带来新的成本和管理问题?
4、代码能力评测成绩很好,但真实工程里,AI 写代码最难跨过去的坎是什么?
原文内容
想不到,真的想不到。
每一天,大家调用的豆包大模型 API Tokens 竟有 180 万亿。距离首次发布才不到两年,Token 的数字就飙涨了超 1500 倍。因为 AI 能力的突破,火山引擎如今已占到中国公有云 MaaS 市场的 49.5%,成为当之无愧的第一,「万亿 Tokens 俱乐部」成员更是突破了 200 家。
刚刚,火山引擎 Force 原动力大会上,我们见证了一波大数字,与此同时还有字节的新一代通用大模型豆包大模型 2.1,以及一系列多模态新模型的发布。

几个数字背后,是爆发性的技术突破。如今的大模型行业,正在从技术探索期全面迈入产业规模化,不论技术还是落地,豆包大模型已经跑在了前面。
豆包大模型 2.1
直面生产力
AI 落地的过程中,Token 消耗是直观的表象。
这次大会上,火山引擎抛出了一个关键的行业判断:企业采纳大模型,正在跨越「质变点」。
当模型能力跨越了阈值,生产力瓶颈被突破,Token 的用量就会呈指数级上升。就像此前图像领域的 Nano Banana、文本和编程领域的 Claude Opus 4.6,以及视频领域的 Seedance 2.0,它们很大程度上成为了 AI 进入真实生产环境的关键分水岭。
很多人认为 Opus 4.6 是大模型真正进入生产力阶段的节点,原因在于它解决了此前 AI 的几个核心的痛点(不可靠、不持久、不深入),让 AI 从回答问题进化到了处理工作的阶段。
今天发布的豆包大模型 2.1 也要在代码生成、Agent(智能体)与 VLM(视觉语言模型)三大核心能力上跨越这一质变点 —— 它在多项评测任务中甚至超越了 Opus 4.7。
其中,豆包 2.1 Pro 在 Terminal Bench 2.1、SWE-Pro、SciCode 等代码评测中进入第一梯队:
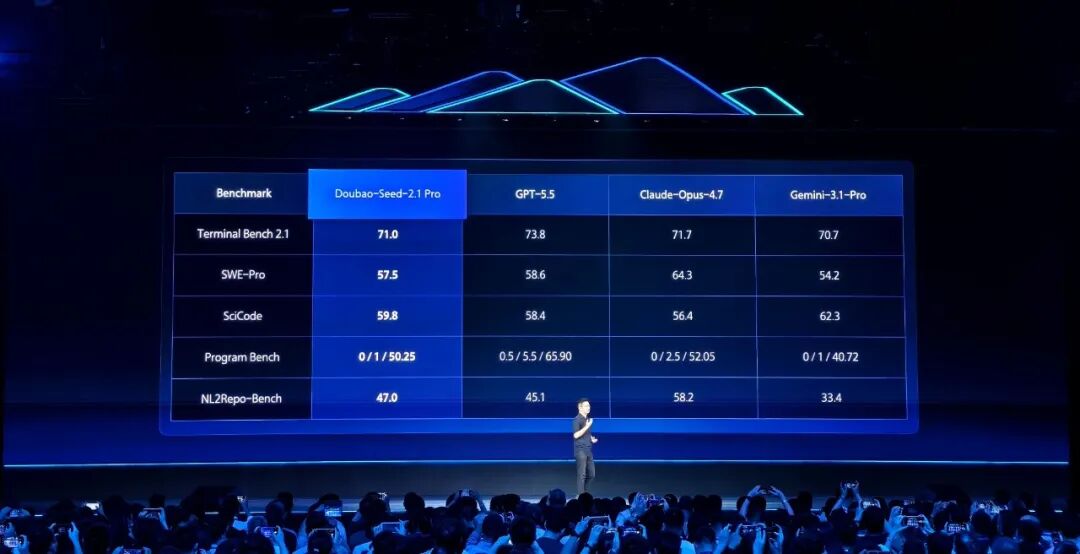
Coding 能力评测。
在 GDPVal、MCP-Atlas 等智能体、真实环境工具使用评测上,豆包 2.1 Pro 也位居全球前列:
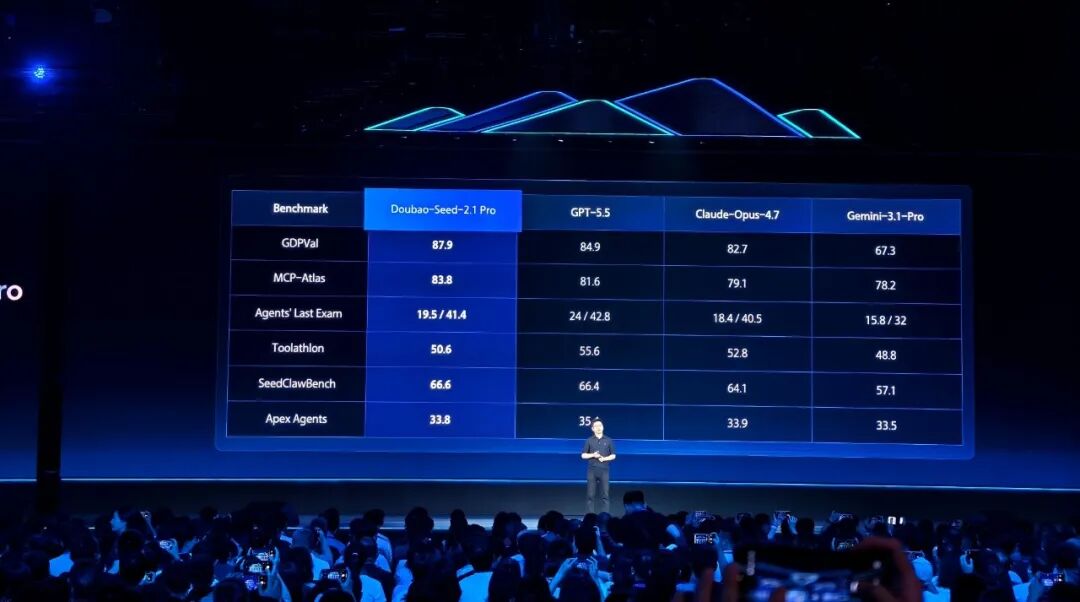
Agent 能力评测。
在实际使用过程中,豆包 2.1 的 Coding 能力有了跨越式进化,比如在代码生成的过程中,不再局限于片段补全或单文件生成,而是跑通了「仓库级理解 + 端到端项目交付 + 自测闭环」的完整链路,能够独立完成真实工程任务。
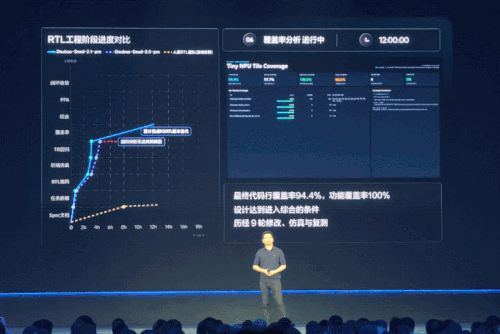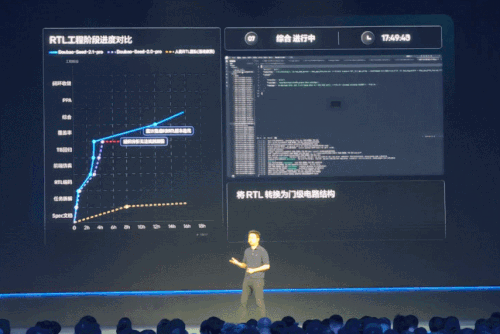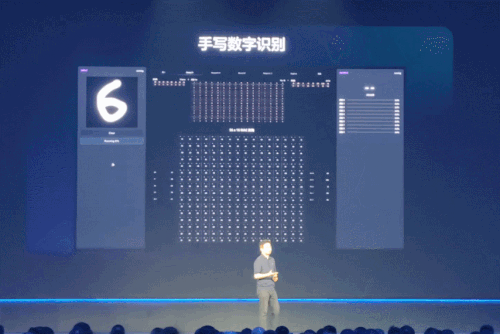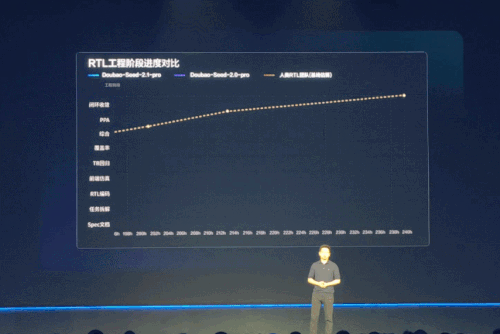
大会上展示的是一项芯片设计 RTL(寄存器传输级)测试的效果,豆包 2.1 Pro 连续运行近 18 小时,经历 9 轮迭代,跑通了仿真、测试、综合检查等完整工程流程,秀了一把真实工程场景里的生产级 Coding 交付能力。
智能体方面,豆包 2.1 驱动的智能体从能执行简单任务,升级成了能在接口报错、数据缺失等复杂异常环境下,依然进行「动态路径规划 + 异常自纠 + 交付产物 」的成熟智能体。
我们对此进行了测试,发现现在豆包 App、桌面端的模式选择上多出了一个「办公任务」选项,专门来跑多智能体。
假如我是个计算机视觉(CV)的研究者,想让豆包的智能体来帮我们分类一下 2 月份某天 arXiv 上全部该领域的论文,顺便看看有没有人引用了我以前的工作。把这个任务交给豆包 2.1 后,一群智能体开始了工作:

如果你点进去看细节,可以看到当天该领域有超过 100 个领域内论文 ID,一个人自己看肯定是看不过来的。我们给出任务后,智能体自行进行了搜索,自行计划使用工具,写 Python 脚本进行分类,中间出错了会自行纠正,最后完成了还会通知你。
生成的结果看起来不错:

除了文本与代码能力的提升,豆包大模型原来的强项多模态能力(视频理解、图像推理与跨图分析)在 2.1 版上也大幅强化,在大部分多模态基准成绩上领先 Opus 4.7,正在指向更复杂的现实世界互动。
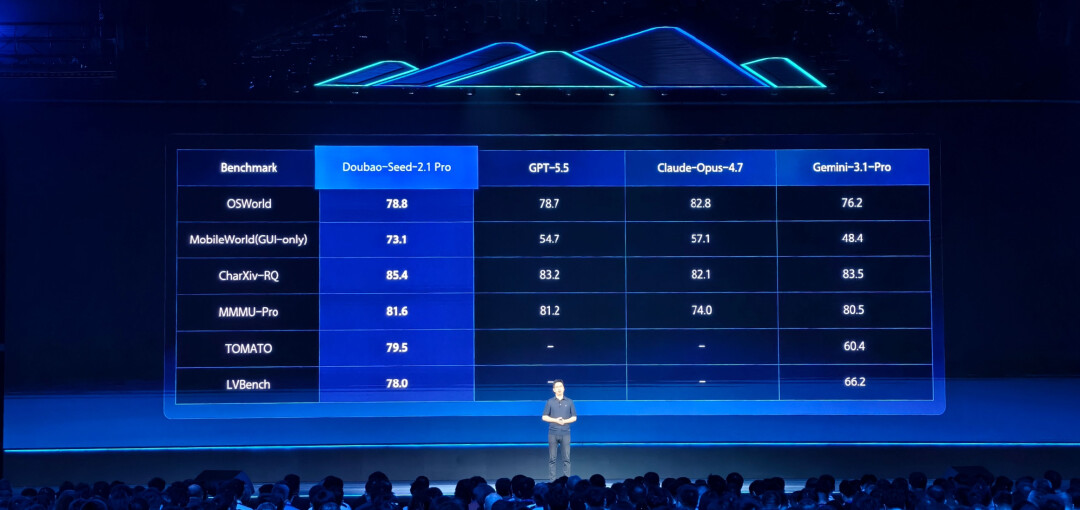
GUI、图像理解等 VLM 能力评测成绩。
例如在视频理解方面,豆包 2.1 不仅能「看懂」画面,还能处理长视频的跨时序逻辑;在图像推理上,针对复杂的图表数据(如金融报表、工业设计图),其空间理解能力和跨图对比分析能力都有了肉眼可见的提升。这意味着,AI 模型不再是单纯地处理文本,现在已能像专业人士一样看懂复杂的视觉资料。
为满足不同场景的算力与成本需求,豆包大模型 2.1 同步推出两款主力型号:适配高性能场景的 Doubao-Seed-2.1-pro,以及主打性价比的 Doubao-Seed-2.1-turbo。除了通过火山引擎接入 API,我们也能在豆包、TRAE、扣子等应用中体验到最新的模型。
从技术报告中我们能看到,豆包大模型 2.1 引入了一种专为前沿研究和高级工程任务设计的推理时(Inference-time)配置:Seed2.1 Deep Think。该模式不直接输出最终响应,而是执行「推理 -> 验证 -> 修正 -> 选择」的自动化循环,期间可以调用网络搜索和代码沙盒进行假设验证与迭代。
为了构建更强大的新版本模型,豆包大模型也祭出了 AI 的自我迭代,其训练阶段的 Seed for Seed 机制,利用不断变强的 Seed 模型本身来深度参与研发和迭代的全生命周期。AI 自我迭代的参与范围涵盖预训练数据的处理、数据合成与训练自举、基础设施建设与算子优化等。

豆包 2.1 Pro 每百万 Token 输入价格为 6 元、输出价格 30 元,缓存命中价格 1.2 元。火山引擎表示,其综合使用成本较 Claude Opus 4.6 降低近 80%。另外,Turbo 的价格进一步降至 2.1 Pro 的一半。
大模型「质变点」
字节都拿出了什么?
作为核心基座模型,豆包大模型 2.1 的提升为其众多 AI 应用提供了支持。
这样的质变点,在 Seedance 2.0 问世的时候,我们已经清晰地感受过。
作为当下公认的视频生成领域 SOTA 模型,Seedance 2.0 今年 2 月推出后在极短时间内完成了现象级破圈。从刷屏短视频平台的爆款 AI 创作,到深度嵌入专业影视后期与高转化率的电商营销流,Seedance 2.0 已经用实打实的市场份额证明:当模型能力真正跨越视觉连贯性与物理逻辑的门槛,迎来的将是真实生产力环节的爆发。
Seedance 2.0 此次发布了原生 4K 10-bit 高位深直出能力,在细节、运动和色彩上全面优化。

AI 视频生成除了娱乐、营销等应用方向之外,还是通往世界模型的路径之一,在实体产业中有巨大的应用潜力。字节表示,目前 Seedance 已经在具身智能、工业制造、智能驾驶等领域落地,为数据合成、场景仿真、流程演示等业务需求提供了新的工具能力。
与此同时还有它的商业化。之前大家都在演绎华强买瓜,火山引擎此次直接拿下了周星驰旗下比高集团三部经典影片《喜剧之王》、《长江七号》、《食神》的 AI 创作授权,推出的影视 AI 模板在抖音单日互动量就突破了 20 万。你现在可以用 Seedance 2.0 来充分展示你自己的想象力。
大会同步推出了「火山 AI 版权商业化平台」,试图跑通从「模型生成」到「版权分发变现」的完整闭环。
字节还预告了下代视频生成大模型 Seedance 2.5,它目前处于内测阶段,将在 7 月初上线,其将支持全球第一的 30 秒单段原生直出,最多 50 个全模态多素材联合输入,并支持更精准的视频二次编辑。

在这场大会上,还有一些值得关注的发布:
即将上线的图像创作模型 Seedream 5.0 Pro 专为企业级设计工作打造,它最大的突破在于让 AI 绘图告别了开盲盒式的一次性出图,实现了多图层分离、交互式局部微调编辑,无缝对接专业设计软件的日常工作流。Seedream 5.0 Pro 的单张图像可以承载 PPT 级别的高密度信息,支持 14 种语言的图内文字精准生成排版。
豆包音频生成模型 1.0 可以帮助我们无需声音样本,仅靠文本、图像或音频输入生成自然语音,大大降低定制门槛。其突破性的「长时一致性」解决了长音频前后音色割裂的痛点,并支持影视级多轨混编,可直接产出多人对话级别的专业对白。

在 AI 领域,你可以永远相信更好的还在后面。
结语
AI 能力质变带来的不仅是数据的增长,更是对人们使用 AI 的方法,工作流程乃至生产力的颠覆。在大会上,火山表示,目前「万亿 Tokens 俱乐部」的成员已超 200 家,覆盖互联网、制造、金融、汽车等全行业。
不得不说,这种大规模应用和渗透率,是所有人始料未及的。当 AI 模型跨越了可用性的临界点,底层算力、基座大模型与顶层的智能体应用正在加速形成闭环。180 万亿的日均 tokens 用量是一个清晰的信号。

AI 正在全面接管高价值生产任务,属于大模型的时代,正在到来。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com