清华提出可穿戴RGB-T对抗服装,揭示多模态检测系统的物理安全隐患。
原文标题:一件衣服「隐身」可见光-热成像检测器,清华多模态对抗新方法
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、这类对抗服装论文公开代码和制作方法,会不会反而增加现实风险?
3、多模态AI是不是被高估了?加了热成像、雷达等传感器,就一定更安全吗?
4、如果要防御这种物理对抗样本,模型训练阶段应该加入哪些数据或机制?
原文内容

来源:新智元本文约2500字,建议阅读5分钟清华大学提出一种新型物理对抗方法,利用特殊服装同时干扰可见光和热成像检测。这种服装通过非重叠设计和三维建模优化,可有效躲避RGB-T检测器,促进系统安全性研究。
近年来,可见光-热成像(RGB-T)联合目标检测系统受到了越来越多关注。
与单一可见光检测相比,RGB-T检测器能够同时利用普通相机和热成像相机的信息,在夜间、弱光、恶劣天气等复杂环境下具有更好的鲁棒性,因此在自动驾驶、智能安防、机器人感知等场景中具有重要应用价值。

由于多模态系统同时融合了可见光和热成像信息,人们通常认为它比单模态系统更加可靠:即使一个模态受到干扰,另一个模态仍然可以提供补充信息。
然而,这类系统在现实物理世界中的安全性是否真的足够可靠,仍然缺乏系统研究。
最近,来自清华大学的研究团队在CVPR 2026论文中提出了一种面向可见光-热成像目标检测器的物理对抗方法。该方法通过设计一套特殊的对抗服装,使行人在现实世界中能够同时躲避可见光和热成像检测器。

论文链接:https://arxiv.org/abs/2605.04675
代码链接:https://github.com/zxp555/RGBT-Clothing
实验表明,该方法可以对抗不同融合架构的RGB-T检测器,在数字世界中的平均对抗成功率达到90%,在真实物理世界中的平均成功率达到60%。

对抗样本研究表明,深度神经网络在面对经过精心设计的扰动时,可能产生错误判断。过去,大量物理对抗工作主要集中在单一模态上:例如,在可见光场景中,可以将对抗图案打印在纸张、贴纸或衣服上;在热成像场景中,则可以利用发热器件、隔热材料等方式改变热图像。

但是,可见光和热成像机制存在显著差异。可见光图像依赖光照、颜色和纹理,而热成像图像反映的是物体表面的热辐射特性。
因此,只针对可见光设计的对抗图案,往往无法在热成像图像中产生有效对抗;只针对热成像设计的材料,也难以同时欺骗可见光检测器。
目前,有一些工作尝试对抗RGB-T检测器,但仍存在局限。例如,一些方法采用二维对抗贴片,但对抗角度范围较窄;另一些方法需要将特殊低辐射薄膜叠加在打印图案上,但削弱可见光图案效果,且增加了制作成本。也就是说, RGB-T 检测器在不同角度、距离和融合架构下的真实安全风险仍未被充分揭示。
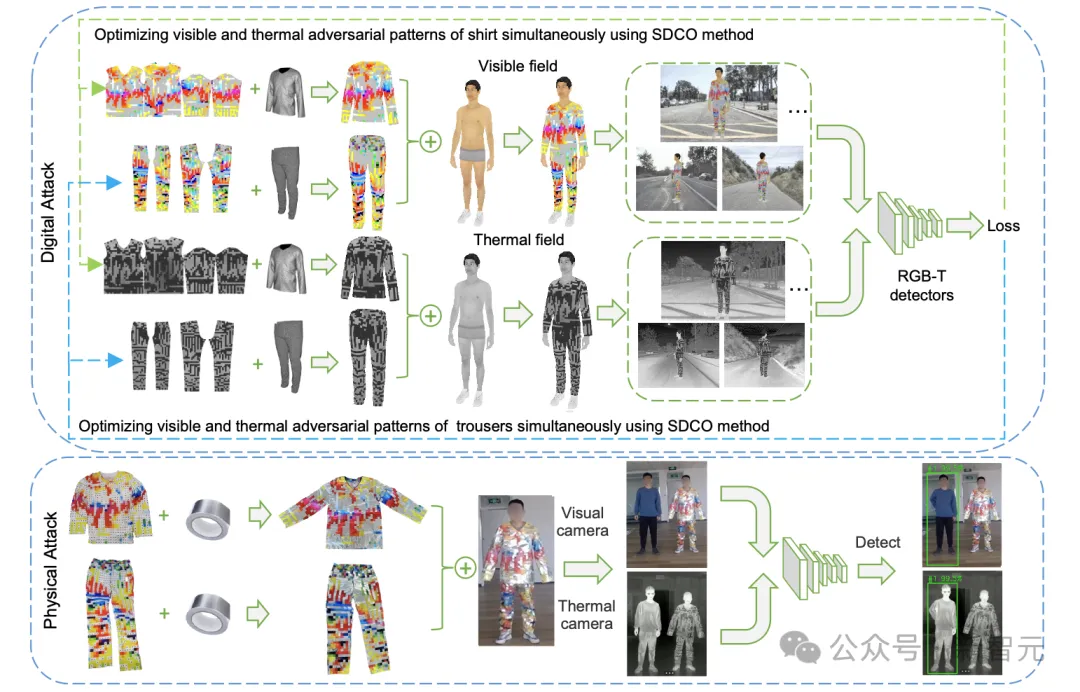
为了解决这些问题,作者提出了一种非重叠RGB-T对抗图案设计,称为NORP(non-overlapping RGB-T pattern)。其核心思想是:物理对抗服装上的每一个位置要么用于显示可见光图案以干扰可见光检测,要么用于显示热成像图案以干扰热成像模态,两者在空间中不重叠。
具体来说,作者使用普通可打印布料来承载可见光对抗图案,同时使用常见的铝膜材料来改变局部热热成像效果。这样既可以同时作用于RGB和Thermal两个模态,又避免了传统重叠式打印带来的亮度下降问题。
为了在现实世界中适用于不同观察角度,作者进一步构建了人体和服装的三维RGB-T模型。通过三维建模,系统可以在数字世界中模拟0到360度全视角下的人体穿衣效果,并同时渲染可见光图像和热成像图像。优化完成后,作者再根据生成的图案制作真实衣服,包括上衣和裤子,从而实现物理世界中的全视角RGB-T对抗。
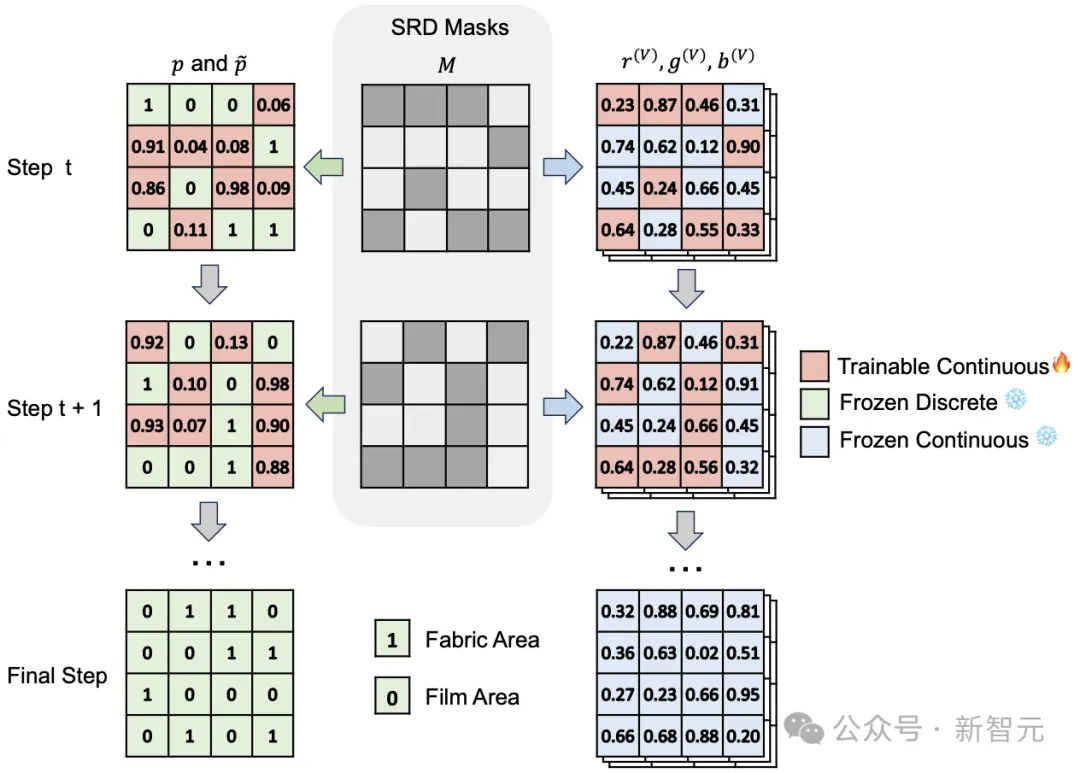
但是,在对抗图案的优化方法上,NORP带来了一个新的难题:同一个位置不能既是可连续优化的RGB颜色,又是离散选择的热成像材料。为此,作者提出了空间离散-连续优化方法,在优化过程中随机选择部分区域进行离散化,同时更新另一部分连续变量,从而在满足物理可制造约束的同时,联合优化可见光和热成像对抗图案。
为了提升对未知检测器的迁移对抗能力,作者还提出了融合阶段集成方法,将早期融合、中期融合、晚期融合以及独立双模态检测器共同纳入优化,使一套衣服能够有效干扰不同融合架构的RGB-T检测系统。
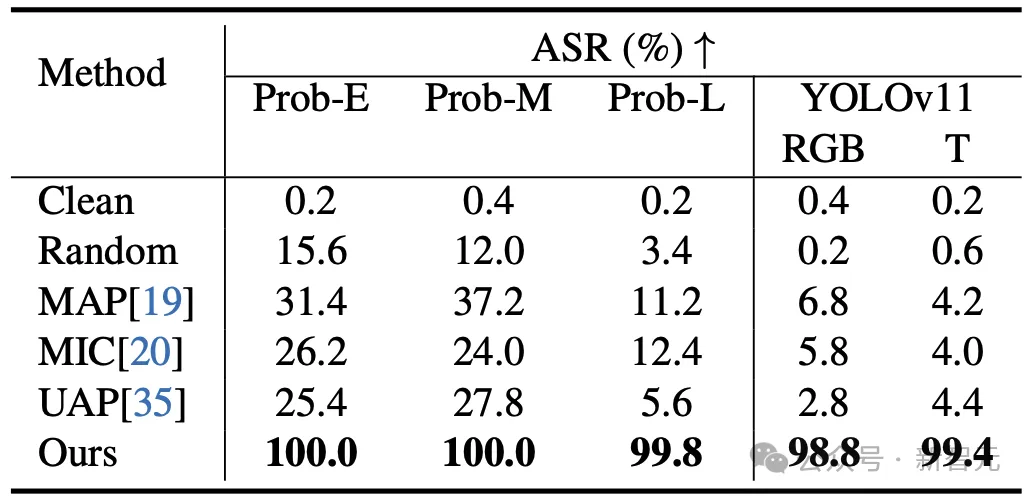
作者首先在数字世界中进行了系统评估。实验覆盖了多种RGB-T检测架构,包括早期融合检测器Prob-E、中期融合检测器Prob-M、晚期融合检测器Prob-L,以及独立的YOLO11可见光和热成像检测器。评测使用FLIR测试集的500张图像,在随机人物角度,距离,背景和光照条件下进行。
结果显示,得益于3D建模以及连续离散混合优化的对抗方法,本文实验在数字世界中对不同RGB-T检测器均取得了非常高的对抗成功率(ASR),达到90%以上。相比之下,普通纯色衣服、随机RGB-T图案以及已有对抗方法,对多模态目标检测器的对抗成功率较为有限。
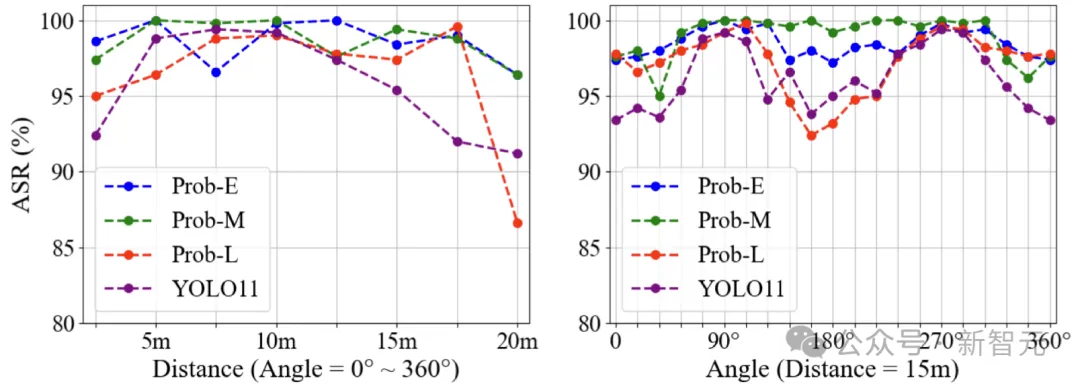
作者还进一步分析了不同距离和角度下的对抗效果。实验覆盖0到360度视角,以及2.5米到 20 米的距离范围。结果表明,本文方法能够在全视角和多个距离条件下稳定对抗RGB-T检测器,相比以往主要适用于有限角度范围的二维贴片方法具有明显优势。
接下来,作者使用布料和铝膜制作了真实RGB-T对抗服装,并开展物理世界实验。实验使用iPhone 13 Pro和FLIR T560热成像相机同步采集可见光和热成像图像,并在室内和室外、早晨、中午、下午和傍晚等不同场景中采集数据。物理实验结果显示,本文方法在不同融合架构的RGB-T检测器上均能有效逃避检测,平均对抗成功率达到60%,显著优于普通衣服、随机图案衣服和已有方法。

作者还验证了方法在黑盒设置下的迁移能力。通过融合阶段集成优化,一套对抗服装可以迁移对抗未参与训练的RGB-T检测器,例如RPN-E、AR-CNN、RPN-L和Deformable DETR等。作者在这些模型上也观察到了一定的迁移对抗效果。这表明当前RGB-T检测系统在面对现实物理对抗时仍然存在普遍安全隐患。
结论与展望
研究人员提出了一种面向可见光-热成像目标检测器的物理对抗方法。
通过构建三维RGB-T人体和服装模型,设计非重叠RGB-T对抗图案,并提出空间离散-连续优化方法,实现了可制造、可穿戴、全视角的多模态对抗服装。
该研究表明,即使是融合了可见光和热成像信息的多模态检测系统,也可能在现实世界中受到物理对抗样本的威胁。
相关研究发现有助于更加全面地理解RGB-T检测器的安全风险,并推动未来实现更加鲁棒、更加可靠的多模态感知系统。
论文作者依次为,朱小佩,清华大学水木学者,合作导师为朱军教授;曾冠宁(共同一作),清华大学计算机系本科生;胡展豪,加州大学伯克利分校博士后;以及本文通讯作者,清华大学朱军教授和胡晓林副教授。
参考资料:https://arxiv.org/abs/2605.04675
编辑:文婧
校对:林亦霖
