Skill 不是提示词堆料,而是上下文工程与组织经验复用。
原文标题:Anthropic 终于公开了他们内部 Skill 方法论
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、哪些内容应该写进 Skill,哪些内容更应该做成脚本?这个边界你会怎么划?
3、如果一个团队有几十上百个 Skill,应该怎么避免 Skill 太多导致混乱?
4、文风类 Skill 为什么经常会让内容变浅?有没有办法兼顾风格和质量?
原文内容
看了一篇 Anthropic 团队写的博客《Lessons from building Claude Code: How we use skills》。这应该是我目前看到关于 Skill 最深入的一篇实践总结了。
Skill 这东西其实不复杂,但真正想把 Skill 做好,我觉得也没那么容易。
我记得 Skill 刚火的时候,大家特别喜欢做各种文风 Skill、写作 Skill。好像只要把自己的写作风格塞进去,模型就能稳定按照这个风格输出。
但我后来自己试了一圈,发现很多时候根本不可行。
因为一个文风 Skill 可能就塞进去几千字甚至上万字内容。Skill 一加载,上下文就占掉很大一块。上下文一重,模型的思考能力反而容易下降。
最后经常出现一种情况:风格倒是学到了,但内容变浅了,分析能力也变弱了。
还有一种常见情况。
很多人写 Skill 的时候,喜欢往里面塞各种操作说明。第一步做什么,第二步做什么,第三步做什么。结果跑起来会发现,模型执行并不稳定。
后来我才慢慢理解,很多这种重复执行的工作,其实更适合沉淀成 Script,而不是写成长长的 Instructions。
看完 Anthropic 这篇文章之后,我最大的感受是,很多人其实都在用 Skill,但未必真正理解 Skill。
Skill 本质上是在做 Context Engineering。什么时候应该把知识放进 Skill,什么时候应该拆成 References,什么时候应该写成 Script,什么时候应该用 Gotchas 去约束模型,这里面其实有很多经验。
理解了 Skill 的运行原理之后,再回头看那些优秀的 Skill,会发现它们解决的从来都不是提示词的问题,而是在解决上下文、经验沉淀以及能力复用的问题。
如果大家想深度研究 Skill,特别推荐看两篇文章:
https://claude.com/blog/lessons-from-building-claude-code-how-we-use-skills
https://research.perplexity.ai/articles/designing-refining-and-maintaining-agent-skills-at-perplexity
01 不要写废话
Skill 本质上是在沉淀组织里的「隐性知识」。所以,Skill 里不要重复它已经知道的常识。真正有价值的是其实是那些模型根本不知道的信息。
Anthropic 内部经常强调,Skill 真正要写的是 Gotchas,也就是常踩的坑。
比如: 1、这个表不能按 created_at 排序 2、staging 返回 200 不代表成功 3、request_id 和 trace_id 是同一个东西
因为这些信息往往存在于员工的经验里。所以一定要记住 Skill 本质是什么。
Skill = 把老师傅经验写下来。
通过 Skill,把原来散落在不同人脑子里的经验沉淀下来。
02 Skill 其实是 Context Engineering
这可能是 Anthropic 最深刻的观点之一。
Skill 不是一个 markdown 文件,而是一个文件夹。对用过 Skill 的人来说,这话听上去像废话。
但我这两天反复琢磨,慢慢意识到:他们正是想用文件夹这个形式,来表达 Context Engineering 的理念。
我们再重新看一下典型的 Skill 结构:
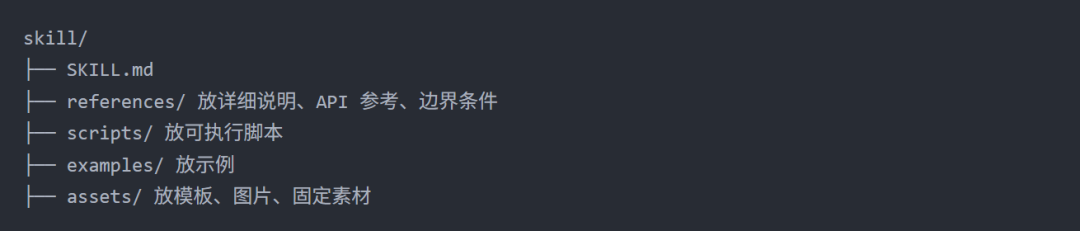
当调用某个 Skill 的时候,模型首先读取的是 SKILL.md。如果我们把所有的信息都塞进这个文件里,那很快就会上下文爆炸。 假设这是一个支付排障 Skill,里面既有 Stripe 的错误码说明,也有历史故障案例,还有排查脚本和最终报告模板。
如果这些内容全部堆进 SKILL.md,每次调用 Skill 的时候,Claude 都得重新读一遍。
哪怕用户只是想确认一个错误码的含义,哪怕只是想查看某个支付状态为什么没有更新。大量根本用不上的信息,也会被一起塞进上下文。
而 Anthropic 的思路完全不同。
SKILL.md 更像一个导航页。它的职责是告诉模型,遇到 Stripe 错误的时候,去 references 里找对应说明。
需要参考历史案例的时候,去 examples 里查类似问题,需要真正执行排查动作的时候,运行 scripts 里的脚本,最后生成排障报告时,再使用 assets 里的模板。
整个过程是渐进的暴露。下面这张图,强烈建议大家收藏。

03 尽量用脚本
不要让模型把有限的上下文和推理能力浪费在重复劳动上。把这些事情交给脚本。 举个例子。很多人写 Skill 的时候,会这样写:
-
查询注册数据;2. 查询付费数据;3. 计算转化率;4. 分析异常原因。
这种写法当然没问题。模型也能完成。但每次执行的时候,它都得从头把整个分析流程重新走一遍。
查询数据、整理数据、处理各种边界情况,这些工作其实都是重复的。
既然这些能力已经被验证过无数次。为什么还要让模型重新发明一次?不如直接提供具体的脚本。
而且通过脚本的方式, Skill 的执行也会更加准确,也更省 Token。
从这个角度看,Skill 里的 Scripts 其实是在沉淀组织能力。
每一个脚本背后,往往都是团队过去踩过无数坑之后总结出来的最佳实践。
把这些能力固化下来之后。Claude 每次都能站在这些经验之上工作,而不是一次又一次从零开始。
所以我越来越觉得,Skill 中,Instructions 和 Scripts 解决的是两个不同层面的问题。
Instructions 提供的是经验和判断,Scripts 提供的是能力和执行。
举个例子,支付排障 Skill 里可能有这样一句:如果 Stripe 返回 200,不要直接认为支付成功,需要进一步检查 payment_events 表。
这属于 Instructions。因为这是经验,而 check_payment_events() 属于 Script,因为这是执行能力。
如果只有 Script,模型知道怎么查,但未必知道为什么查。如果只有 Instructions,模型知道应该查。但每次都得重新实现。 两者缺一不可。
04 Description 更像一个路由规则
很多人写 Skill Description 的方式天然就是错的。
因为大家习惯写成功能介绍。比如:PR Management Skill 帮助用户监控 PR 状态,处理 CI 问题,自动完成 Merge。
但问题在于,模型并不是通过功能去寻找 Skill 的,Claude Code 启动的时候,会先扫描所有 Skill 的名称和 Description。
然后根据用户当前的问题,判断应该加载哪个 Skill。
所以 Description 里最重要的信息,不是这个 Skill 能干什么,而是什么情况下应该加载它。
Description 其实承担着整个 Skill 的路由工作。
真实世界里,很少有人会说帮我调用一个 PR 管理工具。大家更可能说:帮我盯一下这个 PR、CI 又挂了之类。
所以一个好的 Description,应该尽量描述用户的意图,而不是罗列功能。
我甚至觉得可以用一个特别简单的方法检查。
写完 Description 之后,把整个 Skill 删掉,只保留这一行 Description。然后问自己:模型看到用户的问题之后,能不能知道什么时候该加载这个 Skill。
如果做不到,那概率还得继续改。
05 Skill 的管理和分发
还有一个是关于 Skill 的管理。
一个人用 Skill 的时候,这事其实很简单。自己写几个 Skill,自己维护,自己升级就行了。但我相信大部分团队后面都会遇到同一个问题。
当 Skill 从几个变成几十个,甚至几百个的时候,这些 Skill 应该怎么管理?怎么升级?怎么分发给团队成员?
Anthropic 在这方面的经验,我觉得挺值得参考。
团队规模比较小的时候,Skill 直接跟着代码仓库走。放在项目里的 .claude/skills 目录就行。大家共享同一套 Skill,也共享同一套工作方法。
但随着 Skill 数量越来越多,一个新的问题出现了。
Claude Code 启动的时候,会扫描所有 Skill 的名称和 Description,然后判断当前任务应该调用哪个 Skill。Skill 越多,路由成本就越高。
这也是为什么 Anthropic 后来开始做 Marketplace。但更有意思的是,他们管理 Marketplace 的方式。
很多公司遇到这种问题,第一反应往往是建立一套审批流程。谁写了 Skill,先提交申请;审核通过之后,再进入官方 Skill 库。我们内部之前也这样做过,但非常重。为了管理而管理 我发现人家 Anthropic 的组织就很轻巧。
让新的 Skill 先在小范围传播,让同事自己安装、自己试用。
如果越来越多人开始使用,说明这个 Skill 确实解决了某个真实问题。到了这个阶段,作者再提交到正式的 Marketplace。
所以他们没有先讨论 Skill 有没有价值,而是先让它接受真实使用场景的检验,用的人多了,自然就进入正式体系。这样留下来的 Skill,基本都是团队真正需要的 Skill。

《图解 Skill:AI 提效实战指南》
宝玉 | 著
知名 AI 应用专家宝玉结合自身实战经验,撰写了这本技能实操指南,旨在帮助读者将个人经验转化为智能体可执行的技能,摆脱“AI 工具人”困境,真正实现工作自动化。 作者手把手教你掌握:3 个单技能模板、1 条组合式写作工作流、1 套技能工程方法论、1 次从零开始完整迭代的技能项目实战。本书不绑定平台,扣子、Claude Code、OpenClaw 均可使用。也不要求读者具备编程基础,只要你想用 AI 提效,就可以通过本书学会技能,并立刻投入使用。