δ-mem用8×8在线矩阵为冻结大模型加入长期记忆,参数开销仅0.12%。
原文标题:一个8×8矩阵,让大模型「记住」长对话:Mind Lab联合NTU、复旦推出δ-mem,参数仅0.12%
原文作者:机器之心
冷月清谈:
论文将现有记忆方法归纳为文本记忆、外部通道记忆和参数化记忆三类,并指出它们分别存在上下文限制、工程复杂度、静态不可更新等问题。δ-mem的核心优势在于:参数仅占骨干约0.12%,显存开销接近原模型,同时能在持续交互中更新记忆。
实验基于Qwen3、SmolLM3等模型,在LoCoMo、MemoryAgentBench、HotpotQA等任务上取得提升,记忆密集型任务最高提升1.31倍。消融实验显示,即使移除原始历史上下文,仅保留8×8记忆状态,模型仍能恢复部分历史信息。不过,方法在更长周期、跨会话、多Agent场景中的稳定性和容量上限仍需进一步验证。
怜星夜思:
2、8×8矩阵真的能算“记忆”吗,还是只是某种任务相关的压缩特征?
3、这种动态记忆机制用在个人AI助手上,会不会带来新的隐私和安全问题?
4、δ-mem这类方法会不会改变Agent系统的架构设计?
原文内容

本研究由南洋理工大学、复旦大学、Mind Lab、上海交通大学、香港中文大学、香港科技大学(广州)联合完成。共同第一作者为雷京迪(南洋理工 / Mind Lab)和张迪(复旦 / Mind Lab),通讯作者包括 Soujanya Poria(南洋理工大学)。团队长期深耕参数化记忆与体验智能方向。
不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。
大模型的记忆问题,可能是 2026 年最难啃的硬骨头之一。随着 LLM 被部署到长期个性化助手、长周期 Agent 系统等场景,模型的生命周期不再只是简单的一问一答,而是要在持续交互中累积、更新、复用历史信息。
最直接的解决思路是什么?扩上下文窗口。
但这条路撞墙了。一方面,标准注意力的成本随上下文长度呈二次方增长;另一方面,即使把窗口扩到百万 token,模型也会出现 "context rot"—— 即上下文越长,性能反而越差。虽然现在很多产品宣称有百万 token 窗口,实际却并没有从根本上解决记忆问题。
刚刚,来自南洋理工大学、复旦大学、Mind Lab、上海交大、港中文、港科大(广州)的联合团队发布了一项重磅研究 ——δ-mem。他们用一个 8×8 的在线关联记忆状态,给冻结的 Transformer 骨干配上了真正的长期记忆能力,在记忆密集型任务上最高提升 1.31×,参数开销仅占骨干模型的 0.12%。

-
论文地址:https://arxiv.org/abs/2605.12357
-
代码:https://github.com/MindLab-Research/delta-Mem
现有记忆方案,三条路都有硬伤
研究团队首先做了一件事:从统一视角梳理现有的记忆机制。
在给定上下文窗口的情况下,所有记忆机制可以从两个维度刻画:记忆状态(如何存储历史信息)和记忆引导(存储信息如何影响骨干推理)。
按这个框架划分,现有方法分为三大范式:
文本记忆(TMM)
代表方法:MemGPT、MemoryBank、Mem0、RAG 等。
它们将历史信息显式存储为文本片段,再通过输入上下文注入模型。这类方法的优势在于灵活且无需修改架构,但受限于上下文窗口的长度上限,同时伴随检索噪声和信息压缩损失。
外部通道记忆(OMM)
代表方法:Memorizing Transformers、LongMem、MLP Memory 等。
它们将记忆放置在外部模块中,通过检索或编码器与骨干模型交互。模块化设计带来了工程上的灵活性,但也引入了额外的推理开销和集成复杂度,且外部记忆的表征可能与骨干的内部表征难以对齐。
参数化记忆(PMM)
代表方法:LoRA、Prefix-Tuning、ROME、MEMIT 等。
这些方法则将记忆编码到前缀向量或适配器参数中,与冻结骨干兼容且高效。但其本质是静态的 —— 一旦训练完成,参数就固定不变,难以适应动态变化的信息流。
研究团队指出:这些局限共同指向一个需求 —— 需要一种记忆机制,既能维护紧凑且动态演化的记忆状态,又能通过与骨干内部注意力计算紧密对齐的路径来引导推理。δ-mem 就是为这个需求而生。
δ-mem 核心思想:把历史压进 8×8 矩阵,直接参与注意力
δ-mem 的设计思路可以用一句话说清:
不在上下文里塞 token,而是把历史压缩进一个固定大小的在线状态矩阵,在每次生成时直接产生对注意力计算的低秩修正。
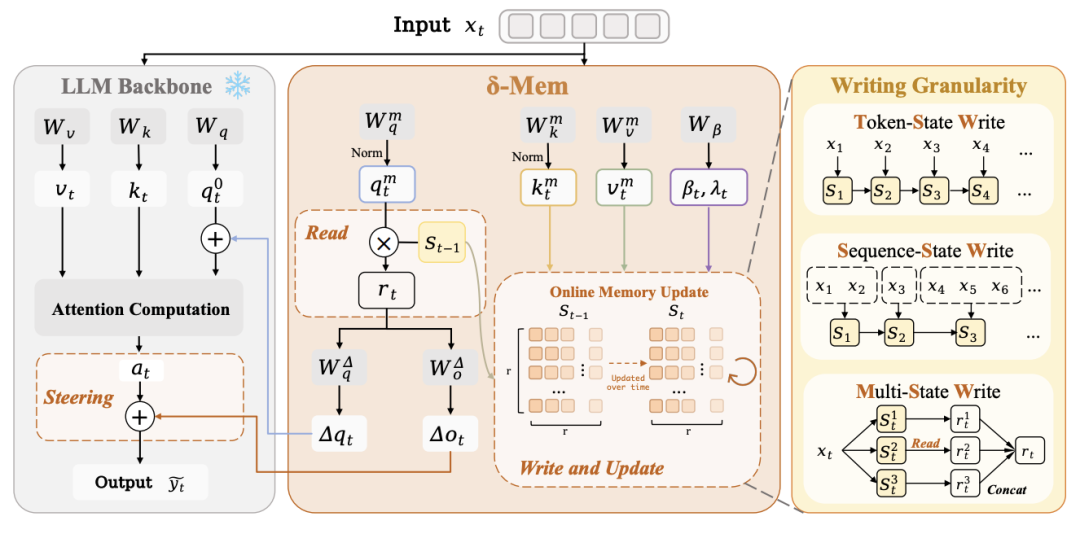
具体来说,在每个位置上,δ-mem 按相同顺序执行三步操作。第一步是读取(Read):从旧的关联记忆状态中读出与当前输入相关的信号。第二步是引导(Steer):利用读出的信号生成对注意力的低秩修正。第三步是写入(Write):通过 Delta-rule 学习规则将当前信息更新进状态矩阵。整个过程中骨干模型完全冻结 —— 不做全参微调、不换架构、不扩上下文。
关键技术 1:Delta-rule 学习的在线状态
δ-mem 将记忆建模为一个矩阵 S,充当关联记忆(Associative Memory)的载体。给定当前位置的 key-value 对,状态更新遵循如下公式:
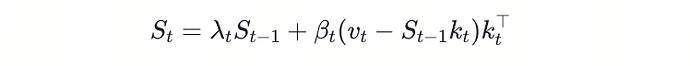
这条更新规则的直觉非常清晰:模型先用当前 key 去查询旧记忆,得到预测值 St−1;然后只将预测残差 —— 也就是「模型还没记住的部分」—— 沿 key 方向写入。已经学好的关联几乎不引起更新,而预测偏差会动态修正记忆状态。这种选择性写入机制使得 δ-mem 的状态能够在持续交互中稳定演化,而非被新信息无差别覆盖。
关键技术 2:低秩修正引导注意力
读出的关联记忆信号,通过两个轻量的线性映射分别生成 query 侧和 output 侧的修正量:
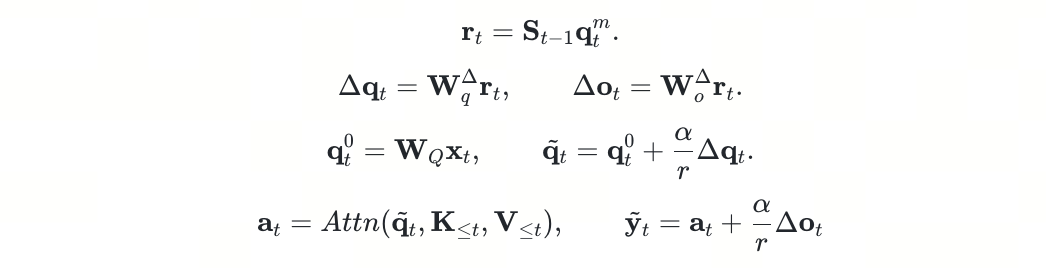
需要特别强调的是,这种低秩修正与静态适配器(如 LoRA)存在本质差异。LoRA 的低秩更新矩阵在推理时是固定的,而 δ-mem 虽然映射参数 本身不变,但其输入来自动态演化的状态 ![]() 。这意味着同一组参数在不同历史条件下能产生完全不同的引导效果 —— 参数是静态的,但记忆引导是动态的。因此同一组参数在不同历史下能产生完全不同的引导效果。
。这意味着同一组参数在不同历史条件下能产生完全不同的引导效果 —— 参数是静态的,但记忆引导是动态的。因此同一组参数在不同历史下能产生完全不同的引导效果。
关键技术 3:三种写入粒度
δ-mem 研究了三种写入策略:

实验结果:8×8 矩阵碾压一众基线
研究团队在 Qwen3-4B-Instruct 上进行了系统对比实验。基线方法覆盖了三大记忆范式的代表性工作:文本记忆类的 BM25 RAG、LLMLingua-2、MemoryBank,参数化记忆类的 Context2LoRA、MemGen,以及外部通道记忆类的 MLP Memory。测试基准涵盖通用能力评估(IFEval、HotpotQA、GPQA-Diamond)和记忆密集型任务(LoCoMo、MemoryAgentBench)。
主结果:全方位领先
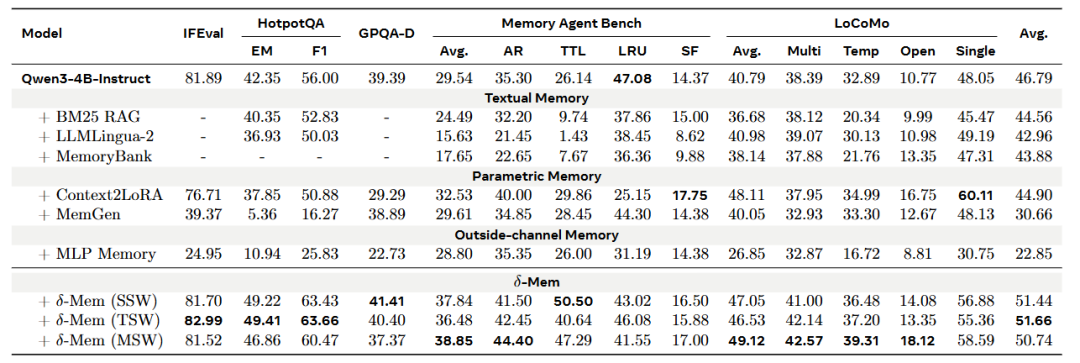
δ-mem 相比骨干模型平均提升 1.10 倍,相比最强非 δ-mem 基线提升 1.15 倍。在记忆密集型任务上的优势尤为突出:MemoryAgentBench 得分从 29.54 提升至 38.85,达到 1.31 倍;LoCoMo 从 40.79 提升至 49.12,达到 1.20 倍;其中 TTL 子任务从 26.14 直接翻倍至 50.50。在通用多跳推理任务 HotpotQA 上,EM/F1 也从 42.35/56.00 提升至 49.41/63.66。
跨骨干验证:从 3B 到 8B 都 work
δ-mem 在三个不同规模的骨干模型上都带来了显著提升。Qwen3-4B-Instruct 的综合得分从 46.79 提升至 51.66,Qwen3-8B 从 47.20 提升至 50.86,SmolLM3-3B 从 26.08 提升至 36.96。
值得关注的是,最优写入策略与模型容量存在交互关系。对于推理能力更强的 Qwen3-8B,段级写入(SSW)效果最好 —— 平滑的状态更新能有效减少逐 token 的噪声积累。而对于容量较小的 SmolLM3-3B,多状态并行写入(MSW)带来了最大提升(+10.88),因为分离的记忆状态减少了异质信息之间的干扰。这一发现为不同规模模型的部署提供了实践指导。δ-mem 在三个不同规模的骨干模型上都带来了显著提升。Qwen3-4B-Instruct 的综合得分从 46.79 提升至 51.66,Qwen3-8B 从 47.20 提升至 50.86,SmolLM3-3B 从 26.08 提升至 36.96。
关键消融:8×8 矩阵真的 "记住了" 吗?
研究团队设计了一组特别有说服力的实验来验证记忆状态的信息承载能力。实验设置非常激进:直接删掉原始历史上下文,只注入压缩后的 8×8 记忆状态,观察模型能否仍然正确回答问题。
设置非常激进:直接删掉原始历史上下文,只注入压缩后的 8×8 记忆状态,看模型还能不能回答问题。
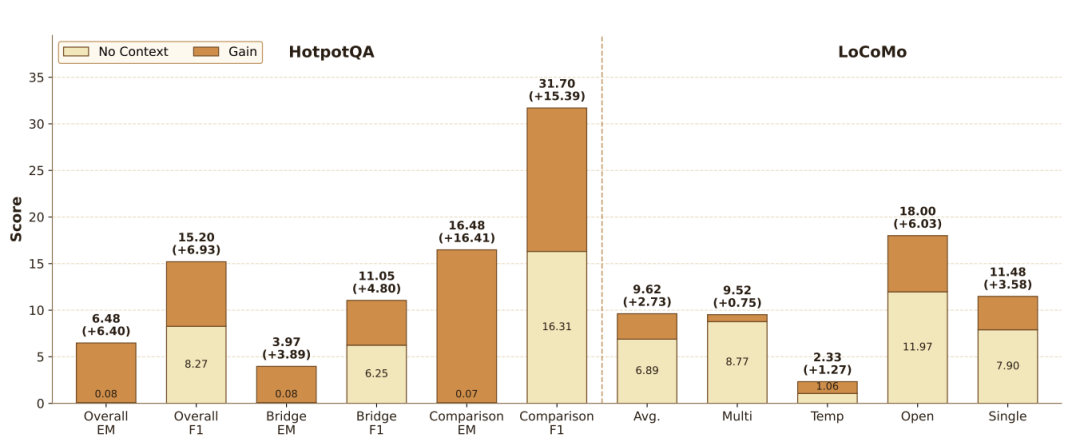
结果颇为惊人。在 HotpotQA 上,EM 从 0.08% 提升至 6.48%,F1 从 8.27% 提升至 15.20%。在需要多跳推理的 Bridge 子集上,EM 从 0.08% 提升至 3.97%,F1 从 6.25% 提升至 11.05%—— 模型能从压缩状态中恢复部分多跳推理所需的证据链。LoCoMo 上的整体平均得分则从 3.49% 提升至 8.05%,多跳、时序、开放、单跳问题均有提升。这组实验证实了一个重要结论:8×8 的在线状态确实编码了与上下文相关的历史信号,可以在显式上下文不可用时被有效复用。
Heads 消融:低秩修正注入哪里最有效?
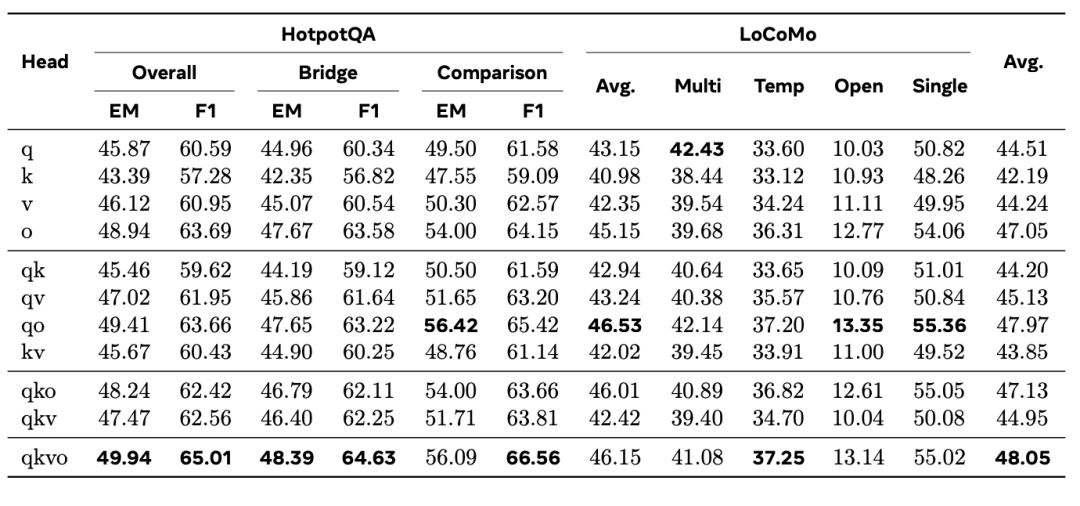
研究团队系统对比了在注意力模块的 q/k/v/o 各分支注入低秩修正的效果。在单分支注入中,output 分支最为有效(47.05)。双分支组合中,q+o 的表现最好(47.97)。四分支全注入虽然平均分最高(48.05),但相比 q+o 的边际增益不足以抵消额外的参数开销。因此,δ-mem 默认采用 q+o 组合,在性能与效率之间取得了最优平衡。
插入深度消融:哪些层最关键?
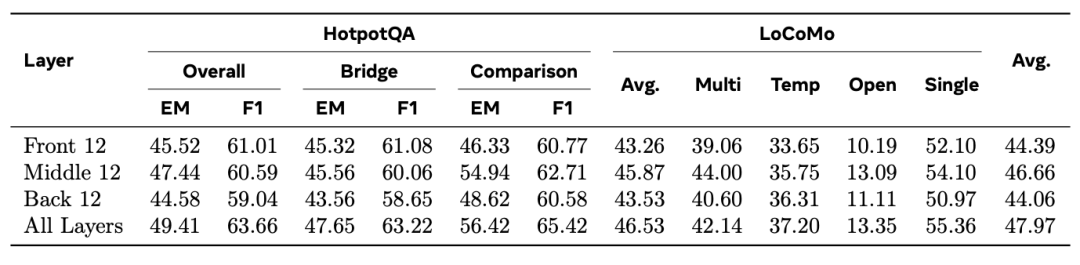
全层注入效果最佳(47.97),而在部分层注入的实验中,中间层的贡献最为显著 —— 它平衡了语义抽象与任务特定计算之间的关系。前层注入作用于过于局部的低层表征,难以承载高层语义关联;后层注入则留给关联记忆信号传播和整合的深度不够。
效率与开销:极致轻量
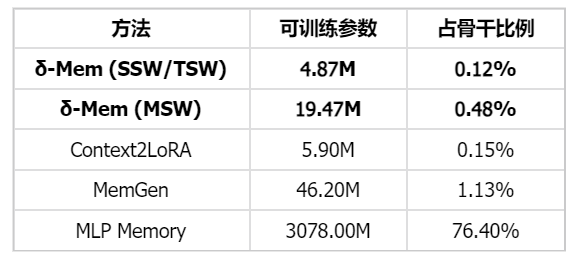
δ-mem 的参数开销极为紧凑。在 Qwen3-4B-Instruct(3.6B 参数)上仅引入 4.87M 额外参数,占比 0.12%。随着骨干规模增大到 Qwen3-8B(8.2B 参数),额外参数为 9.65M,占比仅 0.10%。
参数开销:
推理效率:
δ-mem 的 GPU 内存占用与 Vanilla、Context2LoRA 几乎相同 —— 即使 prompt 长度扩到 32K,紧凑递归状态几乎零额外开销:
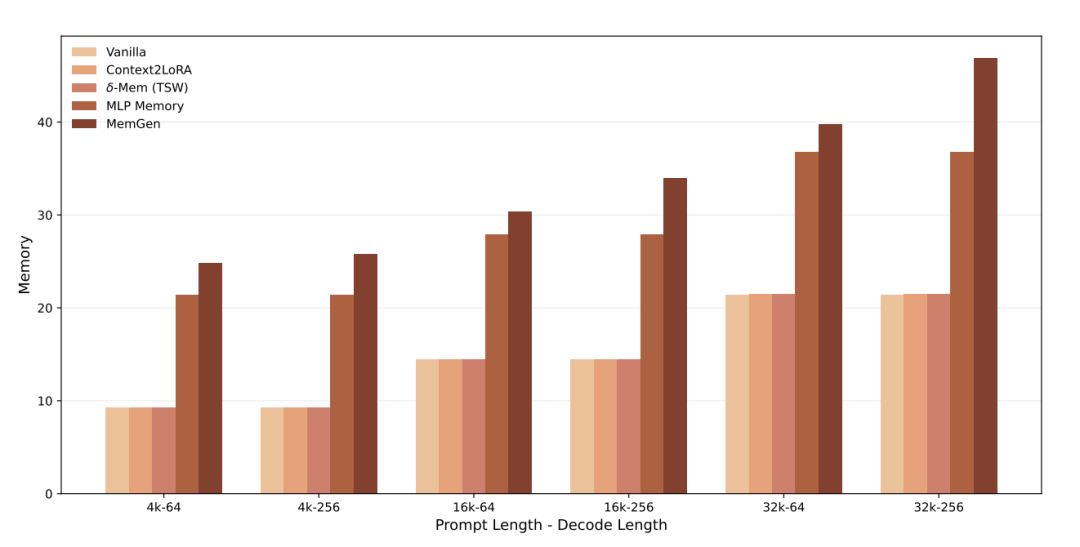
解码吞吐方面,δ-mem 略慢于 Vanilla(每步需读写在线状态):
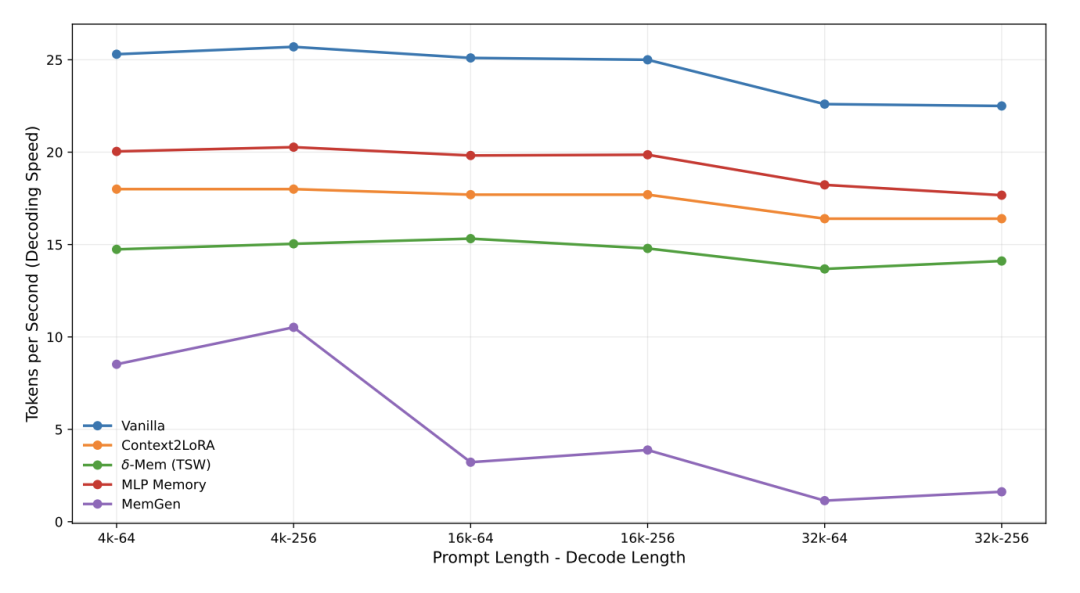
在推理效率方面,δ-mem 的 GPU 显存占用与原始模型和 Context2LoRA 几乎相同。即使 prompt 长度扩展到 32K token,由于记忆状态是固定大小的紧凑递归结构,几乎不引入额外显存开销。解码吞吐量方面,δ-mem 略慢于原始模型 —— 每步需要执行读写在线状态的操作 —— 但差距在工程可接受范围内。
这项研究意味着什么?
δ-mem 提供了一个值得关注的新视角:有效的长期记忆不一定要靠扩展显式上下文或部署重型外部检索模块。紧凑的在线状态,当与注意力计算直接耦合时,可以成为冻结 Transformer 骨干进行测试时记忆的可扩展、高效接口。
从学术角度看,δ-mem 提出的「记忆状态 × 记忆引导」统一框架为理解和设计记忆机制提供了清晰的坐标系,而 δ-mem 本身在这个框架下开辟了一条新路径 —— 紧凑动态状态与低秩注意力修正的结合。从工程落地角度看,8×8 的状态矩阵、4.87M 的参数量、与现有 Transformer 架构的完全兼容性,意味着给已部署的模型「加装」长期记忆变得切实可行。对于当前快速发展的 Agent 生态而言,长期个性化助手和长周期 Agent 的记忆瓶颈一直是核心痛点。δ-mem 在 TTL 子任务上从 26.14 翻倍至 50.50 的结果,预示着这条路径具备可观的工程潜力。
不过,也需要保持审慎。当前的验证主要集中在数千到数万 token 量级的交互场景,δ-mem 在更长周期(数十万 token 甚至跨会话)的持续学习场景中表现如何,仍有待进一步检验。此外,8×8 的固定状态维度是否存在信息容量的天花板,以及在更复杂的多轮 Agent 交互中记忆状态的退化特性,都是值得后续研究探索的问题。
值得一提的是,Mind Lab 一直深耕 LoRA 和参数化记忆方向,此前已完成业界首个 1T LoRA-RL、修复 MoE 强化学习 Router Replay R3 关键 Bug 等工作。δ-mem 延续了团队对「体验智能」(Experiential Intelligence)的核心愿景 —— 构建能从真实交互中持续学习的 AI 系统。
-
论文链接:https://arxiv.org/abs/2605.12357
-
代码仓库:https://github.com/declare-lab/delta-Mem & https://github.com/MindLab-Research/delta-Mem
对于关注大模型长期记忆、Agent 持续学习、参数高效微调的研究者和工程师来说,这篇论文值得大家仔细阅读。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com