开源大模型正围绕长上下文与显存效率进行底层架构升级。
原文标题:2026 年开源大模型架构全复盘:显存暴省,DeepSeek V4 与 Gemma 4 这波底层神进化,我彻底看呆了……
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、Gemma 4 的跨层 KV 共享会牺牲一部分模型容量,这种“省显存换精度”的取舍你能接受吗?
3、DeepSeek V4 这类架构越来越复杂,普通开发者还有必要深入理解底层机制吗?
4、这些架构优化看起来都在降低推理成本,未来开源模型会不会更适合个人电脑和边缘设备?
原文内容
新一代开源大模型的架构正将重心转向长上下文处理效率的提升。
随着推理模型与 Agent 工作流需要处理的 Token 数量与留存时间不断增长,KV缓存大小、内存流量以及注意力计算成本迅速成为了阻碍性能提升的核心瓶颈。为了打破这一限制,开发者们正不断引入各种架构上的技巧。
本文作者 Sebastian Raschka,是《从零构建大模型》《大模型技术 30 讲》等畅销书的作者,这篇文章他将重点拆解几个典型案例:Gemma 4 的 KV 跨层共享与逐层嵌入、Laguna XS.2 的层级注意力预算、ZAYA1-8B 的压缩卷积注意力,以及 DeepSeek V4 的 mHC 机制与压缩注意力。
虽然在这些架构图中,上述变动看似只是细微的调整,但其中蕴含的设计逻辑相当精妙,值得我们跟着作者一起进行一次深度的技术复盘。
本文篇幅较长,建议码后仔细阅读。
这张图展示了4月至5月间发布的主流开源大模型架构
KV 跨层共享:实现缓存空间的有效缩减
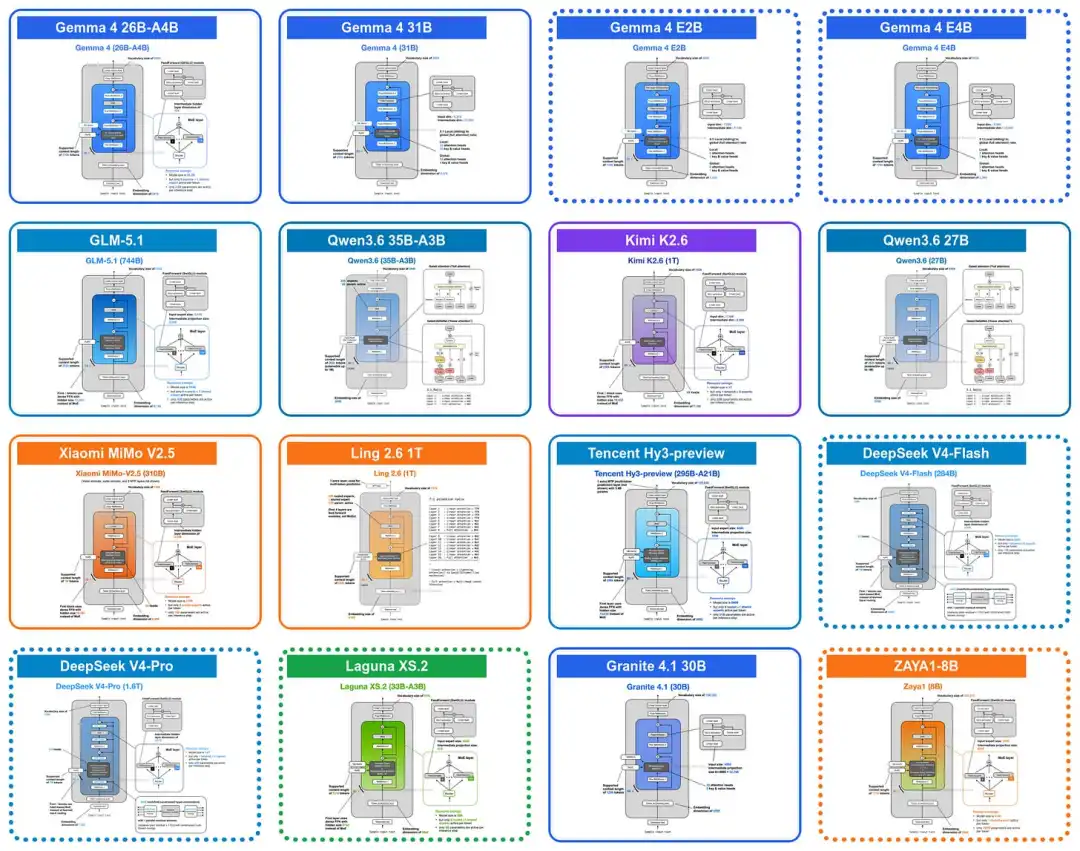
在近期的架构演进调研中,我们将视角回溯至 4 月初发布的 Gemma 4 模型套件。该系列涵盖了针对移动与边缘设备(IoT)的 E2B 与 E4B 模型、针对高效本地推理的 26B 混合专家模型,以及追求最大模型性能、利于后训练优化的 31B 密集模型。
这张图展示了Gemma 4 模型架构
在 E2B 和 E4B 变体中,第一个值得关注的微小架构调整在于它们引入了共享 KV缓存方案。简单来说,后续层会复用早期层的键值状态,从而大幅降低长上下文处理时的内存占用与计算开销。
这种 KV缓存共享并非 Gemma 4 的原创技术。此前已有学术界探索,如 Brandon 等人在 NeurIPS 2024 发表的《Reducing Transformer Key-Value Cache Size with Cross-Layer Attention》一文。但 Gemma 4 是我见过的首个将此概念落地于主流开源架构的模型。
为什么我们需要“缩容”KV缓存?内存占用越小,意味着我们能处理更长的上下文——在如今推理模型与智能体大行其道的时代,这正是性能竞争的关键。
关于 KV 缓存机制的更多背景,推荐阅读我的文章《Understanding and Coding the KV Cache in LLMs from Scratch》。而关于各类注意力变体的设计思路,此前发布的《A Visual Guide to Attention Variants in Modern LLMs》或许能为你提供更全面的视角。
让我们回顾一个经典案例:分组查询注意力(GQA,Grouped Query Attention)。它通过让多个查询头(Query heads)共享相同的键值头,从而实现了缓存规模的压缩。
具体逻辑如下图所示:
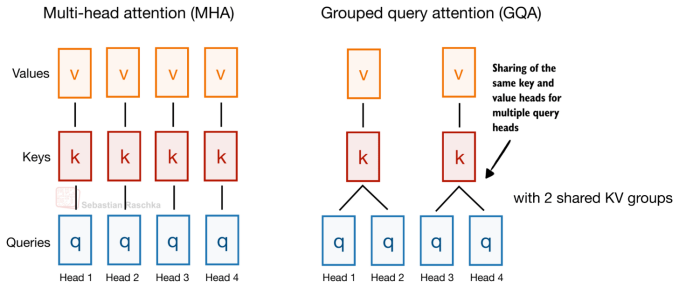
这张图展示了分组查询注意力 (GQA) 在多个查询头之间,共享相同的键值头
Gemma 4 在沿用分组查询注意力的基础上,带来了一项更激进的架构优化。它不仅在查询头之间共享 KV,还实现了跨层级的 KV 投影共享。这种机制跳过了在每一层注意力模块中重复计算的步骤,直接在层间复用 KV 投影。
这种设计被称为“KV 跨层共享”(Cross-layer Attention),传统的 Transformer 模块在每一层都要独立计算 Q、K、V 投影,而KV 跨层共享则实现了 K 和 V 投影的层间复用。
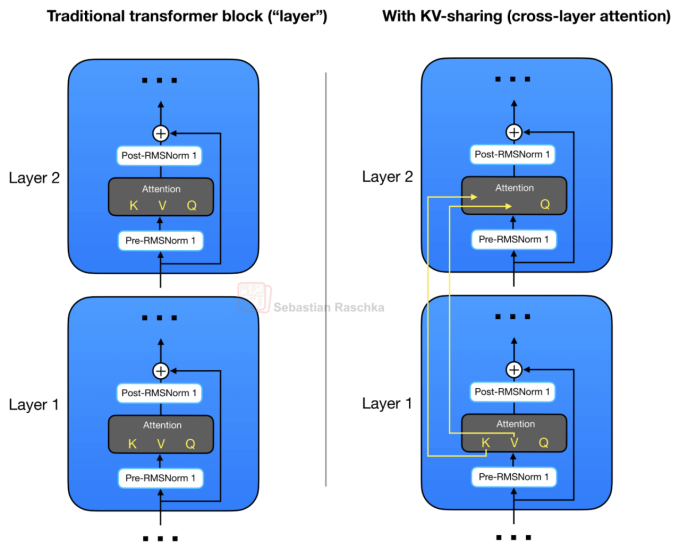
如图左所示,常规 Transformer 模块需要在每一个注意力模块中,对 Q、K、V 进行独立的投影计算。相比之下,如图右所示,跨层注意力设计采取了更高效的策略,它实现了K和V投影在多个层级间的共享
回溯Gemma 4 模型架构示意图,Gemma 4 E2B 在架构上采用了常规 GQA 与 4:1 比例的滑动窗口注意力。
在 GQA(或 MQA)架构下,KV 跨层共享的运作逻辑非常清晰,后续层不再独立计算 KV 投影,而是直接复用同一注意力类型中距离最近的非共享层的 KV 张量。这意味着滑动窗口层复用滑动窗口层的 KV,全注意力层亦然。虽然每层仍保留独立的查询投影以维持个性化的注意力模式,但原本沉重的 KV 缓存被有效地分摊了。
以Gemma4E2B 为例在35层Transformer 结构中,只有前 15 层负责计算 KV,余下的20 层直接复用最近层的 KV 张量。同理,Gemma4E4B拥有 42 层结构,其中 24层承担计算,后18 层执行共享。
通过这种“对半共享”策略,KV 缓存规模直接削减了约50%。在128K长上下文场景下,这一优化为 E2B 模型带来了2.7GB的显存节省,而 E4B模型则节省了约6GB。
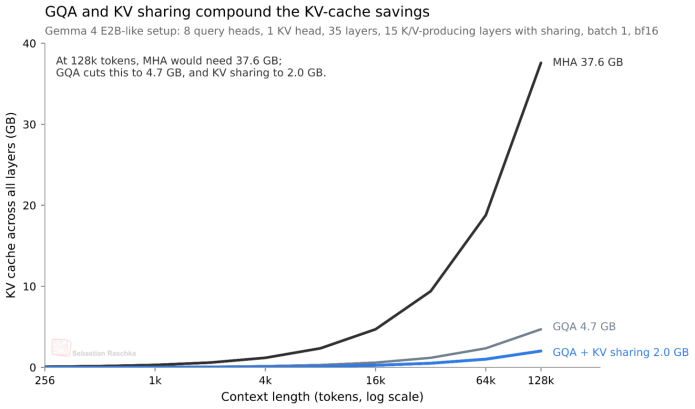
这张图展示了在类似 Gemma 4 E2B 的配置下,GQA 与跨层 KV 共享机制所带来的 KV 缓存显存节省
当然,凡事皆有代价。这种机制本质上是一种“近似”,在一定程度上会降低模型容量。不过,根据跨层注意力机制的相关论文结论,对于已测试的中小型模型而言,这种性能折损微乎其微。
逐层嵌入与“有效”规模
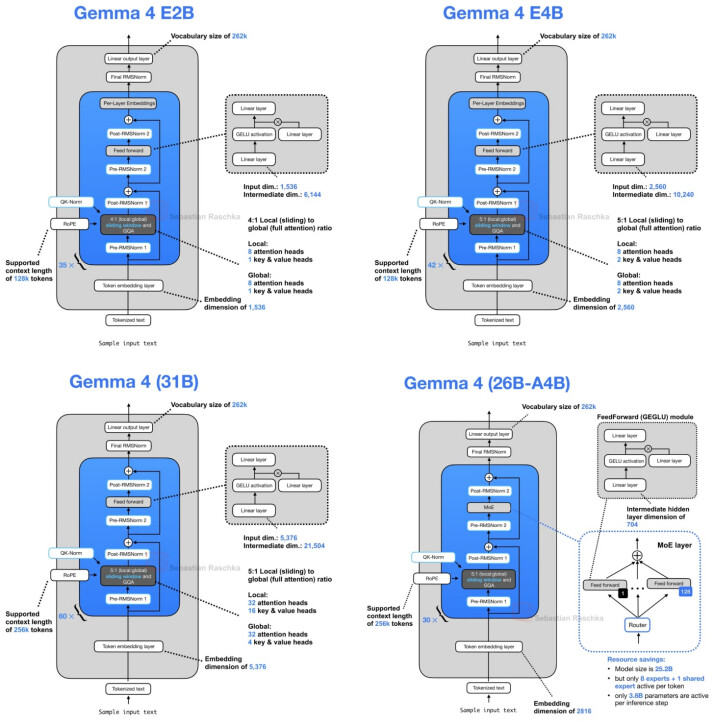
Gemma 4 的 E2B 与 E4B 变体引入了第二项效率优化设计:逐层嵌入(Per-Layer Embeddings, PLE),该技术与前述的 KV 共享方案彼此独立。
KV 共享旨在缩减 KV Cache,而逐层嵌入则侧重于参数效率(Parameter Efficiency)。该机制的优势在于,能够使小规模的 Gemma 4 模型利用更丰富的Token特征信息,同时避免了让主 Transformer 堆栈像同等参数规模的密集模型那样昂贵。
在 Gemma 4 E2B 与 E4B 中,“E”即代表“有效”(Effective)。具体而言:
-
Gemma 4 E2B:有效参数量为 2.3B,计入嵌入层后的总参数量为 5.1B。
-
Gemma 4 E4B:有效参数量为 4.5B,计入嵌入层后的总参数量为 8B。
简言之,在这些“E”系列模型中,主 Transformer 堆栈的计算量更接近于较小的数字,而较大的数字则包含了额外的嵌入表层。关于嵌入层如何运作,可参考《Understanding the Difference Between Embedding Layers and Linear Layers》一文。
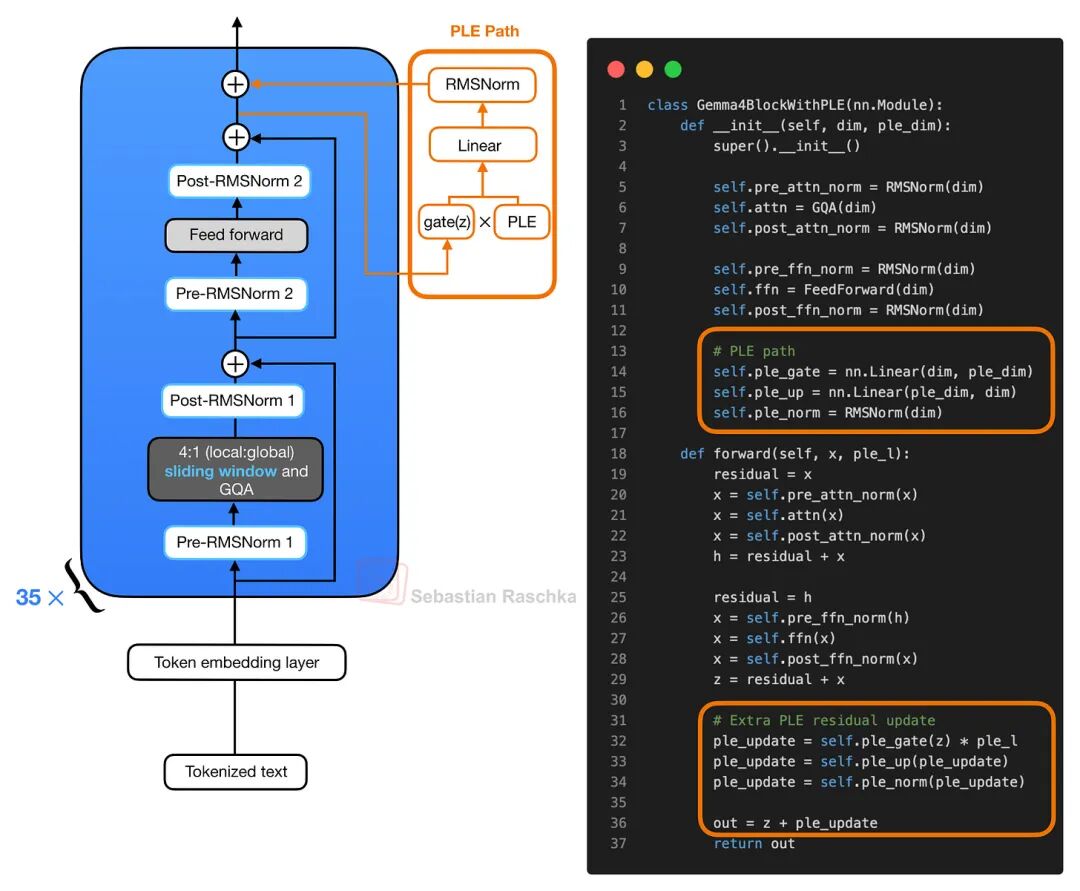
这张图展示了简化版 Gemma 4 模块与逐层嵌入残差路径设计。在该架构中,常规模块首先执行注意力与前馈残差更新。随后,产生的隐状态(hidden state)会对逐层嵌入向量进行门控,并将投影后的PLE更新作为额外的残差更新,在模块末尾进行累加
PLE 向量的构建过程位于重复的 Transformer 模块之外。简化来看,其构建涉及两个关键输入:Token ID 经过逐层嵌入查找,常规 Token 嵌入经过线性投影映射至统一的压缩 PLE 空间。这两部分数据经过相加、缩放与重塑,最终形成一个每层对应一个切片(slice)的张量。每个 Transformer 模块均会接收并应用其专属的切片数据。
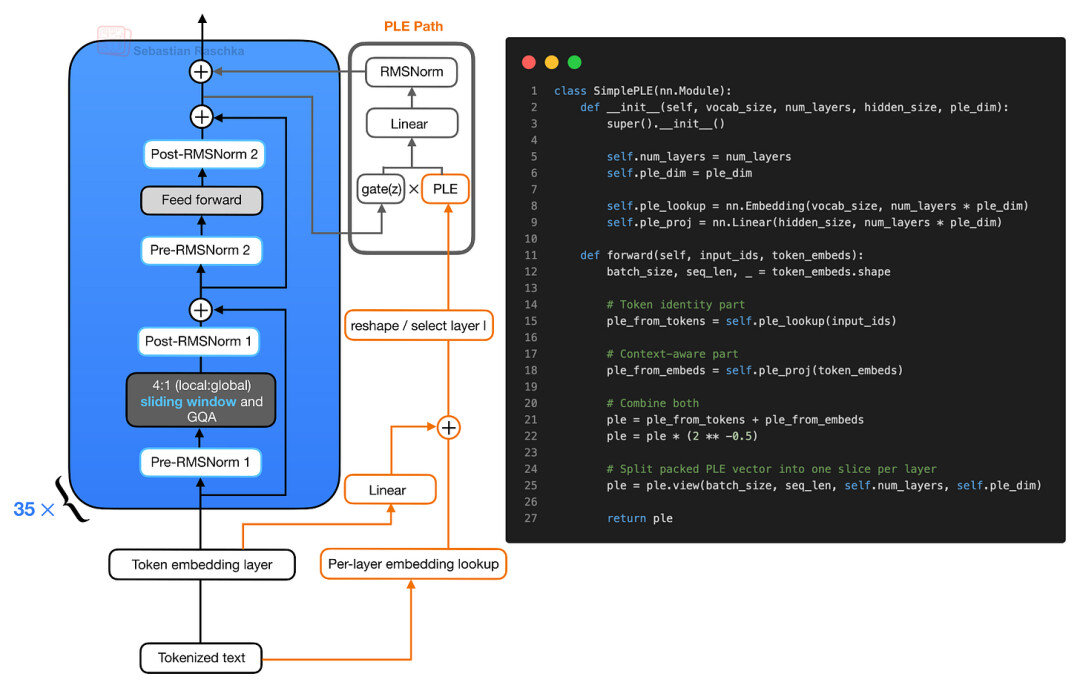
这张图展示了简化版 PLE 构建逻辑
需要强调的关键细节是:PLE 并非为每个 Transformer 模块分配一份完整的、独立的 Token 嵌入层副本。相反,系统只需执行一次逐层嵌入查找。正如前文所述,通过“重塑与层级选择”机制,每一层均能获得一个微小的 Token 特异性嵌入切片。
因此,针对每个输入 Token,Gemma 4 会预先准备一个封装好的 PLE 张量,其中涵盖了对应每个解码器层的微小向量。在前向传播阶段,第I层仅接收其专属切片。
在 Transformer 模块内部,注意力分支与前馈网络分支的运作逻辑保持常规。模块首先完成注意力残差更新,随后进行前馈网络残差更新。在完成第二次残差累加后,所得的隐状态将被用于门控(Gate)该层的特定 PLE 向量。这一经过门控的 PLE 向量随后会被投影回模型隐藏层维度,经过标准化处理,最终作为额外的残差更新项累加至系统中。
我们可以建立这样一个直观的认知模型:Transformer 模块的核心注意力与前馈路径保持不变,但 Gemma 4 在前馈分支之后,巧妙地引入了一个层级特定的微小 Token 向量。这种机制通过增加嵌入参数与微型投影层,显著提升了模型的表征能力。尽管这不可避免地带来了少量计算开销,但相比于将整个 Transformer 堆栈扩容至相同规模,这种方案极大程度地规避了参数量暴增带来的高昂计算代价。
为什么选择 PLE?最直观的替代方案是压缩密集模型,例如减少层数、缩减隐藏层维度或缩小前馈网络规模。虽然这确实能降低内存开销与延迟,但不可避免地会削弱模型核心计算区域的容量。
PLE 架构的精妙之处在于:它将高昂的 Transformer 模块维持在较小的“有效”规模,同时将额外的模型容量存储在逐层嵌入表中。 相较于盲目增加注意力机制或 FFN 权重,这种方式更为经济,因为它们本质上是更易于缓存的“查询式”参数。
当然,我们目前尚需基于 Google 的官方论述来评估这一设计的实际效能。若能开展针对性的对比研究,将 Gemma 4 E2B 架构与常规的 Gemma 4 2.3B 及 5.1B 模型进行横向测评,无疑会非常具有参考价值。
原则上,PLE 并不局限于小型模型。理论上我们可以在大型模型中添加逐层嵌入切片,但大型模型自身往往已具备充足的容量,额外的嵌入参数提升可能并不显著。此外,针对大型模型,业界已广泛采用 MoE(混合专家模型)架构,旨在以较小的计算成本实现容量扩展。
顺带一提,如果你对相关代码实现感兴趣,我已经在 GitHub 上从零构建了 Gemma 4 E2B 与 E4B 模型,代码逻辑力求简洁易读。
层级注意力预算
Poolside 是一家立足欧洲、专注于代码生成大模型训练的前沿企业,而 Laguna 正是其推出的首款开源权重模型。近年来,我的一些前同事陆续加入了 Poolside,这是一支极具天赋且技术底蕴深厚的专业团队。乐见更多公司拥抱开源浪潮,将自研模型以开源权重形式对外发布。
回归正题,从架构层面来看,下方展示的 Laguna XS.2 模型初看十分标准。然而其中有一个未在图中直观呈现的核心技术细节,即我们所称的“层级注意力预算”(Layer-wise attention budgeting)。
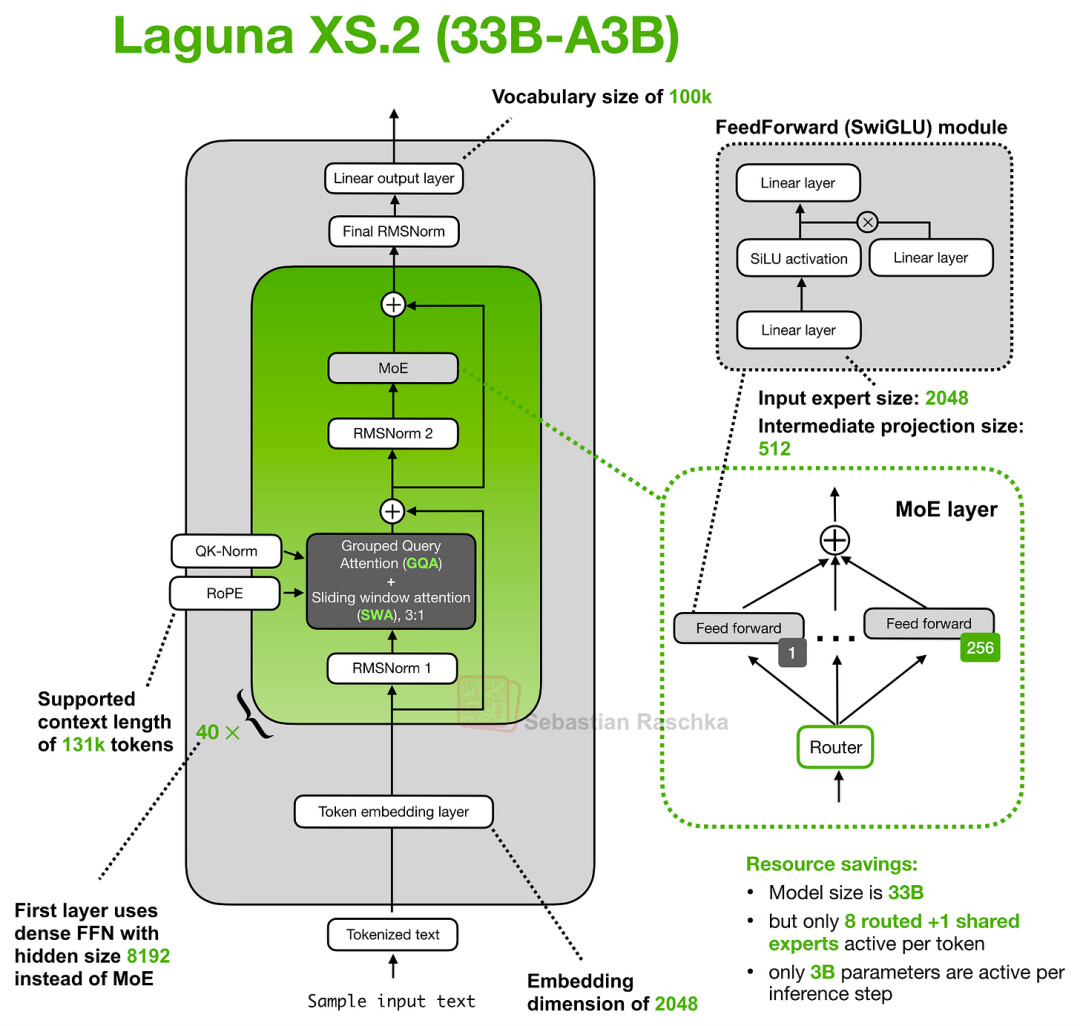
这张图展示了Poolside Laguna XS.2 模型架构解析。
Laguna XS.2 的注意力预算设计理念在于放弃了“一刀切”的均等化分配,转而根据层级差异动态调整注意力代价。模型架构包含 40 个层级,其分布策略如下:
-
滑动窗口注意力层(30 层):仅处理局部窗口信息(设定为 512 tokens),旨在降低 KV 缓存压力与计算开销。
-
全局/全注意力层(10 层):虽然计算代价更高,但保留了对整个上下文窗口信息的完整访问能力。
这种“滑动窗口 + 全局注意力”的混合模式并非 Laguna XS.2 独有,其真正的技术创新在于引入了逐层动态调整查询头数量的机制。通过配置 num_attention_heads_per_layer 参数,模型允许各层在维持 KV 缓存形状兼容的前提下,实现查询头数量的精细化适配。
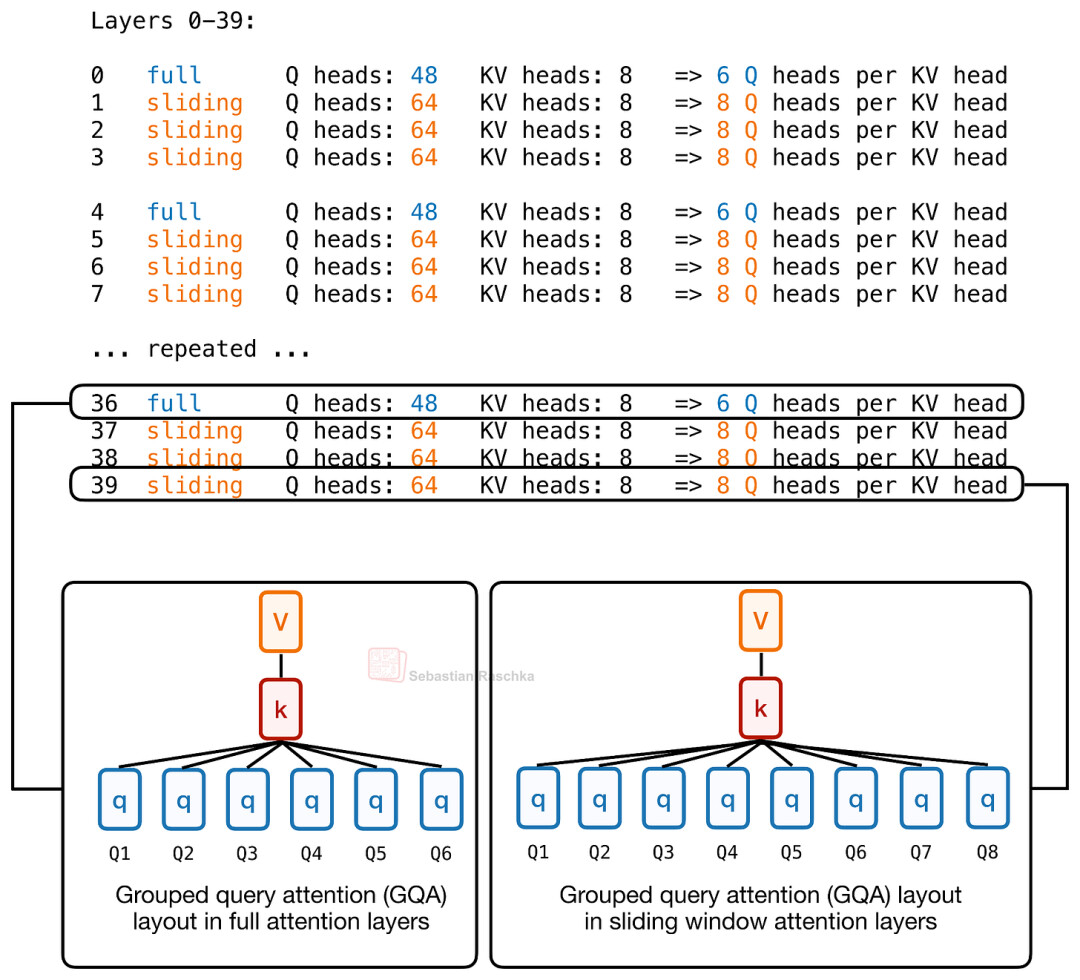
这张图展示了Laguna 在模型架构中创新性地引入了逐层查询头预算机制。在该配置下,全注意力层采用了“每 KV 头对应 6 个查询头”的分配方案;而滑动窗口注意力层则调整为“每 KV 头对应 8 个查询头”,从而在算力开销与模型表征能力之间实现了更精细的动态适配
简单来说,Laguna XS.2 通过差异化的分配策略,实现了真正的层级化头部预算(Layer-wise head budgeting)。在配置文件中,模型保持了 8 个 KV 头的固定配置,但在查询头的分配上做出了动态调整:滑动窗口注意力层被赋予了更多的查询头,而全局注意力层则配置较少。
Laguna XS.2 是近期生产级开源模型中,应用逐层查询头预算设计最显著的标杆案例之一。事实上,这种根据层级动态调整模型容量的理念并非孤例,其设计源头可追溯至 Apple 在 2024 年提出的 OpenELM 架构。
那么,这种设计的核心目的究竟为何?与 KV 共享机制如出一辙,其逻辑在于将注意力算力集中在最需要的地方,而非“一刀切”地为每一层分配均等预算。具体而言,全局注意力层因需要覆盖整个上下文,计算成本极高,因此 Laguna 选择通过减少查询头数量来抑制其资源消耗,从而将更多算力倾斜至滑动窗口注意力模块。
此外,还有一个值得注意的微观实现细节:Laguna 还采用了逐头注意力输出门控(Per-head attention-output gating)。这一设计与 Qwen3-Next 等模型有异曲同工之妙。
压缩卷积注意力
ZAYA1-8B 是开源模型市场中的又一位新晋选手,与前文提及的 Laguna 颇有几分相似。该模型由 Zyphra 开发,而此次发布中最值得玩味的一点在于:它的训练并非基于业界惯用的 NVIDIA GPU 或 Google TPU,而是完全在 AMD GPU 上完成的。
谈及核心架构细节,压缩卷积注意力(Compressed Convolutional Attention, CCA)与分组查询注意力的强强联合是其最大亮点。
与 MLA(多潜向量注意力)类设计主要将潜在表征作为紧凑的 KV 缓存格式不同,CCA 实现了质的突破:它直接在压缩的潜在空间内执行注意力运算——关于这一点,我们在后文中会有更深入的探讨。
观察 ZAYA1-8B 的 config.json 文件可以发现,它列出了 80 个交替的层条目,而非传统的 40 个 Transformer 块。这些条目在 CCA/GQA 注意力层与 MoE 前馈层之间交替出现。不过,为了架构图的可视化表现,将其抽象为 40 个重复的“注意力 + MoE”对,在概念上是完全等价的。
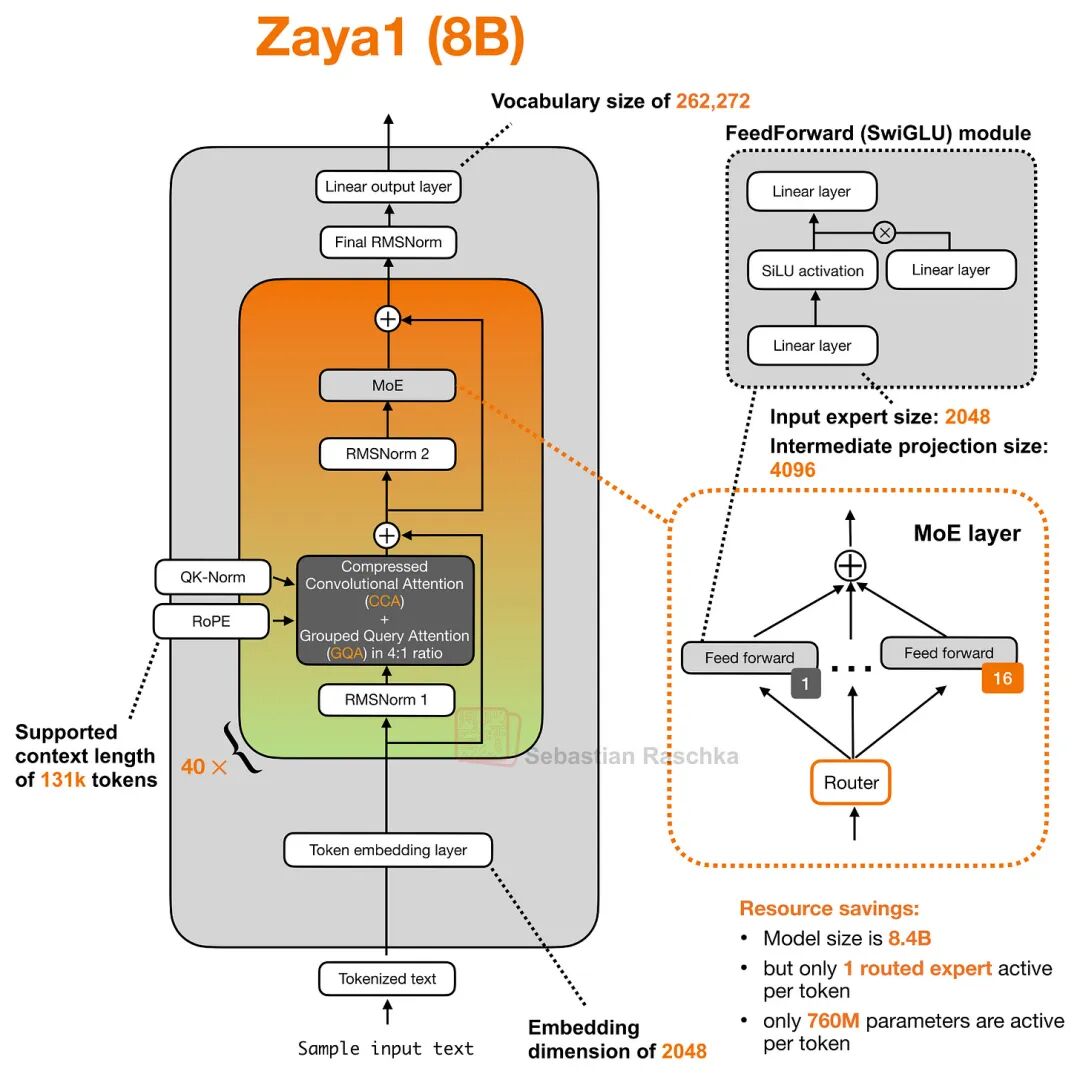
这张图展示了Zaya1 (8B) 模型:搭载集成压缩卷积注意力机制 (CCA)的 Transformer 模块
如上图所示,ZAYA1-8B 采用了压缩卷积注意力机制,并搭配了 4:1 的分组查询注意力布局。其核心架构亮点在于,注意力模块是围绕 CCA 构建的,而非采用传统的滑动窗口注意力模块。
那么,究竟什么是压缩卷积注意力(CCA)?从核心理念来看,CCA 与 DeepSeek 模型中采用的多头潜在注意力有异曲同工之妙,二者均在注意力模块中引入了压缩潜在表征(Compressed Latent Representation)。
然而,二者对这一潜在空间的应用逻辑截然不同。MLA 的主要目的是压缩 KV缓存,在 MLA 中,KV 张量以紧凑形式存储,随后被投影至注意力头空间,以执行实际的注意力计算。
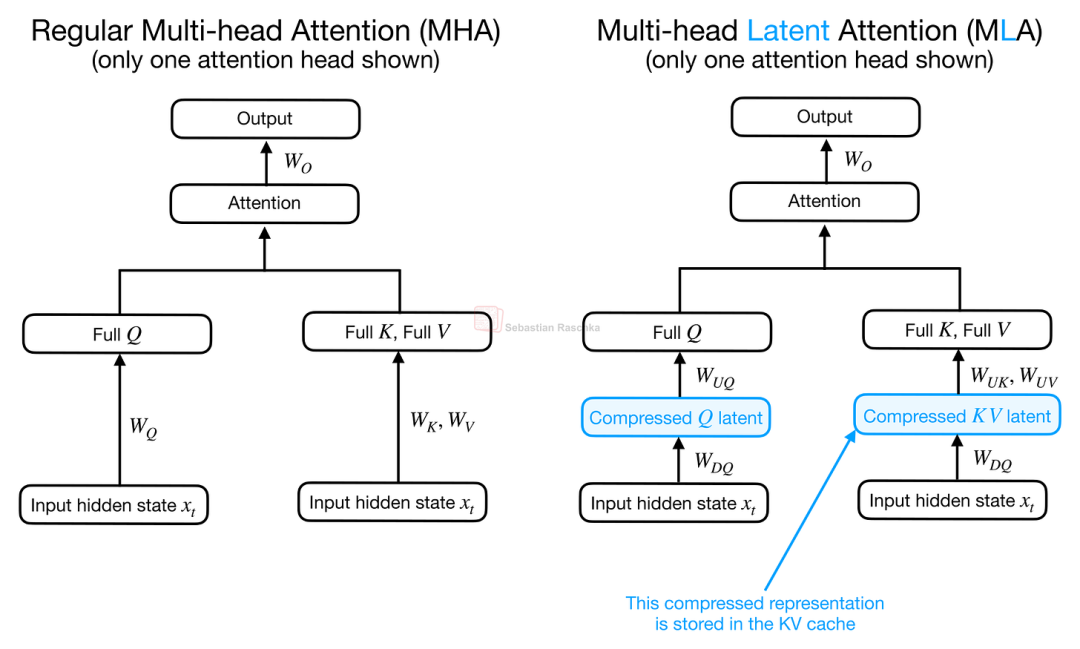
这张图展示了常规多头注意力 (MHA) 与多头潜在注意力 (MLA) 的架构并置对比
CCA 的核心逻辑在于它不仅仅是对 Q、K 和 V 进行压缩,而是直接在压缩后的潜在空间中执行注意力运算。
正因如此,CCA 不仅能够有效缩减 KV缓存的空间占用,还能显著降低模型在预填充(prefill)及训练阶段的注意力计算开销(FLOPs)。
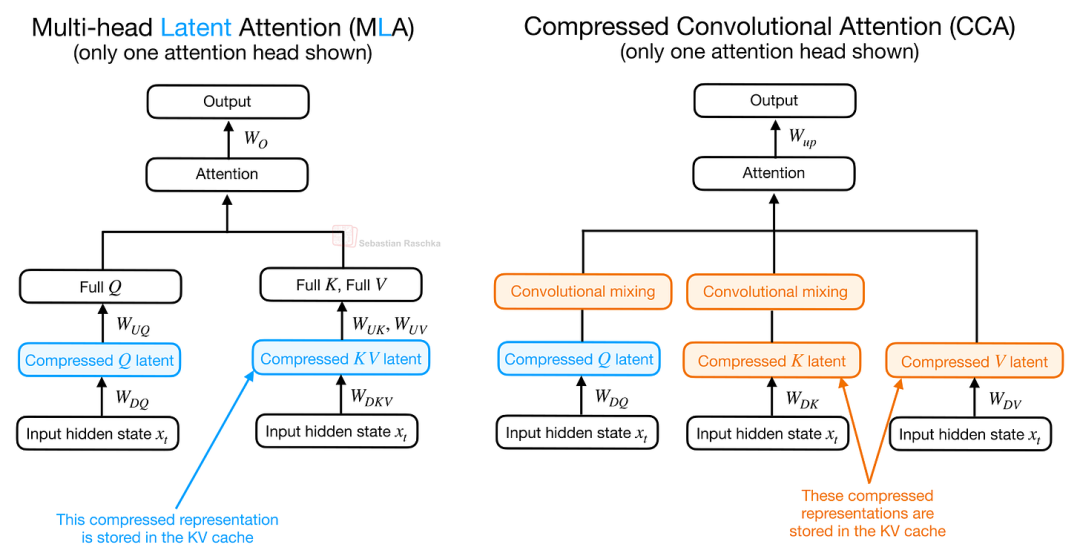
这张图展示了多头潜在注意力 (MLA) 与 压缩卷积注意力 (CCA)架构方案
如上图 所示,在 CCA架构中,经过压缩的潜在表征(Latent Representation)直接进入注意力机制参与运算。计算得出的压缩注意力向量,随后被执行上投影(Up-projected)操作,恢复至目标维度。
该机制之所以冠以“卷积”之名,在于其在潜在的 K 和 Q 表征上引入了卷积混合过程。
卷积混合直接作用于压缩后的 Q 和 K 张量。压缩的本质代价在于维度缩减——这虽然能显著节省计算资源并降低 KV缓存占用,但往往会牺牲注意力的表达能力。引入卷积,正是为了以极低的算力成本,在计算注意力得分前,为压缩后的 Q 和 K 向量注入更多的局部上下文信息。
(注:卷积仅作用于 Q 和 K,不对 V 进行处理。原因在于,Q 和 K 共同决定注意力得分的分布,而 V 仅是承载最终被加权平均的内容实体。)
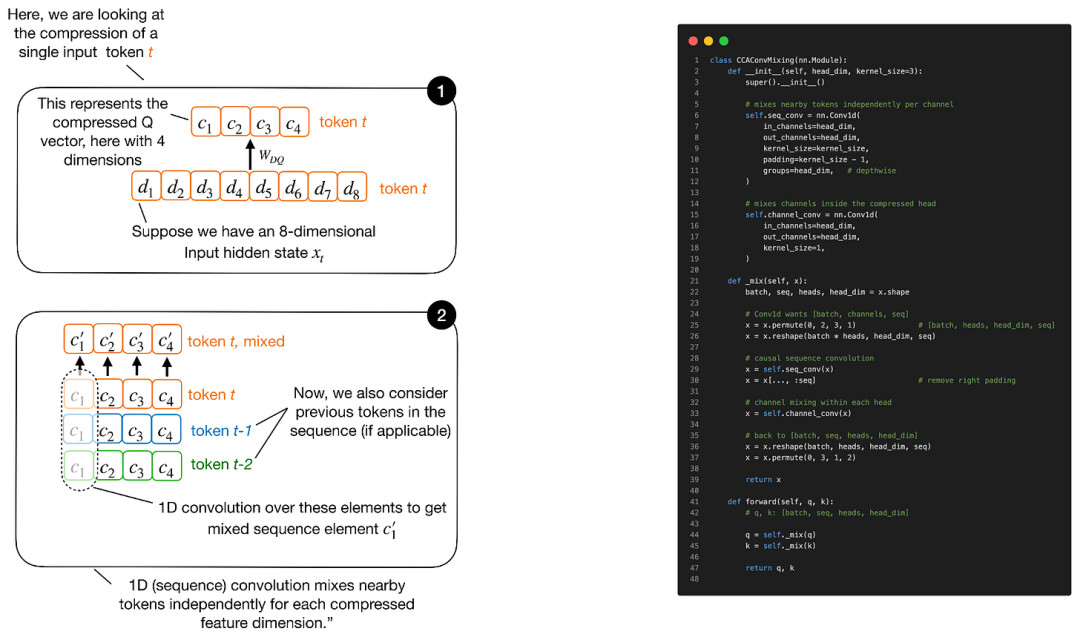
这张图片展示了序列混合卷积的原理概述
除了序列混合外,CCA 架构还引入了一个通道混合(channel mixing)组件。鉴于二者在原理上的高度同构性,此处不再赘述。
从技术溯源来看,CCA 并非随 ZAYA1-8B 的技术报告同步产出,而是由 Zyphra 团队先行定义。早在 2025 年 10 月发布的论文《Compressed Convolutional Attention: Efficient Attention in a Compressed Latent Space》中,CCA 概念便已正式确立,而 ZAYA1-8B 则是将该技术作为核心架构基石的一次重要工程实践。
那么,CCA 是否具备超越 MLA 的潜力?依据 CCA 原论文的实验结论:在同等压缩配置条件下,CCA 的性能表现确实优于 MLA。
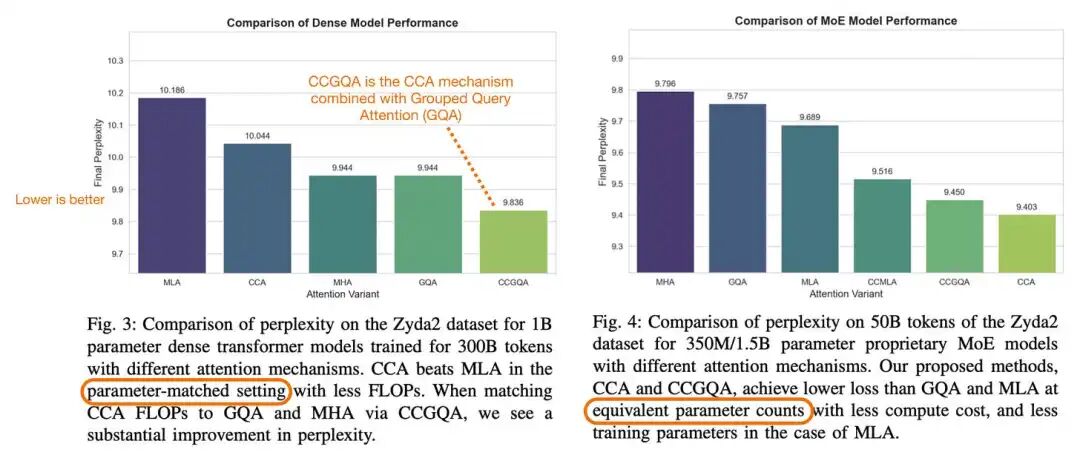
这张图片展示了CCA 论文https://arxiv.org/abs/2510.04476.中的注释图表
总结来看,ZAYA1-8B 最令人眼前一亮的,无疑是它那套全新的注意力机制。
该模型采用了极其稀疏的 MoE(混合专家模型)架构——每个 Token 仅激活一名路由专家。虽说这种设计在当下已非新鲜事,但其技术表现依然值得关注。
而 CCA 的引入,让它显得与众不同:它直接在压缩的潜在空间内完成注意力运算,并创新性地利用卷积混合(Convolutional Mixing)机制作用于压缩后的 Q 和 K 表征。这一巧妙设计有效弥补了压缩带来的信息损失,让模型即便在紧凑状态下,也能保持强劲的注意力表征能力。
简而言之,ZAYA1-8B 的技术野心远不止于前馈层(Feed-forward layers)的算力优化,它更进一步,将算力成本的削减触角延伸至了注意力机制的核心逻辑之中。
CSA/HCA、mHC 与压缩注意力缓存
DeepSeek V4 无疑是今年迄今为止最重磅的发布,无论是市场热度还是模型硬核规模,都处于行业顶尖梯队。值得玩味的是,若从“激活参数占比”这一关键指标来看,DeepSeek V4-Pro 堪称下表中参数稀疏度最高的 MoE 架构。
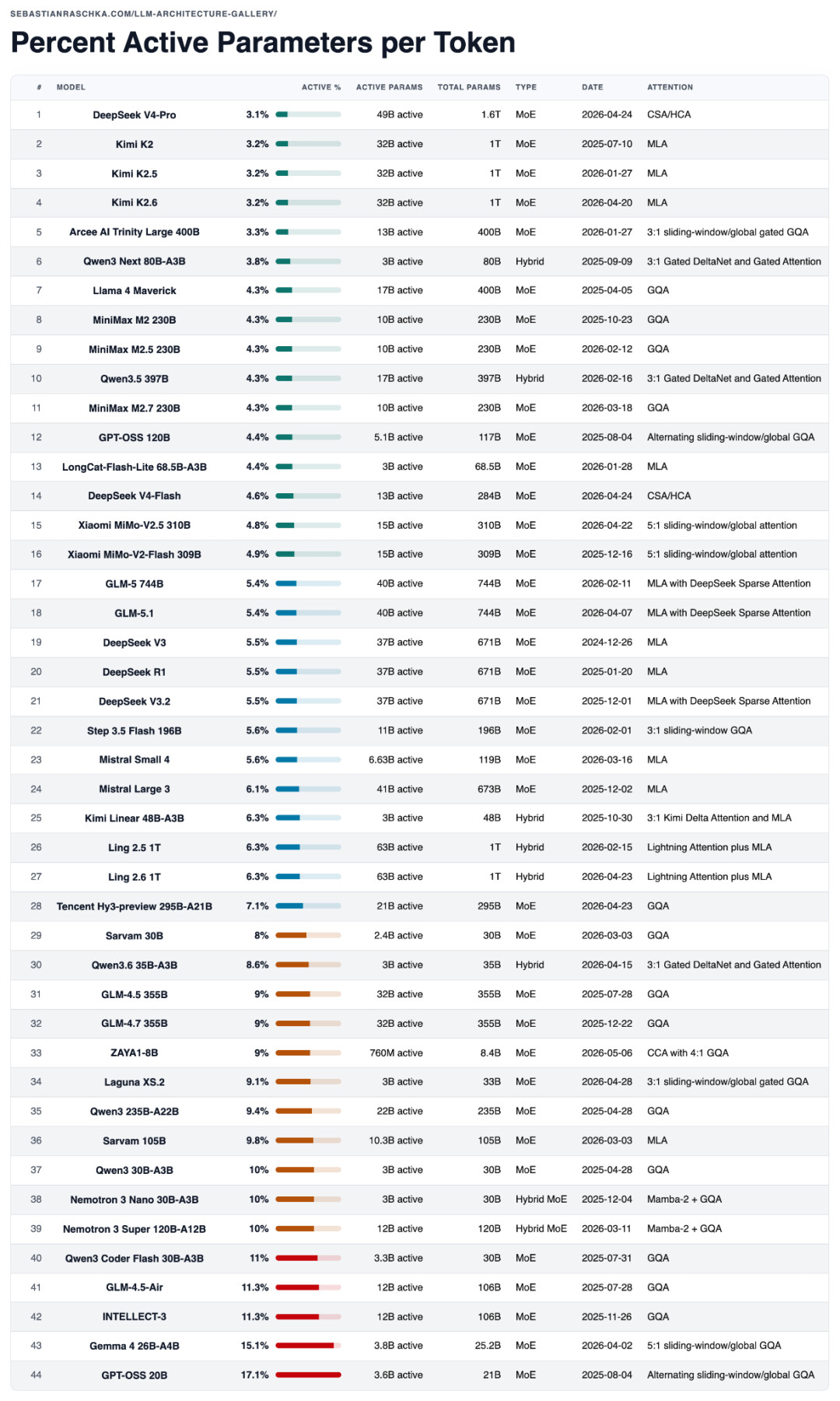
激活参数占比(Active parameter share)仅能作为观察模型的一个视角。它无法涵盖 KV缓存大小、注意力模式、上下文长度、路由开销、硬件效率或训练质量等深层因素。尽管如此,在横向对比稀疏模型时,这依然是一个高效且实用的快速评估指标。
关于 DeepSeek V4,外界讨论已铺天盖地。为了保持内容聚焦,我将略过冗余信息,直接切入与前代架构相比最具创新性的两点核心变革:
-
mHC:旨在构建更宽的残差路径。
-
CSA/HCA:用于实现长上下文的注意力压缩与稀疏化。
关注下方 DeepSeek V4 的架构图,信息量极大,直接阅读容易陷入细节陷阱。理解该架构的高效方式在于将其解构为两条主线:关注 mHC 带来的路径优化、关注 CSA/HCA 与压缩注意力缓存的协同作用。
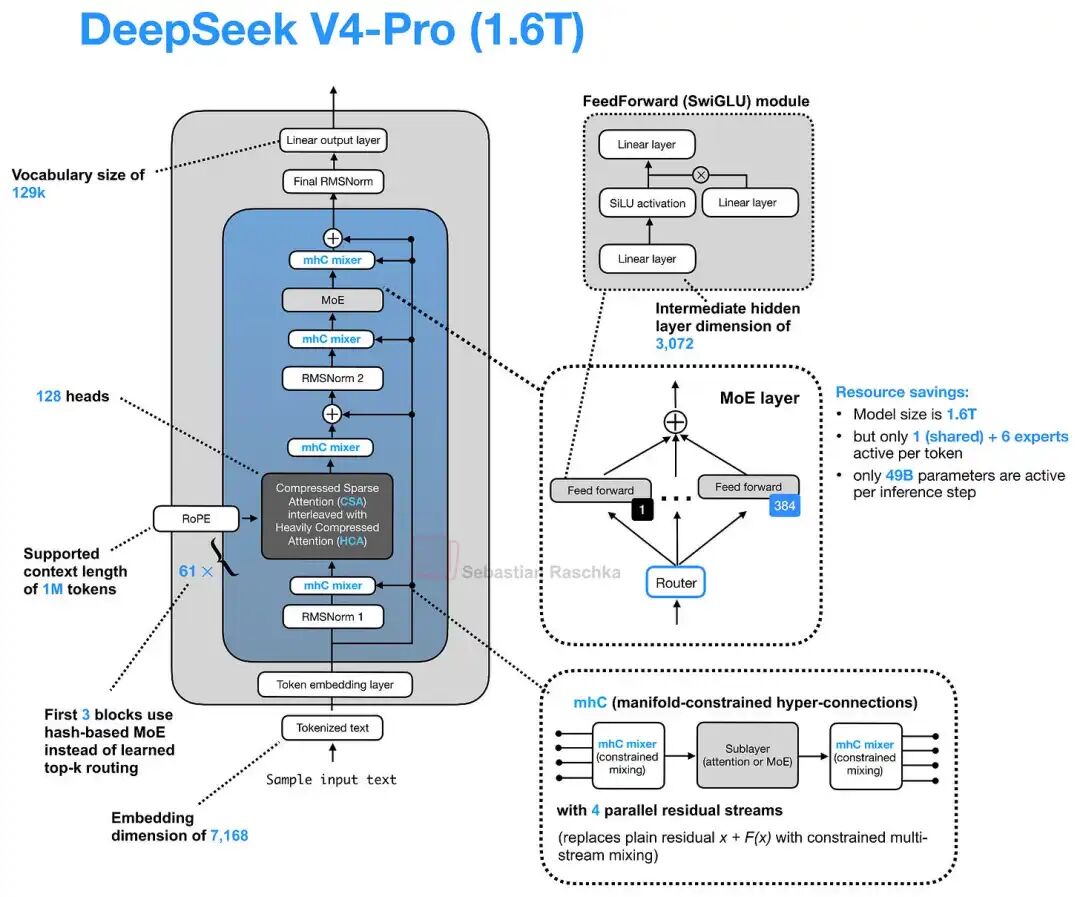
这张图片展示了DeepSeek V4-Pro 架构概览
1.流形约束超连接 (mHC):深度重构残差路径
我们先来拆解 DeepSeek V4 中的 mHC 组件。这项技术源自 DeepSeek 团队去年年底(2025年12月31日)发表的论文《mHC: Manifold-Constrained Hyper-Connections》。当时该技术仅在 27B 的实验性模型上进行了验证,而如今它已成功落地于旗舰级模型,这无疑是该方案在生产环境表现优异的有力佐证。
mHC 的核心在于对 Transformer 块内部残差连接(Residual Connections)的现代化改造。这在当下显得颇为“清流”,毕竟绝大多数架构优化仍聚焦于注意力机制、归一化层位置或 MoE 结构。
mHC 的设计思想承袭自 Zhu 等人 2024 年提出的 Hyper-connections(超连接)概念。简单来说,它通过引入多条并行残差流及其间的可学习映射,彻底重构了 Transformer 内部单一残差流的传统范式。
其核心逻辑在于“加宽”残差流。你可以将其想象为维护多条并行的残差流,并通过“Res Mapping(残差映射)”线性变换,实现各层级间的信息混合。由于 Attention 或 MoE 层本身仍基于标准隐藏层维度运行,因此 mHC 引入了两项关键操作:
-
Pre Mapping:将多条并行残差流合并为一个标准的隐藏向量,以供层内计算使用;
-
Post Mapping:将层输出重新分发回多条并行残差流中。
关于这一机制的运作,下图进行了直观的展示。
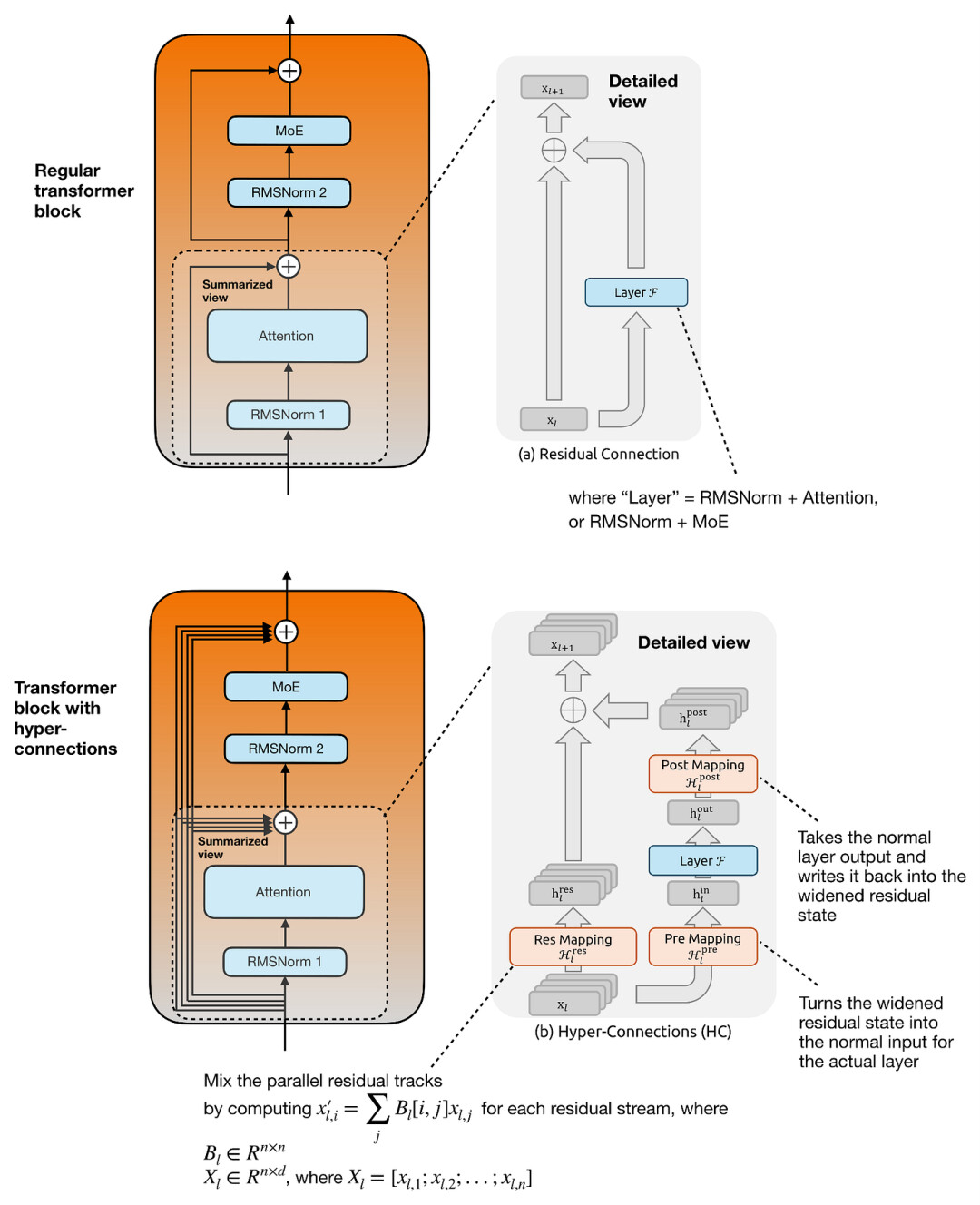
这张图展示了基于mHC 论文https://arxiv.org/abs/2512.24880.中的注释图,我们可以直观对比常规 Transformer 块(上图)与搭载超连接的 Transformer 块(下图)在架构设计上的核心差异
下图重点展示了 Transformer 块中注意力层部分的结构,但同样的原理也完全适用于 MoE 层周围的第二个残差分支。
超连接(Hyper-connections)的设计初衷,在于在不改变 Attention 或 MoE 层实际计算宽度的情况下,显著增强残差路径的表达能力。
这种机制带来的算力(FLOPs)开销极小。原因在于,额外的映射操作是基于较小的残差流轴进行的(以 DeepSeek V4 为例,n=4),而非在庞大的隐藏维度上展开。在原始的超连接论文实验中,7B 参数的 OLMo MoE 模型单 Token 计算量仅从 13.36G 微增至 13.38G,性能损耗几乎可以忽略不计。从实验结果来看,该机制也确实带来了稳健且小幅的性能提升。
(当然,仅仅关注 FLOPs 难免有些片面。加宽后的残差状态依然涉及存储、内存搬运以及混合计算等操作。因此,实际的系统开销可能更多源于内存带宽瓶颈和工程实现的复杂度,而非算术运算本身——这一点在论文中并未被显式度量。但鉴于 DeepSeek V4 对效率的极致追求,引入该机制显然是一项值得的改进。)
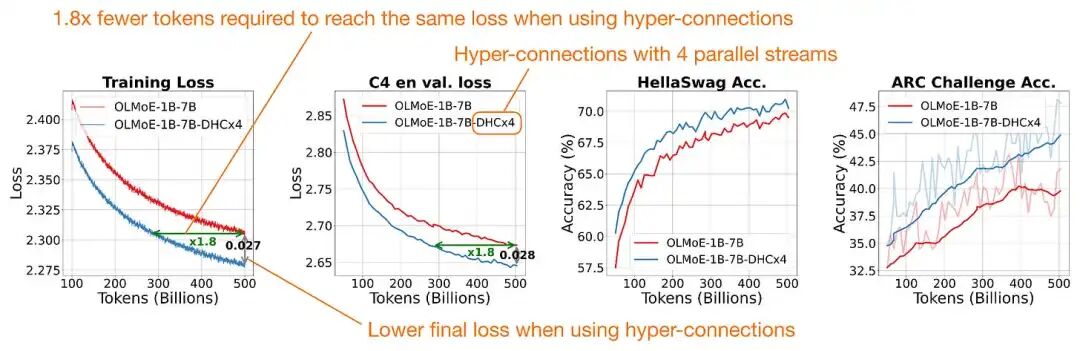
这张图展示了基于Hyper-connections原始论文https://arxiv.org/abs/2409.19606.研究数据,超连接架构与基准模型的性能对比
如图所示,该架构仅需约一半的训练 Token,便能达到基线性能水平。
相比常规的超连接(HC),流形约束超连接(mHC)的核心改进在于对映射关系的约束。在常规 HC 中,作为残差混合器的 Res Mapping 矩阵是完全可学习的。然而,随着网络层数堆叠,未经约束的映射极易导致信号出现不可预期的增益或衰减,进而影响模型稳定性。
mHC 将残差映射严格限定在双随机矩阵(Doubly Stochastic Matrices)流形之上——即矩阵所有元素均为非负,且每一行与每一列之和均恒等于 1。这一数学限制,本质上是将残差混合转化为一种稳定的信息重分布过程。同时,Pre Mapping 与 Post Mapping 层也引入了非负性与边界约束,有效规避了在读写加宽残差状态时可能发生的信息抵消问题。
简而言之,mHC 在保留 HC 丰富残差混合特性的同时,通过引入约束确保了模型在纵深扩展时的安全性与鲁棒性,这对于深层的大规模模型而言至关重要。
至于其核心架构,即并行残差流的设计思路,仍保持不变,详细示意图如下。
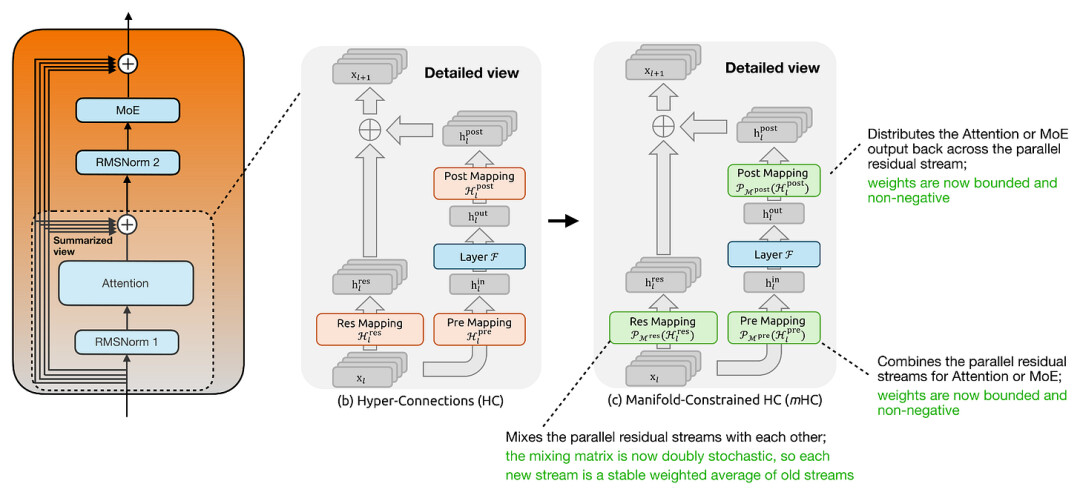
这张图展示了基于 mHC 论文https://arxiv.org/abs/2512.24880.提供的注释图,我们深入对比了 Transformer 模块在 HC与 mHC两种架构下的设计差异
根据 mHC 论文中的实验数据,DeepSeek 团队在 27B 参数模型上对其优化实现进行了验证。结果显示,在所有 Transformer 块中采用 4 条残差流(n = 4)架构后,其训练时间开销仅比传统的单流基线增加了 6.7%。
本节总结:HC/mHC 架构的核心在于以多个相互交互的残差流取代了单一残差流,从而彻底改变了信息在这些层间的传递逻辑。得益于 mHC 中引入的额外稳定性约束,该方案在保持极低算力开销的同时,显著提升了架构的稳健性。此外,该机制与 CSA/HCA 注意力优化方案高度兼容,两者相辅相成,共同作用于 Transformer 块的各关键部位,具体的细节分析我们将在下文展开。
2.借助 CSA 与 HCA 实现注意力压缩
DeepSeek V4 架构的另一项核心变革,则聚焦于注意力机制。
其背后的驱动力依然明确:在超长上下文场景下,注意力机制的开销激增——这不仅源于注意力分数计算本身,更在于随着序列长度增长,KV缓存的显存占用也随之迅速膨胀。为此,DeepSeek V4 巧妙地引入了一套混合压缩注意力机制,通过结合压缩稀疏注意力(Compressed Sparse Attention, CSA)与重度压缩注意力(Heavily Compressed Attention, HCA),有效地化解了这一计算瓶颈。
如果需要回顾相关背景知识,推荐阅读我此前的文章《现代大模型注意力变体可视化指南》。其中详细拆解了多头潜在注意力(MLA)、DeepSeek 稀疏注意力(DSA)等关键机制,能帮你快速建立认知。
首先需要明确的是,DeepSeek V4 中采用的 CSA/HCA 机制,与此前 V2/V3 版本中使用的 MLA 风格压缩有着本质上的逻辑差异。
MLA 的核心在于对每一个 Token 的 KV 表示进行特征层面的压缩。相比之下,CSA 和 HCA 则是通过沿着序列维度进行压缩,从而实现了更深层次的优化。换句话说,模型不再机械地为每一个历史 Token 都保留一个完整的(或经过压缩的)KV 条目,而是将一组 Token 汇总为数量更少的压缩 KV 条目。
显而易见,这直接带来了 KV 缓存长度的有效缩减。虽然 DeepSeek V4 在实现中依然用到了紧凑的压缩条目与共享 KV 注意力技术,但它与 MLA 之间最核心的区分点,依然在于这种序列长度层面的压缩范式。具体架构逻辑详见下图。
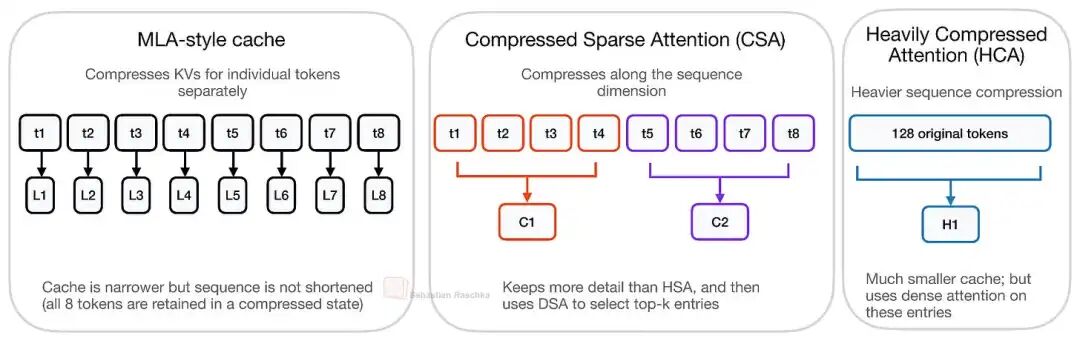
这张图展示了MLA 风格的逐 Token 隐式缓存、CSA 及 HCA 进行了概念层面的核心对比。虽然 MLA对存储的 KV 表示进行了压缩,但其核心逻辑在于依然为每一个 Token 保留一个隐式表征。CSA 利用 $m=4$ 的分块及稀疏 Top-k 筛选机制,对序列长度进行了温和的轻量级压缩。而 HCA 则通过m'=128实现高强度序列压缩,从而能够在更短的缓存空间上执行密集注意力计算
在理解 DeepSeek V4 的机制时,我们需要关注其在性能与质量之间的微妙权衡(Trade-off)。CSA/HCA 与 MLA 在设计哲学上有着本质区别。
如前文图示,MLA 虽然压缩了每个 Token 的存储表征,但它依然保持了“每个 Token 一个隐式 KV 条目”的架构。相比之下,CSA 以及更为激进的 HCA,其切入点更深:它们直接减少了序列条目本身的数量。这意味着,模型通过牺牲一定的 Token 级精细信息,换取了大幅降低的长上下文计算成本。
当然,这是一把双刃剑。若压缩力度过大,难免会损伤模型的建模质量。因此,DeepSeek V4 并未将赌注压在单一的压缩方案上,而是巧妙地交替使用 CSA 与 HCA 机制,以实现更优的动态平衡。
-
CSA(压缩稀疏注意力):采用较为温和的压缩率,并沿用了我在此前 DeepSeek V3.2 解析中深入探讨的 DSA(DeepSeek 稀疏注意力)风格的筛选机制。
-
HCA(重度压缩注意力):这是两者中更为激进的变体。它将每 128 个 Token 压缩为一个 KV 条目,并在此基础上进行密集的注意力计算。
这种设计呈现出高度的互补性:CSA 通过稀疏筛选保留了更多的 Token 细节;而 HCA 通过极致压缩条目数量,使得模型能够承担得起针对这些条目的密集注意力计算。
与此同时,为了确保模型在处理近期信息时的准确度,两者均保留了一个局部滑动窗口分支,专门用于处理近期的未压缩 Token。这也解释了为什么 DeepSeek V4 选择交替堆叠 CSA 和 HCA 层,而非单一使用其中某一种——这种混合架构有效地兼顾了信息的深度与上下文的广度。
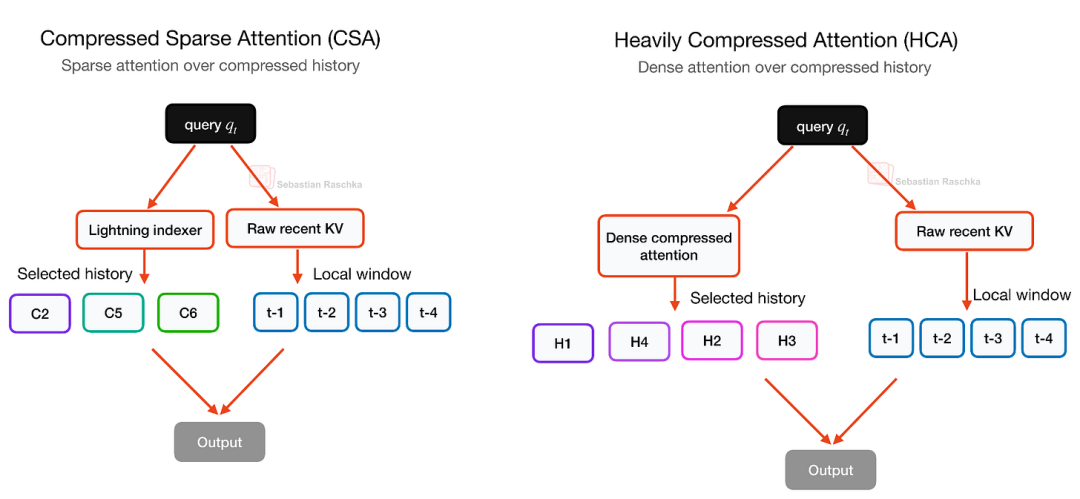
这张图展示了在 DeepSeek V4 的机制设计中,CSA 与 HCA 呈现出互补的逻辑:CSA 通过稀疏选择机制,仅关注部分关键的历史压缩块;HCA 采取了更为激进的压缩策略,但针对这些重度压缩后的数据块,进行了全覆盖的密集注意力计算。两条路径均并入了基于 128-token 滑动窗口的分支,以完整保留近期的未压缩 KV 信息
根据 DeepSeek V4 论文披露的数据,在 1M 超长上下文这一极具挑战性的场景下,DeepSeek V4 的表现令人瞩目。与沿用 MLA 和 DeepSeek 稀疏注意力技术的 DeepSeek V3.2 相比,新架构实现了显著的降本增效:DeepSeek V4-Pro单 Token 推理所需的 FLOPs 仅为原先的 27%,KV缓存显存占用也缩减至 10%。DeepSeek V4-Flash性能优化更为极致,FLOPs 仅占 10%,KV缓存占用则进一步压缩至 7%。
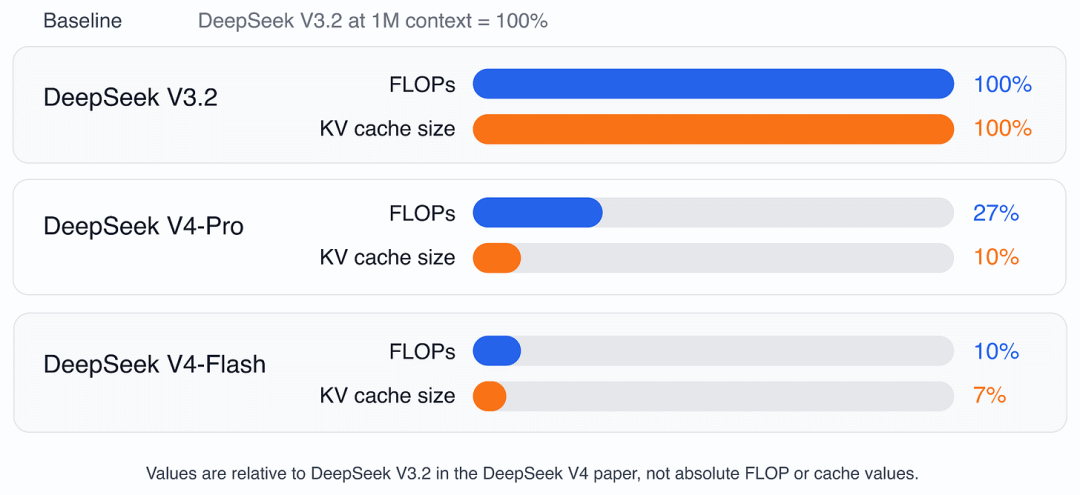
这张图展示了DeepSeek V4 论文中公布的百万上下文效率指标,以 DeepSeek V3.2 为参照基准
我并不认为 CSA/HCA 在通用意义上就“优于” MLA。CSA/HCA 本质上是一种更为激进的长上下文设计方案,当然,其实现复杂度也必然更高。
很遗憾论文中并未给出相关的消融实验。但从整体来看,该论文所展现的建模效果依然非常强劲——例如 DeepSeek V4-Flash-Base 在大多数基准测试中均超越了 DeepSeek V3.2-Base,并且在 1M-token 的超长文本检索任务中表现卓越。
不过需要指出的是,这些成果是基于 DeepSeek V4 的“完整配方”实现的。该配方不仅仅依赖于单一技术,还集成了更优质的数据、基于 Muon 的优化、mHC 架构、精度与存储优化,以及训练和推理系统的全面升级。
现阶段我们可以将 CSA/HCA 看作一种以效率为导向的长上下文设计。它在 DeepSeek 的大型旗舰模型中展现了良好的建模性能,但并不意味着它在所有场景下都具备压倒性优势,优于 MLA。
结语
总的来说,今年模型界呈现出一个有趣的趋势:大多数新的开源权重模型都在致力于降低长上下文推理成本,而非简单粗暴地通过削减模型总参数量来实现。 举例来说:
-
Gemma 4 通过跨层 KV 共享来优化缓存,并借逐层嵌入提升模型容量。
-
Laguna XS.2 对各层的注意力容量进行了更精细的微调。
-
ZAYA1-8B 将注意力机制迁移到了压缩后的潜在空间中。
-
DeepSeek V4 则引入了受限残差流混合与压缩长上下文注意力机制。
所有这些变体设计都极大地增加了架构复杂性,这也恰恰反映了当前大模型架构演进的核心方向。
我的核心观点是:Transformer 架构并未停滞,而是在进行高针对性的迭代。虽然基础框架依然沿用 GPT Decoder-only 的原始架构,但内部诸多核心组件已完成升级或置换,变得更专精于长上下文处理与推理效率的提升;而模型性能的质变,很大程度上依然源于高质量的数据与训练策略。
过去许多人问过我 Transformer 是否会被取代。答案是:尽管目前存在扩散模型等其他设计方案,但 Transformer 依然是目前最先进架构的业界标准。
然而,伴随着每个季度密集的版本发布,我们看到的“微调”越来越多。如果说以前仅需 50-100 行 PyTorch 代码即可实现一个基础 Transformer 模块,那么在引入这些新组件之后,代码复杂度已经飙升至原来的 10 倍。这本身并非坏事,毕竟它们确实降低了运行时成本;但问题在于,我们正变得越来越难以彻底理清这些独立组件及其复杂的交互逻辑。
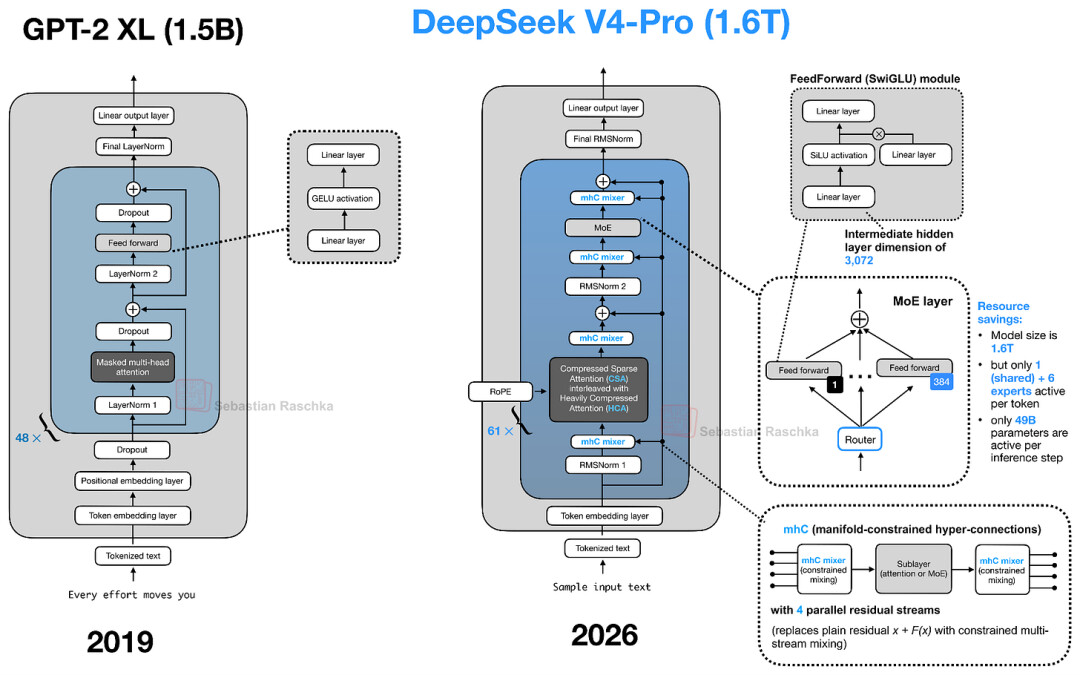
这张图展示了从 2019 年 GPT-2 到 2026 年 DeepSeek V4-Pro 的技术演进历程
举个例子,我深信对于初探大模型架构的读者而言,面对 DeepSeek V4 的源码,大概率会产生一种“深陷重围”的挫败感。但若我们从最基础的 Decoder 架构(如 GPT/GPT-2)切入,再像拼积木一样,循序渐进地拆解每一个新组件,学习曲线就会变得平滑许多。这或许就是学习的真谛:“保持耐心,稳扎稳打,一次吃透一个架构。”
文章链接https://magazine.sebastianraschka.com/p/recent-developments-in-llm-architectures.