谷歌发布 Gemma 4 12B,主打16GB笔记本本地运行与原生多模态能力。
原文标题:120亿参数跑在16G笔记本上,谷歌Gemma 4新成员杀来了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Gemma 4 12B 去掉独立视觉/音频编码器,把多模态输入直接交给 LLM 主干,这条路线靠谱吗?
3、和 26B-A4B MoE 相比,Gemma 4 12B 更省显存但速度更慢,大家会怎么选?
4、开放许可证加本地多模态能力,会不会让小团队更容易做出端侧 AI 产品?
原文内容
在下载量突破 1.5 亿次之际,谷歌 Gemma 4 系列模型迎来了新的家族成员!
今天,谷歌正式推出 Gemma 4 12B,目标是把具备智能体能力的多模态智能,直接带到笔记本电脑上。
根据介绍,Gemma 4 12B 介于面向边缘设备的 E4B 与能力更强的 26B 混合专家模型(MoE)之间,在更小的内存占用下提供了强大的能力。
另外,Gemma 4 12B 也是谷歌首个支持原生音频输入的中等规模模型。
谷歌 DeepMind 创始人兼 CEO 哈萨比斯,「为庆祝 Gemma 4 下载量突破 1.5 亿次这一重要里程碑,谷歌发布了全新的 Gemma 4 12B 模型!对于这样一个小尺寸模型来说,它的能力非常强大;同时,它也足够轻量,只需 16GB 显存,就能在笔记本电脑上本地运行。」
大家可以用它构建了各种各样的应用,从用于物理辅助的可穿戴机器人手臂,到企业级 AI 安全系统。谷歌也期待看到开发者用这款最新模型创造出更多可能。
此次,Gemma 4 12B 模型具有以下几大特性:
-
全新的统一架构:不再使用多模态编码器,视觉和音频输入可以直接进入 LLM 主干网络。
-
更强的推理能力:在基准测试中的表现接近谷歌的 26B 模型,能够支持强大的多步推理和智能体工作流。
-
适合笔记本本地运行:模型规模足够小,只需要 16GB 显存或统一内存即可在本地运行。
-
开放且易于获取:采用 Apache 2.0 许可证发布,并支持广泛的开发者生态。
-
支持草稿模型加速:Gemma 4 12B 配备了多 Token 预测(MTP)草稿模型,可用于降低延迟。
目前,用户可以通过 LM Studio、Ollama、Google AI Edge Gallery App、Google AI Edge Eloquent App 以及 LiteRT-LM CLI 等渠道进行试用。
在 GPQA Diamond、BBEH、MMLU Pro、LiveCode Bench、DocVQA、InfoVQA、MMMU Pro 和 MRC v2.8 needle 128k(average)等一系列基准测试中,Gemma 4 12B 的表现接近谷歌更大的 26B MoE 模型,但整体内存占用不到后者的一半。
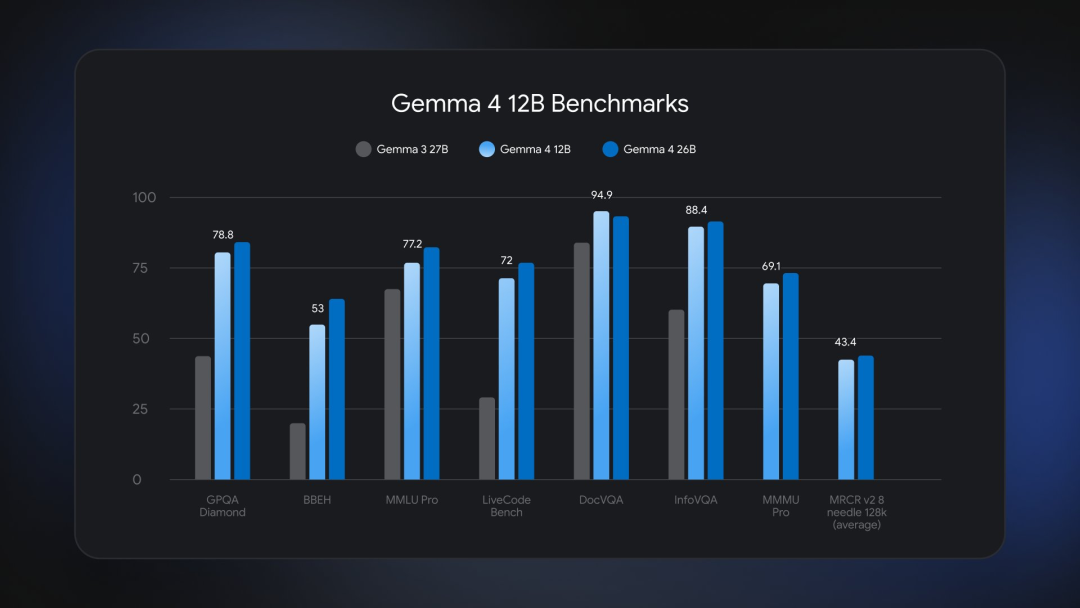
并且,它的规模足够小,可以在配备 16GB 内存的消费级笔记本电脑上本地运行,从而把强大的多模态体验和智能体能力带到你的个人设备上。
有人在一张 RTX 4090 上本地运行了 Gemma 4 12B 和 Gemma 4 26B-A4B,并给它们布置了同一个任务:在不使用任何库的情况下,用单个文件写出一个自包含的 HTML5 Canvas 动画,并加入真实物理效果。测试包含三个场景:高尔顿板、两个方块与墙面碰撞,以及混沌三重摆。输出结果如下:
-
Gemma 4 26B-A4B:占用 15GB 显存,生成 6.9k tokens,速度 138 tokens/s
-
Gemma 4 12B:占用 9GB 显存,生成 8.9k tokens,速度 80 tokens/s
同属 Gemma 4 家族,但 26B-A4B 在三个场景中都胜出,而且运行速度快了约 1.7 倍,它的活跃参数量只有 4B。不过,12B 的表现也非常接近,同时显存占用几乎只有一半。这也让它成为 16GB 笔记本上的理想本地模型。


另外,Gemma 4 12B 最突出的地方在于,它处理视觉和音频输入的方式更加精简。
传统多模态模型通常依赖独立编码器,先把图像和音频转换成模型可理解的表示,再传递给语言模型。但这些分离式编码器会带来额外延迟,也会增加内存占用。因此,谷歌在训练 Gemma 4 12B 时采用了无编码器架构,让音频和视觉输入能够直接整合进模型。
Gemma 4 12B 原生处理多模态输入的方式如下:
-
视觉:谷歌用一个轻量级嵌入模块替代了 Gemma 4 的视觉编码器。这个模块由一次矩阵乘法、位置嵌入和归一化组成,让 LLM 主干网络接管视觉处理。
-
音频:音频处理进一步简化。谷歌完全移除了音频编码器,并将原始音频信号投影到与文本 token 相同的维度空间中。
在 Google AI Edge Eloquent App 中,Gemma 4 12B 可以完全离线完成语音输入的转录、格式整理和翻译。
参考链接:
https://x.com/sundarpichai/status/2062257242645393889
https://x.com/demishassabis/status/2062241713398149524
https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12B/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com