OmniVTG 用大规模语义数据和自我纠错机制,提升开放世界视频时序定位能力。
原文标题:CVPR 2026 | 破解开放世界“语义盲区”:北大和华为团队携手开源大规模OmniVTG数据集,用“自我反思”机制补齐定位短板
原文作者:机器之心
冷月清谈:
怜星夜思:
2、OmniVTG 这种自动化收集和标注的视频数据集,可靠性会不会成为最大隐患?
3、自我纠错 CoT 对视频模型真的有帮助,还是只是让模型输出更像推理过程?
4、开放世界视频理解要覆盖罕见概念,靠继续堆数据就够了吗?
原文内容

本文的第一作者为北京大学王选计算机研究所博士生郑明航,通讯作者为博士生导师刘洋。团队近年来在 TPAMI、CVPR、ICCV、ICML 等顶会上有多项代表性成果发表,多次荣获多模态感知和生成竞赛冠军,和国内外知名高校、科研机构广泛开展合作。
本文主要介绍该团队和华为中央媒体技术院在多模态视频理解与时序定位领域的最新研究成果。该工作针对开放世界视频时序定位中数据集语义局限和模型缺乏自我修正能力的问题,提出了一个大规模、语义丰富的数据集OmniVTG,以及一种自我纠错思维链(Self-Correction CoT)训练范式。该方法不仅有效缩小了罕见与常见概念的性能差距,还在多个公开基准上取得了最先进的零样本性能。 目前相关代码已开源。

-
论文标题:
OmniVTG: A Large-Scale Dataset and Training Paradigm for Open-World Video Temporal Grounding
-
论文链接:
https://arxiv.org/abs/2604.25276
-
开源代码:
https://github.com/oceanflowlab/OmniVTG
-
数据集链接:
https://huggingface.co/datasets/zhengmh/OmniVTG-Dataset
-
视频介绍:
https://www.youtube.com/watch?v=lrCdZU1fxQ8
背景与动机
视频时序定位(Video Temporal Grounding, VTG)旨在根据自然语言查询在未剪辑视频中精准定位事件的起止时间。如图1(a)所示,尽管多模态大模型为视频理解带来了突破,但在开放世界视频时序定位任务中,现有方法仍面临在稀有概念上性能不佳的问题。本文在以下两个方面对这些难题进行了分析:
数据层面存在语义盲区。主流数据集往往局限于特定领域(如室内活动或烹饪),词汇覆盖范围狭窄。 对于现实中存在的“罕见概念”,现有数据集中缺乏相应的训练样本,导致模型在面对这些概念时无法准确识别。 依赖人工标注的数据集成本高昂难以扩展,而简单的监督微调无法赋予模型处理陌生概念的有效推理机制。
模型层面缺乏自我修正能力。现有的定位模型大多采用直接回归或分类的方式预测时间边界,面对陌生或复杂的查询时往往会给出错误预测且无法自知。 然而本文发现,如图1(b)所示,多模态大模型在视频理解(如判断视频片段是否匹配查询、判断事件状态)上的能力显著优于其直接定位能力,且其理解能力在常见概念和稀有概念上的性能差距更小。如何利用这种较强的理解能力来修正较弱的定位结果,是提升性能的关键。

图1:背景与动机
针对上述问题,本文提出了OmniVTG,一个专为开放世界设计的大规模、语义丰富的数据集,以及一种自我纠错思维链(Self-Correction CoT)训练范式。如图2所示,OmniVTG通过语义覆盖迭代扩展策略构建,包含2124小时视频和超35万条查询对,显著扩展了语义覆盖范围。在训练方面,本文利用多模态大模型(MLLMs)强大的视频理解能力来反哺其定位能力,通过“预测-反思-修正”的思维链机制,显著提升了模型在开放世界中的鲁棒性。实验表明,该方法不仅在OmniVTG测试集上有效缩小了罕见与常见概念的性能差距,还在ActivityNet Captions、QVHighlights等四个公开基准上取得了最先进的零样本性能。
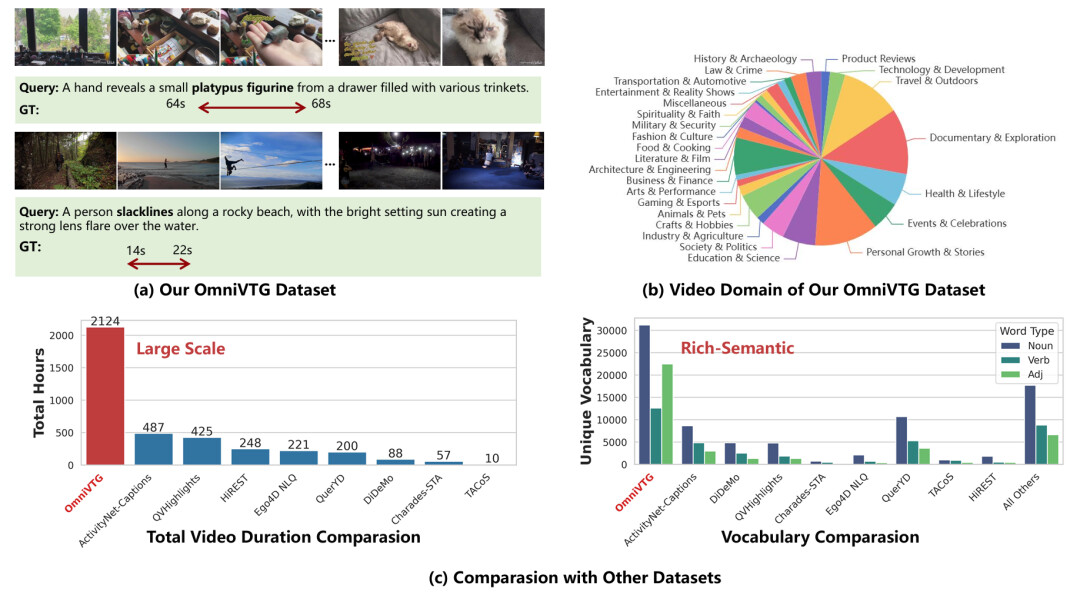
图2:OmniVTG数据集
技术方案
为解决上述挑战,本文提出了OmniVTG,包含数据构建与训练范式两个核心部分,如图3所示。
第一部分:语义覆盖迭代扩展的数据构建。为了突破现有数据集的语义局限,如图3(a)所示,本文设计了一套主动数据收集流程:(1)目标词识别:分析现有数据集的词汇分布,识别出未被覆盖的罕见词;(2)定向视频收集:利用大语言模型(LLM)将罕见词转化为具体的视频搜索关键词,从互联网检索极有可能包含这些概念的视频;(3)自动化标注:基于MLLM在密集描述任务上比直接定位更准确的观察,设计了以描述为中心的标注引擎,提示模型生成包含目标罕见词的带时间戳描述,从而获得高质量的<视频, 查询, 时间戳>三元组。最终构建了包含2124小时视频、语义丰富的OmniVTG数据集。数据集的可视化和数据统计如图2所示,本文所提出的数据集在视频领域覆盖、视频时长、词汇量大小等方面都显著强于现有公开数据集,为开放世界视频时序定位提供了坚实的数据基础。此外,数据集的测试集标注全部经过了人工验证,提供了可靠的开放世界视频时序定位评测基准。
第二部分:自我纠错思维链(Self-Correction CoT)训练范式。如图3(b)所示,基于模型理视频解强于定位的特性,本文提出了三阶段训练策略:(1)多任务监督微调(SFT)。除了基础的时序定位任务外,引入事件描述、查询-片段匹配、事件状态分类(未开始/进行中/已结束)等辅助任务,强化模型的基础理解和定位能力,为后续的自我反思打下基础。(2)自我纠错CoT微调。构建特定的思维链数据,教导模型遵循先进行初步预测,再利用理解能力检查预测片段是否匹配,最后根据事件状态调整时间边界的推理路径。(3)强化学习(RL)。利用GRPO算法进一步优化模型的推理策略,使模型从模仿CoT中固定格式的推理过程转向自我探索更鲁棒且更符合逻辑的自我修正轨迹,从而输出更精准的定位结果。
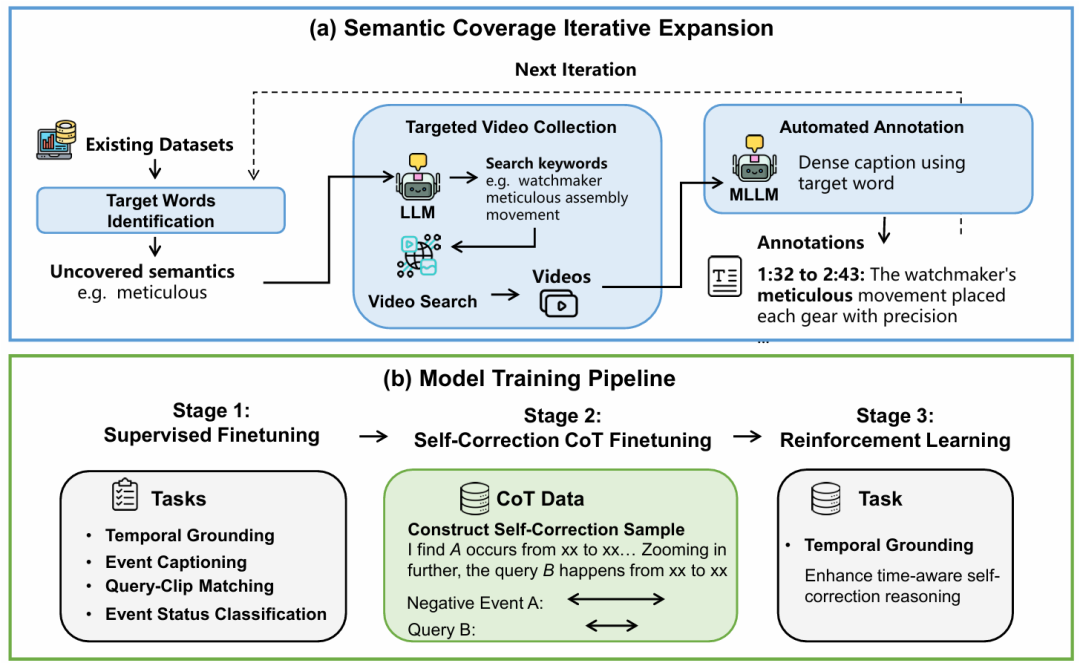
图3:开放世界视频时序定位数据集收集流程与模型训练框架
实验结果
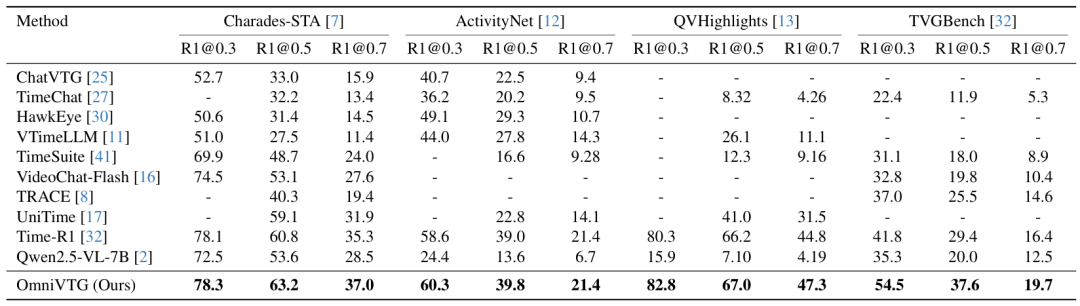
零样本视频时序定位性能分析:如表1所示, OmniVTG模型在未接触过目标数据集训练集的情况下,凭借其在OmniVTG大规模数据上学到的开放世界知识和推理能力,在ActivityNet Captions、Charades-STA、QVHighlights和TVGBench四个权威基准上取得了全面超越现有SOTA模型的性能。
表1:零样本视频时序定位性能比较
开放世界罕见概念性能分析: 表2进一步分析了模型在处理罕见概念时的表现发现,现有模型在遇到罕见词时性能下降。 而OmniVTG模型表现出更强的鲁棒性,罕见概念与常见概念的性能差距被显著缩小,证明了该方法有效提升了模型的泛化能力。
表2:开放世界罕见概念性能分析

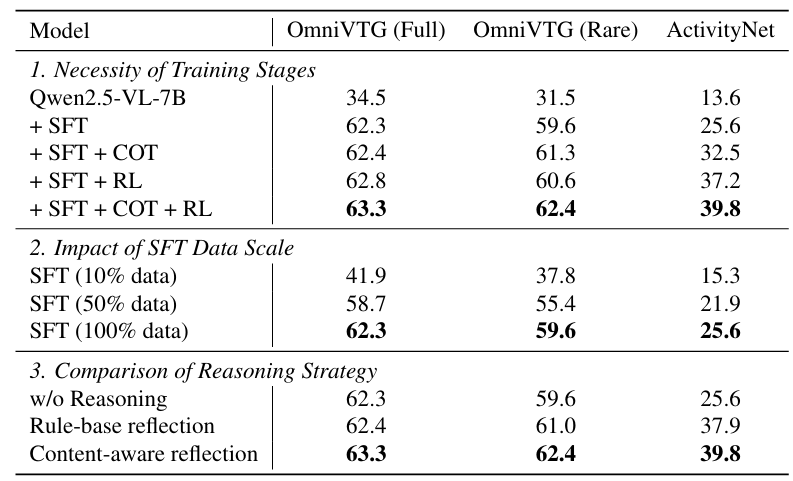
消融实验:表3验证OmniVTG各核心设计的有效性。首先,相较于表现较弱的基线模型,引入多任务监督微调(SFT)带来了最显著的性能提升;在此基础上加入自我纠错思维链和强化学习,模型在处理罕见概念与未见过的数据集(ActivityNet)时的泛化能力得到了进一步提升。其次,随着SFT训练数据量从10%逐步增加到100%,模型的性能稳定的增长,印证了大规模数据集的价值。最后,在推理策略的对比中,自我反思策略表现出了最佳效果,显著优于无推理机制。
表3:消融实验
可视化结果: 定性案例展示了自我纠错机制的有效性。 对于“无肩带婚纱”这一细粒度查询,基线模型错误地定位到了有肩带婚纱的片段;而OmniVTG模型在初步预测后,通过思维链推理发现当前片段不符合无肩带特征,并利用视觉理解能力将时间窗口调整至正确的片段,成功完成了精准定位。
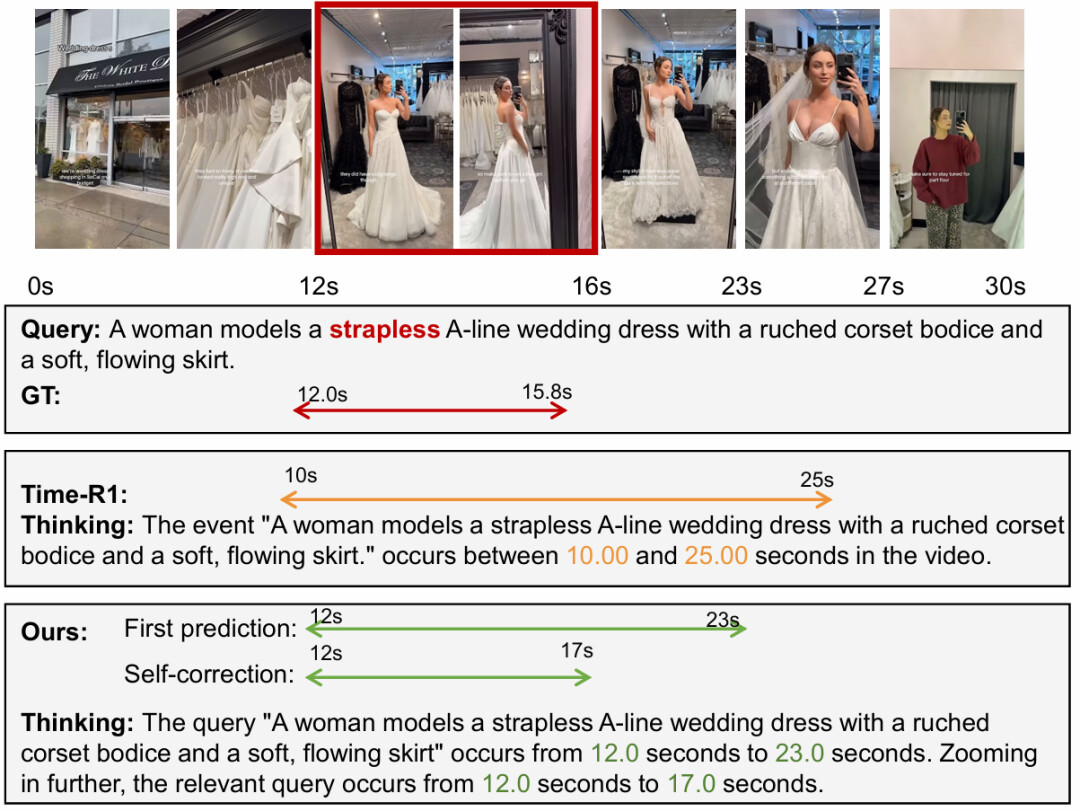
图4:开放世界视频时序定位案例展示
总结
针对开放世界视频时序定位中数据匮乏与推理能力不足的问题,本文推出了OmniVTG,一个大规模、语义丰富的数据集,并提出了一种自我纠错思维链训练范式。通过主动扩展数据集语义覆盖和利用视频理解能力反哺定位,该方法不仅在数据规模和语义覆盖范围上进行了突破,也赋予了模型在面对未知和罕见概念时的推理与修正能力。实验结果证明,OmniVTG在多个基准测试中取得了最先进的零样本性能,为多模态大模型在开放世界视频理解任务中的应用提供了新的范式。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com