NeurIPS 用 AI 检测器筛稿引发误伤与公平性质疑。
原文标题:NeurIPS用AI检测,说我的论文是AI生成的
原文作者:机器之心
冷月清谈:
怜星夜思:
2、科研写作里,AI 润色和 AI 代写到底该怎么划线?
3、如果 AI 检测器误伤作者,会议应该提供怎样的申诉机制?
4、顶会严格限制 AI 写作,会不会反而不利于科研效率?
原文内容
NeurIPS 2026 正在用 AI 检测器来判定「论文投稿是否使用 AI」,并作为拒稿的重要依据。
今天,Reddit 上一则帖子火了。发帖人对 NeurIPS 官方发出了控诉。
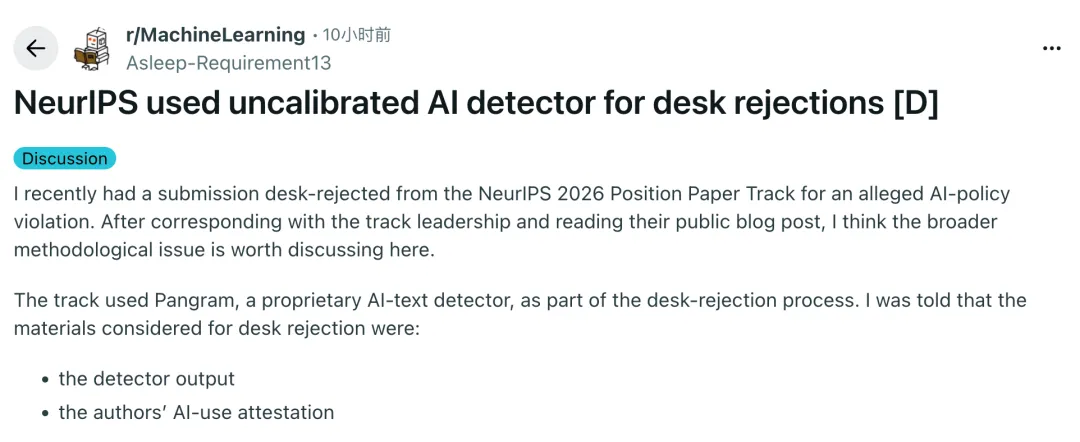
原贴内容是这样的:
我最近有一篇投稿被 NeurIPS 2026 Position Paper Track 以所谓违反 AI 使用政策为由直接拒稿。在和 track 负责人沟通之后,又读了他们公开发布的博客文章,我觉得这里面更大的方法论问题值得拿出来讨论。
这个 track 在 desk rejection 流程中使用了 Pangram—— 一个闭源的 AI 文本检测器。我被告知,作出拒稿判断时参考的材料包括:检测器输出结果和作者提交的 AI 使用声明。
这就可能产生一个循环论证的问题:如果一个较高的检测分数被用来判断作者的声明「不一致」,而这种「不一致」又被用来证明拒稿合理,那么检测器就不只是一个辅助工具了。它实际上成了裁决过程中的决定性因素。
更大的问题在于验证。NeurIPS 的文章提到,他们做过一些测试,包括 Pangram 审计、较早的 ACM FAccT 论文、合成生成的 AI position paper,以及人工编辑过的样本。但真正的目标群体是 NeurIPS 2026 Position Paper 的投稿,而这些投稿的真实写作过程并没有已知的 ground truth。
所以,关键问题是:在真实目标分布上,这套最终决策流程的误判率到底是多少?在一个分布上测得的假阳性率,并不会自动迁移到另一个分布上。如果真实投稿池中出现了 NeurIPS 博客所说的「异常高的被标记比例」,这反而可能说明存在分布偏移,或者检测器校准出了问题。
为了简单验证一下这个检测器的行为,我还用 Pangram 跑了几篇 2026 年近期的论文,作者包括 NeurIPS Position Paper Track 的几位主席。Pangram 给出的结果包括:69% AI、45% AI、36% AI 和 24% AI。我并不是说这些论文就是 AI 写的。对我来说,仅凭 Pangram 的输出,根本不能得出这样的结论。而这恰恰就是问题所在。
帖子里提到的 NeurIPS 博客文章是 6 月 2 日发布的,列出了 Position Paper Track 上 AI 生成的论文。

完整内容参见:https://blog.neurips.cc/2026/06/02/ai-generated-papers-in-the-neurips-2026-position-paper-track/
文中指出,NeurIPS 2026 Position Paper Track 决定要求所有论文必须主要由人类作者撰写,AI 只能用于文字润色,或对正文进行类似的辅助性、外围修改。
今年 Position Paper Track 的主席在政策上采取了相对保守的做法。他们认为,对于 position paper 这类重在论证的文章来说,过度使用 AI 撰写投稿,对整个研究共同体的帮助有限。AI 生成的文字往往看起来很流畅,但可能明显偏离作者原本想表达的意思。在这种情况下,把 AI 生成的文本提交给同行评审,等于是把核查这项工作的成本转嫁给审稿人。即便 AI 生成的文本本身并不混乱,也没有明显误导性,这仍然会引发一个问题:相关贡献应当如何归属。
因此,为了评估作者是否基本遵守了这项政策,他们与 AI 检测模型公司 Pangram 合作,并根据企业级数据协议,确保在使用其模型的过程中不会保留任何数据。随后进行了多项独立分析,以验证该模型的准确性,并排除会产生大量误判的情形。
最终结果是:178 篇投稿将被直接拒稿,占全部投稿的 18.4%;123 篇投稿将被要求提供证据,证明论文中有充分的人类参与,否则也可能被直接拒稿,占 12.7%。
reddit 发帖人正是被直接拒稿的其中之一。
在评论区,有人将矛头指向了公平问题。
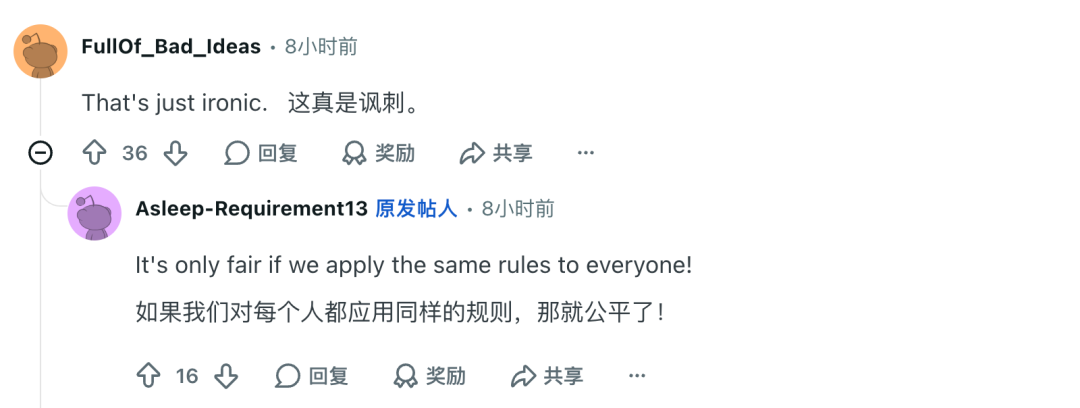
也有人认为 AI 检测器就是鸡肋,遗憾的是,NeurIPS 这样的顶会都开始使用这种检测手段了。
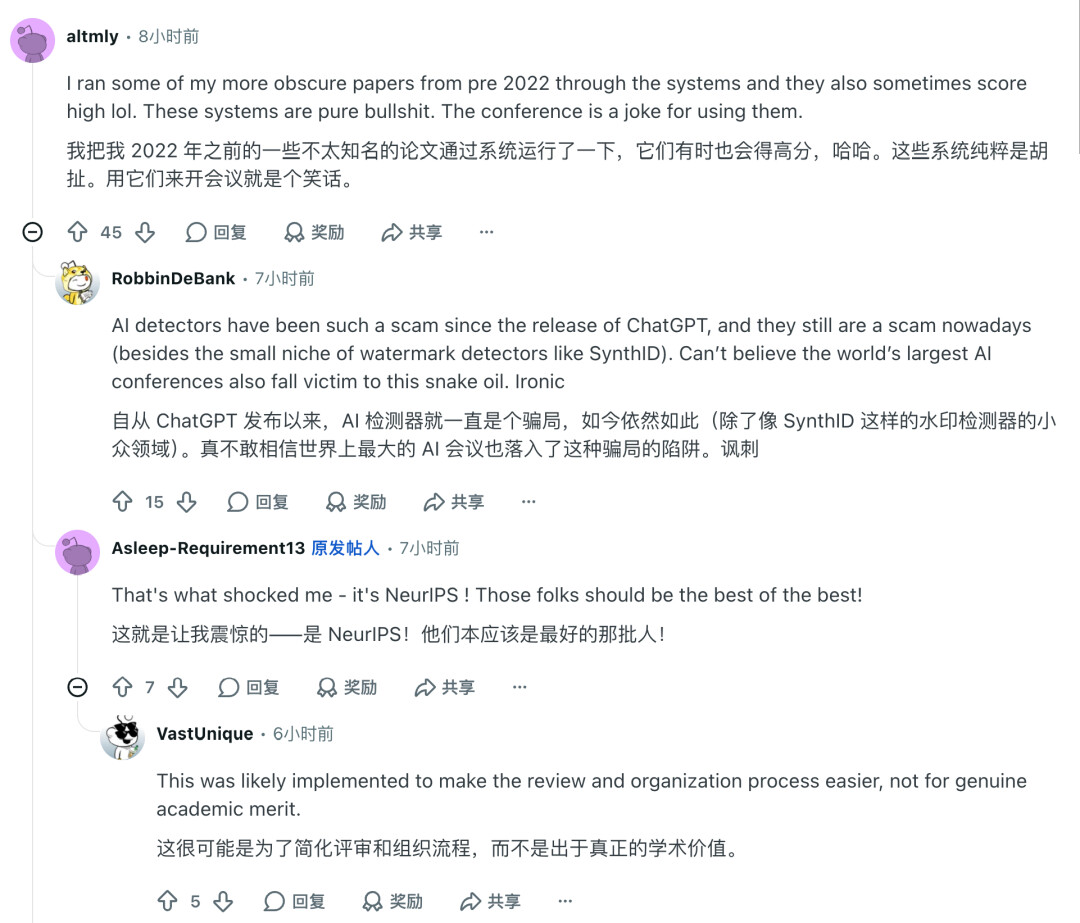
还有人现身说法,指出了 Pangram 在检测 AI 使用方面的一些不足之处。

这场风波真正暴露的,不只是 NeurIPS 有没有误伤投稿者,一个更现实的问题是:当 AI 已经进入科研写作,学术界到底该如何判断「合理辅助」和「过度代写」?如果答案只是交给一个黑箱检测器,那么新的公平争议,可能才刚刚开始。
reddit 地址:
https://www.reddit.com/r/MachineLearning/comments/1tvwctd/neurips_used_uncalibrated_ai_detector_for_desk/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com