AI自我改进正在从概念走向局部闭环,但距离完全自主演化仍有现实阻力。
原文标题:如果AI开始自我演化:递归自我改进正在以一种远比「奇点」更现实的方式出现
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、递归自我改进最危险的地方,是AI能力突然暴涨,还是人类过早把关键决策权交出去?
3、文章里提到未来可能是“AI寒武纪”,不是一个超级AI统治一切。你觉得哪种场景更可能?
4、如果AI能自动完成科研闭环,论文、专利和发现的署名权应该怎么分配?
原文内容

来源:ScienceAI本文约2200字,建议阅读5分钟人类正第一次接近“只能闭环”。

AI 领域的发展建设,建立在未来的机器能否实现自我改进之上。1966 年,英国数学家 I. J. Good 写道:
“一种超智能机器可以设计出更好的机器;随后毫无疑问会出现‘智能爆炸’,而人类智能将被远远甩在后面。”
几十年来,研究者既期待这种“递归自我改进”(recursive self-improvement,RSI),也对它保持警惕。而现在,随着 AI 能力快速推进,一个问题开始变得现实:这个过程,会不会已经在发生了?
但 RSI 这个词本身就充满模糊性。
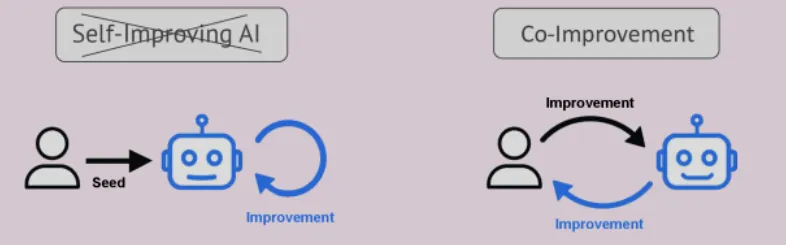
有人把它当作推动监管的警报词;有人则把它当成营销口号。对某些人来说,RSI 意味着一个完全自主的闭环系统;而对另一些人来说,只要“技术帮助制造技术”,就已经算是某种形式的自我改进。
最安全的理解方式,也许是把它看成一个连续谱。
在最严格的定义下,RSI 指的是一种不仅能改进输出结果,还能改进“自身改进过程”的系统:它能够自行提出想法、评估结果、修改方法,而且完全不需要人类介入。按照这个标准,今天的大多数 AI 系统仍然达不到要求。它们确实已经能帮助构建更好的 AI,但依然依赖人类来设定目标、定义成功标准,并决定哪些修改值得保留。
真正的问题,不是“自我改进是否已经存在”,而是这个闭环,到底已经闭合了多少。
通往自我改进的台阶
事实上,研究者已经为 RSI 铺路很多年了。
机器学习算法早就能够自动调整程序参数;进化算法(evolutionary algorithms)可以不断生成、筛选并迭代设计方案;过去十年里,AutoML 又开始自动化神经网络结构设计、训练和评估中的部分流程。
而今天,大语言模型——例如 OpenAI 的 GPT、Google DeepMind 的 Gemini、Anthropic 的 Claude,以及 xAI 的 Grok——把这一趋势推得更远。这些模型最重要的用途之一,就是写代码。包括用于生成下一代模型的代码。
今年 2 月,OpenAI 表示,GPT-5.3-Codex 已经在自身开发过程中发挥重要作用:帮助调试训练、管理部署以及分析评测结果。与此同时,Anthropic 也声称,其大部分代码如今已经由 Claude Code 编写。尽管如此,这些系统仍然需要人类来指挥和验证整个过程。
2025 年,Google DeepMind 还公布了一个名为 AlphaEvolve 的系统——一种“用于科学与算法发现的编码智能体”。它利用大语言模型引导解空间的进化,例如优化神经网络结构、数据中心调度和芯片设计。虽然它依旧需要人类来定义问题和评价标准,但每一次算法突破,都在反过来提升 AI 研发自身的能力。
图示:AlphaEvolve 高层次概述。
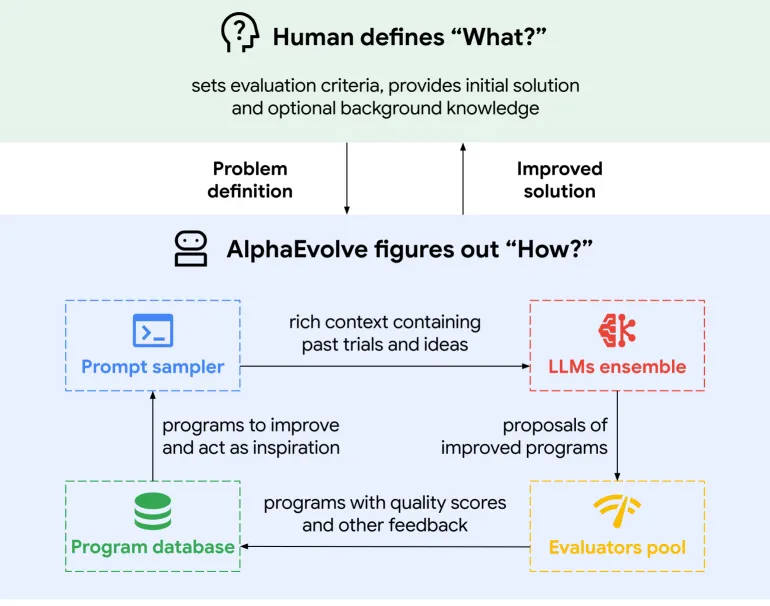
参与 AlphaEvolve 的计算机科学家 Matej Balog 对此评价道:“这是一个高度协作的过程。”很多时候,人类研究者会从 AI 发现的新方案中反过来获得启发。
与此同时,DeepMind 早期芯片设计系统 AlphaChip 的联合负责人,也创办了一家名为 Ricursive Intelligence 的新公司,希望利用 AI 来设计 AI 芯片。
联合创始人 Azalia Mirhoseini 表示,他们希望把传统需要一到两年的芯片设计周期压缩到“几天”:
第一阶段,AI 辅助人类设计;
第二阶段,AI 自动完成没有专业团队公司的芯片开发;
第三阶段,则是用 AI 设计更好的 AI 芯片,再用这些芯片训练更强的 AI。
不过,研究团队强调,这一过程仍会保留人类监督。
还有一些研究,则直接瞄准了“系统修改自身行为”这一目标。比如说去年,University of British Columbia 与 Sakana AI 发布了 Darwin Gödel Machines(DGMs):一种利用进化算法不断改进基于 LLM 的代码智能体的系统。
相关链接:https://spectrum.ieee.org/evolutionary-ai-coding-agents
图示:DGMs 与超级代理。
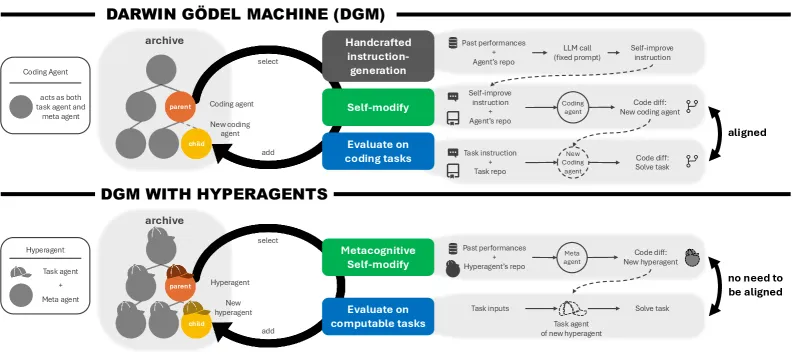
虽然它们暂时还无法修改底层语言模型本身,但已经能越来越擅长“改进自己”;更进一步的版本,甚至已经开始修改“自身改进机制”本身。
同一研究团队后来又开发了 AI Scientist,这个系统旨在尝试自动化整个科研闭环。它意味着,被自动化的不再只是“编码”,而是实验、评估乃至知识生产本身。
智能爆炸仍然面临巨大阻力
不过,并不是所有人都认为“奇点”已经近在眼前。
许多研究者指出,如今的 AI 仍然只是“还不错”地完成生成想法、实现代码与评估结果这些步骤,而远远称不上完全自主。
Nathan Lambert 最近提出,与其说未来会出现“递归自我改进”,不如说会出现一种“有损自我改进”(lossy self-improvement)。随着系统越来越复杂,摩擦和协调成本会逐渐拖慢整个飞轮。
相关链接:https://www.interconnects.ai/p/lossy-self-improvement
另一个现实问题则是成本。今天最前沿的 AI 系统开发成本已经达到数十亿美元,没有任何公司愿意真的把如此昂贵的系统完全交给 AI 自主运行。
此外,即使 AI 能设计更好的软件,也不意味着它能够立刻接管现实世界中的复杂生产体系。真正实现完全 RSI,也许不仅需要 AI 设计芯片和算法,还需要它建造数据中心、运行发电系统 、开采矿产、管理机器人生产链。
而这些能力目前仍然深度依赖人类社会与工业基础设施。
图示:自我改进的 AI 与协作式 AI。
“AI 寒武纪”
有些研究者认为,人们对 RSI 的想象方式本身可能就是错的。
对此,很多人的设想都是一个越来越强大的单一超级 AI,但现实可能更像生物进化。那可能会更像某种人工生命形式的寒武纪大爆发。届时,大量不同类型的 AI 智能体会同时出现,它们拥有自己的生态、文化与经济系统。
但在那时,人类会被剔除出科研回路吗?
也许,但可能更慢。
人类研究者会首先从低层级工作中退出,不再亲自调试细节,而更像教授或团队负责人,负责选择研究方向。之后,人类可能更像项目主管或 CEO,负责制定更宏观的目标。再往后,人类的角色会逐渐变成监督者。
不过也许,当 AI 进化到能治愈癌症,一些学者大概会很乐意放弃这个令自己喜爱的事业。
原文链接:https://spectrum.ieee.org/recursive-self-improvement
编辑:文婧
