MIRA 通过递归自训练产出材料基座模型 MPA,在 40 项实验性质预测任务中刷新表现。
原文标题:AGI将至!40项实验全面SOTA,超级递归智能体自主打造最强材料基座模型
原文作者:机器之心
冷月清谈:
MPA 聚焦材料研发中更难预测的实验性质,如沸点、闪点、毒性、溶解度等。文章认为,这类数据稀疏、噪声高、物理机制差异大,单纯堆参数和计算性质数据难以解决。
技术上,MPA 采用三阶段训练框架:基于大规模分子结构的 3D 自监督预训练、与下游目标共享物理机制的中间训练,以及面向具体任务的后训练。MIRA 还引入 Huber 损失、混合读出头、多构象聚合等改进,将物理先验融入模型结构。
实验结果显示,MPA 在 40 个实验性质预测任务中平均 MAE 降低约 10%,最高降幅达 51%;与 Suiren 对比,40 个可比任务中赢下 35 个,并在分布外泛化上表现更稳。文章将其视为 AI 自主改进 AI、推动科研智能体发展的一个重要案例。
怜星夜思:
2、MPA 强调实验性质预测,而不是只看量子化学计算性质。大家觉得这对真实材料研发有多重要?
3、这类“递归自训练”的科研智能体,算不算 AGI 的前兆?还是只是一个更强的自动化工具?
4、文章里提到 MIRA 会根据物理常识清洗异常数据,这种自动清洗会不会也带来新的风险?
原文内容
今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。
我们相信,AI 的自我进化是突破当前 Scaling 瓶颈的关键路径,这一点也是硅谷在去年年末就已经形成的共识。
Anthropic 联合创始人,他认为到 2028 年底,递归自进化(recursive self-improvement)发生的概率有 60%,AI 很快就能自己改造自己了。

而在上周,OpenAI 公开招聘「递归自我改进安全研究员」,年薪开到 44 万美元,目标是寻找「能够支持递归式自我改进准备工作的强大技术执行者」。
而在 AI4S 领域更是不得了,Nature 发表了三篇 AI 科研智能体论文。
Google DeepMind 的 Co-Scientist 在急性髓系白血病药物筛选中命中了 3 个阳性候选分子;FutureHouse 的 Robin 系统自主完成了从假设生成到实验验证的完整闭环;Google 的 ERA 引擎能并行生成数千个代码变体进行计算实验。
AI 智能体自我迭代飞轮的启动,需要智能体自主从代码重构、数据清洗到模型训练,最终独立产出超越人类精心设计的 SOTA 模型。
这第一步已经启动了。就在本周,深度原理团队发布了 Materials Property Axiom (MPA)模型。
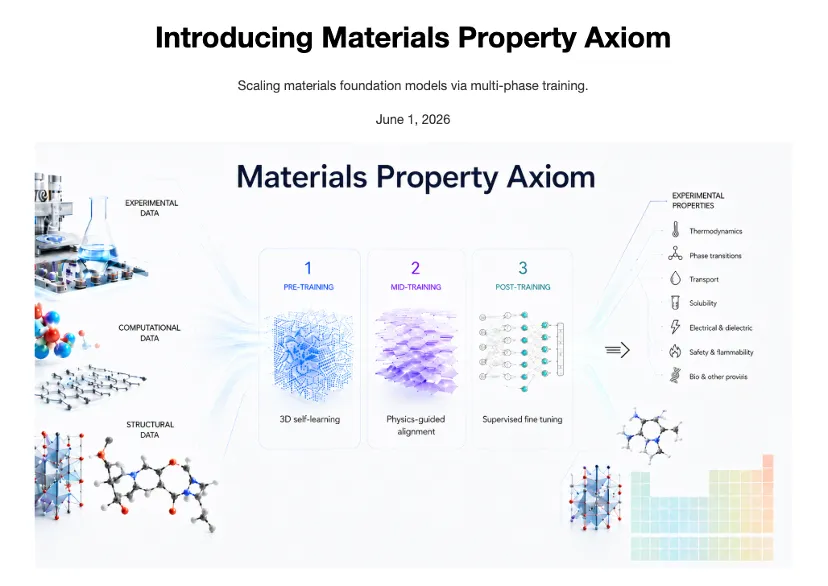
这个由深度原理团队自研的 AI Scientist 平台 MIRA ,通过递归自训练产出的材料基座模型,在 40 项实验性质预测任务中全面刷新了 SOTA,平均 MAE 降低 10%,最高降幅达 51%。
研究报告提到,在整个研究流程中,MIRA 承担了关键工作,包括开展初步研究、适配并更新骨干基础模型、自动化训练与评估循环、分析实验结果,并撰写报告初稿。

-
技术报告链接:https://www.deepprinciple.com/papers/mpa.pdf
这或许是「AI for AI」概念迄今为止最具说服力的一次落地。
对于 MPA 性质预测能力和效果感兴趣的话,可以直接上手试一试:https://sciclaw.cn/?invite_code=CN-JJLRHO9U
前 SOTA 的暴力美学
2026 年 3 月,上海科学智能研究院发布了 Suiren-1.0,一个参数量达 1.8B 的分子基座模型家族,一举击败长期霸榜的 UniMol 系列模型。
320 张 NVIDIA H800 GPU、7000 万条量子化学级别的分子构象数据,Suiren 走的是一条典型的「暴力美学」路线。
但 Suiren 有一个结构性盲区。
它的训练数据和优化目标主要围绕计算性质展开,也就是那些可以通过量子化学软件批量算出来的性质。而在实际的材料研发中,决定一个分子能不能用的是实验性质:沸点、闪点、毒性、溶解度等等。
实验性质预测为什么难?实验数据天然稀疏,一次实验可能花几天;噪声大,不同实验室测出来的值可能不同,而且不同性质背后的物理机制完全不同。靠堆数据和堆参数,解决不了这种物理多样性带来的迁移难题。
这正是 MPA 切入的突破口。
递归自训练:MIRA 从自主科研到新 SOTA 的诞生
AutoResearch 架构:从自动化科研开始
MPA 的诞生过程,与传统的「人类设计实验、手动调参、反复试错」模式截然不同。
深度原理团队构建了一套基于 MIRA 的 AutoResearch 架构,仅需人类科学家参与意图说明和阶段性审核,AI 科研智能体即可全自主完成从文献调研、代码实现、数据处理到模型训练的完整科研管线。
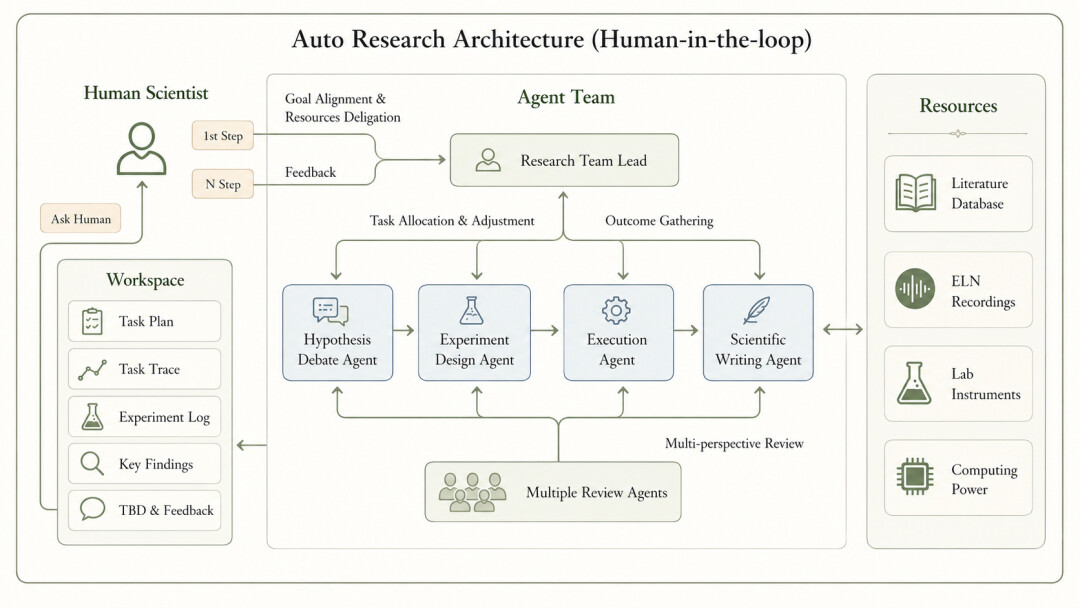
具体而言,MIRA 在这套架构中扮演的角色类似于一个全栈科研员:它能够理解研究目标,自主拆解任务,调用计算资源执行实验,分析中间结果并据此调整策略。整个过程形成递归闭环,每一轮迭代的输出成为下一轮的输入,模型性能在自主循环中持续攀升。
这和 Self-Improving Agent 的研究方向不谋而合,但深度原理将其落地到了一个可量化验证的科学问题上。
自主重构:AI 改写 AI 的代码
AI 科研同样需要先动脑子后动手。
举个例子,团队向 MIRA 抛出一个开放性问题:「考虑到目前已经具备 3D 分子结构和实验性质标签,最可行的多性质预测模型是什么?」

MIRA 启动了 brainstorm ,系统性地分析了当时可选的所有路径,认为 UniMol 系列的 3D 预训练编码器是最合理的起点。
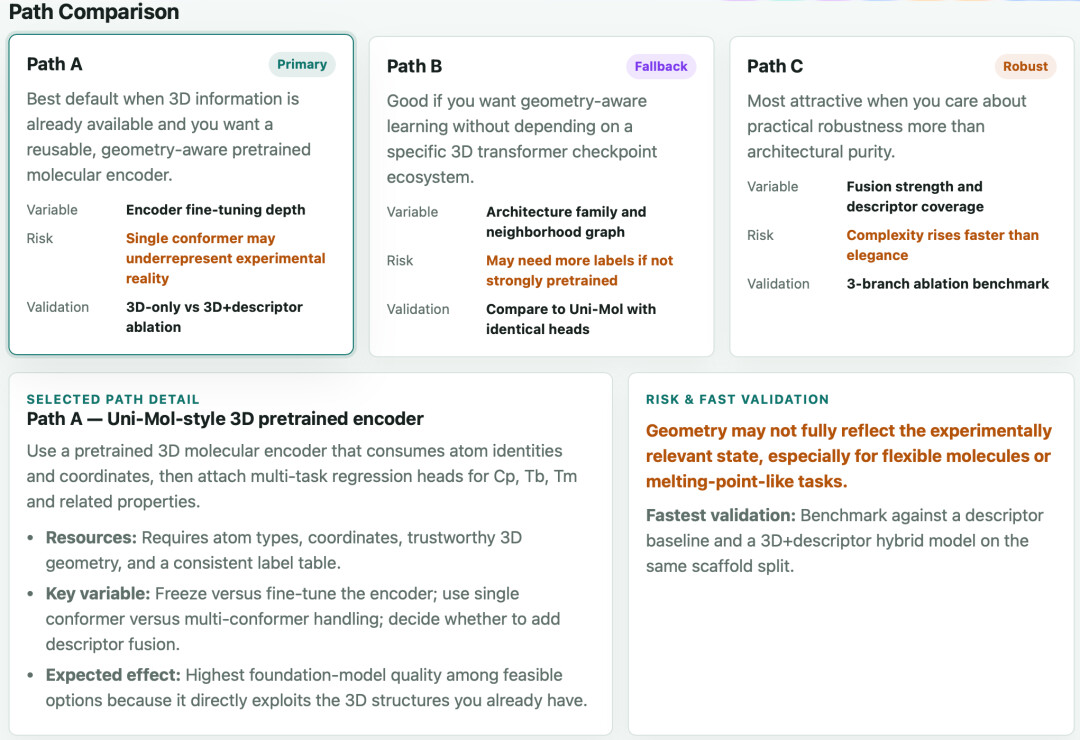
MIRA 给出了几条改进路径,最终推荐了保留 UniMol-v2 的 3D Transformer 骨架,增加多构象感知能力和面向实验性质的对齐训练的方案。
这个决策过程完全由 MIRA 自主完成。人类研究员的角色,是提出问题和确认方向。
随后,MIRA 对现有的分子基座模型代码进行自主重构。这个过程包括:识别架构中的冗余模块,重新设计数据流管线以适配三阶段训练框架,以及将预训练、中间训练和后训练三个阶段的接口标准化。重构后的代码库成为 MPA 三阶段训练框架的工程基础。
值得强调的是,这种代码级的自主重构能力,正是 MIRA 区别于任何一个科研工具的关键。它操作的对象不仅是超参数空间,而是整个模型架构和训练管线的源代码。
自主清理:AI 的「科研直觉」
在准备训练数据的过程中,MIRA 展现出了一种接近人类科研直觉的能力:自主发现数据中的系统性问题。
MPA 的下游基准包含 40 个实验性质预测任务,数据来源涵盖 OPERA、Yaws 手册、CRC 化学物理手册、TDC、MoleculeNet 等多个公开数据库。这些数据集由不同团队在不同时期整理,存在单位不一致、重复样本、标签噪声等问题。
MIRA 在数据预处理阶段自主执行了多阶段清洗管线。更关键的是,它能够基于物理常识判断数据的合理性。例如,当某个分子的沸点数据与其分子量和官能团组成明显不匹配时,MIRA 会将其标记为可疑数据点并从训练集中移除。
这种能力在传统流程中需要领域专家花数周人工审查。MIRA 把它变成了自动化流程的一部分。
自主设计:三阶段训练框架的诞生
在完成代码重构和数据清洗后,MIRA 进入了最核心的环节:自主设计和迭代训练策略。
MPA 最终采用的三阶段训练框架(预训练、物理对齐中间训练、下游后训练),其核心设计思想来自一个类比:大语言模型的训练范式。在 LLM 中,广泛的预训练之后是领域对齐的中间训练,最后是任务特定的微调。MIRA 将这一范式迁移到材料基座模型,但做了一个关键的物理学改造:中间训练的监督信号必须与下游目标共享物理机制。
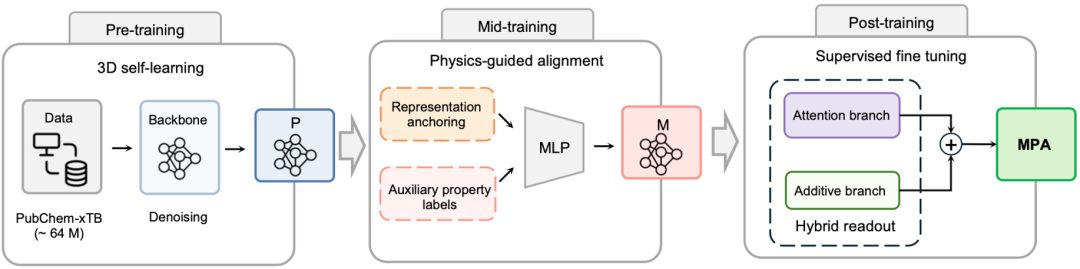
预训练阶段:基于 PubChem-xTB 数据集(约 6400 万分子结构),采用几何恢复的 3D 自监督目标,让模型学习通用的分子空间表征。
物理对齐中间训练:这是 MPA 的核心创新。MIRA 在迭代过程中发现,并非所有辅助任务都能提升下游性能,只有与目标性质共享物理机制的辅助监督才有效。
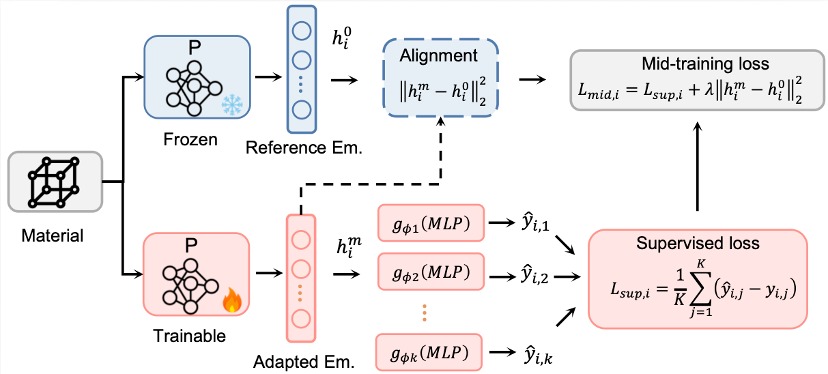
后训练阶段:MIRA 在迭代中还自主发现了两个关键改进。第一,将 MSE 损失替换为 Huber 损失,在 scaffold split 下带来 2.65% 的 MAE 降低,有效抑制了实验数据中异常值的干扰。第二,设计了混合读出头(hybrid readout),将注意力池化分支与原子加和分支结合。
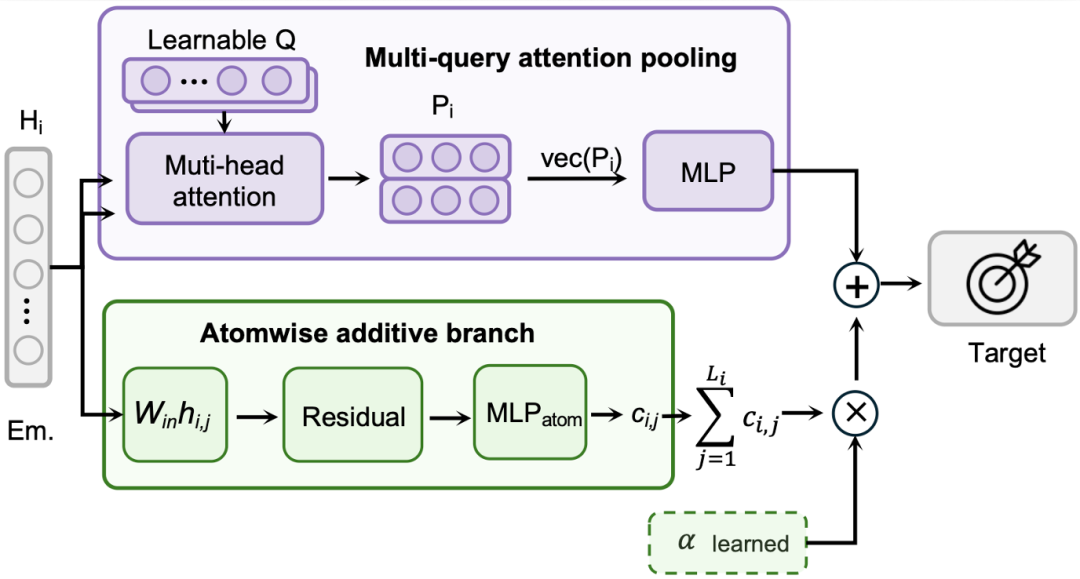
其中注意力分支提供灵活的非加和分子摘要,适合强度性质;加和分支强制原子级分解,适合广延性质。可学习系数 α 让模型自动适配不同性质的物理结构。
这个设计的精妙之处在于,它将物理先验编码进了模型架构本身。对于热力学量(生成焓、燃烧焓、热容等),加和分支提供了天然匹配的归纳偏置,scaffold split 下 MAE 降低高达 21.38%。对于非加和性质(闪点等),注意力分支则占据主导。
最终战绩
MPA 的最终版本,配合三阶段训练框架(预训练 → 物理对齐的中间训练 → 后训练),成绩单如下:
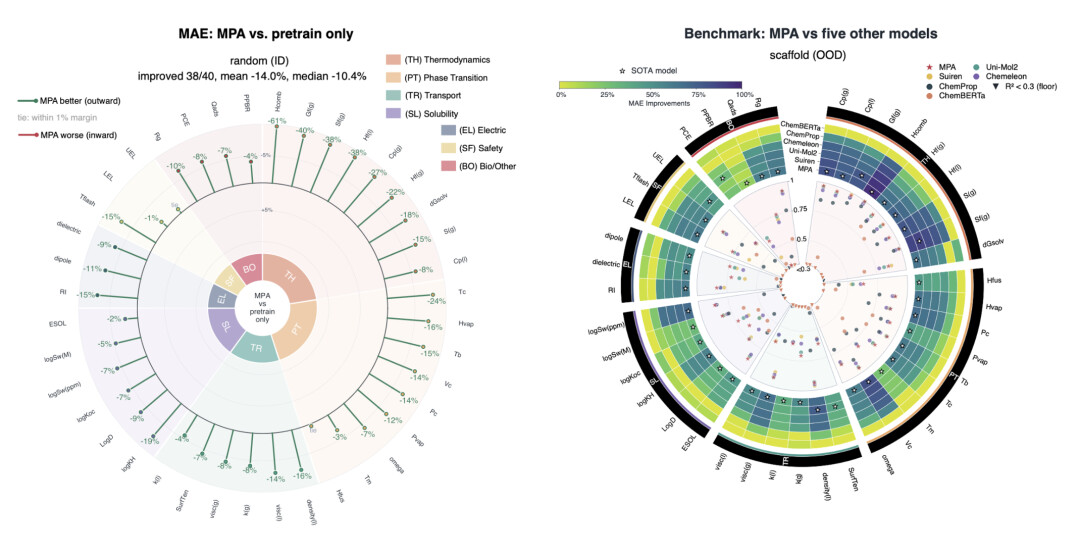
-
与仅进行预训练的模型结构相比,40 个实验性质中 38 个获得提升,平均误差降低 14.0%
-
热力学性质优势最突出:燃烧焓误差降低 51.1%,吉布斯自由能降低 31.6%
-
与 Suiren 正面对决:40 个可比端点中赢下 35 个,平均误差再降 5.4%
-
分布外泛化鲁棒性最强:面对全新分子骨架时,MPA 的性能退化仅 25.7%,而 Suiren 为 31.8%
最后一点尤其重要。在实际材料发现中,你要预测的往往是从未见过的新分子。MPA 在这种「真正的考试」中表现最稳,这才是它对产业界最有价值的地方。
迭代实录,进化的飞轮已经转动
之前讲的那些干净利落的模型架构和成就全新 SOTA 的实验结果,背后是 MIRA 在一个月时间内尝试的上百轮「假设 → 验证 → 调整」循环。
每一轮,MIRA 根据之前的结果自主决定下一步做什么。上百轮尝试贯穿了数据整合与计算、模型架构调整、训练策略迭代、损失函数设计、超参数优化,以及推理阶段的优化与增强。其中,数据、模型架构、损失函数及推理阶段的的升级成就了 MPA 的 SOTA 表现。
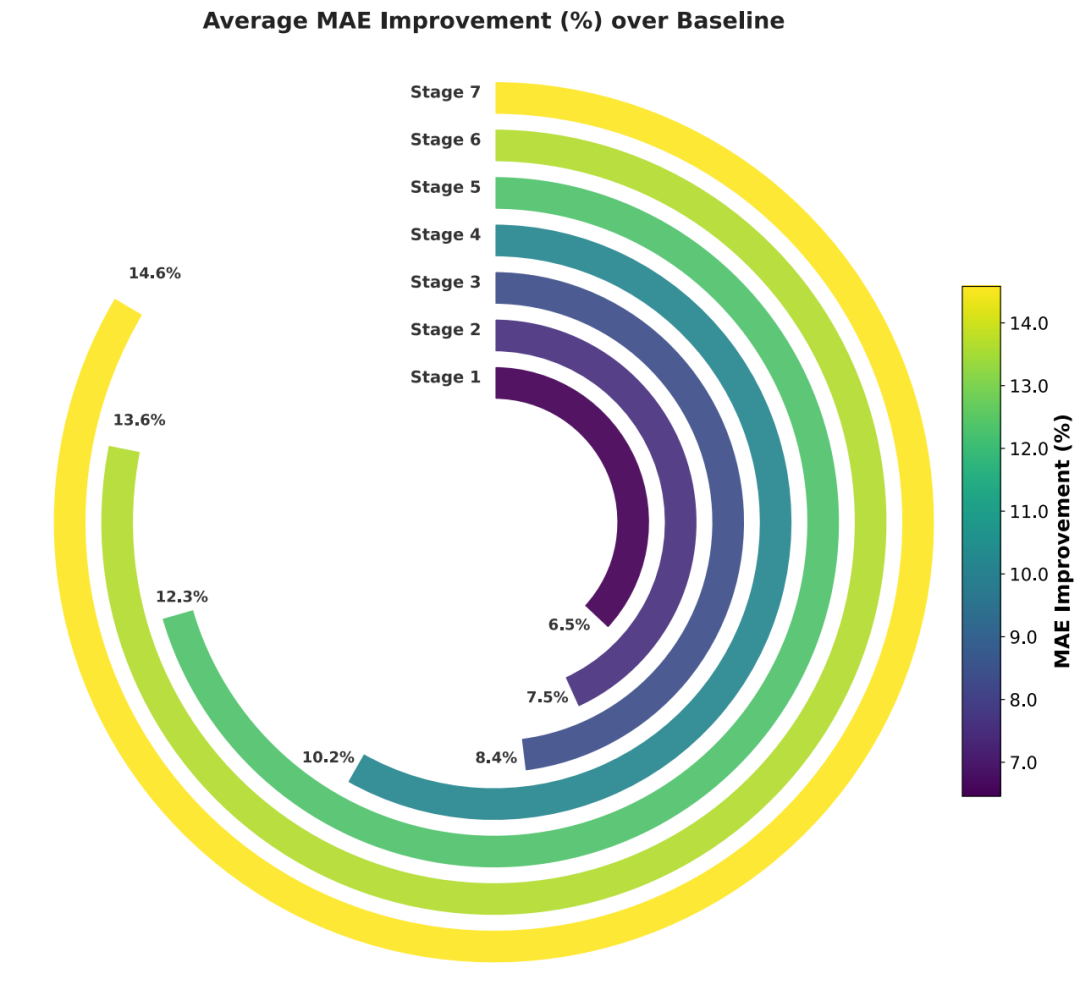
在数据侧,MIRA 做了三次有效的尝试。MIRA 在分析了模型的表现后判断:模型从预训练直接跳到下游微调,中间缺了一层「物理直觉」。为此,MIRA 使用使用 deep research、计算化学相关的技能 ——yamo,最终得到了理论计算的热力学、偶极矩等数据,在此基础上,MIRA 从文献中获取了油水分配系数(logP)数据集,并自主完成了一个关键步骤:将基准测试中出现过的分子从训练集中剔除,以避免数据泄漏风险。在这三次数据叠加中,MPA 实现了 MAE 降低 6.5%、7.5%,最终降低 8.4% 的表现。
到这里,MIRA 做出了一个关键判断:继续堆数据的边际收益在递减,应该转向模型结构的改进。它发现下游微调阶段只用了简单的多层感知机(MLP)做预测头,还有很大的改进空间。
接下来的十几轮迭代中,MIRA 在模型结构方面做了两次有效的尝试,在第一次改进中,MIRA 将 MLP 替换为了多头注意力机制,MAE 又降低了 1.8%。在另一次改进中,MIRA 发现了一个物理层面的规律:40 个实验性质,有一部分具有「广延性」,即性质值随分子大小线性缩放,另一部分则是「强度性质」,和分子大小无关,因此在多头注意力之外,MIRA 增加一条原子级 embedding 经过残差网络后求和的通路。这条通路显式表达了广延性质「各部分之和等于整体」的物理规律。这个发现让 MAE 继续降低至 12.3%。模型学会了「什么性质该用什么物理假设」。
在损失函数和模型推理测,MIRA 在迭代中做了发现了两种有效的策略,一种是将损失函数从 MSE 换成 Smooth L1(Huber 损失),这降低了少数极端值对模型训练的拖累,使得 MPA 在 benchmark 中的 MAE 又降低了 1.3%;一种是在推理阶段加入了多构象信息聚合,这有效的提升了模型在构象相关性质上的表现。最终,MAE 降低至 14.6%。
如果 AI 能在材料科学这样一个高度专业化的领域自主完成从 0 到 SOTA 的全流程,那它在其他科学领域呢?在 AI for AI 本身呢?
MIRA 做的事情,本质上是用 AI 来改进 AI。它重构了一个 AI 模型的代码,优化了这个 AI 模型的训练数据,迭代了这个 AI 模型的训练策略,最终产出了一个更强的 AI 模型。人类在这里的角色已经从「执行者」变成了「目标设定者」,AI 在用 AI 做原料,产出更好的 AI。
一旦这个飞轮转起来,每一圈都比上一圈转得更快。
从 Coding Agent 自动写代码,到 Research Agent 自动做科研,再到 Self-Improving Agent 自动改进自身,AI 智能体的能力边界正在以一种加速度向外扩展。每一次成功的递归迭代,都在缩短我们与 AGI 之间的距离。
递归进化的齿轮已经转动,AGI 可能比我们预想的来得更快。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com