LingBot-VA 用自回归视频-动作世界模型,让机器人先预测未来再行动,50条演示即可完成复杂操控。
原文标题:RSS 2026|蚂蚁灵波提出首个自回归因果世界模型,50条数据解锁通用机器人操控
原文作者:机器之心
冷月清谈:
怜星夜思:
2、每个任务只用 50 条真实演示就能微调成功,这说明机器人低数据学习快要成熟了吗?
3、2Hz 的闭环控制频率对真实机器人够用吗?复杂操作会不会还是太慢?
4、视频世界模型真的能学到“物理因果”吗,还是只是在记忆训练数据里的视觉模式?
原文内容

赋予机器人物理理解和预测能力是通用操作的关键。蚂蚁灵波等机构提出的 LingBot-VA 试图将视频帧预测与动作推理统一起来,让机器人通过自回归扩散框架学会“一边思考一边行动”。
在通用机器人领域,机器人控制需要的不只是“看懂”当前画面 ,还需要预测未来。如果一个模型不能理解“推倒杯子会导致水洒出来”这种物理因果关系,它就很难在复杂环境中做出正确规划。然而,实现稳健的物理推理和预测能力一直是核心难题。当机器人面对需要长程规划、高精度操作或处理柔性物体的复杂任务时,它们往往显得笨拙且难以适应环境的动态变化。
当前主流的视觉-语言-动作(VLA)模型通常直接将视觉观察映射到动作,或者依赖于单帧或短时间窗口的预测。然而,这种端到端的范式缺乏显式建模物理过程的机制,导致模型容易陷入轨迹记忆。同时,将任务视为马尔可夫过程并丢弃历史信息,使得模型在部分可观测和长程任务中难以消除歧义。此外,现有的视频生成模型通常采用破坏因果关系的双向注意力机制,且推理延迟过高,难以满足机器人高频控制的需求。
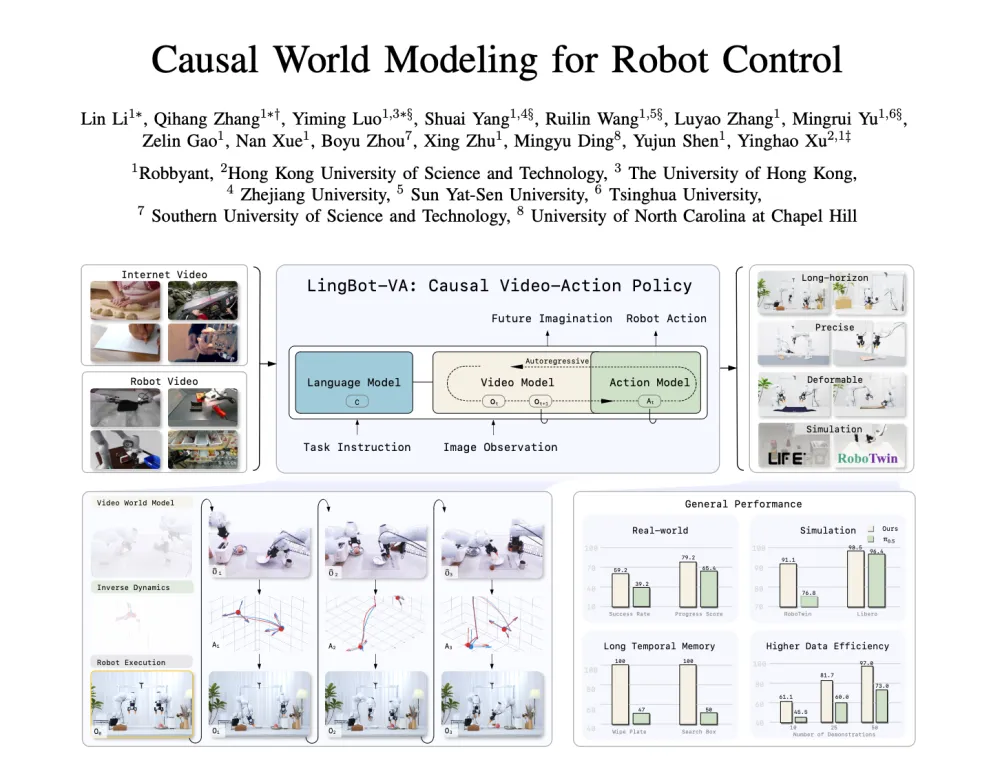
针对上述问题,来自蚂蚁灵波科技、香港科技大学等机构的研究团队提出了 LingBot-VA,一种全新的自回归(AR)视频-动作世界模型,通过统一视频动态预测和动作推理,将物理世界的因果结构融入机器人控制中。该模型不直接学习动作分布,而是先预测视觉世界将如何演变,然后基于这些预测推断动作。这种解耦使得模型可以利用大规模视频数据学习物理先验,同时只需少量机器人演示数据就能将这些先验转化为可执行的动作。
-
论文链接:
https://arxiv.org/abs/2601.21998
-
项目主页:
https://technology.robbyant.com/lingbot-va
LingBot-VA:统一视频与动作的自回归生成
LingBot-VA 的核心在于将视频和动作标记(tokens)交错成单一的因果序列,通过自回归方式联合建模环境动态和机器人动作。
为了弥合现有方法与真实世界复杂性之间的鸿沟,LingBot-VA的设计初衷是为了真实地模拟和预测物理世界的完整交互流程。
-
交错式自回归生成:LingBot-VA 采用了一种创新的混合 Transformer(Mixture-of-Transformers, MoT)架构。该架构将视频流和动作流解耦但交错处理,特定模态的专家在严格的因果掩码下工作:高容量的视频专家根据观察-动作历史预测未来的视觉状态,而轻量级的动作专家则推断与这些预测一致的动作。这种非对称设计既能捕捉复杂的场景过渡,又能保持极低的单步动作解码成本。
-
持久且高效的历史整合:不同于固定长度窗口的方法,LingBot-VA 的因果公式允许每次预测都基于完整的过去观察-动作流。在推理时,模型仅将真实的观测结果输入到 KV 缓存中,从而将策略锚定在实际的交互历史中。KV 缓存极大地分摊了长序列生成中的计算成本,赋予了模型强大的时间记忆能力。
-
噪声潜在增强实现快速推理:视频去噪是推理时的主要计算瓶颈。研究团队敏锐地发现,机器人控制需要的是高级语义结构,而非像素级完美的细节。因此,他们在训练中引入了噪声潜在增强策略,允许动作专家直接从部分去噪的视频潜在表示中解码动作。在部署时,这使得模型可以提前截断视频去噪过程,在保持动作精度的同时大幅提升推理速度。
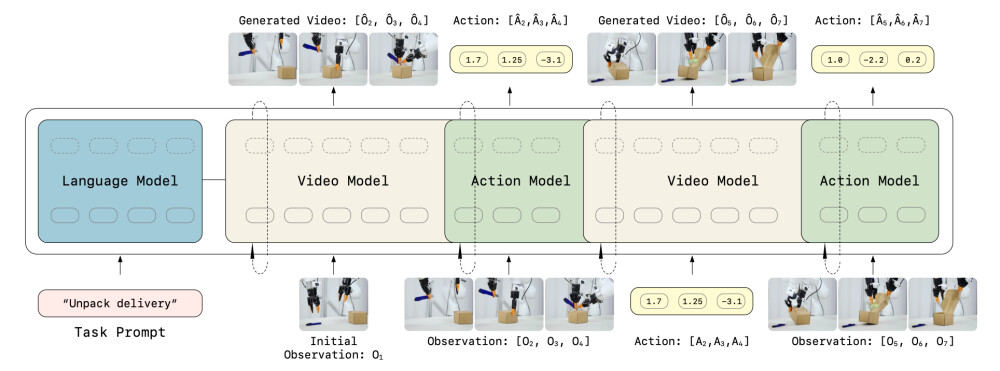
LingBot-VA 的实现遵循了一个严谨的流程,以确保其高质量和可靠性:
1、统一架构设计:采用基于视频生成预训练模型初始化的视频流和较小的动作流组成的双流 MoT 架构。
2、状态编码与对齐:使用因果视频 VAE 将原始视觉观察压缩为紧凑的潜在标记,并通过 MLP 将动作向量投影到相同维度,实现跨模态的统一交错。
3、两阶段预测机制:第一阶段(视觉动态预测)学习给定历史预测未来视觉观察;第二阶段(逆动力学)从期望的视觉过渡中解码出具体动作。
4、高效训练策略:采用教师强制(Teacher Forcing)和流匹配(Flow Matching)技术,在单一前向传递中并行优化视频和动作组件。
实验验证与模型性能:
50 条数据解锁真实世界操控
研究团队在真实物理平台和多个仿真基准上对LingBot-VA 进行了评估。
在真实世界部署中,LingBot-VA 执行了三类极具挑战性的任务:长程任务(如做早餐、拆快递)、高精度任务(如插入管子、捡螺丝)和柔性物体操作(如叠衣服、叠裤子)。令人惊讶的是,每个任务仅使用了 50 个真实世界的演示数据进行微调。
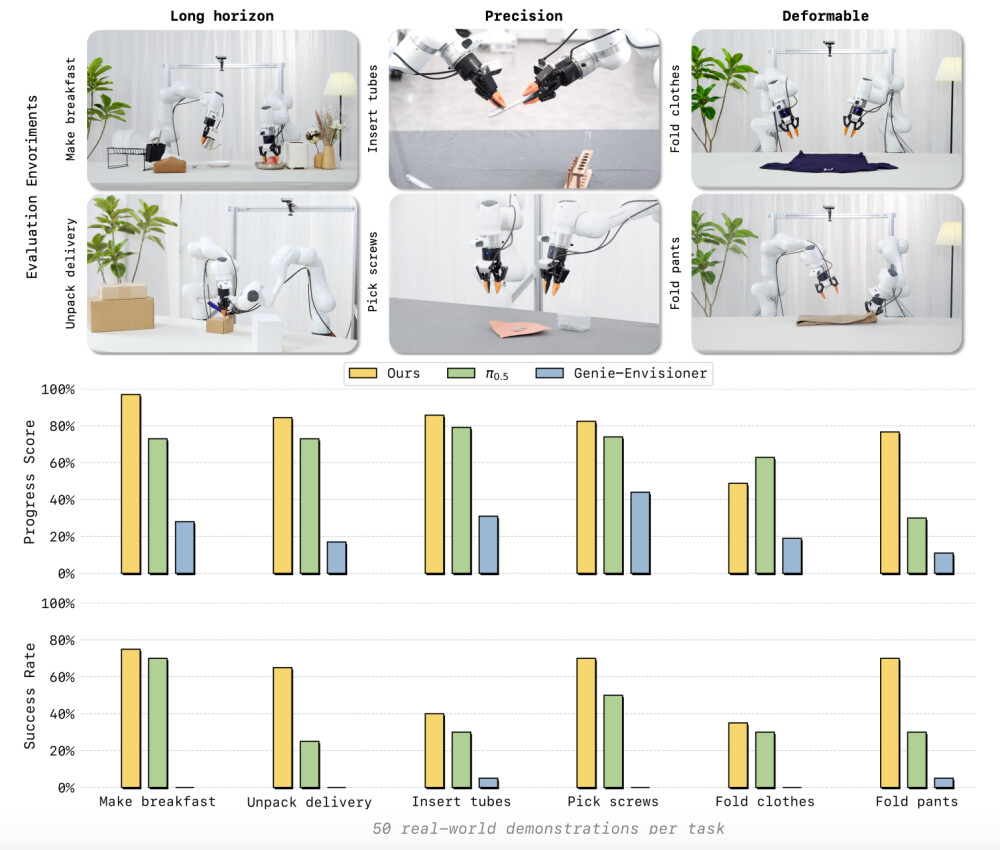
实验结果显示,LingBot-VA 在所有六个任务的成功率和进度得分上均达到了 SOTA 水平,显著超过了强基线模型 π0.5 和Genie-Envisioner。特别是在长程任务上的卓越表现,充分证明了其强大的时间记忆能力;而在柔性物体上的稳健表现,则凸显了视频生成作为隐式引导预测物体动态的巨大价值。
在 RoboTwin 2.0 这一包含 50 个任务的双臂操控基准测试中,LingBot-VA 同样展现了统治力。在 Easy 设置下,它取得了 92.0% 的平均成功率;在更具挑战性的 Hard 设置下,成功率也高达 91.1%。随着任务复杂度的增加,LingBot-VA 的优势愈发明显,其自回归机制有效地维持了长程时间记忆,确保了多步推理的连贯性。
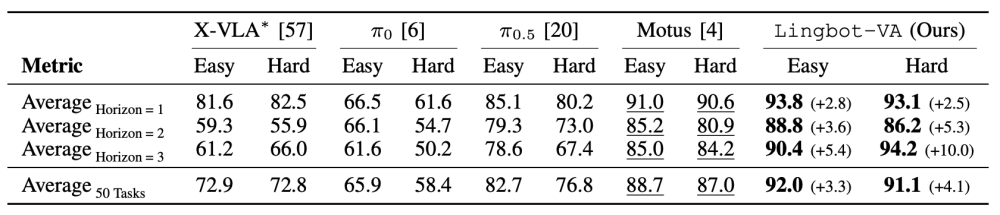
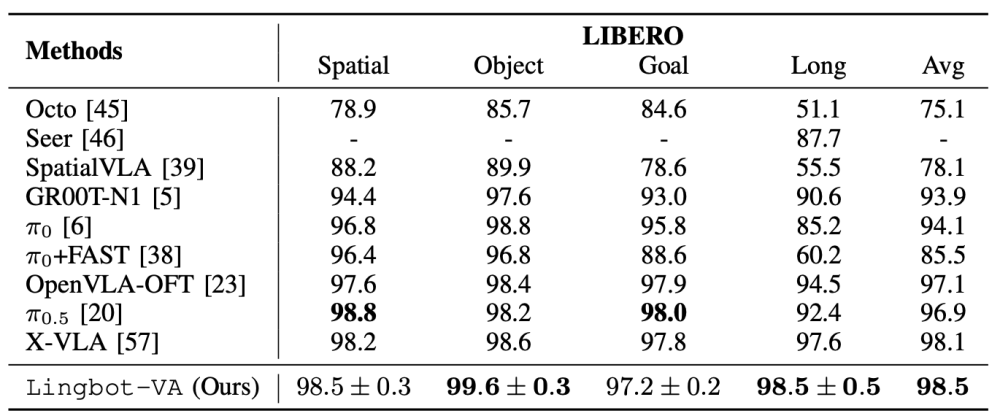
此外,在LIBERO基准的四个任务套件(Spatial, Object, Goal, Long)中,LingBot-VA 则达到了 98.5% 的平均成功率。
消融实验进一步证实了核心设计的必要性:移除视频预测模块会导致成功率从 92.93% 断崖式下跌至48.31%;而放弃因果公式采用双向注意力,也会使性能显著下降至 81.46%。
LingBot-VA 不仅性能强大,而且极其高效。在低数据量(仅 10 个演示)的情况下,它依然能够稳定超越基线模型,展现出惊人的样本效率。在推理延迟方面,得益于噪声潜在增强策略,在单张 RTX 5880 Ada GPU 上,每次闭环控制步骤仅需约 0.5 秒,实现了约 2Hz 的有效控制频率,完全满足了真实世界部署的需求。
总结与未来展望
研究团队提出的 LingBot-VA 为解决通用机器人控制中的物理推理和长程规划问题提供了一个全新且高效的思路。通过将视频动态预测与动作推理统一在自回归扩散框架下,LingBot-VA不仅在理论上进行了创新,更通过充分的实验证明了其卓越的性能和数据效率。它成功地将生成式世界模型的强大预测能力引入了机器人具身操作,向实现机器人“一边思考一边行动”迈出了坚实的一步。
在未来的工作中,研究团队计划探索更高效的视频压缩方案以进一步降低计算开销,并尝试融入触觉、力觉、音频等多模态传感器输入,以应对具有复杂接触动力学的更广泛应用场景。LingBot-VA 的出现,无疑为具身智能和通用机器人的发展注入了新的强劲动力。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com