中科大 LCPO 用少量数据训练,让推理模型显著缩短思维链且准确率不降反升。
原文标题:告别长篇废话!中科大极简训练破解大模型过度思考难题
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、减少思维链长度会不会牺牲模型的可解释性?你更在意过程还是答案?
3、LCPO 这种“小数据偏好优化”会不会成为以后模型降本的常规操作?
4、模型“想太多”导致出错,这和人类反复检查反而改错答案是不是很像?
原文内容

本文约1700字,建议阅读5分钟本文介绍了中科大 LCPO,轻量训练实现大模型精简推理且准确率提升。
你有没有遇到过,问大模型一个简单数学题,它却洋洋洒洒写了 5000 多字才出答案?这种“过度思考”不仅烧钱费时,还容易把对的改成错的。
现在,中科大研究团队提出了 LCPO(Length Controlled Preference Optimization),仅需 800 条数据、50 步训练,就让模型学会“言简意赅”——推理长度砍半,准确率甚至不降反升!
这项工作已被学术顶会 ICLR 2026 接收,代码已开源,感兴趣的小伙伴可以一探究竟:

论文标题:
Pruning Long Chain-of-Thought of Large Reasoning Models via Small-Scale Preference Optimization
论文链接:
https://arxiv.org/abs/2508.10164
源码链接:
https://github.com/SleepyWithoutCoffee/Small_Scale
1、大模型越来越聪明,也越来越“啰嗦”
以 DeepSeek-R1、QwQ-32B 为代表的大型推理模型(LRMs)靠长思维链(Long CoT)在数学、编程等复杂任务上大放异彩。但它们有个通病:
-
明明很简单的问题,也要长篇大论写一堆推理过程;
-
输出越长,计算成本越高,推理速度越慢;
-
更糟的是,面对简单的问题“想太多”有时反而容易出错——这就是所谓的过度思考(overthinking)。
现有的解决方案要么是推理时强行截断(效果不稳定,还伤性能),要么是大规模在线强化学习(Online RL)。后者训练系统复杂,动辄需要几十万条训练数据、上千 GPU 小时的算力投入。
于是,研究团队提出了两个核心问题:
-
第一,在模型已有的生成空间里,到底存不存在既短又对的推理路径?
-
第二,怎么用极少的训练和数据,把模型“推”到那条更高效的路径上?
2、关键发现:模型本就有“简洁模式”,只是没被激活
团队先用 DeepSeek-R1-Distill-Qwen-7B 做了个实验:对每个问题生成 16 个回答,按长度排序,观察准确率变化。
结果非常有意思:短回答(长度排名靠前的那些)准确率几乎不降,而长回答(排名靠后的)准确率反而暴跌。
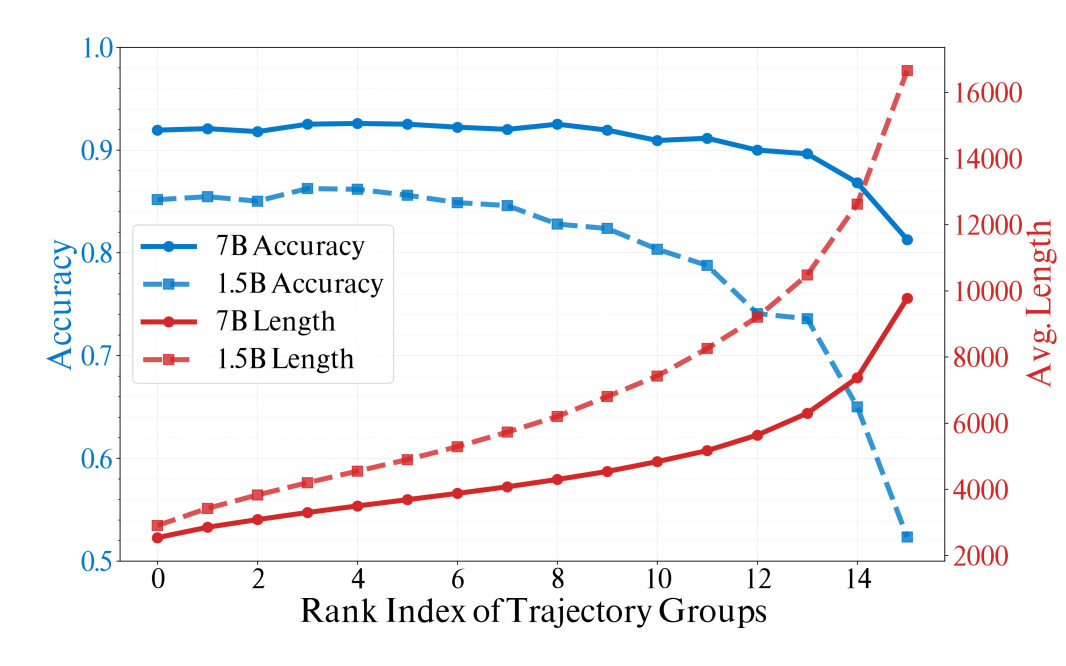
〓 长度分组实验
这说明什么?模型天生就会简洁推理,只不过它的“默认出厂设置”偏啰嗦。 我们不需要教它新知识,只需要用合适的方法把它推向那个更高效的生成分布即可。
2、方法揭秘:三步走,四两拨千斤
基于上述洞察,团队设计了一套极致轻量的训练流程。
数据筛选:只学“学霸的简洁版答案”
他们用模型自己的答题正确率作为难度标签,把数学问题分成三档:
-
Easy(全对):模型已完全掌握,没必要长篇大论;
-
Medium(部分对):有点难度,但还能搞定;
-
Difficult(全错):真不会,需要充分探索。
训练时只用 Easy 部分,并且把最短的正确回答作为“正面榜样”,最长的回答作为“反面教材”。这样一来,数据里全是“本来就会做的题,应该短且对”的强烈偏好信号,总共只用到 2.2 万条原始数据,实际用于训练的样本仅 800 条。
算法创新:LCPO,平衡“隐式 NLL 损失干扰”
团队深入分析了现有偏好优化方法(DPO、SimPO、ORPO 等)的目标函数,发现一个隐藏问题:负对数似然损失(NLL Loss)会干扰长度偏好学习。
在偏好学习使用的 sigmoid 函数中,“藏着” NLL Loss:

而这部分 Loss 会影响 sigmoid 的收敛。如果模型要完全学会一种长度为 1000 的解答,需满足:
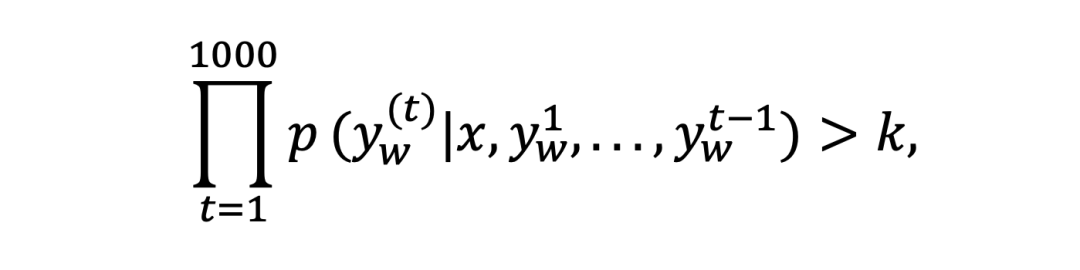
实践中, 可以取 ,而模型生成每个词汇的概率一般为 0.05~0.5,很难满足这一条件。 简单来说,NLL Loss 会让模型过度拟合“正面回答”的表面形式,反而削弱了“短 vs 长”的对比学习效果,学不好高效推理的思维。
为此,他们提出了 LCPO,通过相同的数学形式直接平衡 NLL 的影响,让模型纯粹聚焦于长度偏好。而且,LCPO 无需任何超参数调优,开箱即用!
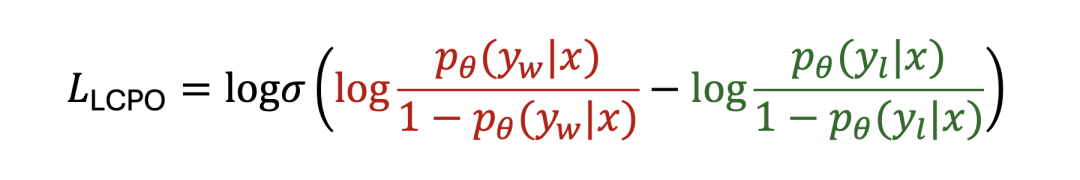
极致轻量:训练成本降低两个数量级
对比一下同类方法的资源需求:
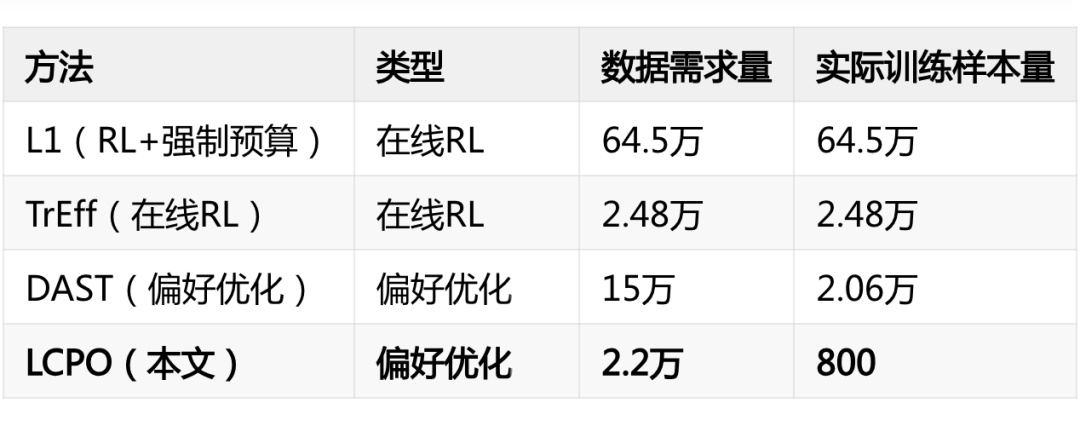
该方法数据需求降低 1~2 个数量级,总训练成本仅约 10.4 A100 小时,而同类在线 RL 方法动辄上千小时。
4、效果明显:长度砍半,性能基本保持
在 DeepSeek-R1-Distill-Qwen-1.5B/7B 上的实验结果如下:
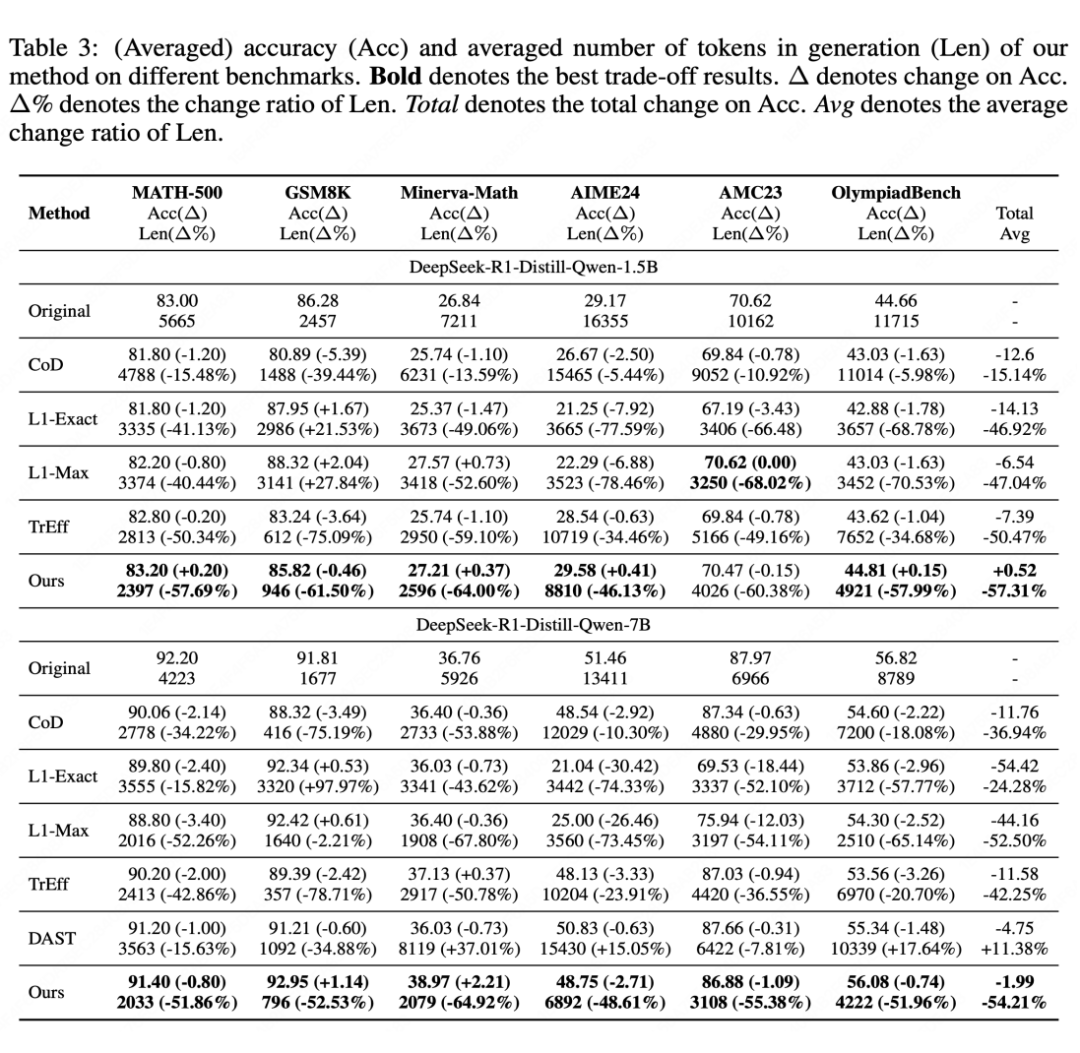
〓 主要实验结果
更惊喜的是,即使仅在数学数据上训练,在训练数据以外的任务(如 MMLU、GPQA-Diamond、WinoGrande)上,模型依然保持长度缩减超 55% 的同时准确率稳中有升——说明它学到的是通用的“高效思考习惯”,而非死记硬背。
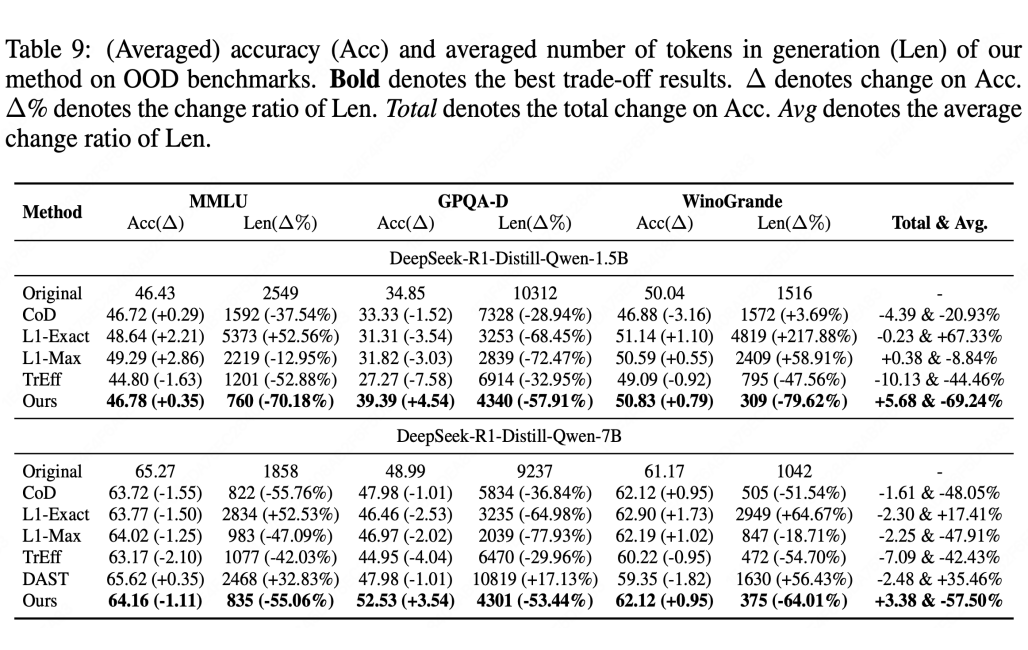
〓 OOD 实验结果
来看一个具体的例子:一道使用换底公式简化计算的简单数学题。在训练前,模型会在各个环节深入思考,在已经得到答案时依然陷入深深的“自我怀疑”,各种反复验算高达 8 次才给出最终回答!而在掌握“高效推理”的思维之后,仅做一次验算,既可以验证答案,又不至于过度谨慎,token 损耗直降 79.37%!
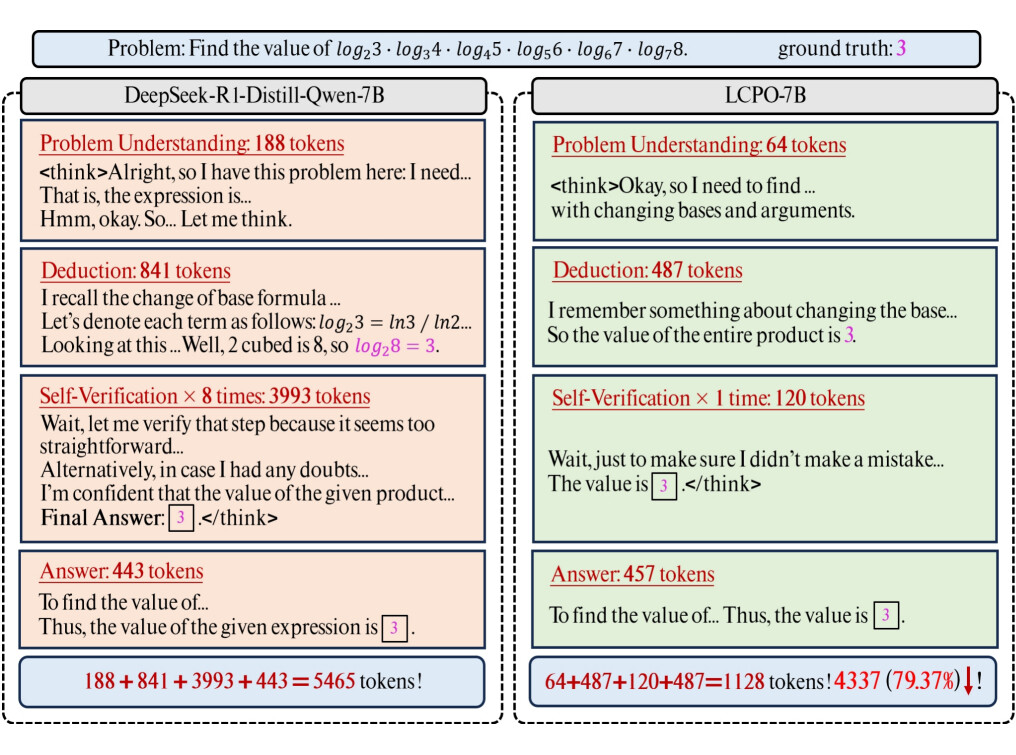
〓 case
5、启示与展望
这项工作的核心价值,在于揭示了一个深刻洞察:
大模型的生成空间中本就蕴藏着高效推理路径,我们只需用精巧的信号把这种思维“引导”出来,而不必大规模“改造”。
这为低成本、高效率的大模型行为对齐开辟了新思路:
-
模型面对简单问题自动“快速思考”,不再因输出过长而等待;
-
API 调用成本大幅下降,agent 使用更轻松;
-
减少“想多了”的窘境,有助于降低因“过度思考”而引入的失误。
编辑:于腾凯
校对:林亦霖
