DiffusionOPD 用在线策略蒸馏整合扩散模型的构图、文字与美学能力。
原文标题:DiffusionOPD:复旦联合通义万相提出扩散模型「在线策略蒸馏」新范式,让学?模型同时学会构图、?字与美学
原文作者:机器之心
冷月清谈:
怜星夜思:
2、如果一个图像生成模型同时追求文字准确、构图合理和画面好看,这三者之间会不会天然存在冲突?
3、在线策略蒸馏和普通离线蒸馏相比,真正关键的差别在哪里?为什么文章强调学生要用自己的轨迹?
4、DiffusionOPD 这类方法如果落地到文生图产品里,用户最容易感知到的提升会是什么?
原文内容

扩散模型在单一任务上的强化学习已经取得了显著进展,例如提升文字生成质量、增强构图准确性,或优化画面美感等。但当这些能力需要同时集成到同一个模型中时,训练往往会变得十分困难:不同任务之间容易产生相互干扰,训练目标也会变得复杂而不稳定。
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。
基于这一观点,他们提出了 DiffusionOPD,为 diffusion 领域的 On-Policy Distillation 提供了一个统一视角,并建立了相应的理论与实验框架。
DiffusionOPD 的核心思路,是先针对不同任务分别训练各自的「专家教师」模型;随后,再通过在线策略蒸馏,将这些教师模型的能力统一蒸馏到同一个学生模型中,实现多任务能力整合。最终,一个统一的 student model 便能够同时兼顾构图、OCR、美学等多项能力。

-
论⽂标题:DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
-
论文地址:https://arxiv.org/abs/2605.15055
-
项⽬主⻚:https://quanhaol.github.io/DiffusionOPD-site/
-
代码链接 https://github.com/ali-vilab/DiffusionOPD
多任务强化学习方法
过去常⻅的多任务强化学习⽅法主要有两类。
联合多任务 RL (Joint Multi-Task Optimization) :使用现有的 RL 算法例如 DiffusionNFT, GRPO 去联合优化多个任务。这种范式会撞上两个问题: 1 奖励冲突:不同任务的优化⽅向往往存在相互干扰; 2 任务失衡:简单任务会主导训练过程,导致复杂任务难以充分学习。
级联 RL (Cascade RL):按阶段依次训练不同任务。虽然能够缓解任务冲突,但是训练流程复杂,需要分别调整各阶段的超参数与训练策略,而且容易产生灾难性遗忘,后续任务训练的时候会削弱已有能力。
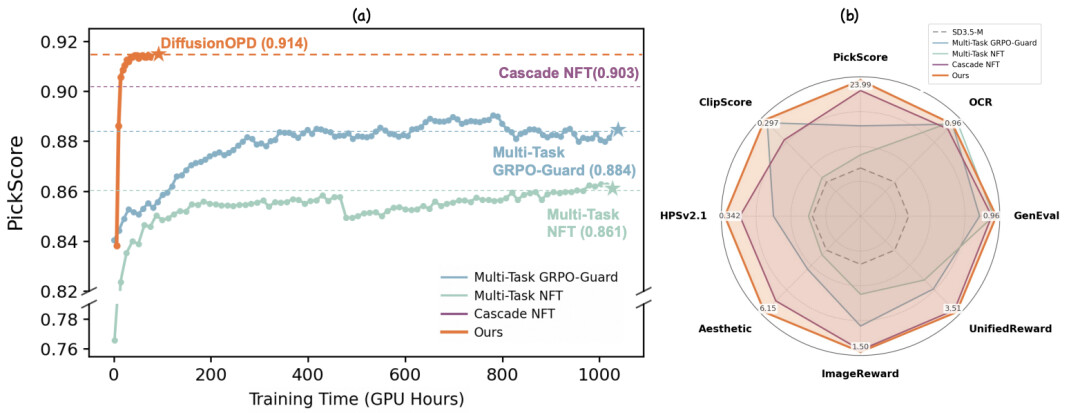
图 1:(a)相比所有多任务强化学习基线方法,DiffusionOPD 展现出显著更快的收敛速度以及更高的性能上限。(b)在包括 GenEval、OCR 与美学在内的多个任务领域中,DiffusionOPD 均优于所有基线方法。
DiffusionOPD: 单任务探索 + 多任务整合
DiffusionOPD 给出的答案⼲脆利落:多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。

整体训练过程可分为两个阶段
-
Stage 1・单任务⽼师独⽴训练:针对不同任务(如 GenEval、OCR、Aesthetic 等),分别使用现有的 diffusion RL 方法训练对应的「专家教师」模型。其中,GenEval 任务采用 DiffusionNFT,OCR 与美学任务采用 GRPO-Guard。由于每个教师仅负责单一任务,因此能够避免跨任务干扰。
-
Stage 2・在线策略蒸馏多任务能力到学⽣模型:随后,从一个预训练扩散模型初始化统一的学生模型,并通过在线策略蒸馏整合多任务能力。在训练过程中,学生模型针对不同任务,基于自身策略生成去噪轨迹;随后,在学生生成的每个去噪状态上,由对应任务的教师模型提供监督信号。因此,学生模型无需重新对所有任务进行从零探索,而是能够直接学习各任务教师的策略与能力,从而实现高效的多任务能力融合。
Diffusion 领域 OPD 的⽬标函数推导
在 LLM 中,OPD 的做法很自然:学生模型先按照自己的策略生成 token,随后教师模型在学生访问到的每一个 token 状态上提供监督。由于语言模型本身是离散 token 分布,因此可以直接对每一步的 token distribution 做 KL 蒸馏。
但 diffusion model 不一样。它不是离散 token 序列,而是一个连续状态的去噪过程。
因此作者首先把 diffusion 的去噪过程重新视作一个 continuous-state Markov chain(连续状态马尔可夫链)。在这个视角下,每一步去噪 transition 都对应一个 Gaussian transition kernel;学生模型和教师模型分别定义自己的 transition distribution:
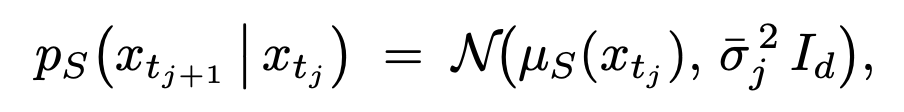
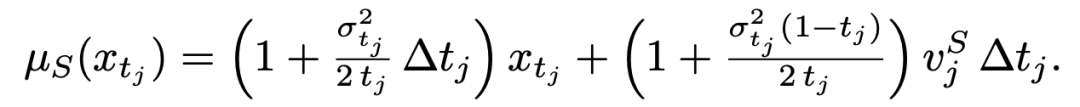
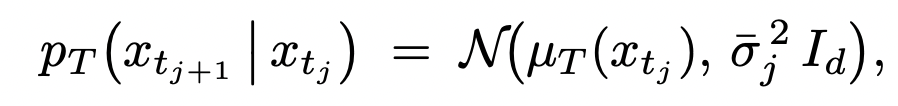
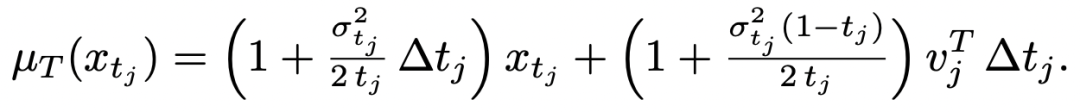
接着,论文进一步推导发现:由于 student 和 teacher 的 transition covariance 是相同的,于是整个扩散版 OPD ⽬标 reverse KL,就被写成了⼀个完全解析、⽆ Monte-Carlo ⽅差的均值匹配损失:
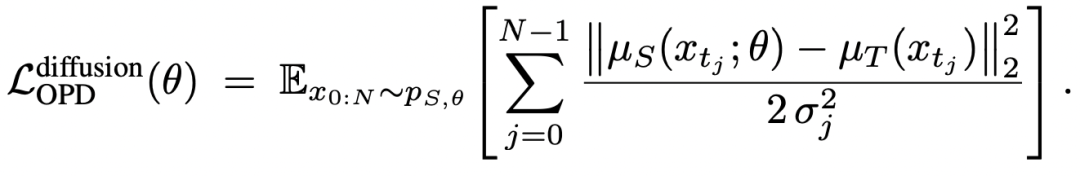
作者进一步指出这一框架同时统一了 stochastic SDE sampler 与 deterministic ODE sampler。在 ODE 情况下目标会退化成均值之间的 L2 匹配。
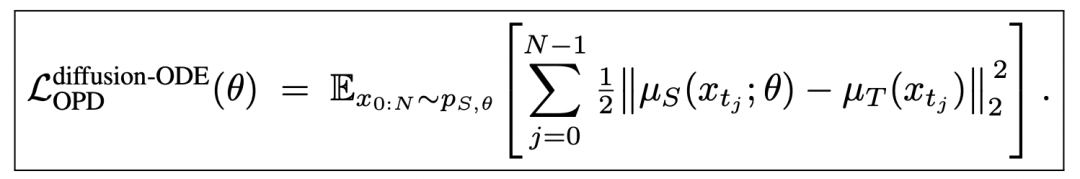
与 PPO-style policy gradient 的比较
另一个一非常自然的想法是:把老师当作「过程奖励模型」,把 KL 损失看作每一个去燥步的 dense reward 然后计算 advantage,最后套一个 PPO 的损失函数。
DiffusionOPD 论文里严格证明了直接闭式 KL 与 PPO -style policy gradient 在期望意义下梯度完全相等。但 PPO 的梯度里会多出一项 score-function 项,它与高斯噪声成正比,期望为零但方差不为零。也就是说,PPO 估计天然比闭式 KL 更「吵」。
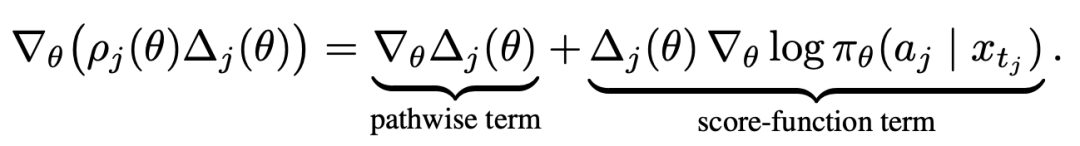
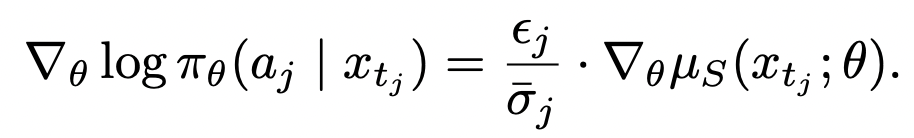
更关键的是 PPO 形式离不开 logprob 与 ratio 的计算,因此它在 ODE 确定性采样器下根本无法定义,仅仅支持 SDE sampler。
实验结果
1.与多任务强化学习方法的对比
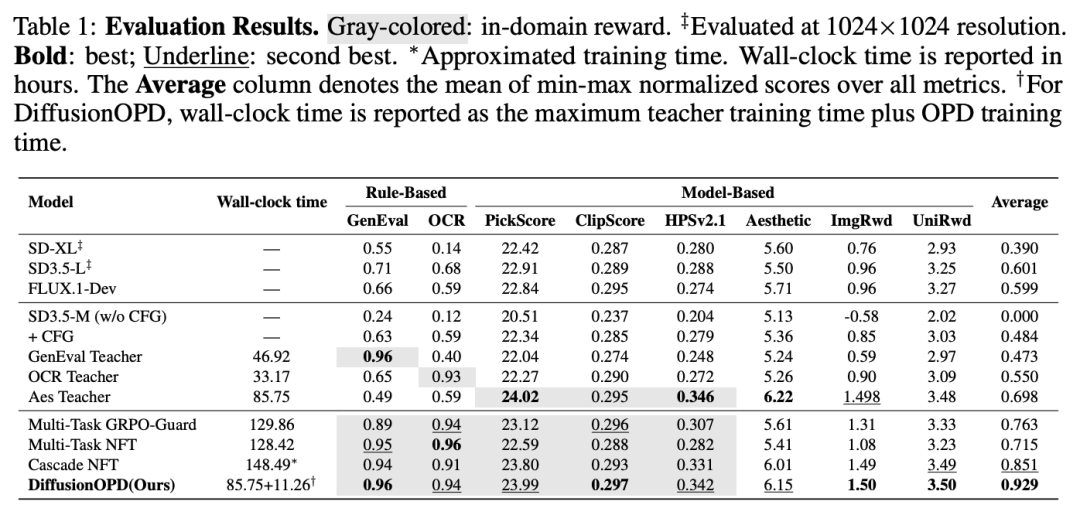
定量效果对比:
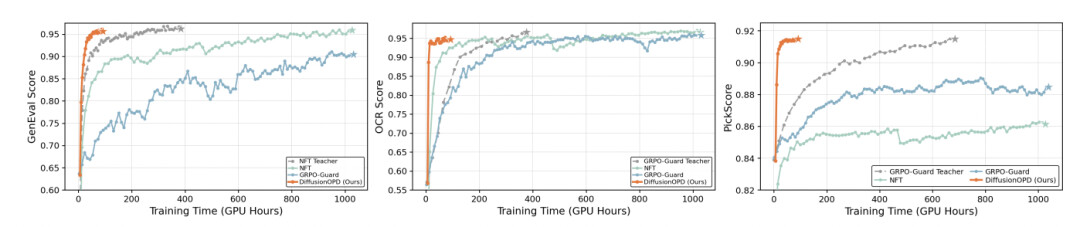
训练曲线对比:
定性效果对比:

图 2:与多任务强化学习方法以及单任务教师模型的定性对比结果。每个案例分为两行展示:第一行从左到右依次为 DiffusionOPD(本文方法)、Multi-Task GRPO-Guard、Multi-Task NFT 和 Cascade NFT;第二行从左到右依次为输入文本、Aesthetic Teacher、GenEval Teacher 和 OCR Teacher 的生成结果。
2.蒸馏方法消融:
作者还做了一组很有意义的对照实验:固定同一批专家老师,分别用 DiffusionOPD、DMD、TDM、SFT 蒸馏到同一个学生,控制变量后对比谁更适合「多任务能力整合」这个场景。
训练曲线对比:
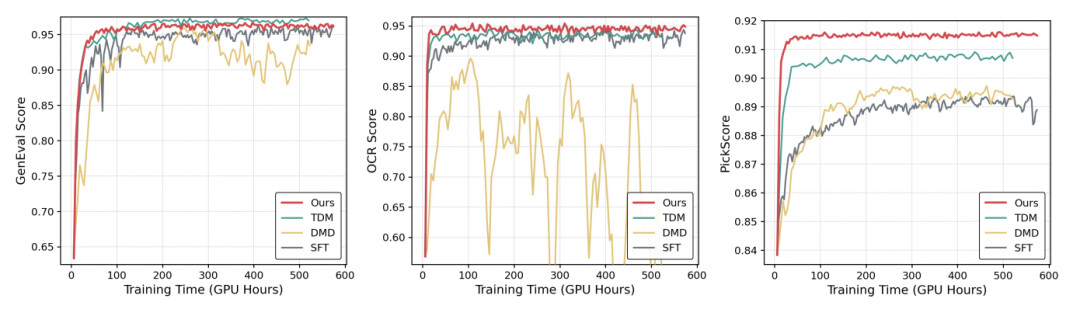
曲线表示同样的老师、同样的采样设置,DiffusionOPD 在收敛速度和上限上都明显更好。
定性效果对比:

图 3:与不同蒸馏方法的定性对比结果。从左到右依次为:DiffusionOPD(本文方法)、DMD、TDM 和 SFT。
3.Loss 形式以及 Sampler Type 消融

图 6:关于损失函数形式与采样器噪声水平的消融实验。当噪声水平设为 0 时,SDE sampler 将退化为 ODE sampler。实验结果表明,PPO-style policy gradient 的表现逊于同样 noise level 的 closed-form KL objective;此外,更低的噪声水平能够带来更快的收敛速度和更高的性能上限。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com