Mila 与 DeepMind 提出 UNSL,用统一函数建模多变量缩放规律、瓶颈、拐点和过拟合。
原文标题:多变量神经缩放定律迈向大一统:Mila联手DeepMind提出UNSL
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章里说 scaling 会出现瓶颈和拐点,你觉得实际训练中最常见的瓶颈是数据、模型大小,还是训练时间?
3、UNSL 把学习率、初始化尺度这类超参数也纳入缩放定律,这是不是说明传统 scaling law 太理想化了?
4、如果一个 scaling law 函数越来越复杂,它的可解释性和泛化能力会不会反而变差?
原文内容
过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。
但真实训练过程要复杂得多。模型性能不只受参数量和数据量影响,还会受到训练步数、处理 token 数、数据是否被重复使用、batch size、学习率、初始化尺度,以及推理时计算量等因素影响。
更麻烦的是,这些变量之间并不是简单相加关系:某个变量可能在特定区间成为瓶颈,也可能让性能曲线出现阶段性「拐点」,甚至带来非单调变化。比如,训练数据太少或训练超过一定 epoch 后可能出现过拟合;学习率或初始化权重标准差过大,也可能反过来损害性能。
针对这些限制,来自蒙特利尔大学 Mila、Google DeepMind 的研究者提出了一种全新的函数形式,称为统一神经缩放定律(Unified Neural Scaling Law,简称 UNSL),它把多变量同时变化、拐点、瓶颈、过拟合以及超参数带来的反向作用统一纳入 scaling law。
所以,这篇论文的主张可以概括为:神经网络的 scaling behavior 不应该只用「参数量 — 数据量 —loss」这样的二维或三维公式描述,而应该用一个能同时处理多变量、阶段性转折、性能瓶颈、过拟合和超参数影响的统一函数形式。

-
论文标题:Unified Neural Scaling Laws
-
论文链接:https://arxiv.org/pdf/2605.26248
论文一作 Ethan Caballero 用一段视频,展示了「统一神经缩放定律」准确建模和外推人工神经网络在多个变量同时变化时呈现出的多变量缩放定律。
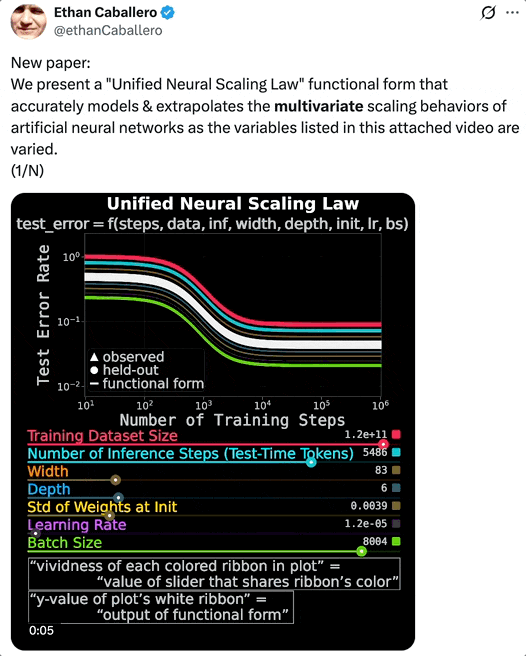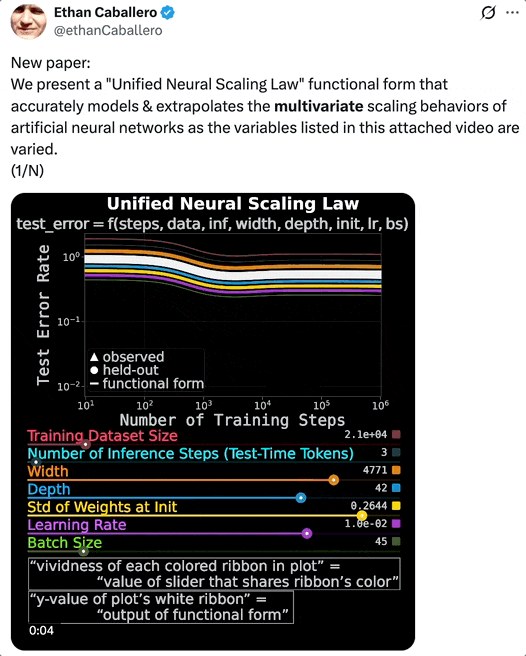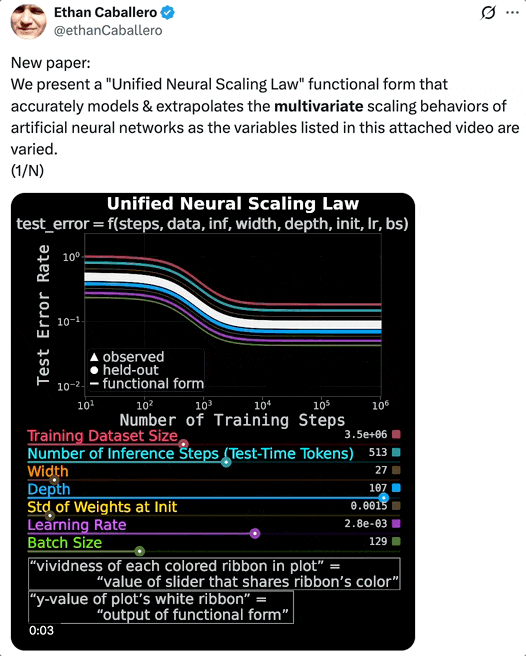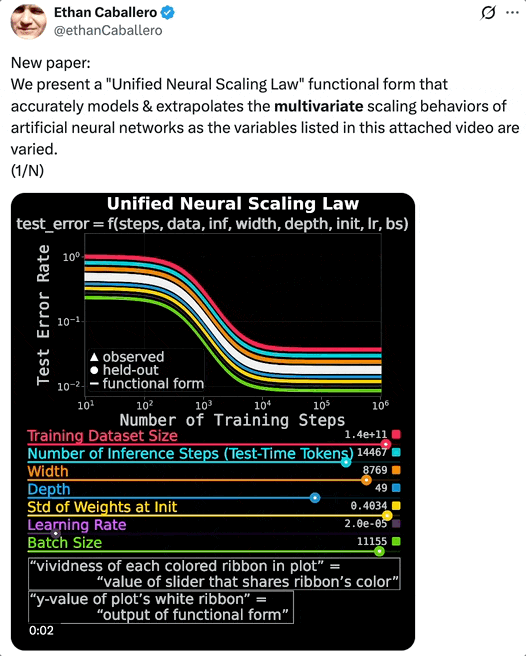
UNSL 的函数形式
UNSL 的完整架构是由多个分层函数嵌套而成的,它在多维对数空间中将性能建模为一组平滑连接的超平面:
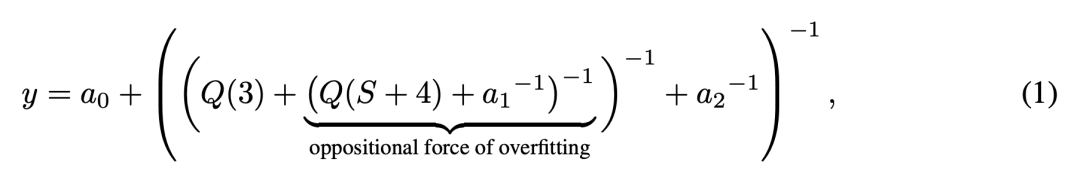
其中 Q 定义如下:
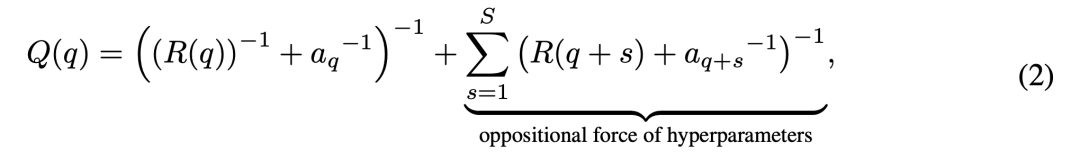
R 定义如下:
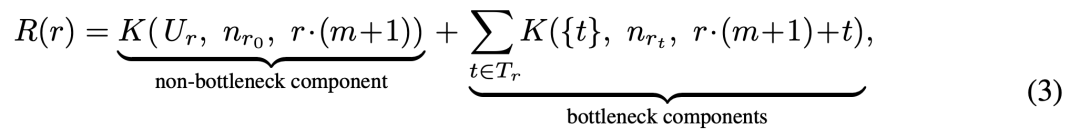
K 为多变量断裂神经缩放定律(Multivariate Broken Neural Scaling Law,MBNSL),定义如下:
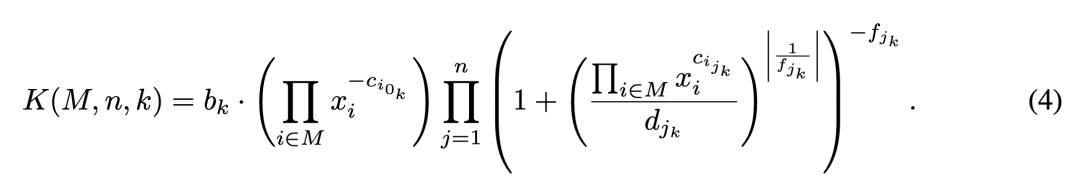
整体上可以像下面这样理解:
在函数形式上,UNSL 不是简单把参数量、数据量和训练步数塞进一个幂律公式,而是采用了一套分层结构。
底层的 K 是多变量 broken scaling law,用来描述 log-log 空间中由多个平滑连接超平面构成的 scaling 曲面;其中的 hyperbreak 对应性能曲面中的阶段性转折。
再往上一层,R 将整体 scaling 行为拆成非瓶颈组件和瓶颈组件,分别描述多变量共同作用下的整体趋势,以及某一单独变量限制最终性能的情况。瓶颈组件表示,当其他变量都足够好时,某一个变量仍可能单独限制性能。例如模型够大、训练够久,但数据量不足,数据量就成为瓶颈;或者数据足够多,但模型太小,参数量成为瓶颈。
Q 则进一步引入学习率、初始化尺度等超参数可能带来的反向作用。
最外层公式再加入不可约性能极限、评价指标导致的坏表现极限,以及训练超过一定 epoch 后可能出现的过拟合项。
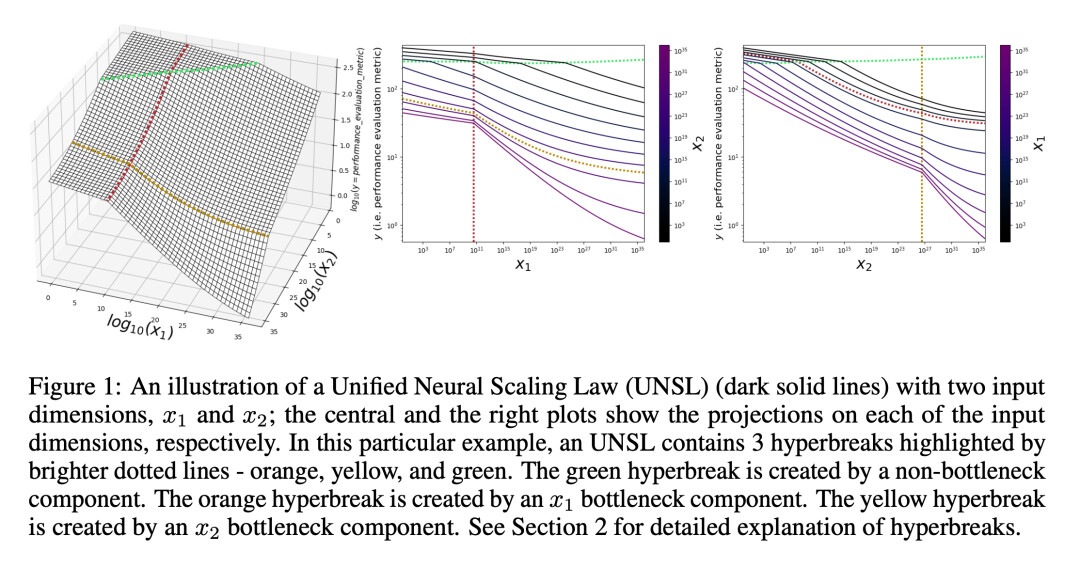
下图为统一神经缩放定律(Unified Neural Scaling Law,UNSL)的示意图,包含两个输入维度 x_1 和 x_2;中间图和右侧图分别展示了它在各个输入维度上的投影。
在这个具体例子中,一个 UNSL 包含 3 个 hyperbreak,也就是图中用更亮的虚线标出的橙色、黄色和绿色转折结构。Hyperbreak 可以理解为 scaling law 中的「阶段转折」。例如一开始增加数据带来明显收益,过了某个区间收益下降,这个转折就是一种 break;多变量情况下,它不再是一点,而是高维空间里的转折面。
其中,绿色 hyperbreak 由非瓶颈组件产生;橙色 hyperbreak 由 x_1 瓶颈组件产生;黄色 hyperbreak 由 x_2 瓶颈组件产生。
实验结果
在实验部分,研究者对比了以下几类函数形式。
第一类是已有 scaling law 形式,包括 CF 和 DC。CF 接近 Kaplan、Chinchilla 一类常见形式,主要描述参数量、训练数据量或训练 token 数与 loss 之间的关系。DC 来自 Muennighoff 等人的三变量函数形式,考虑参数量、训练 token 数和训练数据集大小。
第二类是作者设计的消融版本:A1、A2、A3。它们可以理解为 UNSL 的逐步简化版。其中 A1 去掉了 additive symmetry,A2 加入了性能下限项,A3 进一步加入部分反向作用结构;完整 UNSL 包含全部 additive symmetry、瓶颈组件、非瓶颈组件、过拟合项和超参数反向作用项。
接下来,研究者主要做了视觉和语言两大类实验。
在视觉任务中,研究者评估了下游少样本图像分类,包括 Birds 200、Cars 196 和 ImageNet。模型包括 ViT、MLP-Mixer 和 BiT,它们在 JFT-300M 子集上预训练。变量包括训练数据集大小、训练步数,以及在三变量设置中的模型参数量。结果显示,在下游图像识别任务中,UNSL 在 60.87% 的任务上取得最好的外推表现,而下一个最好的 A3 是 21.74%。
在语言任务中,研究者评估了上游和下游语言表现,变量包括模型参数量、处理 token 数、训练数据 token 数等。下游任务包括 LAMBADA 和 CSR,其中 CSR 是 HellaSwag、ARC、PIQA、WinoGrande、OpenBookQA、SIQA、BoolQ 等常识推理任务的零样本平均错误率。结果显示,在语言任务中,UNSL 在 88.89% 的任务上外推最好,而下一个最好的 A2 是 11.11%。

更细化地讲,视觉部分实验分为二变量和三变量两类:二变量设置中同时变化的是训练数据集大小和训练步数,三变量设置中同时变化的是训练数据集大小、训练步数和模型参数量。
在三变量视觉实验中,UNSL 的优势非常直接。以 Birds 和 ImageNet 为例,UNSL 都取得最低 RMSLE。尤其和 DC 相比,误差下降非常明显,说明只靠传统三变量形式不足以描述视觉模型在参数量、训练数据和训练步数同时变化时的外推趋势。

语言部分实验同时覆盖上游语言建模表现和下游任务表现。三变量语言实验使用 Muennighoff 等人的 scaling behavior 数据,三个同时变化的维度是 模型参数量、处理过的 token 数、训练数据集中的 token 数。二变量语言实验则关注模型参数量与训练步数 / 处理 token 数的关系。
在三变量语言实验中,UNSL 的 RMSLE 明显低于 A3、A2 、A1 和 DC。也就是说,在这个设置下,UNSL 的外推误差大约只有 DC 的八分之一左右。

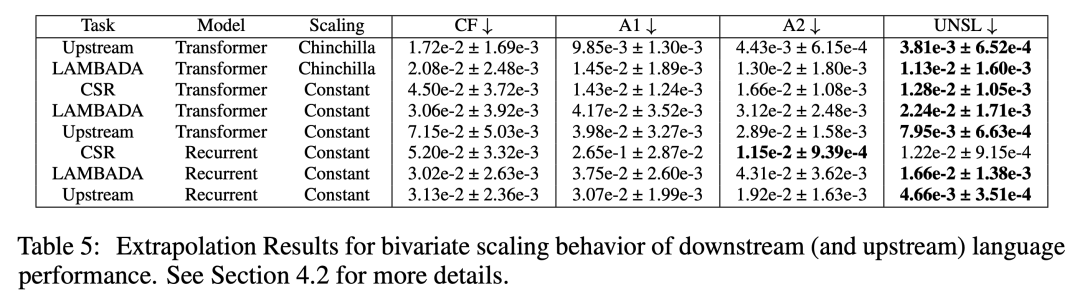
二变量语言实验也体现了类似趋势。在下表 5 中,UNSL 在大多数任务上取得最低误差。
除了主文中的视觉和语言任务,论文还在附录中给出更多场景,试图说明 UNSL 的适用范围更广。UNSL 可以外推强化学习中的多变量 scaling behavior,可以处理宽度和深度同时变化的 scaling,还可以把 batch size 作为输入变量;另外,UNSL 还被用于学习率、初始化权重标准差和训练步数同时变化的三变量 scaling behavior。
一系列实验结果表明,UNSL 的优势不在于简单拟合历史数据,而在于它能在多变量同时变化的情况下,更稳定地预测模型性能随规模扩展的走势。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com