通过浏览器录制真实请求,再让AI生成接口封装和E2E测试用例,显著降低复杂平台自动化测试成本。
原文标题:基于浏览器请求录制与AI代码生成的E2E接口自动化测试实践
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、让 AI 自动生成测试代码后,测试工程师的核心价值会不会被削弱?
3、录制真实请求用于生成测试代码,会不会带来安全和隐私风险?应该怎么控制?
4、这种“录制一次生成用例”的方式,如何避免测试用例过度依赖当前页面实现,导致稍微改版就失效?
原文内容

阿里妹导读
以阿里云DataWorks为例,介绍如何通过浏览器录制插件捕获真实请求数据,结合AI编程工具自动生成接口封装与测试用例,解决复杂平台产品自动化测试中接口多、参数杂、数据流深的核心难题。(文章内容基于作者个人技术实践与独立思考,旨在分享经验,仅代表个人观点。)
一、引言:复杂平台产品的自动化测试之痛
在企业级软件测试领域,有一类产品让自动化测试工程师感到尤为头疼——复杂业务逻辑的平台型产品。
以阿里云DataWorks为例,它是一个集数据开发、数据集成、数据质量、数据地图、数据服务、运维中心、数据治理等十余个子模块于一体的大型平台。这类产品有几个显著的测试难点:
1. 接口数量庞大且无标准文档
这类平台的前端与后端通过大量HTTP请求进行通信,涉及近20个微服务端点。这些接口大多是内部网关层封装,没有像OpenAPI那样标准化的接口文档——测试工程师想知道"创建一个数据质量规则需要调哪个接口、传什么参数",唯一的办法就是打开浏览器开发者工具,手动操作一遍,然后从Network面板中找到对应请求。
2. 接口间存在复杂的数据流依赖
一个完整的测试场景往往需要串联5~20个接口调用。例如,测试"创建数据质量自定义模板规则"这一功能,需要先查询目录树,创建目录,检查名称是否冲突,再创建模板,最后查询验证——每个接口的返回值(如目录ID、模板ID)都是下一步的入参,数据流环环相扣。
3. 多版本并行演进
产品以季度为周期持续迭代,接口路径、参数结构、返回体格式都可能发生变化。测试框架需要同时维护多个版本的接口封装,旧版本不能动,新版本要新增。
4. 认证机制复杂
不同于简单的Token认证,这类平台的HTTP请求需要Cookie加CSRF Token双重认证,且不同版本的获取方式不同。

二、传统人工编码时代:
一个测试工程师的典型一天
让我们回到AI辅助编码工具出现之前,看看一个测试工程师要怎样为这类平台编写一个E2E自动化测试用例。
2.1 工作流程总览
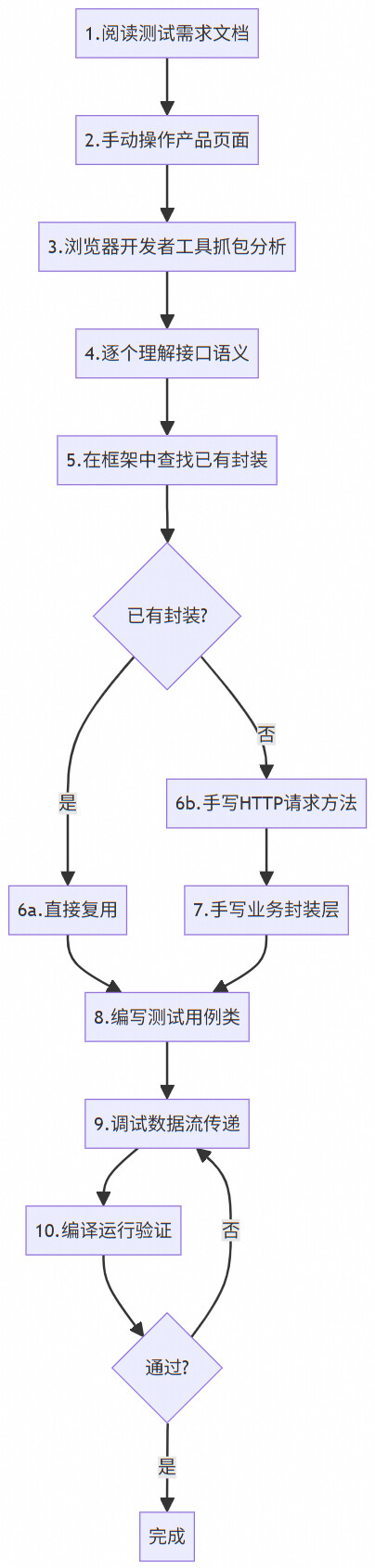
2.2 各阶段的具体工作
阶段一:需求理解与抓包(约1小时)
测试工程师首先需要理解这个测试用例要覆盖什么功能。然后打开浏览器,手动在平台上执行一遍完整的测试操作。
这个过程中,工程师需要同时打开浏览器开发者工具,切换到Network面板,仔细观察每一步操作触发了哪些接口调用。关键问题在于:
-
一次页面操作可能触发5到10个请求,其中只有1到2个是真正的业务请求,其余是心跳、静态资源、权限校验等
-
工程师需要凭经验判断哪些请求是核心业务请求
-
需要逐个点开请求,手动记录URL路径、请求方法、请求体结构、返回体结构
阶段二:接口封装(约2小时)
确认需要封装的接口后,工程师要做几件事:
-
在现有代码中搜索:框架中有近20个接口封装模块,总计数千个方法,需要用IDE全局搜索确认是否已有同类封装
-
理解HTTP请求封装模式:框架的HTTP请求通过统一方法发送,需要理解URL参数、Body参数的构建方式
-
手动编写代码:将抓包得到的请求信息翻译为代码
// 手动编写的HTTP请求封装示例
public ApiResponse createQualityRule(Long projectId, String ruleName,
Integer ruleType, String checkExpression, Long tenantId) {
return httpClient.post("/api/quality/rules")
.queryParam("projectId", projectId)
.body(new JSONObject()
.put("projectId", projectId)
.put("ruleName", ruleName)
.put("ruleType", ruleType)
.put("checkExpression", checkExpression)
.put("tenantId", tenantId)
)
.execute();
}
这里最容易出错的地方是:参数名拼写错误、参数遗漏、数据类型不匹配。因为全程是人工从开发者工具面板中手抄过来的,一个驼峰拼写的差异就会导致接口调用失败。阶段三:用例编排(约1~2小时)
接口封装完成后,需要在测试用例类中确定继承关系、编写初始化方法、将多个接口调用按正确的业务顺序编排、处理接口间的数据流(前一个接口的返回值作为后一个接口的入参)、编写断言。
阶段四:调试修复(约1小时)
这往往是最耗时的阶段:参数名写错导致接口返回400、数据类型不匹配导致JSON解析异常、接口调用顺序错误导致业务逻辑报错、返回体字段路径取错导致空指针。
保守估计,传统方式编写一个中等复杂度的测试用例(涉及10到15个接口),需要5到6小时。
三、新范式:录制插件 + AI编程的化学反应
3.1 核心思路转变
传统方式的本质问题在于:人需要充当"接口信息的搬运工"——从浏览器Network面板手动搬运到代码中。这个过程不仅低效,而且极易出错。
新范式的核心思路是:
让录制插件自动捕获完整的请求-响应信息,让AI自动理解这些信息并生成正确的代码。
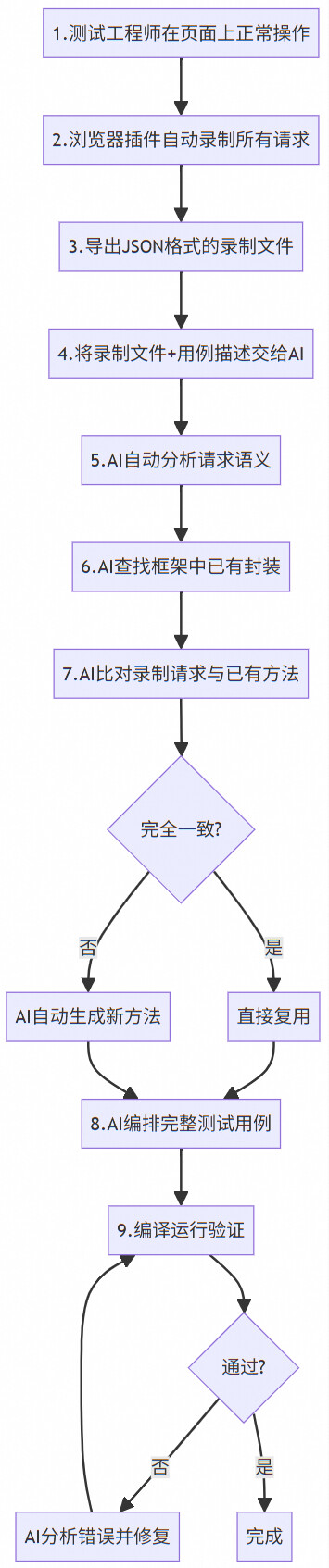
3.2 录制插件:从"人眼抓包"到"机器捕获"
我们开发了一个浏览器扩展,专门用于自动捕获测试过程中的所有网络请求。
使用流程
从使用者的角度看,录制插件的操作极其简单:

插件提供四按钮状态机(开始/暂停/继续/停止),并实时显示录制计数。录制过程中,插件在后台自动拦截页面发出的所有XHR/Fetch请求,捕获完整的请求体和返回体,自动过滤非业务请求(如静态资源、心跳包),并按时间戳统一排序。
录制数据格式
录制结果以JSON数组导出,每条记录包含完整的请求-响应对:
[
{
"method": "GET",
"url": "https://bff.example.com/api/quality/tree?projectId=100001",
"requestBody": null,
"responseBody": "{\"requestId\":\"xxx\",\"data\":[ ],\"code\":200}"
},
{
"method": "POST",
"url": "https://bff.example.com/api/quality/catalog?projectId=100001",
"requestBody": "{\"projectId\":100001,\"parentId\":0,\"level\":1,\"name\":\"测试文件夹\",\"tenantId\":700000000000}",
"responseBody": "{\"requestId\":\"xxx\",\"data\":{\"id\":12},\"code\":200}"
}
]
这份数据对AI来说是一份"完美的接口说明书"——它同时包含了接口路径和HTTP方法、完整的请求参数结构(字段名、类型、示例值)、完整的返回体结构(嵌套层级、字段路径),以及接口间的调用顺序和数据依赖关系。
3.3 AI编程工具:从"信息理解"到"代码生成"
有了录制数据后,AI编程工具可以执行以下自动化流程:
Step 1:请求智能过滤
AI自动识别并过滤掉非业务请求(静态资源、心跳、预检请求等),只保留与测试逻辑相关的核心业务请求。
Step 2:框架复用性检查
AI在已有的接口封装模块中搜索,按三级优先级查找可复用方法:业务封装层(最高优先级)→ HTTP请求层(次优先级)→ 公共SDK层(再次优先级)→ 需要新封装。
Step 3:录制请求比对
即使找到了已有方法,AI也会逐一比对录制请求与已有封装在URL路径、请求参数、返回体结构上的差异。发现差异时,AI会自动创建新版本方法,保证旧方法完全不受影响。
Step 4:完整代码生成
AI一次性生成HTTP请求封装层加测试用例编排层的完整代码,包括新的HTTP请求方法、测试类的初始化、步骤方法、断言、资源清理,以及正确的数据流传递(前一个接口返回的ID作为下一个接口的入参)。
3.4 实际使用方式:测试工程师只需做两件事

输入1:录制文件
测试工程师打开产品页面 → 点击浏览器插件"开始录制" → 执行完整的测试操作 → 点击"停止录制" → 自动下载JSON文件
输入2:用例描述(自然语言)
测试用例名称: 数据质量自定义模板管理
测试步骤:
1. 查询质量目录树,确认初始为空
2. 创建目录文件夹
3. 检查模板名称唯一性
4. 创建自定义规则模板
5. 查询用户自定义模板列表,验证创建成功
输出:完整的可运行代码
AI自动生成包含接口封装、测试用例编排、断言验证、资源清理的完整代码。
四、两种方式的深度对比
4.1 效率对比
|
维度 |
传统人工编码 |
录制+AI生成 |
提升倍数 |
|
接口信息获取 |
1小时(手动抓包+记录) |
5~10分钟(自动录制) |
6~12x |
|
接口封装编码 |
2小时(手写HTTP方法) |
1~3分钟(AI自动生成) |
40~80x |
|
用例编排 |
1~2小时(手动编排数据流) |
1~3分钟(AI自动编排) |
20~40x |
|
调试修复 |
1小时(排查参数错误) |
10~30分钟(AI辅助修复) |
3~6x |
|
总计 |
5~6小时 |
20~50分钟 |
7~15x |
4.2 准确性对比
|
问题类型 |
传统方式出错概率 |
AI+录制方式出错概率 |
原因 |
|
参数名拼写错误 |
高 |
极低 |
AI直接从录制JSON解析,不存在手抄问题 |
|
参数遗漏 |
中 |
极低 |
录制数据包含完整参数集 |
|
数据类型不匹配 |
中 |
极低 |
AI从录制的实际值推断类型 |
|
返回体字段路径错误 |
高 |
极低 |
AI从录制的完整返回体解析路径 |
|
接口调用顺序错误 |
低 |
极低 |
录制数据天然保留了正确的时间顺序 |
|
编码规范违反 |
高 |
极低 |
AI内置了完整的团队编码规范 |
4.3 知识沉淀对比

传统方式下,接口理解和框架使用的知识高度依赖个人经验,新人上手周期长。AI+录制方式将这些知识沉淀为结构化规范文档,AI作为"最了解框架的助手",确保每个工程师都能输出符合规范的代码。
五、核心优势深度剖析:
为什么"录制+描述"天然适合AI
5.1 录制数据是最佳的"接口说明书"
传统的接口文档(如Swagger)往往存在滞后、不完整、与实际不符等问题。而录制数据来自真实的页面操作,它天然具备以下特征:
-
绝对真实:录制的就是产品实际发送的请求,不存在文档与实现不一致的问题
-
上下文完整:不仅有请求结构,还有完整的返回体,AI可以准确知道每个字段的实际类型和值
-
顺序正确:录制按时间戳排序,天然保留了业务操作的正确顺序
-
依赖可推导:前一个接口返回的ID出现在后一个接口的请求体中,AI可以自动推导数据依赖关系
5.2 用例描述补充了业务语义
录制数据告诉AI"做什么"(What),用例描述告诉AI"为什么"(Why)和"验证什么"(Assert):
录制数据 = 完整的接口调用序列(机器可理解的事实)
用例描述 = 测试意图和验证目标(人类的业务期望)
二者结合 = AI可以生成既技术正确又业务准确的代码
5.3 有API文档也不够:
同一接口在不同场景下的传参差异
有人可能会问:如果产品提供了完整的API文档(比如Swagger),AI直接读文档生成代码不就行了,为什么还需要录制?
答案是:同一个接口,在不同页面位置、不同业务场景下的调用方式可能完全不同。 API文档只告诉你"这个接口支持哪些参数",但不告诉你"在这个具体场景下应该传哪些参数、传什么值"。
举一个真实例子:某个创建业务规则的接口,文档上列出了十几个参数。但实际上:
-
从"自定义创建"入口操作时,规则类型传固定枚举值,表达式字段是必填的
-
从"从模板克隆"入口操作时,规则类型从模板中继承,表达式字段不需要传递
-
从"跨空间导入"入口操作时,还会额外传递可见范围和来源空间参数
如果只看API文档,你根本不知道当前测试场景应该用哪种参数组合。只有真实录制——在页面上执行一遍具体的测试操作——才能捕获到这个场景下的精确参数排列组合。
API文档是接口的"能力边界",录制数据是场景的"精确快照"。AI需要的是后者。
这也是为什么我们坚持"录制驱动"而非"文档驱动"的根本原因。
5.4 一次性正确率极高
这是这种方式最突出的优势:
当测试工程师在页面上正确执行了完整的测试操作时,录制数据就是这个测试场景的"标准答案"。AI只需要将这个标准答案从JSON翻译为代码。
具体来说:接口封装层一定是正确的(URL路径、请求方法、参数全部来自真实请求),用例编排层一定是正确的(调用顺序就是录制时间线),数据流传递一定是正确的(AI可以自动识别前后请求的参数依赖),返回体解析一定是正确的(AI直接看到了完整的返回体结构)。
5.5 天然兼容版本演进
当产品迭代导致接口变化时:
-
传统方式:工程师需要重新抓包、比对差异、修改代码
-
新方式:重新录制一次 → AI自动对比差异 → 自动生成新版本方法
框架的版本兼容策略(旧方法不动,新增版本方法)与这种工作方式完美契合。
六、测试框架与AI的协作机制
6.1 分层架构设计
为了让AI能够准确生成代码,我们建立了清晰的测试框架分层体系:

-
测试用例层:编排业务逻辑、断言验证、功能点声明
-
业务封装层:高层业务抽象,组合多个底层HTTP调用
-
HTTP请求层:底层网络请求封装,一个方法对应一个API
6.2 AI的知识体系
我们将框架的所有规范编写为AI可理解的结构化知识文档,包含核心工作流程、编码规范与红线规则;类继承体系与模块架构地图;已封装接口的方法清单;以及典型用例的编写示例。AI在生成代码前会自动加载这些知识,确保生成的代码符合团队的所有规范约定。
七、实战示例:从录制到代码生成
以"数据质量自定义模板管理"为例,展示完整的工作流。
Step 1:录制
测试工程师在产品数据质量页面操作:查询目录 → 创建文件夹 → 检查模板名 → 创建模板 → 查询验证。
浏览器插件自动录制,导出JSON文件包含5条请求。

Step 2:AI分析与生成
AI收到录制文件和用例描述后,自动完成以下工作:
-
识别这是数据质量模块的测试场景
-
搜索已有封装中的相关方法
-
比对发现部分接口已有封装但参数有差异
-
生成新版本方法和完整测试用例
// AI自动生成的HTTP请求封装(参数精确匹配录制请求)
public ApiResponse createCatalog(Long projectId, Long tenantId,
Integer parentId, Integer level, String name) {
return httpClient.post("/api/quality/catalog")
.queryParam("projectId", projectId)
.body(new JSONObject()
.put("projectId", projectId)
.put("parentId", parentId)
.put("level", level)
.put("name", name)
.put("tenantId", tenantId)
)
.execute();
}
// AI自动生成的测试用例(正确编排数据流)
@Test(description = "数据质量自定义模板管理")
public void testCustomTemplateManagement() {
var catalogId = stepCreateCatalog(); // 创建目录,获取ID
var isUnique = stepCheckNameUnique(); // 用目录ID检查名称
var templateId = stepCreateTemplate(catalogId); // 用目录ID创建模板
stepVerifyTemplateCreated(templateId); // 验证创建结果
reportTestResults();
}
注意AI如何正确地将stepCreateCatalog()返回的目录ID传递给了后续步骤——这完全是从录制数据中的请求-响应关系自动推导的。
八、适用场景与局限性
8.1 最适合的场景
-
接口数量多、无标准文档的内部平台产品
-
接口间存在复杂数据流依赖的场景
-
需要频繁跟随版本迭代更新用例的产品
-
有成熟测试框架但方法封装工作量大的团队
8.2 前提条件
-
录制时测试过程必须正确:垃圾进→垃圾出,如果录制时操作有误,AI也会生成错误代码
-
产品本身运行正常:如果产品的接口返回了错误数据,AI会按错误数据生成代码
-
框架规范文档化:AI的知识库质量直接决定生成代码的质量
-
需要有经验的测试工程师审核:AI生成的代码仍需人工审查业务合理性
8.3 不适合的场景
-
接口简单、数量少的轻量级应用
-
纯UI自动化测试(虽然插件支持UI事件录制,但当前AI主要针对接口自动化)
-
需要复杂数据Mock或外部依赖准备的场景
九、总结
录制驱动的AI自动化测试代表了一种新的测试开发范式,它将测试工程师从繁琐的"接口信息搬运工"角色中解放出来,转变为测试场景设计者和AI输出审核者。
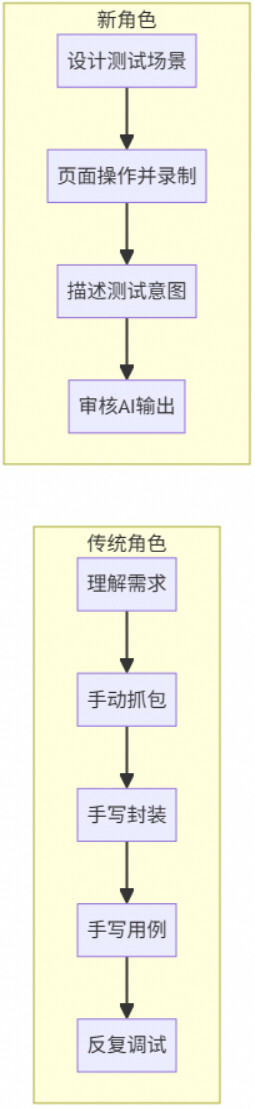
核心价值总结:
|
价值维度 |
具体体现 |
|
效率提升 |
单用例开发时间从5到6小时缩短到20到50分钟 |
|
准确性提升 |
参数拼写、类型匹配、路径解析的错误率趋近于零 |
|
知识民主化 |
新人+AI = 资深工程师的产出质量 |
|
版本兼容 |
天然支持多版本并行的接口封装策略 |
|
规范一致性 |
AI内置团队规范,每次输出都符合编码标准 |
在AI编程工具日益成熟的今天,将录制数据作为AI的"接口真相"输入,结合结构化的测试框架规范作为AI的"行为准则",可以在复杂平台产品的E2E自动化测试领域实现显著的效率和质量提升。这不是AI替代测试工程师,而是AI与测试工程师各自发挥所长的最佳协作模式。
本文基于团队在大型平台产品E2E自动化测试领域的实践经验总结,文中涉及的浏览器录制插件和AI知识框架均为团队内部工具。