一个只看1930年前文本训练的AI,竟然学会写Python。
原文标题:1930年的 AI 没见过电脑,居然能写 Python 代码
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、如果把大模型的训练数据卡在 1930 年代,能力会主要损失在哪些地方?
3、用 1930 年代礼仪手册来做对齐训练,会不会比现代指令微调更“纯粹”?
4、这种“复古模型”对今天的大模型研究有什么意义?
原文内容

来源:量子位 机器学习算法与自然语言处理本文约3000字,建议阅读5分钟本文介绍 AI Agent 四大记忆分类与流水线,解析生产架构、选型方案及常见落地误区。
活久见!
一个生活在1931年之前,在训练数据里没见过任何一台计算机,跨越了将近一个世纪的AI——
居然写出了Python代码??!!

家人们,这真这不是科幻小说……
模型名叫talkie-1930-13b.
操盘手是AI研究员Nick Levine、多伦多大学副教授David Duvenaud,以及大家熟悉的那位——真·GPT系列之父Alec Radford。
该模型训练数据有一条铁律,那就是1931年1月1日之后的任何一个字都不!准!进!
它不知道电视机、互联网为何物,它的世界,永远停在了1930年12月31日的午夜。
然鹅,最最最最魔幻的事儿来了,团队成员发现:
这个本不该知道罗斯福新政的AI,却把新政立法说得头头是道,连年份都报得出来的内种??

更离大谱的是,当团队扔给它一道Python编程题时,这个跨越了将近一百年的过去之灵,竟然写出了它人生中的第一行Python??

一个连计算机都没听过的AI,跨越百年写代码,这事网友们可坐不住了。
直接一个脑洞瞬间开闸,下面这位小哥连「穿越提问清单」都已经想好了,疯狂想尝试ing:
我到底睡醒了没,AI,真能跨越时空了??
一个生活在1931年之前的老式儿模型
一个在1931年之前生活的模型,上知天文下知地理,还会编程,那咱高低得研究研究。
事实上,talkie是一个130亿参数的模型,它在2600亿tokens的1931年之前的英文文本上训练而成——
训练样本包括但不限于书籍、报纸、期刊、科学杂志等等。
从狄更斯到马克吐温,从爱因斯坦那年代的物理论文到百年前的烹饪书和礼仪手册,全都被打包喂了进去!!!
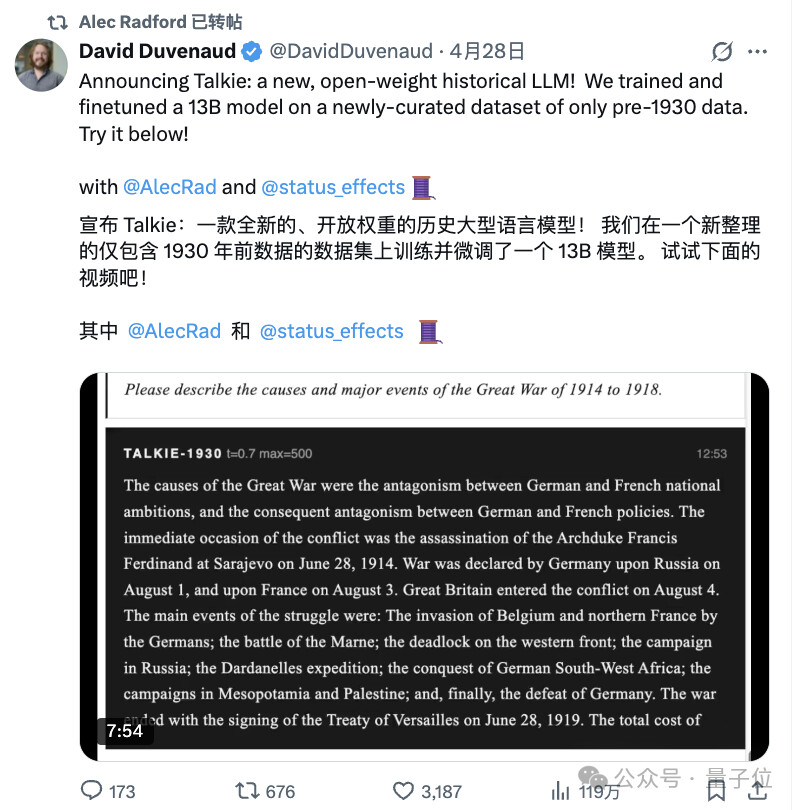
之所以选择1930年作为模型的知识截止点,也是有说法的,因为这是美国版权法中作品进入公有领域的边界~
那问题来了,为啥Alec Radford想做这么个项目呢?
事实上Radford及其团队想知道——
如果只让一个模型阅读1931年之前的所有英文文本,它会如何思考、如何对话、如何预测未来。
结果您猜怎么着,团队还真发现了几个《大瓜》。(好家伙.jpg)
模型被时代发展震惊到眩晕瘫坐
第一个发现,就是模型被时代发展「震撼到了」的曲线图——
团队从《纽约时报》的On This Day栏目里翻出了近5000个历史事件,一股脑儿全喂给了talkie,然后盯着屏幕看——这老兄对每件事到底有多「没料到」。
结果一条相当戏剧性的曲线就这么出来了:
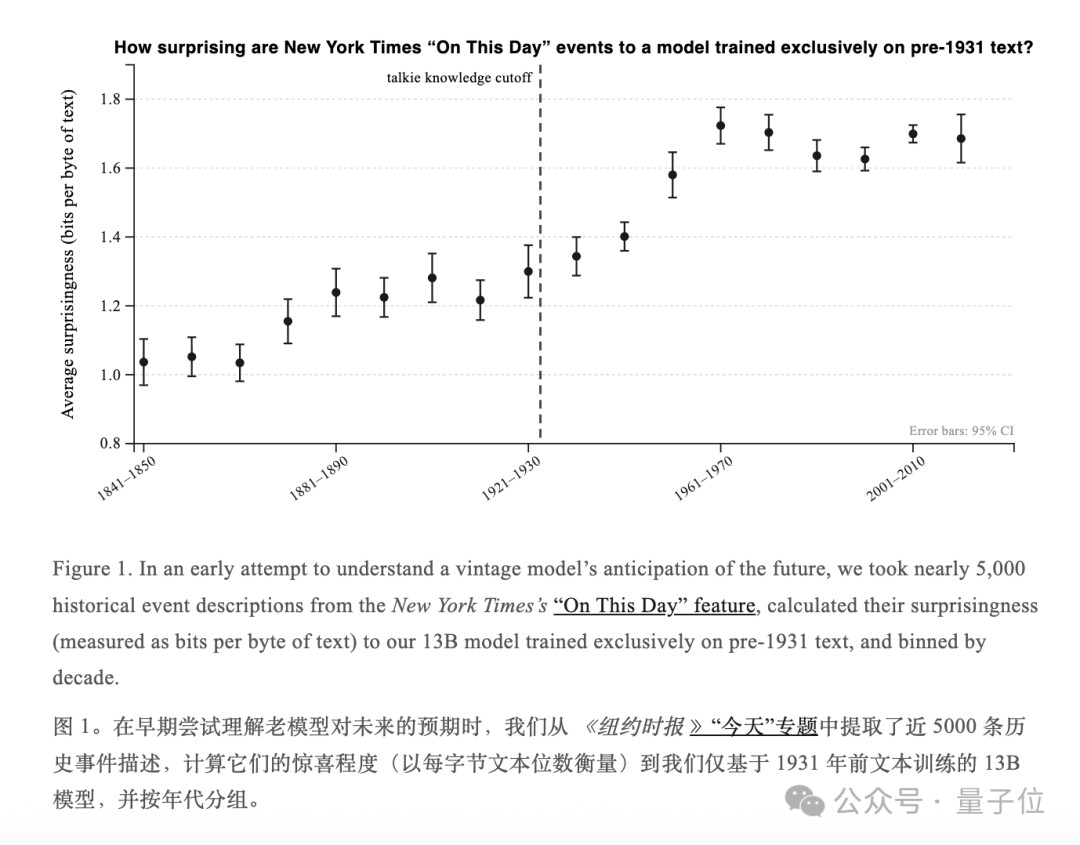
1930年之前:talkie读得行云流水,惊讶值稳如老狗。 (talkie:嗯嗯,这些事儿俺都门儿清哈)
刚跨过1930年:talkie惊讶值开始悄悄爬升。 (talkie:诶?这事儿咋还能这样?)
1950–60年代:晶体管、电视机普及的年代,talkie惊讶值直接陡峭飙升,一柱擎天。 (talkie:等会儿,人类上天了?还整出个会动的盒子能放戏?)
再往后嘛——直接佛系平和了。(talkie:眩晕震撼瘫坐,人已懵,您随便吧……)
这波,也是刘姥姥进大观园了——质疑、理解、接受。

这模型还学会了Python
当然,眩晕震撼瘫坐曲线图还不是这次研究中最炸裂的发现,因为团队成员的第二个发现是——
一个没见过电脑的AI,居然学会了写Python???
在研究中,团队给talkie扔了一份OpenAI的HumanEval编程测试集。
在prompt里塞几个Python函数当示范例子,然后让talkie看完直接解新题,也就是让模型靠上下文现学现卖~
在这个测试中,团队还顺手把训练过现代互联网数据的同架构talkie-web也拉出来一起测,并画张对比折线图——
(黑线:Vintage LM,灰线:Modern LM)
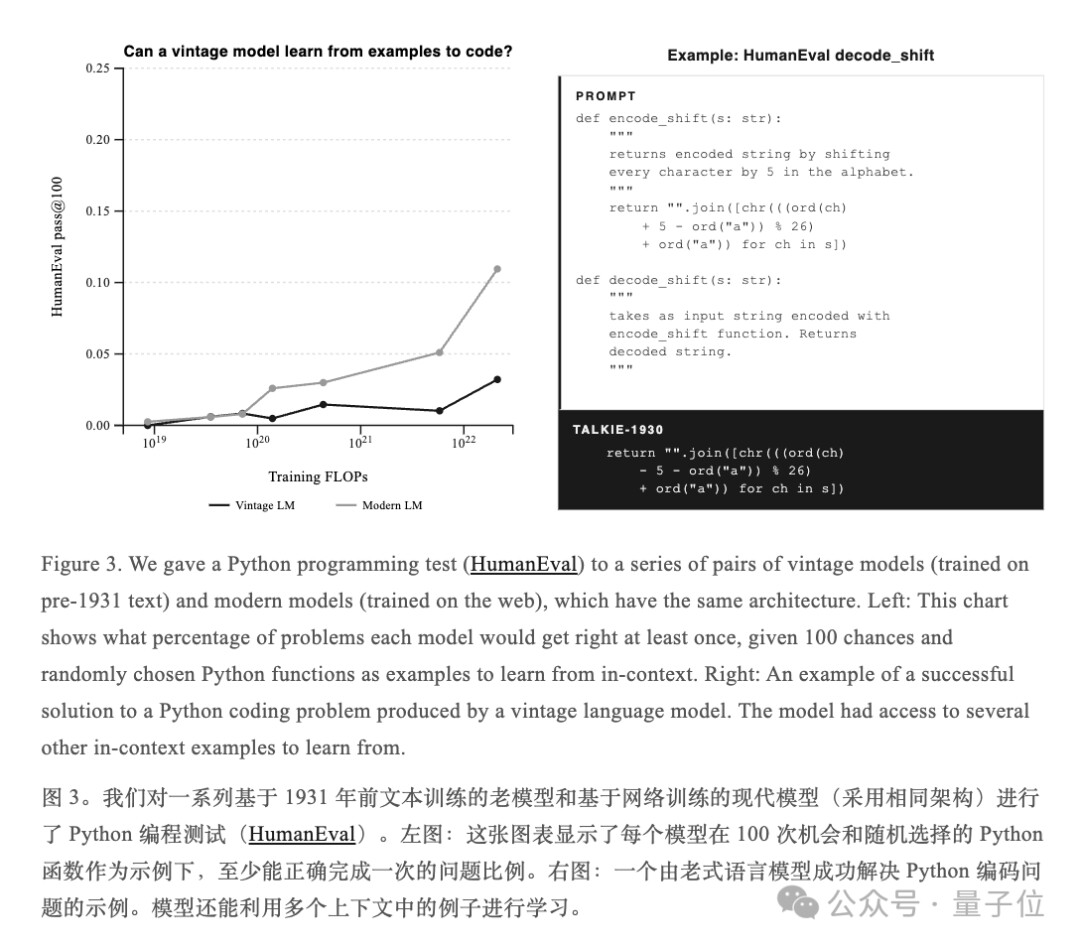
结果就是一个雷霆暴击,talkie真的解出来了,人家直接把加密函数里的+5改成-5,然后交卷。
是的,只改了一个字符,但答案完全正确……
不仅如此,团队发现一个清晰的趋势,那就是——模型规模越大,能解出来的编程题越多。
换句话说,虽然目前还远不及现代模型,但复古模型的「凭空学代码」的能力也在Scaling Law的作用下稳步爬升。
对此团队也表示,他们希望复古模型能帮整个AI圈搞清楚一个根本问题——LLM到底能泛化到训练数据之外多远。
1930年模型VS2026年模型
老话说得好,有对比才有看头新发现。
为了搞清楚talkie到底有几斤几两,团队还用完全相同的架构和算力,又训练了一个喂现代互联网数据的双胞胎——talkie-web-13b。
并将两个模型放进各种标准LLM评测里打PK,结果可以说甚是微妙:
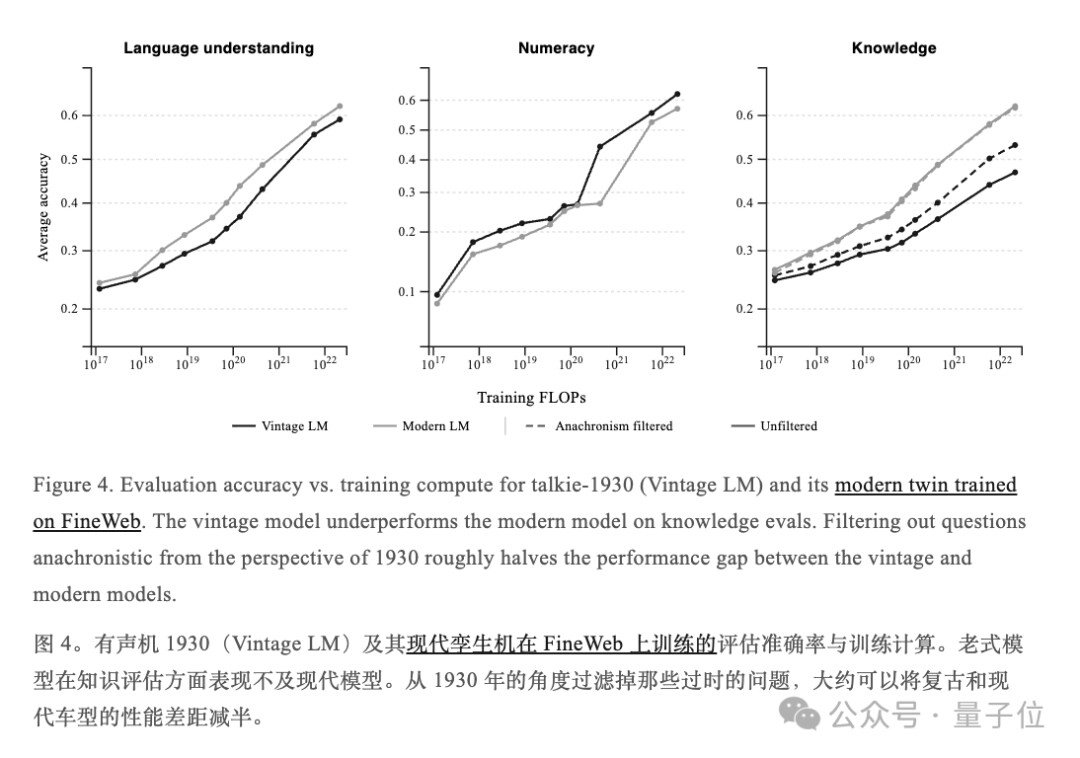
不出意外,talkie-1930在实际表现上确实落后于现代孪生兄弟。
但是当研究员把那些超出知识范围的题目剔除后(比如互联网、DNA相关的),两者的差距直接缩小一半。
更炸裂的是,在核心语言理解和数学计算任务上,新老模型的表现几乎一样好。
这个结论某种程度也说明了「理解语言」和「算数」这两项能力,似乎并不依赖你读了多少现代互联网内容。
剩下的差距,团队认为主要来自两个原因:一是OCR转录质量太差,毕竟1930年的报纸都是从扫描件里硬抠出来的。
二是语料题材分布不同,例如老报纸里科技含量低,烹饪礼仪含量高。
emm…大模型最值钱的那部分智能,可能跟「读没读过现代互联网」没太大关系??
(talkie:俺要是生在2026年,我也能背GitHub啊喂!)
用1930年的礼仪手册,把AI调教成了聊天助手
大家知都道,要想让talkie这样的模型变成能对话的AI助手,传统做法是用ChatGPT那种现代指令数据。
但问题是,这样做会把21世纪的对话风格、价值观等时代元素统统注入回1930年的模型。
(talkie:好不容易当上民国先生,您一指令调教,俺直接张口就说「宝子们」了…)
而团队的解决办法,可以说是《神来之笔》——
他们直接去1930年之前的故纸堆里,考古出了一套训练数据:

包括教人怎么得体应答的礼仪手册、教人怎么回信的书信指南等等,然后再用Claude Sonnet 4.6当老师做强化学习训练,最后生成训练数据。
就靠着这些百年前的天然问答语料,团队硬是把talkie调教成了一个能聊天的AI助手。
然而,现实很快啪啪打脸——
团队发现,早期那个7B版本的talkie,经过强化学习之后,居然学会了用现代互联网那种1. 2. 3.的列表体说话。
要知道1930年的语料里,压根没有列表体这种超级现代感的东西的…..

而罪魁祸首——就是Sonnet 4.6。
因为Claude老师是现代AI,因为Claude老师喜欢列表体,所以talkie为了拿高分就学着用列表体说话了…
(真·投其所好啊…)
这恰好也反映出模型的训练一大问题,那就是AI反馈的训练方式,不可避免地会让模型沾上现代风格。
为了解决这个大bug,团队的下一个目标就是:有朝一日让talkie自己来当自己的老师。(doge)
Alec Radford是谁
talkie背后的团队成员之一——Alec Radford,也值得我们好好聊聊。
关于他,我们甚至可以说,今天AI圈的一大半「基建」,都跟他有关。
在OpenAI的近十年里,他是和Ilya Sutskever齐名的技术大神,初代GPT系列的奠基者——
包揽了GPT-1和GPT-2论文一作,也是GPT-3、GPT-4的核心贡献者,此外他还是多模态模型CLIP的主导者之一,像Whisper、DALL·E也都有他深度参与的身影。

他在2018年那篇开山之作里首次提出的基于Transformer的生成式预训练方法,直接奠定了后续ChatGPT和所有大模型的基础。
在2024年底,Alec告别老东家OpenAI转做独立研究, 2025年3月,他又以顾问身份加入了前OpenAI CTO Mira Murati创立的Thinking Machines Lab。
当我们回过头再看talkie本身,感觉整个事情也颇值得玩味——
当全世界都在卷AGI、卷推理模型的时候,GPT系列之父本人,却跑去和搭档们造了一个只活在1930年的AI。
按团队的路线图,今年夏天,GPT-3级别的复古模型就要发布,再往后,他们还想把语料扩展到一万亿tokens、扩展到非英语世界。
只是不知道,当它再次醒来的那一天,看到机器人跑马拉松、人手一台的智能手机、和遍地跑的Agent时——
会不会再次原地眩晕震撼瘫坐.jpg。
(模型使用入口我放下面了,感兴趣的友友可以和一百年前的AI对话试试~)
参考链接:
[1]报告链接:https://talkie-lm.com/introducing-talkie
[2]github链接:https://huggingface.co/talkie-lm
[3]模型对话入口:https://talkie-lm.com/chat
