NOSE把分子、受体和气味语义统一进一个表征空间,提升了嗅觉建模和零样本泛化能力。
原文标题:ACL 2026 | NOSE:让AI学会「闻」,首个统一分子-受体-语义的三模态嗅觉表征框架
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文中提到的“正交注入”思路,放到别的多模态任务里会不会也很好用?
3、如果气味预测不再只做分类,而是构建连续的语义流形,这会改变哪些下游应用?
4、这类工作虽然是嗅觉研究,但文章最后提到还能迁移到电解液、电镀添加剂等领域,靠谱吗?
原文内容

来源:ScienceAI本文约2200字,建议阅读5分钟为AI驱动的分子设计提供新的表征范式。

视觉有像素,听觉有频谱,这些物理量与感知之间存在稳定的映射。但嗅觉截然不同,同一个分子可能激活不同的受体组合,同一种气味在不同人的嘴里可以是「花香」也可以是「肥皂味」。如何让 AI 理解「分子闻起来是什么味道」,一直是 AI for Science 领域一个独特而前沿的挑战。
近日,厦门大学程俊教授团队与深势科技合作,提出了 NOSE(Neural Olfactory-Semantic Embedding)框架。该工作首次将分子结构、嗅觉受体序列和自然语言描述三种模态统一到一个连续的表征空间中,在覆盖三个感知层次的 11 个下游任务上达到 SOTA,并展现出优异的零样本泛化能力。研究成果已被自然语言处理顶级会议 ACL 2026 主会录用。

论文链接:https://arxiv.org/abs/2604.10452v1
代码链接:https://github.com/Xianyusyy/NOSE
为什么嗅觉数字化这么难?
嗅觉感知始于气味分子的挥发扩散,与鼻腔中嗅觉受体的结合,经过神经信号传导,最终在大脑中形成主观知觉。这条通路天然涉及三种截然不同的信息,包括分子的三维化学结构、嗅觉受体蛋白的序列特征,以及人类用自然语言给出的感知描述(如「花香」「薄荷味」「奶油感」)。
然而,现有方法从未在统一框架中建模这条完整通路。它们要么仅从分子结构出发预测气味,要么只学习「分子 - 描述」或「分子 - 受体」的局部对应关系。更根本的问题在于,主流方法将气味预测视为分类问题,即预测分子属于「花香」还是「果香」。这种离散化处理不仅破坏了气味空间的连续性(「薄荷」和「清凉」本应相邻,分类框架下却是两个独立标签),还迫使模型丢弃那些对分类「无用」但对分子表征至关重要的结构信息,导致泛化能力受限。
正交注入与连续语义流形
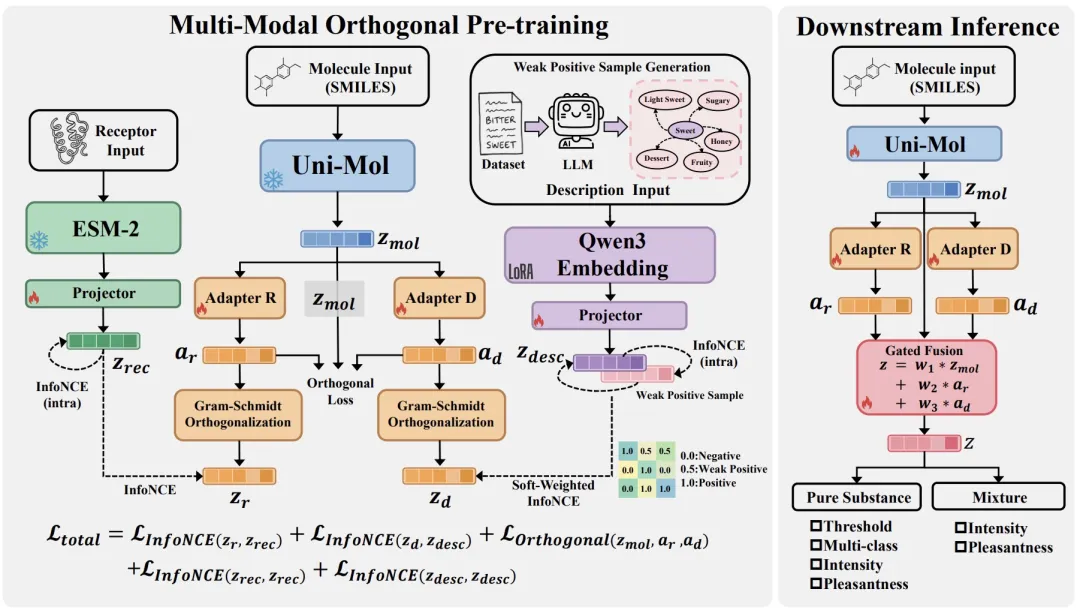
NOSE 的关键洞察在于,虽然「分子 - 受体 - 描述」三元组数据几乎不存在,但「分子 - 受体」和「分子 - 描述」双模态数据可以分别获取。分子是两类数据的唯一交集,因此可以作为中枢,将受体信息和语义信息桥接到统一的表征空间。
但如果将受体特征和语义特征同时注入分子表征,三种模态会不会相互干扰、彼此覆盖?NOSE 给出的解法是正交注入机制。框架采用「硬正交 + 软正交」双重策略,利用 Gram-Schmidt 正交化,将受体和描述的适配器输出投影到分子表征的正交补空间,在几何层面保证注入的信息与分子结构线性无关;同时引入软正交损失,在梯度层面驱动受体分支和描述分支的特征子空间保持互不相关。这样,受体信息和语义信息以相互独立的增量叠加在分子表征之上,既不丢失分子结构先验,又实现了隐式的三模态对齐。
在编码器选择上,NOSE 采用 Uni-Mol 捕捉分子三维构象、ESM-2 提取受体序列特征、LoRA 微调的 Qwen3 Embedding 处理气味描述文本,三大预训练模型各司其职。
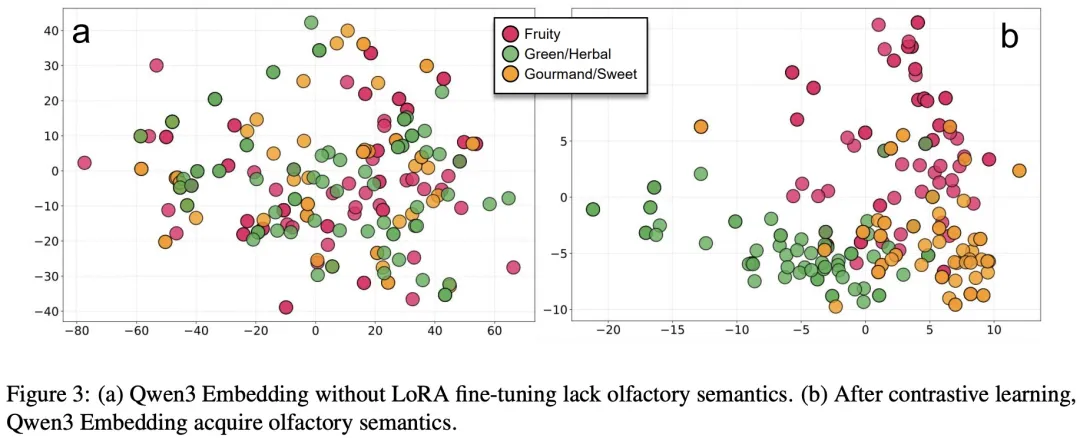
在语义端,NOSE 利用大语言模型 DeepSeek 挖掘 1,086 个气味描述词之间的语义近邻关系(如「柠檬」与「柑橘」、「甜」与「蜂蜜」),将这些语义近邻标记为「弱正样本」并赋予中间权重。这一策略将离散的标签空间转化为连续的语义流形,有效缓解了对比学习中将语义相近的描述错误推远的「假阴性」问题。经过训练后,原本在通用文本模型中高度重叠的气味词在 PCA 可视化中形成了边界清晰的语义簇,证明模型成功构建了结构化的气味语义空间。
全面 SOTA 与零样本泛化
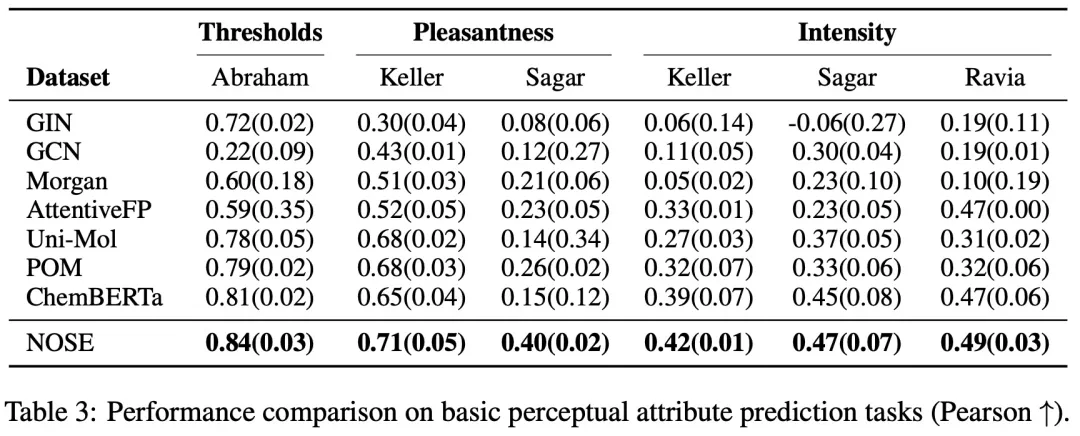
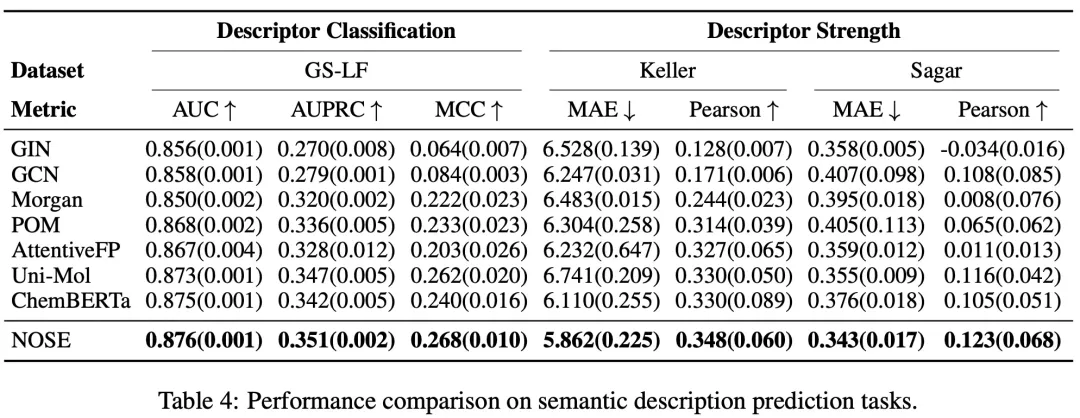
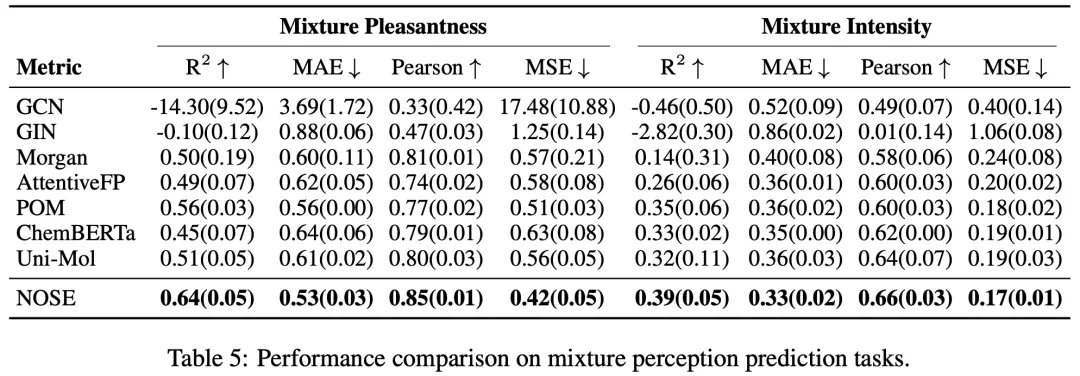
研究团队整合了 6 个公开数据集,构建了覆盖三个认知层次的评估基准,涵盖基础感知(检测阈值、强度、愉悦度)、语义描述(138 类多标签分类和多维度回归)、以及混合物感知(二元混合物的强度与愉悦度预测)。在全部 11 个任务的关键指标上,NOSE 均取得最优表现。
零样本检索
为验证泛化能力,研究团队从 PubChem 构建了专用测试集。与标准零样本设置(分子存在于数据集中但分子 - 描述词配对未见过)不同,严格零样本要求分子完全不存在于训练集中。团队使用分子检索气味描述词,采用百分位排名进行评估(数值越低表示精度越高)。除 PubChem 描述词外,同义术语的排名也被纳入评估。例如对于无味分子,模型将「odorless」排在 Top 1(0.092%),并优先排列 slight、weak、neutral 等术语,表明模型真正理解了分子的感知属性,而非简单地与高频词对齐。

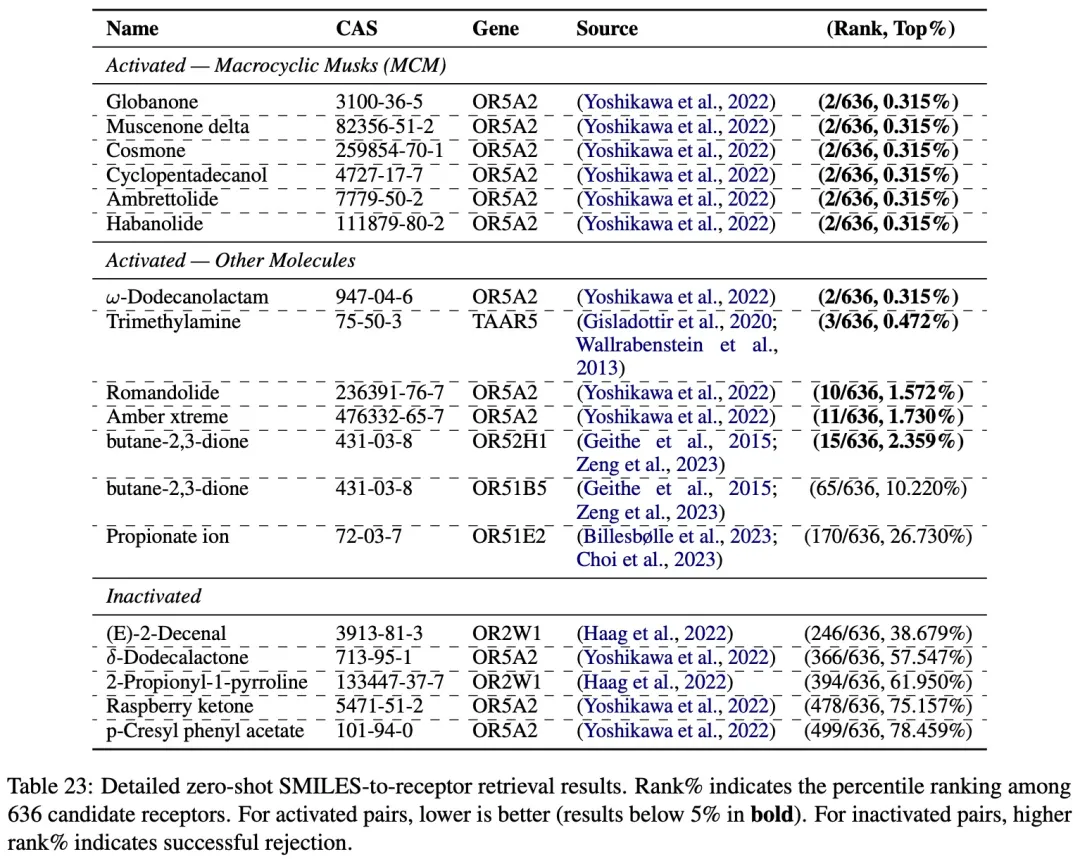
在受体检索方面,团队从文献中选取具有明确「激活」或「非激活」关系报告的分子 - 受体配对作为测试集。模型在已报道的「激活」配对上表现优异,绝大多数排名位于前 2% 以内,涵盖大环麝香(MCM)及其他化学家族,显示出良好的跨家族泛化能力。同时,所有「非激活」样本的排名显著靠后,主要分布在 30% 至 80% 区间。这种激活与非激活样本间的排名分离表明,模型构建的潜在空间有效区分了正负样本对,具备可靠的生物筛选价值。
意义与展望
NOSE 首次为嗅觉通路上的三种模态搭建了统一的表征空间,使分子结构、受体蛋白和人类感知之间的关联能够在一个连续、可检索、可运算的特征流形中被建模。其核心思想,即通过对比学习统一多模态信息以构建连续且结构化的领域分子表征,不局限于气味分子场景,同样有望推广至电解液溶剂、电镀添加剂等电化学领域,为 AI 驱动的分子设计提供新的表征范式。
编辑:文婧
