Monorepo管代码协作,微服务管运行治理;统一仓库后,微服务依然有独立价值。
原文标题:都monorepo了,还有必要搞微服务吗?
原文作者:图灵编辑部
冷月清谈:
文章进一步总结了微服务真正要解决的四类问题:一是认知负载,当系统变大后,单个团队难以理解全局,拆分有助于让团队专注于可掌控的业务边界;二是弹性需求,不同业务模块的流量与资源需求不同,微服务便于按需扩缩容;三是发布节奏,不同团队可按自身节奏独立上线,减少彼此牵制;四是故障隔离,局部问题不至于拖垮整个系统。
同时,作者澄清了几类常见误解:monorepo 不是单体,微服务也不必然要求分库;微服务并不会消灭复杂性,而是将复杂性从进程内转移到分布式系统层面;服务也不是拆得越细越好,过度拆分会带来高昂的协作与运维成本。文章还强调,微服务本质上是组织问题,服务边界往往映射团队边界。
在 AI Coding 背景下,作者认为 monorepo 的价值进一步放大,因为它能为 AI 提供完整上下文,方便跨服务理解、联动修改与统一协作;而微服务则继续承担运行时治理职责。对于小团队、低复杂度、节奏一致的场景,单体依然是合理选择,但这不意味着系统未来不需要演进。
怜星夜思:
2、问题2:文章说微服务的核心价值之一是“独立发布”,但现实里很多服务之间还是强依赖。你觉得真正做到独立发布,最难的是技术问题还是组织问题?
3、问题3:Monorepo在AI编码时代会更有优势,这个判断你认同吗?AI真的能因为“全局上下文”受益很多吗?
4、问题4:文章提到“微服务不会减少复杂性,只是转移复杂性”。那在你看来,什么情况下这种“复杂性的转移”是值得的?
原文内容
之前一篇文章聊了,发出去之后不止一位朋友问到一个很有意思的问题:
"既然你把所有服务都放到同一个代码库了,那还有必要搞微服务吗?直接单体不就完了?"
我当时的第一反应是:当然有必要。
但转念一想,这个问题其实不简单。它背后藏着一个很常见的认知混淆——很多人把"代码放在哪"和"系统怎么跑"当成了同一件事。
这篇文章就来聊聊这个。
一个类比
先打个比方。
你家有个大书架,所有书都放在上面。这是monorepo——一个统一的存放位置。
但你读书的时候,不会把所有书摞在一起同时翻吧?你会一本一本地读,每本书有自己的主题、自己的节奏。这就是微服务——独立运行、独立部署的服务单元。
书架解决的是"东西放哪"的问题。分开读解决的是"怎么消化"的问题。这两件事从来就不矛盾。
Uber就是个活生生的例子。他们的Go monorepo[1]里装着2200多个微服务[2],70000多个手写的Go文件,每个月大约10000次commit。所有代码住在同一个仓库里,但在运行时,这些服务各自独立部署、独立扩缩容。
而在此之前,Uber用的是polyrepo,也就是每个微服务一个独立的代码仓库。这是业界最常见的做法,也是很多人以为微服务"必须"采用的方式。但polyrepo带来了依赖版本各自为政、共享库升级困难、跨服务重构需要同时在几十个仓库提PR等一系列问题。最终Uber选择了合并到monorepo,微服务一个没少,但代码管理的效率大幅提升。
Monorepo管的是代码的组织方式。微服务管的是运行时的架构方式。它们是两个正交的决策,解决的是完全不同的问题。
微服务到底在解决什么
那微服务到底在解决什么问题?为什么不能"直接单体"?
Sam Newman在《微服务设计(第2版)》[3]里给微服务下了一个很精炼的定义:围绕业务领域建模的、可独立发布的服务。注意,"独立发布"是定义的核心,不是"小",不是"分库",不是"用REST通信"。
顺着这个定义往下想,微服务到底在解决什么?我觉得至少有四个理由。
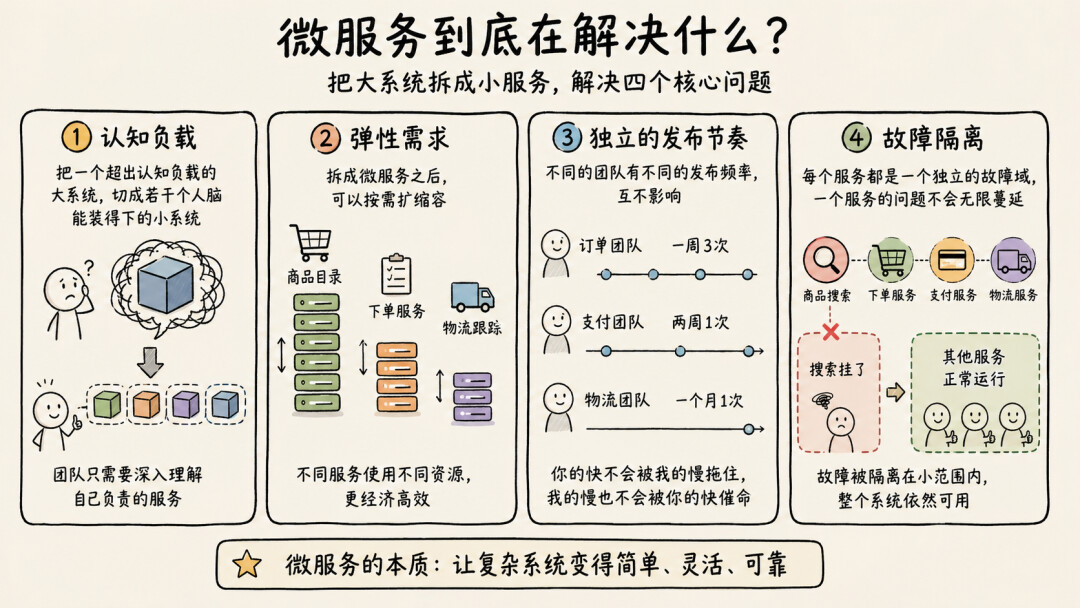
第一,认知负载。
一个系统刚开始构建的时候,单体挺好的。代码量不大,团队也小,一个人脑子里能装下整个系统的全貌。
但系统会长大。功能越加越多,模块之间的依赖越来越复杂,代码库从几万行变成几十万行。到了某个临界点,没有任何一个人能完整理解整个系统了。你改了订单模块的一行代码,不确定会不会影响到库存、支付、甚至推荐系统。每次改动都像在拆炸弹。
这时候你需要拆分。不是因为技术上必须拆,而是因为人脑的认知带宽是有限的。微服务的第一个价值,就是把一个超出认知负载的大系统,切成若干个人脑能装得下的小系统。每个团队只需要深入理解自己负责的那个服务,而不是整个系统。《微服务设计》里有一个很好的提醒:衡量服务大小的正确问题不是"多少行代码",而是"一个团队能拥有和运维多少个服务"——这本质上就是认知负载的问题。
第二,弹性需求。
不同的业务模块对系统弹性的要求是不一样的。
还是拿电商举例。商品目录是读多写少的,大促的时候流量可能是平时的几十倍,需要大幅扩容。下单服务的流量也会涨,但没那么夸张。而物流跟踪?大促期间反而没什么压力,压力在大促之后。
如果这些模块都在一个单体里,你要扩容就只能整体扩容——哪怕只有商品目录需要更多资源,你也得把整个应用多部署几份。这就像因为客厅太热就给整栋楼开空调。
拆成微服务之后,你可以按需扩缩容。商品目录扛不住了,单独给它加实例。下单服务不需要那么多资源,就少给一点。在资源有限的现实世界里,这是最经济的方案。
第三,独立的发布节奏。
不同的团队有不同的发布频率。
订单团队可能一周发三次版,因为业务需求变化快。支付团队可能两周才发一次,因为每次变更都需要严格的合规审查。物流团队可能一个月发一次,因为他们对接的外部系统更新很慢。
在单体架构下,所有人的发布节奏被绑在一起。订单团队改完了想发版,但支付团队的代码还没测完,只能等。支付团队测完了想发版,但物流团队刚提交了一个有bug的commit,又得等。
这种"发布火车"模式,在团队规模小的时候还能凑合。一旦团队多了,协调成本会指数级增长。微服务让每个团队拥有自己的发布节奏,你的快不会被我的慢拖住,我的慢也不会被你的快催命。Sam在书里反复强调,独立部署不应该只是架构图上的理论能力——如果你的架构允许独立部署,那就真正去做,否则它就只是一个摆设。
第四,故障隔离。
单体架构有一个让人头疼的特性:一个模块出问题,可能拖垮整个系统。
商品搜索服务因为一个慢查询把数据库连接池耗尽了,结果下单也不行了,支付也不行了,整个系统一起躺平。这种"一损俱损"的场景,在单体架构里太常见了。
微服务提供了天然的故障隔离边界。商品搜索挂了,下单服务还能正常工作——最多搜索结果暂时不可用,但用户已经加到购物车里的商品照样能买。每个服务都是一个独立的故障域,一个服务的问题不会无限蔓延。
当然,这不是说微服务就没有级联故障的风险。分布式系统有自己的一套故障模式——网络分区、超时雪崩、重试风暴。但至少,你有了隔离的可能性。单体连这个可能性都没有。
那些关于微服务的误解
聊完了微服务的价值,再来说说那些常见的误解。
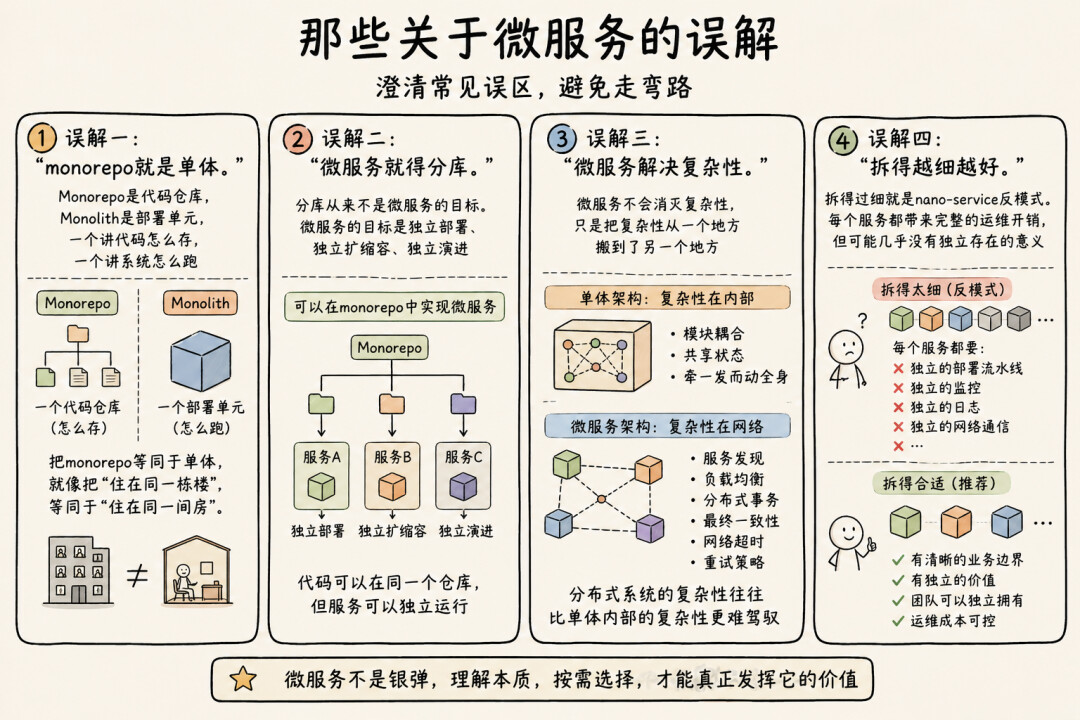
误解一:"monorepo就是单体。"
这是最常见的混淆。Monorepo是mono-repository,一个代码仓库。Monolith是mono-lith,一个部署单元。一个讲的是代码怎么存,一个讲的是系统怎么跑。
Google的monorepo[4]里跑着成千上万个独立服务。Uber的monorepo里有2200多个微服务。代码放在一起,不代表它们要一起编译、一起部署、一起扩缩容。
把monorepo等同于单体,就像把"住在同一栋楼"等同于"住在同一间房"。
误解二:"微服务就得分库。"
这是上一个误解的镜像。很多团队在做微服务的时候,第一件事就是给每个服务建一个独立的代码仓库。好像不分库就不算微服务似的。
前面提到的Uber就是最好的反例——从polyrepo迁移到monorepo之后,2200个微服务一个没少,但跨服务重构、依赖管理、共享库升级这些在polyrepo时代让人头疼的问题,都大幅缓解了。
分库从来不是微服务的目标。微服务的目标是独立部署、独立扩缩容、独立演进。这些目标完全可以在monorepo里实现——《微服务设计》第七章专门讨论了这个话题,Sam的判断标准很简单:关键约束是"你能不能对一个服务做变更并独立部署它,而不需要部署其他所有东西"。如果能,你的仓库结构就没问题。
误解三:"微服务解决复杂性。"
这个误解最危险。
微服务不会消灭复杂性,它只是把复杂性从一个地方搬到了另一个地方。单体架构的复杂性在代码内部——模块之间的耦合、共享状态的管理、牵一发动全身的修改。微服务把这些复杂性搬到了网络上——服务发现、负载均衡、分布式事务、最终一致性、网络超时、重试策略。
这不是在减少复杂性,这是在转移复杂性。而且坦白说,分布式系统的复杂性往往比单体内部的复杂性更难驾驭——单体里的bug你打个断点就能追踪,但一个请求穿过五个服务之后出了问题,你需要对着分布式链路追踪的瀑布图大海捞针,还得祈祷每个服务的日志级别都配对了。
所以微服务不是用来"解决复杂性"的。它是用来解决前面说的那四个问题的——认知负载、弹性需求、部署节奏、故障隔离。如果你的系统没有这些问题,那拆微服务只会凭空增加复杂性。Sam说得很直白[5]:"搞错了服务边界的代价很高。它会导致大量跨服务变更、过度耦合,总体上可能比单体还糟。"
误解四:"拆得越细越好。"
有些团队一旦决定做微服务,就恨不得把每个函数都拆成一个服务。一个用户注册的流程,拆出来"验证邮箱服务""生成密码哈希服务""发送欢迎邮件服务";我还听说有的团队把CRUD拆成4个服务的……
这就是所谓的nano-service反模式。每个服务小到几乎没有独立存在的意义,但每个服务都带来了完整的运维开销——独立的部署流水线、独立的监控、独立的日志、独立的网络通信。
微服务的"微"不是越小越好,而是刚好能被一个团队独立拥有和运维的大小。这个粒度因组织而异,没有标准答案。但有一个简单的判断标准:如果一个服务不能独立地为某个业务能力负责,它可能就拆得太细了。
其实是个组织问题
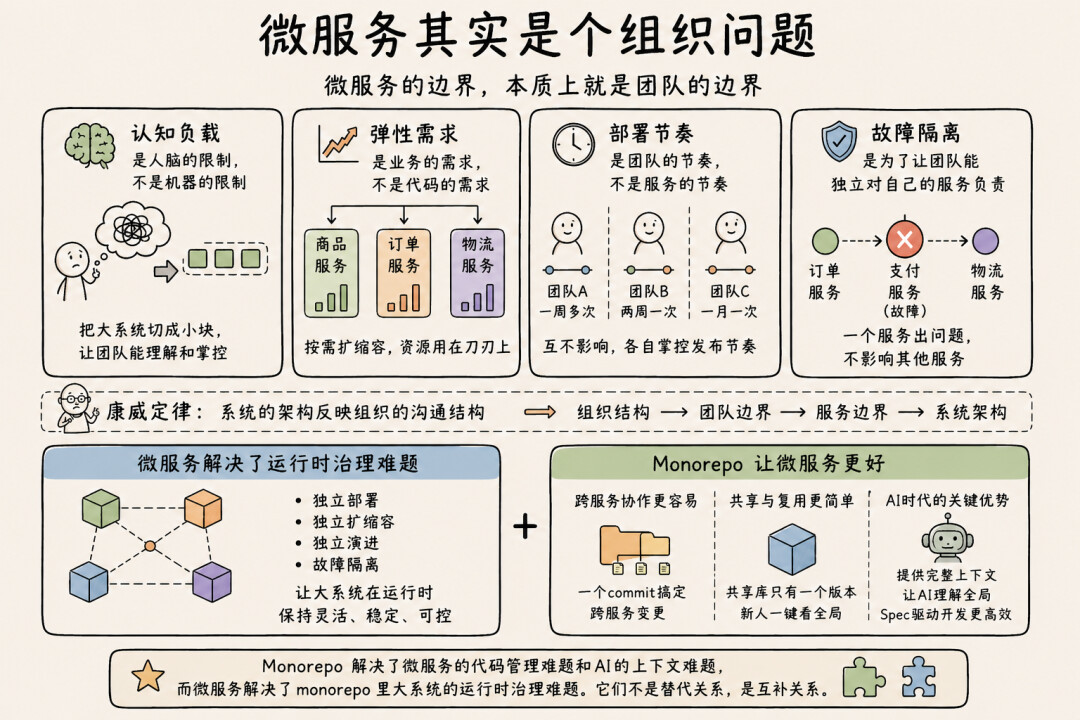
写到这里,你可能发现了一个规律:微服务的每一个价值点,最终都指向了组织,而不是技术。
认知负载——是人脑的限制,不是机器的限制。弹性需求——是业务的需求,不是代码的需求。部署节奏——是团队的节奏,不是服务的节奏。故障隔离——是为了让团队能独立对自己的服务负责。
康威定律[6]说得很清楚:系统的架构反映组织的沟通结构。反过来说,微服务的边界,本质上就是团队的边界。Sam在书的最后几章花了大量篇幅讨论组织结构,他的警告很尖锐:如果你花了钱搞微服务架构,却不去改变那种自上而下的命令式组织,你大概率会得到两个世界里最差的结果。
这就是为什么"都monorepo了还要不要微服务"这个问题本身就问错了。Monorepo改变的是代码的存放方式和协作方式,它不改变团队的边界、不改变业务的弹性需求、不改变认知负载的物理限制。这些问题依然存在,微服务依然是回应这些问题的有效架构选择。
甚至可以说,monorepo让微服务变得更好了。在polyrepo时代,跨服务的重构是噩梦,共享库的版本管理是灾难,新人理解系统全貌几乎不可能。Monorepo把这些问题都缓解了——你可以用一个commit完成跨服务的接口变更,共享库只有一个版本,新人clone一次就能看到整个系统的代码。
而在AI Coding的时代,这种互补关系还有一层更深的意义。
我在里聊过Spec-Driven Development——简单说就是先用自然语言写清楚需求spec,再让Coding Agent根据spec生成代码。这套工作方式有一个前提:Agent需要理解跨服务的全局上下文。一个"用户下单"的spec,涉及用户服务、订单服务、库存服务、支付服务,Agent得知道这些服务之间的接口契约、数据模型、调用关系,才能把spec拆分到正确的服务里。在polyrepo下,Agent只能看到当前仓库的代码,它对系统的理解是割裂的。而在monorepo里,Agent可以同时看到所有服务的代码、接口契约、数据模型,甚至那些没写在文档里的隐含约定。Monorepo给了AI一个完整的上下文窗口,让它从盲人摸象变成了俯瞰全局。
不仅如此,monorepo还统一了所有角色的协作界面。UX的设计稿、BA的页面原型、前端代码、后端各个微服务的代码、测试用例、spec,全部在同一个仓库里。Git就是协作协议,commit就是交接。不再有zip包传来传去,不再有"你发我一下最新版"。当AI agent可以通过命令行完成越来越多的事情,这些原本散落在不同平台的工作,正在被收敛到一个统一的上下文里。
所以monorepo和微服务的关系,在AI时代变得更加清晰了:Monorepo解决了微服务的代码管理难题和AI的上下文难题,而微服务解决了monorepo里大系统的运行时治理难题。它们不是替代关系,是互补关系。
所以,什么时候不需要微服务?
说了这么多微服务的好,最后也得说说什么时候不需要它。
如果你的团队只有五六个人,系统的复杂度还在一个人能理解的范围内,业务模块的弹性需求差不多,发布节奏也一致——那单体就挺好的。不要为了"微服务"这三个字去拆分。
Martin Fowler说过一句话[7],大意是:几乎所有成功的微服务架构,都是从一个成功的单体演化而来的。Sam也持同样的立场,他的默认建议是从一个简单的单体开始,在内部做好模块化,等到真正需要的时候再拆出一两个服务试试水。
但请注意,"什么时候不需要"和"以后都不需要"是两回事。AI能帮你写代码,但它不能帮你缩小人脑的认知带宽,不能帮你把一个只需要扩容搜索模块的系统整体扩容的账单变少,也不能帮你协调十个团队在同一个单体上的发布节奏。这些问题是物理性的、组织性的,不会因为有了AI就消失。
所以回到最初那个问题:都monorepo了,还有必要搞微服务吗?
答案是:monorepo让AI看得见全局,微服务让系统跑得动局部。一个管认知,一个管运行。书架和书,缺一不可。
Uber的Go monorepo: https://www.uber.com/blog/go-monorepo-bazel/
[2]Uber的微服务架构: https://www.uber.com/blog/microservice-architecture/
[3]《微服务设计(第2版)》: https://book.douban.com/subject/36855388/
[4]Google的monorepo: https://research.google/pubs/why-google-stores-billions-of-lines-of-code-in-a-single-repository/
[5]Sam Newman的博客: https://samnewman.io/blog/2015/04/07/microservices-for-greenfield/
[6]康威定律: https://www.melconway.com/Home/Conways_Law.html
[7]Martin Fowler的博客: https://martinfowler.com/bliki/MonolithFirst.html