新基准MME-Emotion显示,主流多模态模型在情绪识别与推理上仍有明显短板。
原文标题:实测 20 款多模态模型,情感理解能力仍有巨大短板
原文作者:数据派THU
冷月清谈:
评测体系包括情绪识别得分、推理得分和综合思维链得分,并引入多智能体自动评分流程,以降低人工评测成本。实验中,研究团队测试了20个主流多模态大模型,包括GPT-4o、Gemini、Qwen等。结果显示,当前模型在情感理解上整体仍偏弱,最佳模型情绪识别得分不到40%,综合思维链得分约56%。
进一步分析表明,模型主要短板集中在细粒度视觉理解、多模态信息融合和稳定推理能力上,尤其容易混淆相近情绪,如恐惧与惊讶。研究认为,未来提升方向包括更精准的视觉细节建模、更有效的语音视觉融合,以及更能解释情绪成因的推理机制。该基准为多模态情感智能研究提供了较统一的评价标准和后续改进参考。
怜星夜思:
2、问题2:如果未来AI真的能更准确地理解人类情绪,你最看好它先在哪些场景落地?哪些场景又最需要谨慎?
3、问题3:文章里提到“会推理的模型,情感智能通常也更好”,你认同吗?推理能力真能带来更强的情绪理解吗?
4、问题4:你觉得情绪识别这件事,最大的难点是技术问题,还是“情绪本来就没有标准答案”这个问题?
原文内容

来源:人工智能前沿讲习本文约2000字,建议阅读5分钟本文介绍了 MME-Emotion 评测基准,用于全面衡量多模态大模型情感智能。
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?
在真实世界中,人类的情绪往往通过多个模态共同表达。例如,一个人可能通过面部表情传递紧张情绪,同时语音语调也在变化,而语言内容可能只提供部分线索。对于人工智能系统而言,仅依赖单一信息来源往往难以准确判断情绪状态。因此,情感智能(Emotional Intelligence)逐渐成为衡量多模态大模型能力的重要指标之一。
然而,目前学界仍然缺乏一个系统性的评测框架来衡量多模态大模型的情感智能水平。已有情感数据集通常规模较小,场景覆盖有限,而且大多只关注情绪分类准确率。模型是否真正理解情绪产生的原因,以及能否在不同场景中稳定工作,往往没有得到充分评估。
为了解决这一问题,来自香港中文大学和阿里通义实验室的团队共同提出了 MME-Emotion,一个面向多模态大模型情感智能的综合评测基准。该工作已被 ICLR 2026 接收。

-
论文标题:MME-Emotion: A Holistic Evaluation Benchmark For Emotional Intelligence in Multimodal Large Language Models
-
项目主页:https://mme-emotion.github.io
-
论文代码:https://github.com/FunAudioLLM/MME-Emotion
-
论文数据:https://huggingface.co/datasets/Karl28/MME-Emotion
MME-Emotion 是目前规模最大的多模态情感智能评测基准之一,包含约 6500 段视频片段及对应问答数据,覆盖 27 类真实场景,并设计了 8 类不同情感任务。相比传统数据集,这一基准强调真实环境中的多模态信息融合能力,使模型必须同时理解视觉、语音和语言信息。
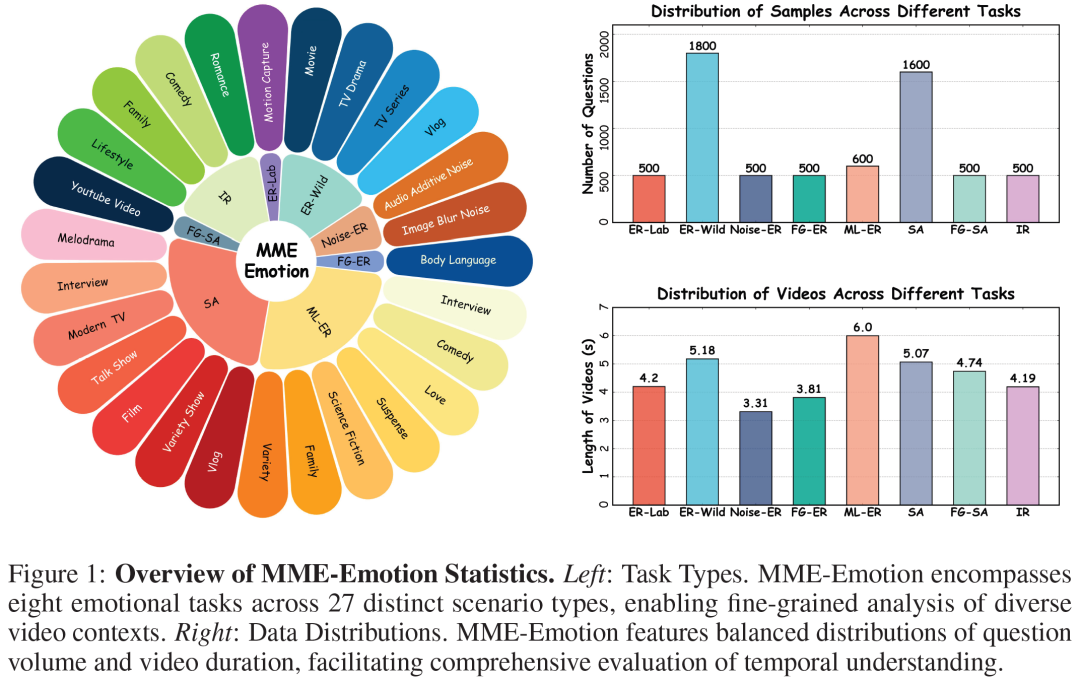
这些任务包括实验室环境情绪识别、真实场景情绪识别、噪声条件下情绪识别、细粒度情绪识别、多标签情绪识别、情感倾向分析、细粒度情感分析以及意图识别等多个方向。不同任务之间保持相对均衡的数据分布,使评测结果更加稳定可靠。
与以往工作相比,MME-Emotion 的一个重要特点是同时评测情绪识别能力和情绪推理能力。在许多已有数据集中,只要模型预测正确的情绪标签即可获得高分,但这种评测方式无法区分「猜对答案」和「真正理解情绪」的差别。
例如,在一个视频中,如果人物表现出恐惧情绪,模型不仅需要给出 “恐惧” 这一标签,还需要能够指出支撑这一判断的线索,例如面部表情变化、语音颤抖或者语速变化等。只有在这种情况下,我们才认为模型具备一定程度的情感理解能力。
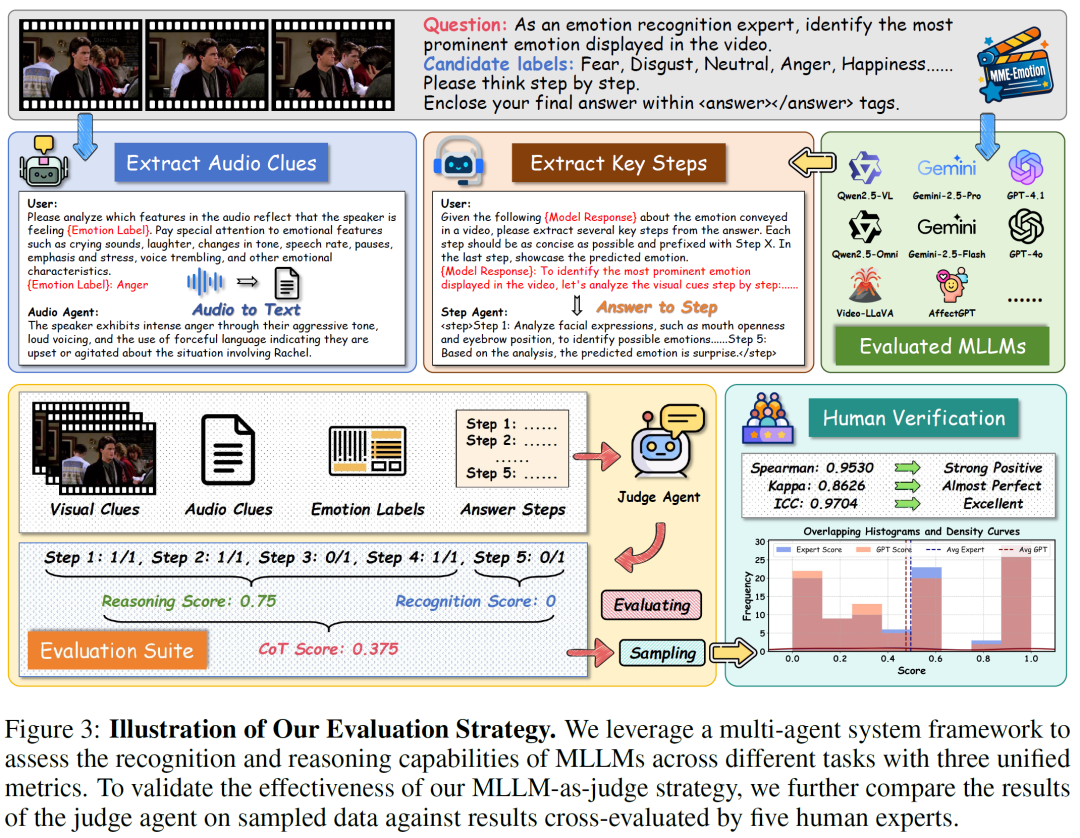
为此,MME-Emotion 提出了一套统一的评测指标体系,包括情绪识别得分(Recognition Score)、推理得分(Reasoning Score)以及综合思维链得分(Chain-of-Thought Score)。其中识别得分用于衡量情绪预测准确率,推理得分用于衡量模型推理过程的合理性,而综合得分则同时反映识别能力与推理能力。
为了支持大规模自动评测,研究团队设计了一套基于多智能体系统的评测流程。系统首先获取模型对问题的回答,然后自动提取回答中的关键推理步骤,并结合视频帧信息和语音线索进行评分。这种方法避免了传统评测中大量人工标注推理过程的成本问题。
为了验证自动评测的可靠性,研究团队还邀请了多位专家对部分样本进行了人工评测。结果表明,自动评分与人工评分之间具有较高一致性,说明这一评测方法在实际使用中具有较好的稳定性。
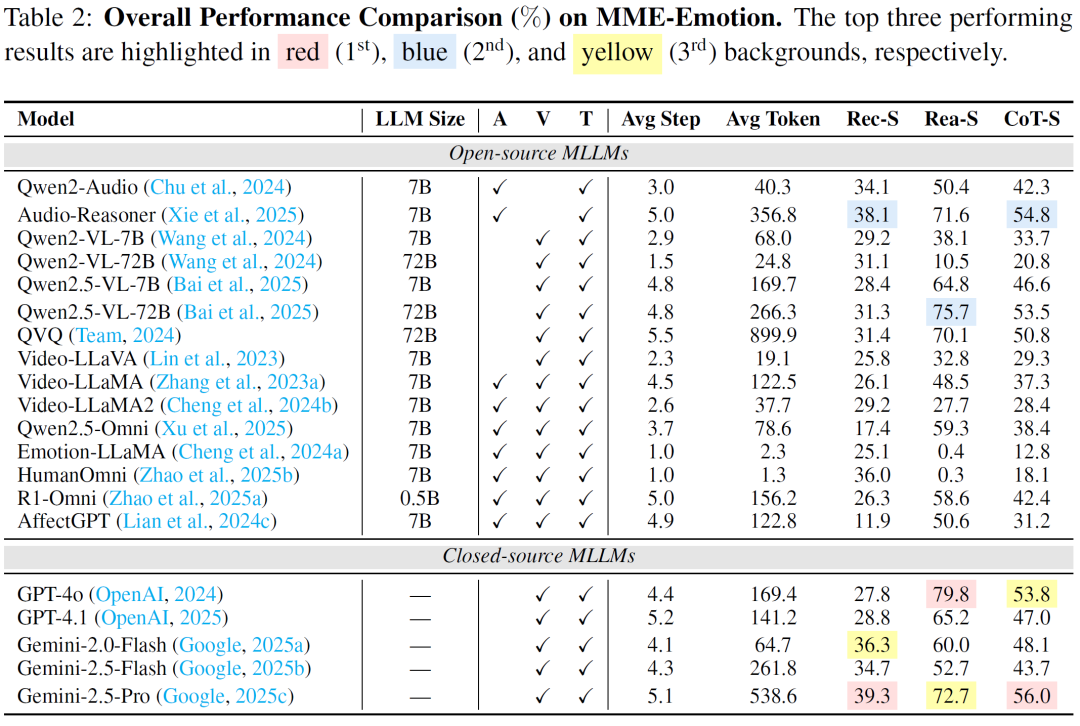
在 MME-Emotion 基准上,研究团队评测了 20 个当前主流多模态大模型,包括多个开源模型以及闭源模型,如 GPT-4o、Gemini 系列以及 Qwen 系列模型。
实验结果显示,即使是当前最先进的模型,在情感智能方面仍然存在明显不足。表现最好的模型情绪识别得分不到 40%,综合思维链得分也只有约 56%。从整体平均结果来看,各模型在情绪识别任务上的表现仍然处于较低水平。
这些结果说明,多模态大模型虽然在视觉理解和语言推理方面取得了显著进展,但情感理解仍然是一个具有挑战性的方向。
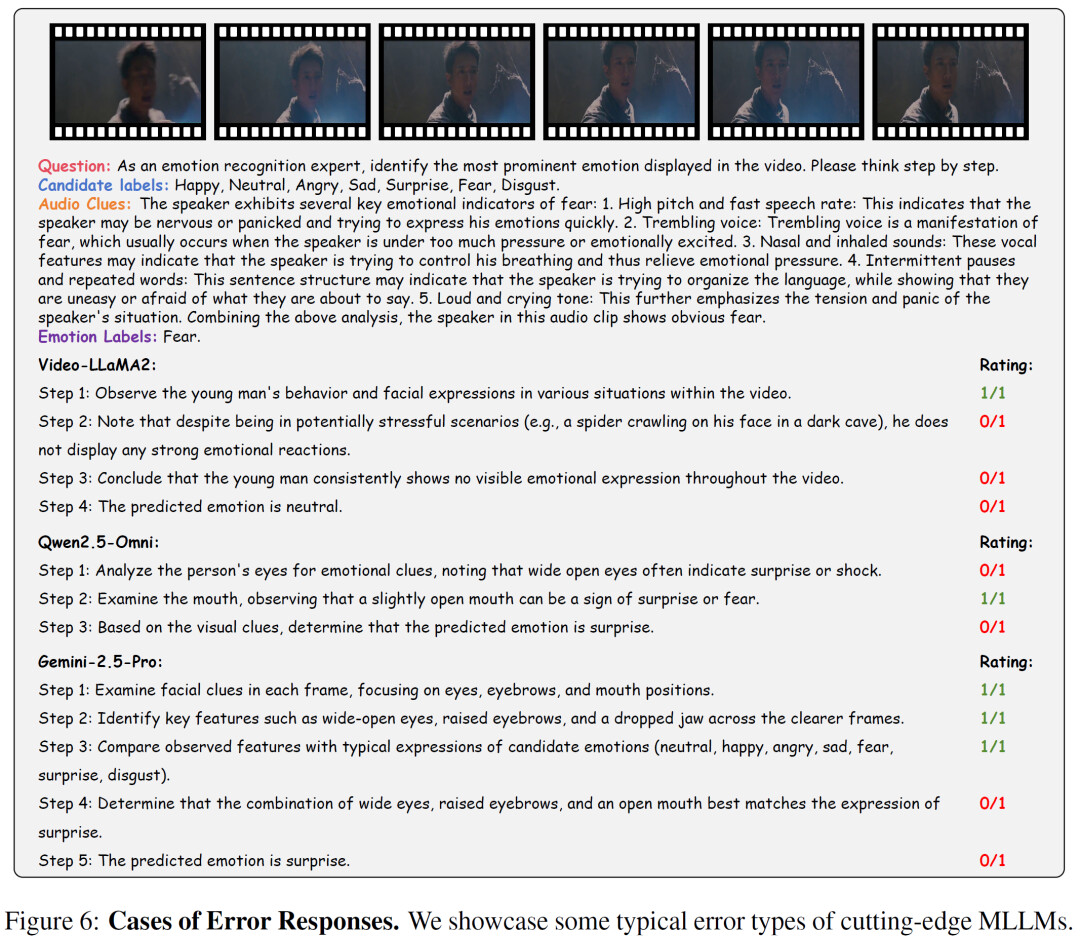
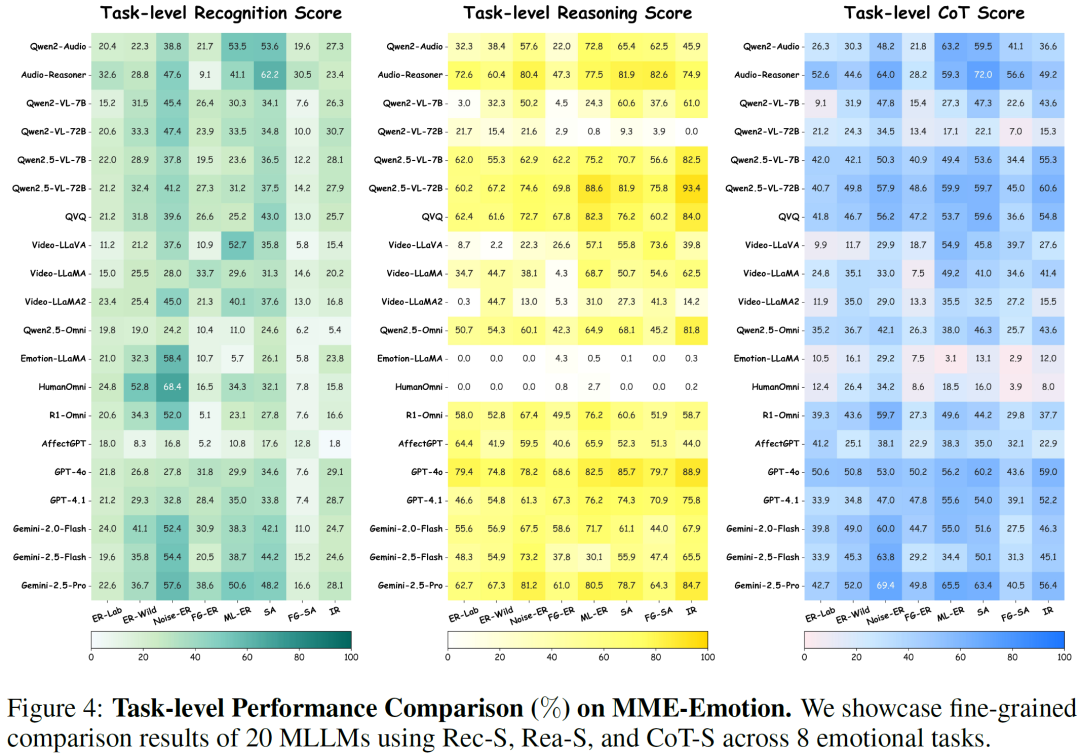
进一步分析发现,目前模型在情感任务中主要存在几类典型问题。
首先是细粒度视觉理解能力不足。在许多错误案例中,模型难以区分相似情绪,例如恐惧与惊讶之间的差别。这类错误通常源于对面部表情和细微动作变化理解不足。
其次是多模态信息融合能力有限。一些模型在仅使用视觉信息时表现尚可,但当需要同时结合语音和视觉信息时反而出现性能下降。这说明当前模型在处理多模态情感线索时仍然存在困难。
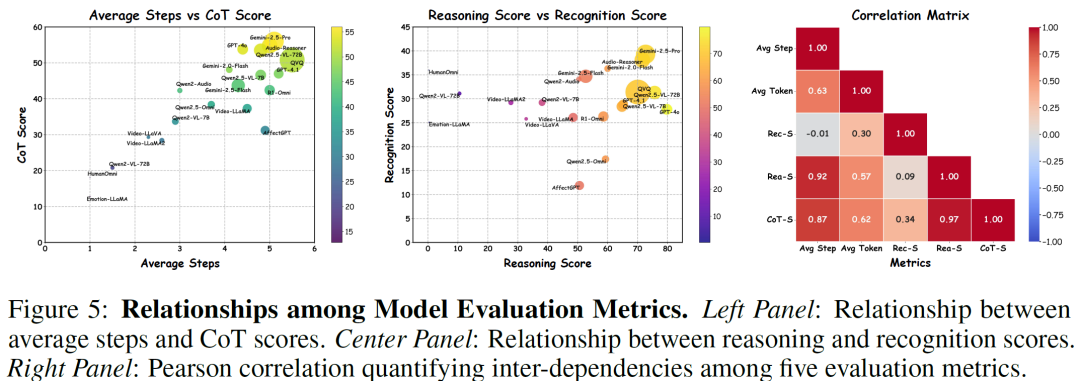
此外,研究还发现模型推理能力与情绪识别能力之间存在明显相关性。通常来说,能够给出更完整推理过程的模型,其整体情感智能表现也更好。这一现象表明,推动模型进行更深入的推理可能是提升情感智能的一条重要路径。
整体来看,MME-Emotion 提供了一个更加全面的评测框架,使研究者能够系统分析多模态大模型在情感理解方面的能力边界。
研究团队认为,未来多模态情感智能的发展可能依赖几个关键方向,包括更高精度的视觉细节建模、更有效的语音与视觉信息融合方法,以及能够解释情绪产生原因的推理机制。
随着多模态大模型不断发展,情感智能有望成为人工智能系统的重要能力之一。在教育、人机交互和医疗辅助等应用场景中,能够理解人类情绪的智能系统将具有重要价值。
MME-Emotion 的发布为这一研究方向提供了统一评测标准,也为后续模型改进提供了清晰的参考基线。
作者介绍
章帆,香港中文大学计算机科学与工程系博士生,导师为 Pheng-Ann Heng 教授。主要研究方向为多模态大模型与 Agent 系统,关注多模态理解、推理能力评测以及面向复杂任务的智能体工作流设计。近年来在 ICLR、CVPR、NeurIPS 等国际会议发表多篇论文,相关研究工作涵盖多模态大模型评测基准构建、后训练以及深度研究型智能体(Deep Research Agents)。目前致力于探索多模态 Agent 系统在复杂真实任务中的能力边界与应用潜力。
