李飞飞团队开源Spark 2.0!突破Web端3D渲染限制,实现亿级3DGS数据流式加载,人人都能访问高保真3D世界。
原文标题:刚刚,李飞飞世界模型开源了个渲染神器
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Spark 2.0 中提到的虚拟内存技术,对于在Web端渲染超大规模3D场景有什么实际意义?如果网络环境不稳定,导致数据加载失败,Spark 2.0 会如何处理?
3、除了游戏和VR/AR应用,你认为Spark 2.0 这种Web端3D渲染技术,还能在哪些领域发挥作用?它可能会给这些领域带来哪些变革?
原文内容
刚刚,李飞飞世界模型新成果来了,还是开源的!

就在今天凌晨,李飞飞空间智能独角兽公司 World Labs 官宣推出「Spark 2.0」,将最具野心的 3DGS(3D 高斯泼溅)世界带入到 Web。
这意味着,原本只有专业设备才能运行的超大规模、高保真 3D 场景,现在变成任何人都可以在浏览器中访问的内容。
而随着高保真 3D 内容可以在任意设备上进行访问,包括手机、VR 设备等,空间叙事能力向前迈进了一大步。
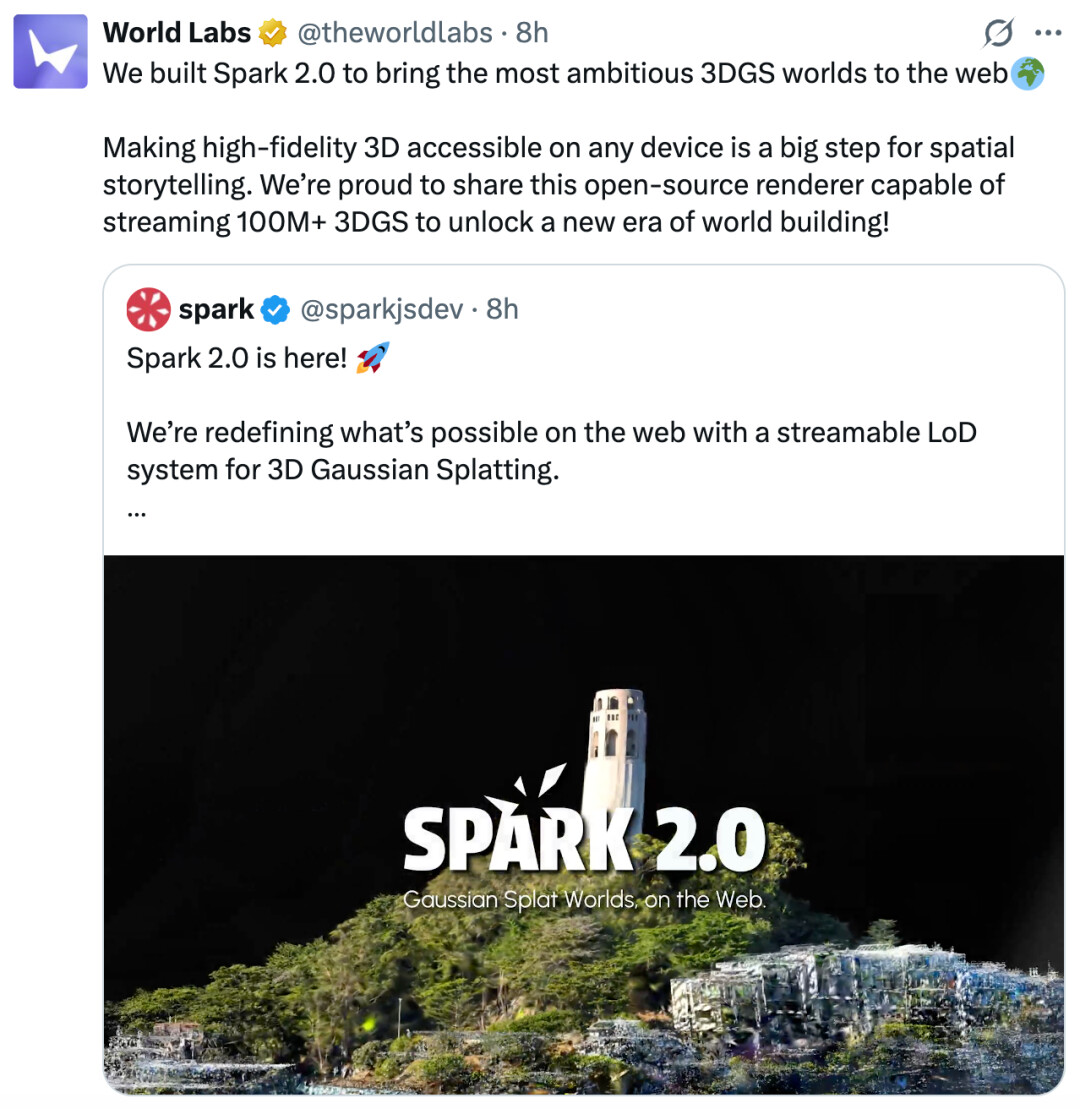
这个专为 3DGS 打造的渲染器还是开源的,可以流式加载 1 亿 + 的 3DGS 数据,将构建一个全新的 3D 物理世界。
3D 高斯泼溅渲染神器,Spark 2.0 来了
作为一个面向 Web 的动态 3D 高斯泼溅(3DGS)渲染器,Spark 与当前最流行的 Web 3D 框架 Three.js 集成,并基于 WebGL2 运行,因此只要有浏览器,无论是桌面端、iOS、Android,还是 VR 设备,都可以使用。
在去年发布时,Spark 就带来了不少其他渲染器没有的能力:比如在同一场景中渲染多个 3DGS 对象、实时编辑与重光照,以及一个着色器图系统让用户可以基于 splat 创建完全动态的特效和动画。
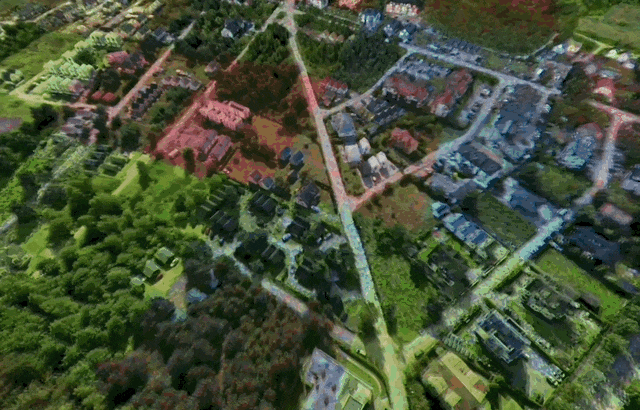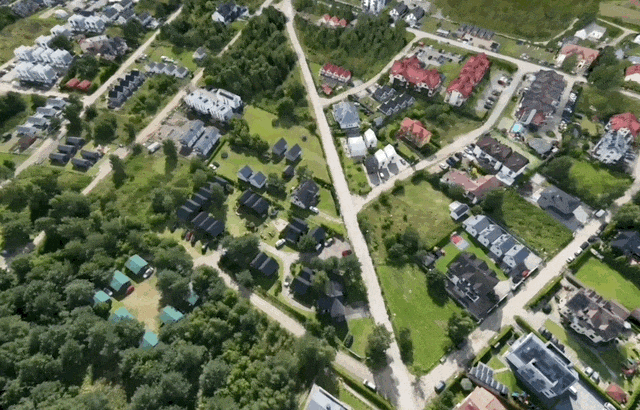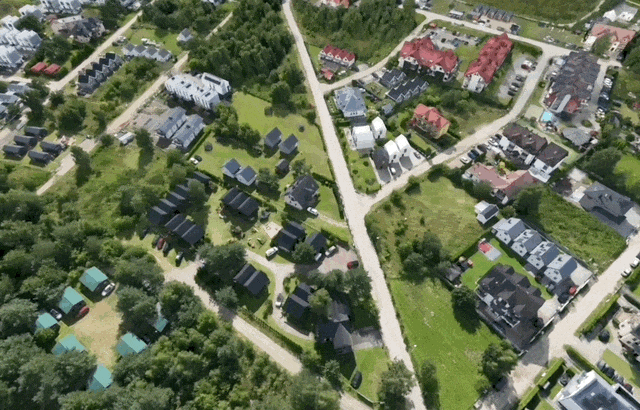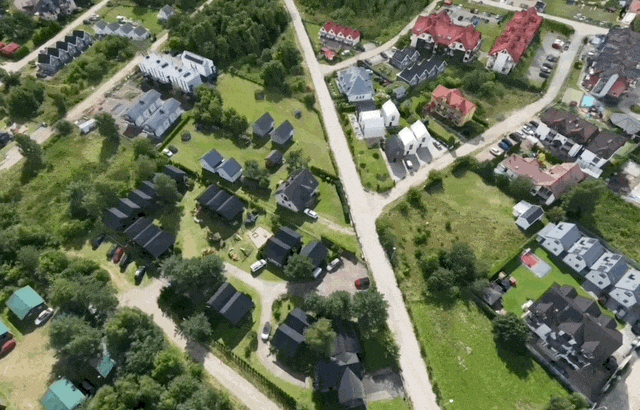
而在 Spark 2.0 中,团队加入了一个细节层级(LoD)系统,可以在任意设备上流式加载并渲染超大规模的 3DGS 世界。当你在场景中移动时,Spark 会根据当前视角自动调整 3DGS 的细节等级,并通过网络按需加载所需数据。我们先来看以下几个场景的展示图:


接着来看技术细节。
Spark 2.0 提供了一整套解决方案,用来在 Web 上为各类设备准备、传输并渲染超大规模的 3DGS 场景。为了解决规模化带来的挑战,它主要用了三类图形学和系统层面的技术:
-
Level-of-Detail(细节层级):为 splat 生成不同分辨率的版本,并根据当前相机视角决定实际渲染哪一部分。当对象距离较远、细节难以分辨时,就减少渲染的 splat 数量,从而提升性能。
-
渐进式流加载(Progressive Streaming):随着数据下载,从粗到细逐步加载 3DGS 的细节内容,并优先加载那些最能提升当前视角清晰度的数据。
-
虚拟内存(Virtual Memory):在 GPU 中分配一块固定大小的内存池,用作 splat 的页表,根据场景中的位置,自动换入和换出所需的 3DGS 数据块。这样一来,就能访问跨多个 3DGS 对象、通过网络获取的海量数据。
细节层级(LoD)高斯 splat 树
Spark 的 LoD 设计采用的是连续 LoD 方法,即所有 splat 都被组织在一个层级结构中,也就是一棵 LoD splat 树。Spark 会在这棵树上选择一条「切面」,从中逐个挑选 splat,使当前视口中的细节达到最优。
在这棵树里,每一个内部节点,都是由其子节点合并得到的低分辨率版本:通过把多个子 splat 合成为一个新的 splat,用来近似它们整体的形状和颜色。这个过程不断向上递归,直到树的根节点,也就是:一个单一的大 splat 汇总了整个对象中所有 splat 的整体形状与颜色。
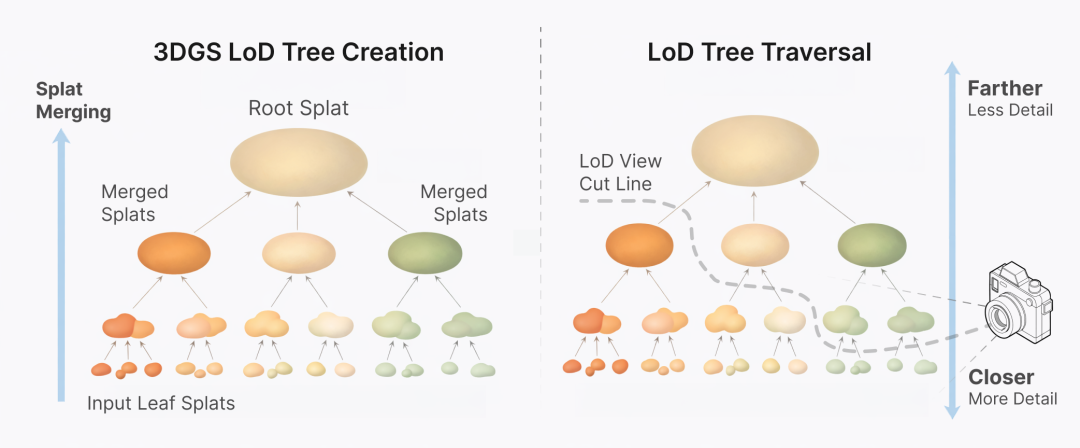
Spark 2.0 提供了两种用于生成 LoD splat 树的算法:
-
一种轻量且速度更快的算法,叫做 Tiny-LoD,在 Web 端默认使用;
-
一种质量更高的算法,叫做 Bhatt-LoD,在命令行环境中默认使用。
这两种方法都「无需训练」,不依赖参考图像或其他输入数据,而是直接基于 3DGS 数据本身进行处理。
渐进式流
Spark 2.0 定义了一种新的文件格式 .RAD(Radiance fields),用于压缩 3DGS 数据,并支持在网络传输过程中进行随机访问,实现逐步细化的流式加载。
在加载初期,3DGS 对象会以一个大约 6.4 万 splat 的粗略版本几乎瞬间呈现出来。随后系统会分块获取数据,优先细化当前画面中最粗糙、最需要提升细节的 LoD splat,并随着用户在场景中的移动动态调整加载优先级。
虚拟内存
虚拟内存是一种内存管理技术,通过一小块固定的「物理内存」,来提供对海量虚拟内存的访问能力。系统通过页表,将虚拟地址与物理内存中的固定大小页进行映射。
Spark 2.0 将这一机制引入到 3DGS 中,在 GPU 上分配一个固定容量(约 1600 万 splat)的内存池,并自动管理 GPU 中 64K splat 的「页」与 .RAD 文件中对应的 64K 数据块之间的映射关系。
数据块会按照 LoD 遍历顺序加载进空闲页中;当页表已满时,如果有新的、更高优先级的数据需要加载,就会按照「最近最少使用」(LRU)的策略,把优先级较低的旧数据块替换出去。

更多技术细节请参考博客原文。
博客地址:https://www.worldlabs.ai/blog/spark-2.0

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com