OpenCLI主张绕开UI点击,直接抓取并复现网页API,把浏览器操作转成更稳定的CLI。
原文标题:浏览器自动化:从GUI到OpenCLI
原文作者:阿里云开发者
冷月清谈:
核心观点有三点:1)传统前端 UI 自动化容易受页面结构、按钮位置、加载时机影响,维护成本高;2)网页展示的数据本质上多来自接口,请求一旦被识别和复现,自动化会更稳定、更高效;3)Agent 做浏览器探索时不能只看静态页面,必须真实打开网页、触发交互、观察懒加载请求,才能发现评论、字幕、关注列表等深层接口。
文章介绍了 OpenCLI 的基本能力,包括命令发现、公共 API 调用、浏览器相关命令,以及 YAML 和 TypeScript 两种适配器形式。它还设计了五级认证策略,从公开接口、Cookie、Header,到状态管理拦截和最终不得已的 UI 自动化,形成一套逐级降级的执行路径。
在自动生成 CLI 方面,OpenCLI 支持 explore、synthesize、generate、record 等流程,用于探索网页、合成适配器、验证命令与录制操作。文章也坦承目前录制能力对写操作支持不足,尤其是无法完整提取 POST/PUT 的请求体,因此更适合只读类场景。
作者最后把话题提升到软件形态演进:未来软件竞争的不只是界面体验,还包括是否足够“可调用”,能否被 Agent 稳定理解、接入和验证。
怜星夜思:
2、问题2:文章强调“未来软件竞争可调用性”,你觉得这会不会真的成为 SaaS 或内部系统的重要评估指标?
3、问题3:OpenCLI 这种“抓网页真实接口生成命令”的方式,在哪些场景最有价值,哪些场景又可能踩坑?
4、问题4:五级认证策略里把 UI 自动化放在最后手段,你认同这种优先级吗?有没有例外?
原文内容

阿里妹导读
文章讲述放弃不稳定的前端UI自动化操作,采用解析并复现底层API请求的方式,来解决浏览器自动化的效率与稳定性难题。(文章内容基于作者个人技术实践与独立思考,旨在分享经验,仅代表个人观点。)
为什么我们需要浏览器自动化
如今大量业务系统都跑在浏览器里——运营配置后台、工单处理系统、发布运维平台。如果能让这些系统自动运转,对提效和智能化运营的价值不言而喻。
但现实是,Agent 想操控浏览器,路并不好走。
现有方案的困境
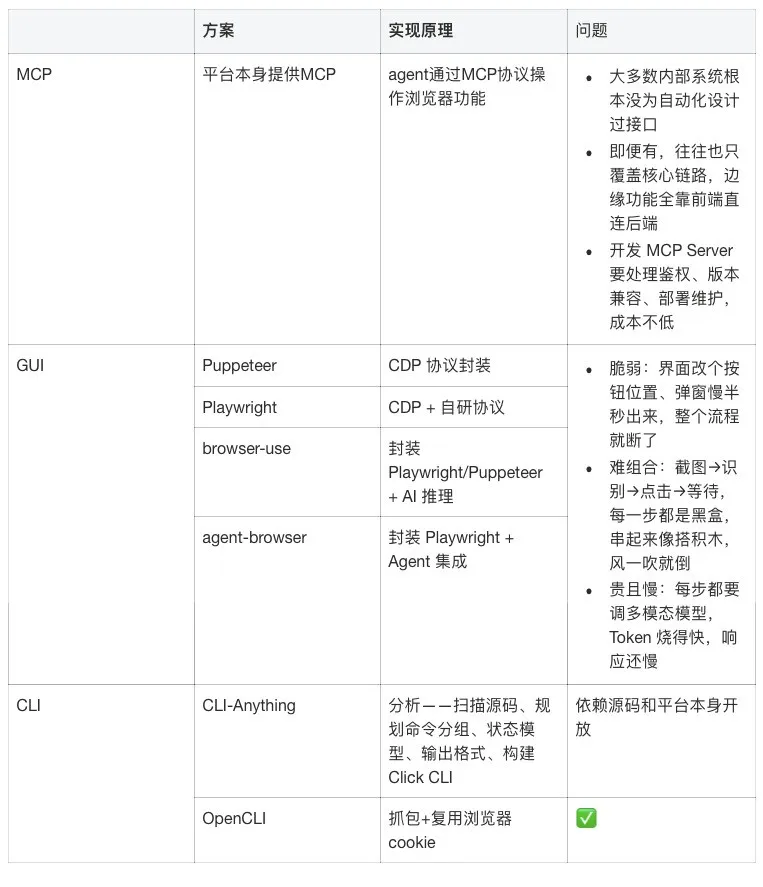
OpenCLI 的思路
核心想法很简单:不跟网页界面较劲,直接抓它背后的 API。
浏览器里看到的数据,本质上都是前端从某个接口拿回来的。把这个接口找出来、把请求复现出来,比点按钮靠谱得多。
快速上手
npm install -g @jackwener/opencli
直接使用:
opencli list
# 查看所有命令
opencli list -f yaml
# 以 YAML 列出所有命令
opencli hackernews top --limit
5
# 公共 API,无需浏览器
opencli bilibili hot --limit
5
# 浏览器命令
opencli zhihu hot -f json
# JSON 输出
opencli zhihu hot -f yaml
# YAML 输出
原理分析
AI Agent 探索工作流
|
步骤 |
工具 |
做什么 |
|
0. 打开浏览器 |
|
导航到目标页面 |
|
1. 观察页面 |
|
观察可交互元素(按钮/标签/链接) |
|
2. 首次抓包 |
|
筛选 JSON API 端点,记录 URL pattern |
|
3. 模拟交互 |
|
点击"字幕""评论""关注"等按钮 |
|
4. 二次抓包 |
|
对比步骤 2,找出新触发的 API |
|
5. 验证 API |
|
|
|
6. 写代码 |
— |
基于确认的 API 写适配器 |
懒加载机制
> [!CAUTION] > **你(AI Agent)必须通过浏览器打开目标网站去探索!** > 不要只靠 `opencli explore` 命令或静态分析来发现 API。 > 你拥有浏览器工具,必须主动用它们浏览网页、观察网络请求、模拟用户交互。为什么?
很多 API 是懒加载的(用户必须点击某个按钮/标签才会触发网络请求)。字幕、评论、关注列表等深层数据不会在页面首次加载时出现在 Network 面板中。如果你不主动去浏览和交互页面,你永远发现不了这些 API。
五级认证策略
OpenCLI 提供 5 级认证策略。使用 cascade 命令自动探测:
opencli cascade https://api.example.com/hot
策略决策树:
直接 fetch(url) 能拿到数据?
→ ✅ Tier 1: public(公开 API,不需要浏览器)
→ ❌ fetch(url, {credentials:'include'}) 带 Cookie 能拿到?
→ ✅ Tier 2: cookie(最常见,evaluate 步骤内 fetch)
→ ❌ → 加上 Bearer / CSRF header 后能拿到?
→ ✅ Tier 3: header(如 Twitter ct0 + Bearer)
→ ❌ → 网站有 Pinia/Vuex Store?
→ ✅ Tier 4: intercept(Store Action + XHR 拦截)
→ ❌ Tier 5: ui(UI 自动化,最后手段)
适配器
你的 pipeline 里有 evaluate 步骤(内嵌 JS 代码)?
→ ✅ 用 TypeScript (src/clis/<site>/<name>.ts),保存即自动动态注册
→ ❌ 纯声明式(navigate + tap + map + limit)?
→ ✅ 用 YAML (src/clis/<site>/<name>.yaml),保存即自动注册

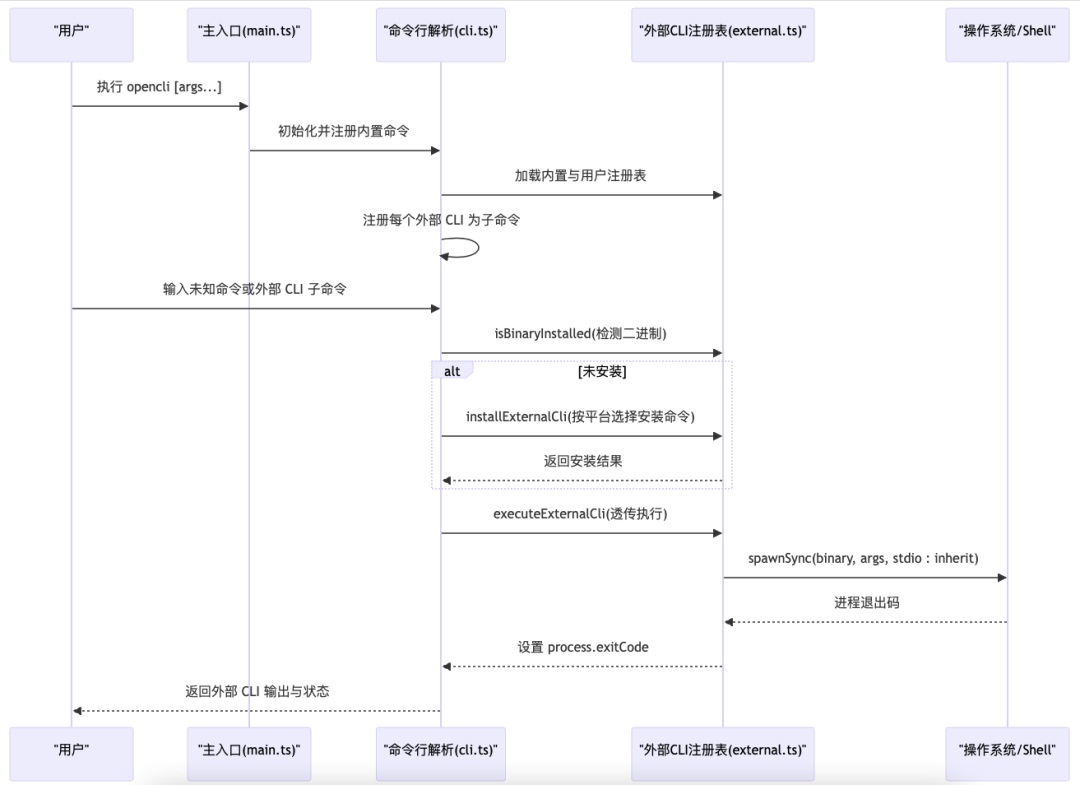
外部CLI集成
也支持现有CLI直接集成到OpenCLI
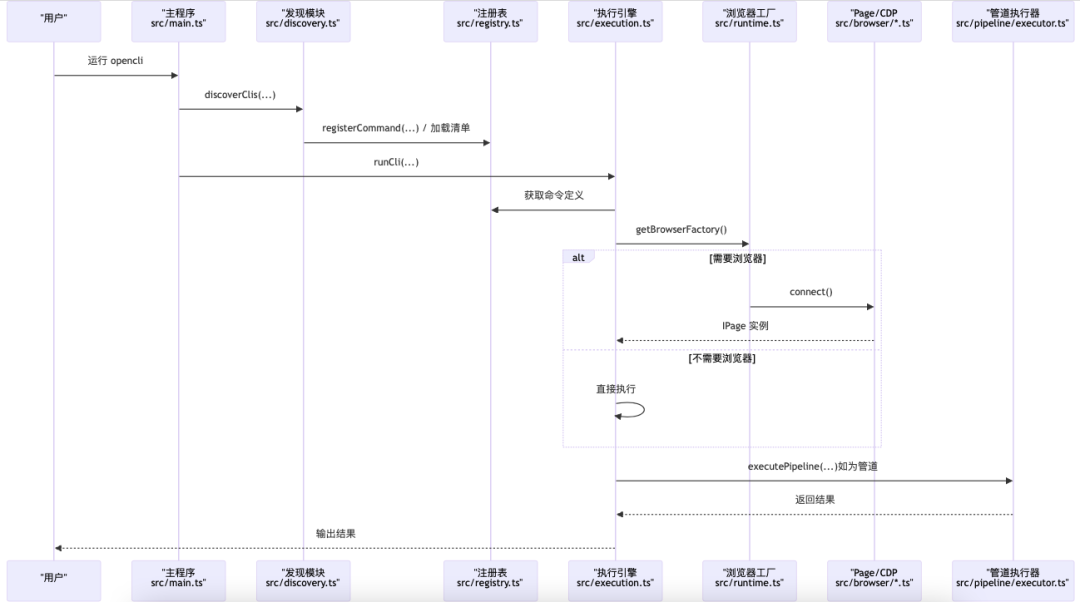
CLI执行流程
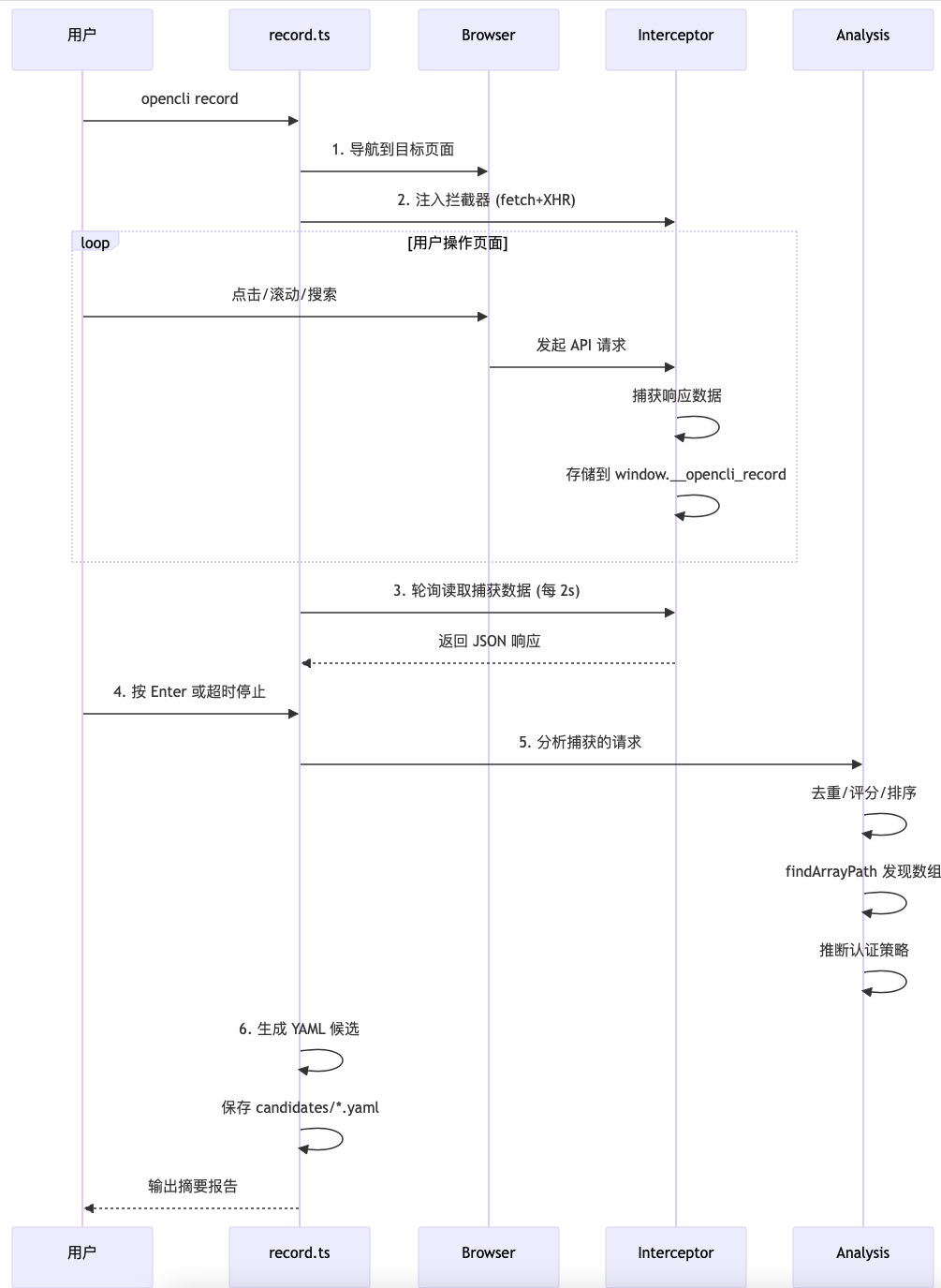
下图展示从启动到执行的关键路径:入口加载命令清单,构建注册表;执行阶段根据策略与浏览器需求选择适配器或管道步骤,完成数据采集与输出。
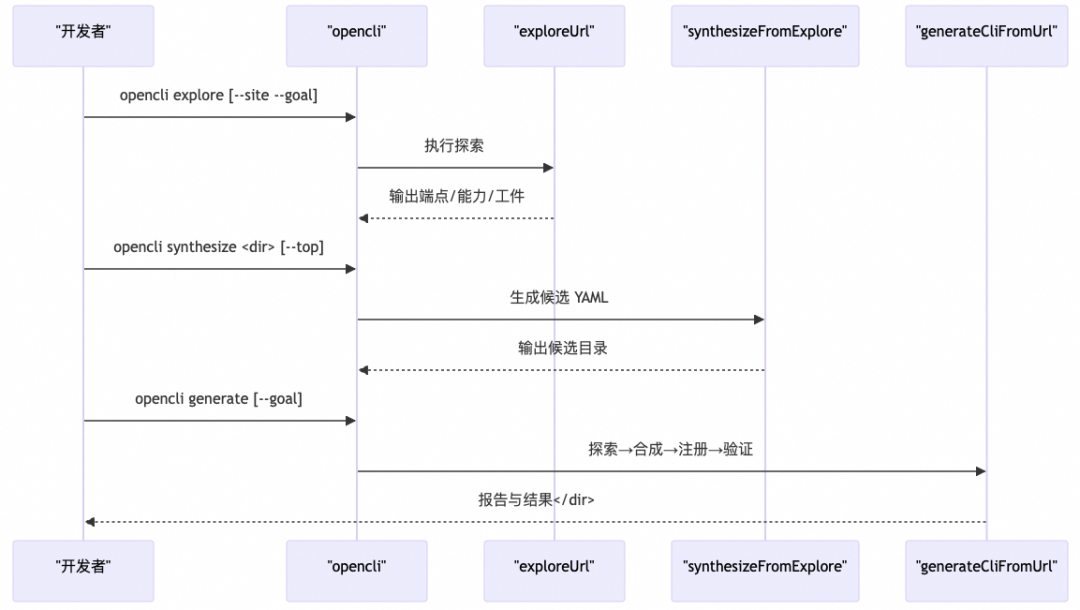
自动生成CLI
AI 原生生成CLI流程
1.探索与分析:explore 深度抓取页面、自动滚动、拦截网络请求、识别框架与状态管理、推断能力与推荐参数。
2.策略选择:根据鉴权头/签名等特征自动选择策略(public/cookie/header/intercept/store-action)。
3.适配器合成:synthesize 基于探索产物生成候选 YAML,自动模板化 URL、字段映射与参数默认值。
4.测试与验证:generate 串联探索→合成→注册→验证,支持目标化选择与回退策略。
-
请求体(Payload)缺失:目前的录制引擎仅捕获请求元数据(url, method, body: responseBody),未能完整提取 POST/PUT 等写操作中的 Request Body。
-
生成能力受限:由于缺乏关键参数载荷,自动化脚本生成逻辑目前仅能覆盖只读类接口(如列表查询、详情获取并输出 YAML),无法有效支撑写操作类接口(如创建、更新、删除)的命令生成,导致自动化闭环在“写入场景”中断。
QoderWork自动生成CLI
为了方便自动生成CLI命令,我整理了如下的Skill,其中CLI-ONESHOT.md和CLI-EXPLORER.md可在开源项目中自行下载。
SKILL.md
--- name: opencli description: "Generate CLI adapter files (YAML/TypeScript) for the opencli framework. Use when the user wants to create CLI commands, build adapters for websites or APIs, or interact with the opencli tool. Covers browser-based API discovery, authentication strategy selection, and adapter generation workflows." ---OpenCLI Adapter Generator
Overview
OpenCLI is a CLI framework that wraps website APIs into local command-line tools. This skill guides the agent through discovering APIs via browser exploration, selecting authentication strategies, and generating adapter files (YAML or TypeScript) placed in
~/.opencli/clis/{site}/{command}.yaml|.ts.Workflow Modes
Quick mode (single command): Follow CLI-ONESHOT.md — just a URL + description, 4 steps.
Full mode (complex adapters): Read CLI-EXPLORER.md before writing any code. It covers: browser exploration workflow, auth strategy decision tree, platform SDKs (e.g. Bilibili
apiGet/fetchJson), YAML vs TS selection,tapstep debugging, cascading request patterns, and common pitfalls.Output Specification
All adapter files must be written to
~/.opencli/clis/{site}/{command}.yamlor.ts. No other output locations or file formats (.js,.json,.md,.txt) are permitted.Correct examples:
-~/.opencli/clis/aem/page-views.ts
-~/.opencli/clis/twitter/lists.yaml
-~/.opencli/clis/bilibili/favorites.tsSupported Formats
Format Extension When to use YAML .yamlSimple scenarios (Cookie/Public auth, straightforward flows) TypeScript .tsComplex scenarios (Intercept capture, Header auth, multi-step logic) Standard Workflow
1. Create directory:
mkdir -p ~/.opencli/clis/{site}
2. Generate adapter file at the correct path (YAML or TS)
3. Verify:opencli list | grep {site}thenopencli {site} {command} {option}Naming Conventions
Element Rule Good Bad site Lowercase, hyphens allowed aem,my-siteAEM,my_sitecommand Lowercase, hyphen-separated page-views,project-infopageViews,project_infoPre-Generation Checklist
- Output path is~/.opencli/clis/{site}/{command}.yamlor.ts
- Site name is lowercase (no uppercase, no underscores)
- Command name uses hyphens (no spaces, no underscores)
- File extension is.yamlor.tsonly
- Directory~/.opencli/clis/{site}/has been created
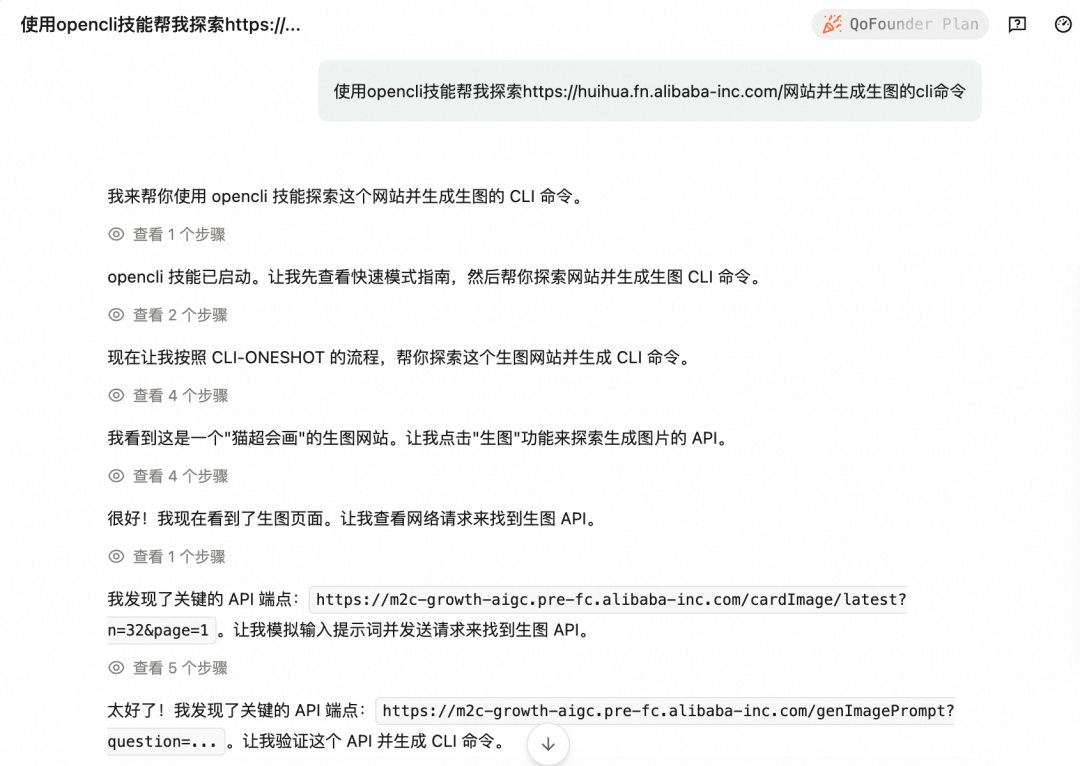
使用case:
内部会画平台CLI化
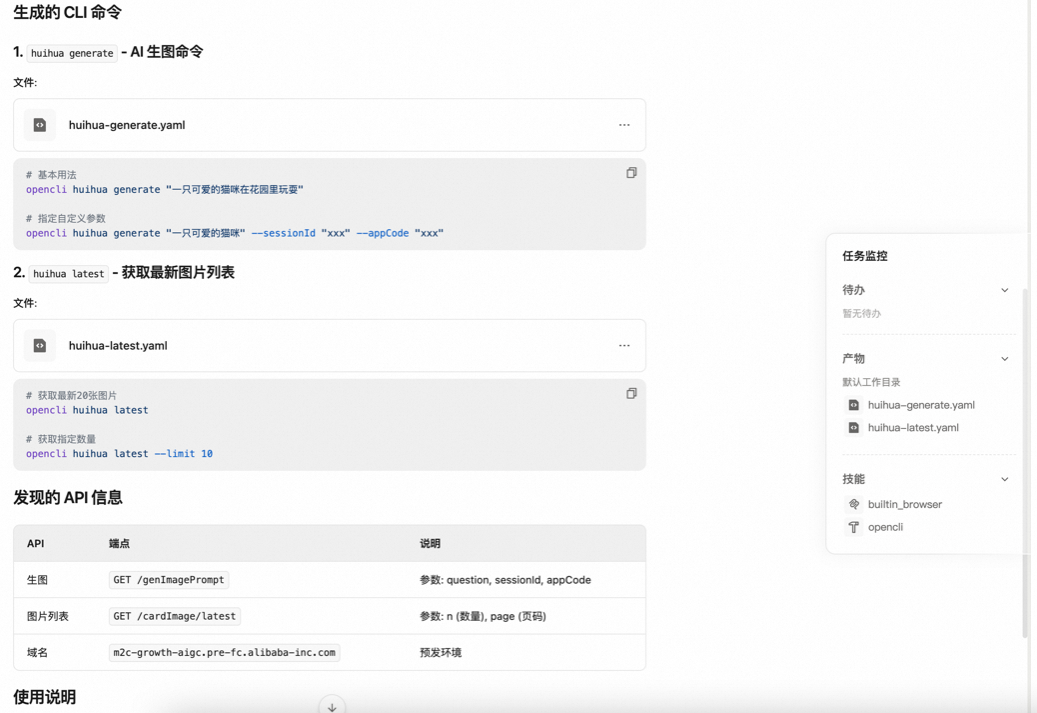

BOSS招聘自动化案例展示
1.帮我和候选人沟通

2.统计招聘数据
未来软件竞争维度:从界面到可调用性
未来的软件,不会只服务人,也会服务 Agent。
以前我们评价一个 SaaS,看的是界面顺不顺、按钮好不好点。但 Agent 不会欣赏你的按钮做得多圆。它只在乎一件事:能不能稳定调用你。
GUI 是给人用的。API 是能力底座。而 Agent 最喜欢的,其实是更清晰的执行面:命令、参数、返回值、失败原因。
未来软件可能会多一个新竞争维度:不是谁页面更好看。而是谁更容易被 Agent 理解、调用、验证,再接进工作流。唯有如此,才更有机会成为下一代工作流里的基础节点。
过去的软件竞争界面,未来的软件竞争可调用性。