Gram Newton-Schulz 通过重构 Muon 正交化流程,将训练耗时降低 40%~50%,并保持模型效果基本不变。
原文标题:大模型训练避坑:Muon 正交化的 50% 提速全方案
原文作者:数据派THU
冷月清谈:
新方法的核心思路,是把原本在大矩形矩阵上的迭代,转移到更小且具对称性的 Gram 矩阵上进行。这样不仅减少了浮点运算量,也能利用对称结构避免重复计算,在典型场景下理论上可显著节省算力。
不过,这种重构在半精度环境下容易出现数值不稳定。为此,团队加入了重启策略、代数重排和精度回退等设计,尽量抑制伪负特征值和截断误差带来的崩溃风险。同时,在工程层面配合 Hopper、Blackwell 架构的定制对称矩阵算子与三角调度器,进一步压缩正交化耗时。
实验结果显示,在 Llama-430M、Qwen-600M、Gemma-1B 和 MoE-1B 等模型上,新方案与原版 Muon 的效果几乎一致,验证集困惑度差异控制在很小范围内;而在训练效率上,正交化端到端耗时可降低 40%~50%,特定并行负载下甚至达到 2 倍加速。整体来看,这是一个兼顾数学重构、数值稳定性和硬件适配的训练加速方案。
怜星夜思:
2、问题2:这篇文章反复强调“算法与硬件协同设计”,你觉得这会不会成为以后大模型基础设施优化的常态?
3、问题3:文章里提到数值稳定性修复很关键。你认为在训练系统里,‘更快’和‘更稳’哪一个更难做好?
4、问题4:像这种针对 Muon 正交化的大幅优化,你觉得接下来最值得继续挖的方向会是什么?
原文内容

本文约2000字,建议阅读5分钟本文介绍了优化 Muon 正交化的 Gram Newton-Schulz 算法及提速方案。
万亿模型训练的免费午餐,一个数学 trick 让 Muon 提速 50%。
万亿模型训练的免费午餐,一个数学 trick 让 Muon 提速 50%。
在万亿参数大模型的竞逐中,训练效率的细微差距往往关乎巨大的算力成本。近期,Kimi K2 与 GLM-5 等前沿语言模型开始广泛采用 Muon 优化器。
对比 AdamW,Muon 达到特定损失值所需的优化器步数更少,但单步计算开销显著增加。
这种开销主要来自 Newton-Schulz 正交化过程,引入了早期优化器中不存在的三次方时间复杂度矩阵运算。
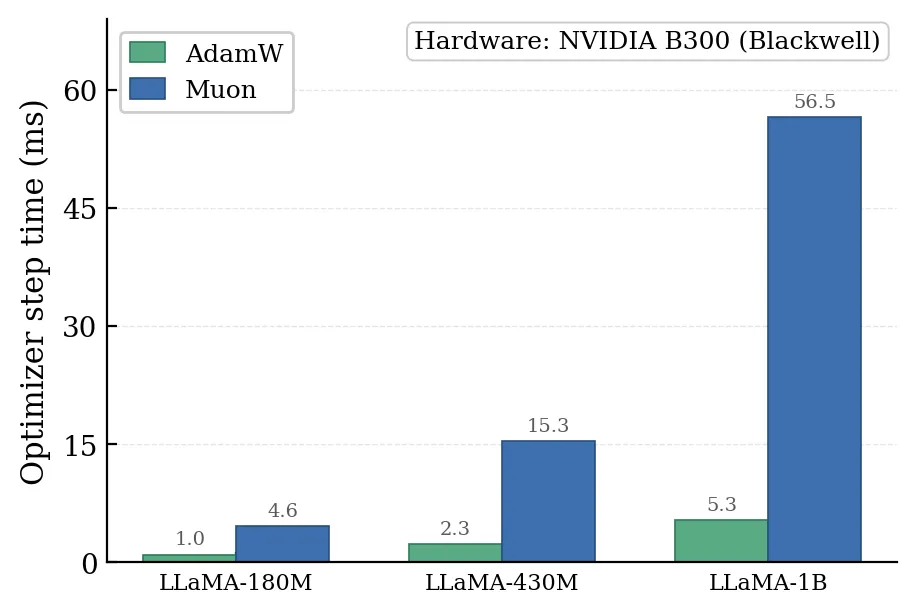
〓 Muon 与 AdamW 单步实际运行时间的对比
为突破该算力瓶颈,普林斯顿大学 Tri Dao 团队(Mamba 与 FlashAttention 核心作者)联合纽约大学研究人员提出了 Gram Newton-Schulz 算法。
在万亿参数 MoE 模型训练中,该算法将正交化步骤的端到端耗时有效降低了 40% 至 50%。
目前团队已将该算法开源,作为标准 Muon 优化器的即插即用替换模块,无需繁琐配置即可直接获得加速收益。
文章标题:
GREPO: A Benchmark for Graph Neural Networks on Repository-Level Bug Localization
文章链接:
https://dao-lab.ai/blog/2026/gram-newton-schulz/
项目链接:
https://github.com/Dao-AILab/gram-newton-schulz
核心算子链接:
https://github.com/Dao-AILab/quack/blob/main/quack/gemm_symmetric.py
1、为什么标准算法这么慢?
传统优化器(如AdamW)执行逐元素操作,时间复杂度为 。
Muon 等现代优化器需要进行正交化,单步计算需要耗费 的时间(假设 )。
Muon 的更新规则基于对动量矩阵 的极分解:
由于极分解 精确计算成本高昂,Muon 采用 Newton-Schulz 多项式迭代进行近似:
现代 Transformer 架构(特别是包含大量细粒度专家的 MoE)的权重矩阵形状大多是不规则的矩形,满足 。
标准 Newton-Schulz 需要在庞大的矩形矩阵上执行多次乘法,矩形矩阵乘法完全主导了整体计算成本。

〓 包含大量昂贵矩形矩阵乘法的标准 Newton-Schulz 伪代码
更关键的是,算法执行期间产生的诸多中间矩阵具备对称结构,常规计算路线未能有效利用这一数学特性,导致半数计算工作冗余。

〓 标准 Newton-Schulz 在 Hopper 架构下的纯算子优化收益
2、Gram矩阵的数学重构
算法的核心在于转移迭代空间:不再对庞大的矩形输入矩阵 进行迭代,而是转移至尺寸更小且对称的方形 Gram 矩阵 。
极分解可表示为 。通过多项式的代数变换,Newton-Schulz 迭代隐含了计算逆平方根的过程。
核心迭代可转化为以下标量形式:
矩阵操作保留了奇异向量,该标量迭代逻辑可直接推广至矩阵空间。空间转换后,算法主体在 的对称矩阵内运行,极大削减了浮点运算次数。
在典型的 场景下,相较于未优化的标准实现,该方法理论上可节省 68% 的浮点运算次数。
3、解决数值不稳定
上述理论在精确算术下完全等价,但在真实的半精度计算环境下会引发严重的数值不稳定。研究团队通过算法与硬件的协同设计,化解了这一工程隐患。
重启策略
在 bfloat16 精度下计算 Gram 矩阵 会产生由于浮点误差导致的伪负特征值。由于更新规则包含平方项,初始微小的负特征值会随迭代呈指数级放大,最终导致数值崩溃。
研究团队引入了重启策略,在算法执行至中途时,利用当前的近似结果重新构造 Gram 矩阵,消除累积的负特征值并重置状态。
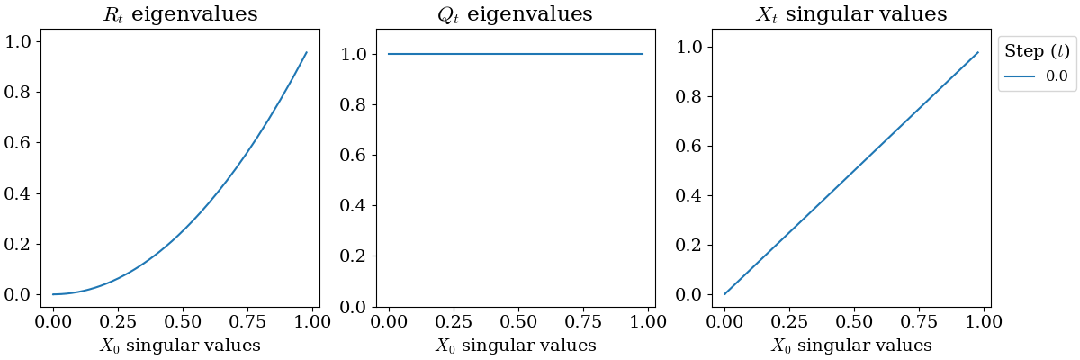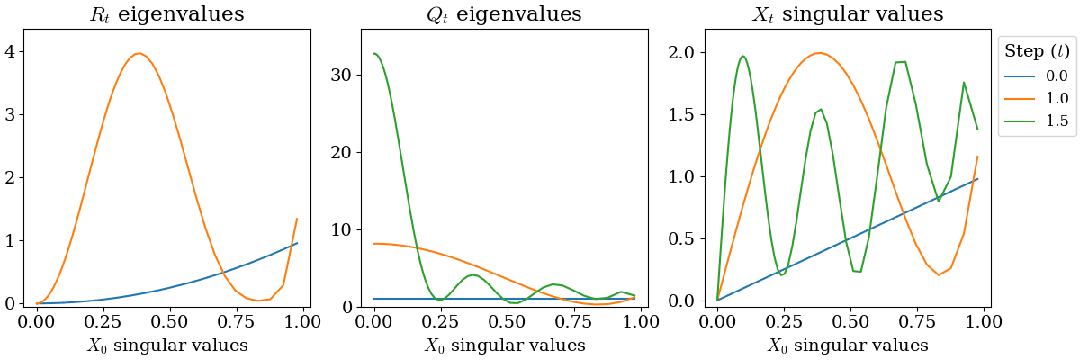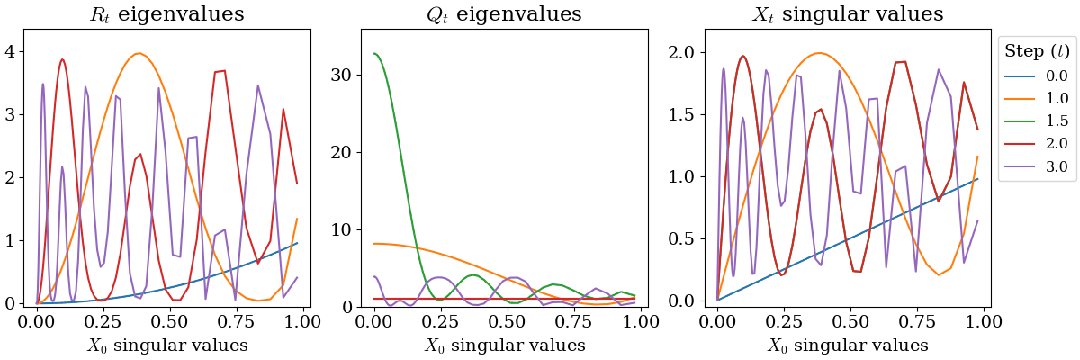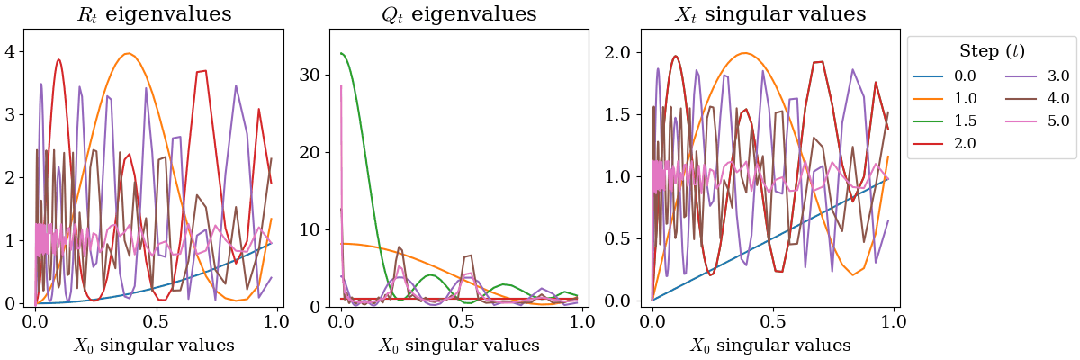
〓 引入重启策略后的特征值演变与稳定收敛
代数重排
在计算矩阵二次型时,常规方法会显式加上单位阵 。底层算子在执行该加法时,会先在 float32 下计算并由于输出限制向 float16 截断,导致后续乘法累积严重的精度损失。
团队重排了代数逻辑,将加法操作隐式融入后续计算,即先算 ,再在后续步骤中分配 的运算,全程在 float32 下保持高精度,消除了隐藏的数值隐患。
精度回退决策
针对 bfloat16 的动态范围大但精度位数不足的问题,算法在初始化阶段默认将输入张量转换为 float16。
由于矩阵范数已被严格控制在 1 附近,float16 在这一小区间内能提供更高的尾数精度,进一步夯实了数值基础。

〓 稳定的 Gram Newton-Schulz 算法伪代码
权重拆分策略
工程实现中,团队特别强调了将 SwiGLU 架构中的 和 拆分后独立进行正交化。
由于这两部分对激活函数的梯度贡献机制不同,拆分处理不仅使 Llama-430M 的验证集困惑度优化了约 0.2,更通过减半矩阵的小维度,使得依赖 复杂度的 Gram Newton-Schulz 获得了更显著的提速比例。
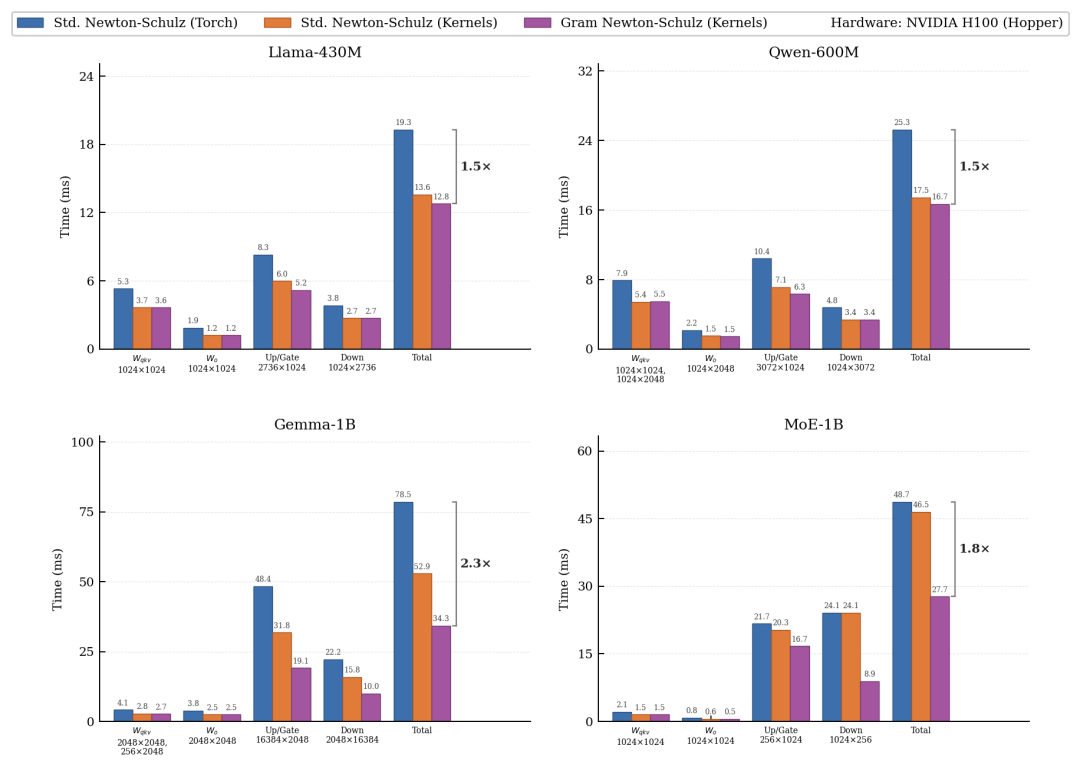
〓 不同形状权重矩阵的单步耗时拆解(极端矩形权重加速最显著)
定制三角形调度器
在底层算子层面,为最大化 Gram 矩阵对称性带来的计算红利,团队基于 CuTeDSL 针对 Hopper 和 Blackwell 架构开发了定制算子。
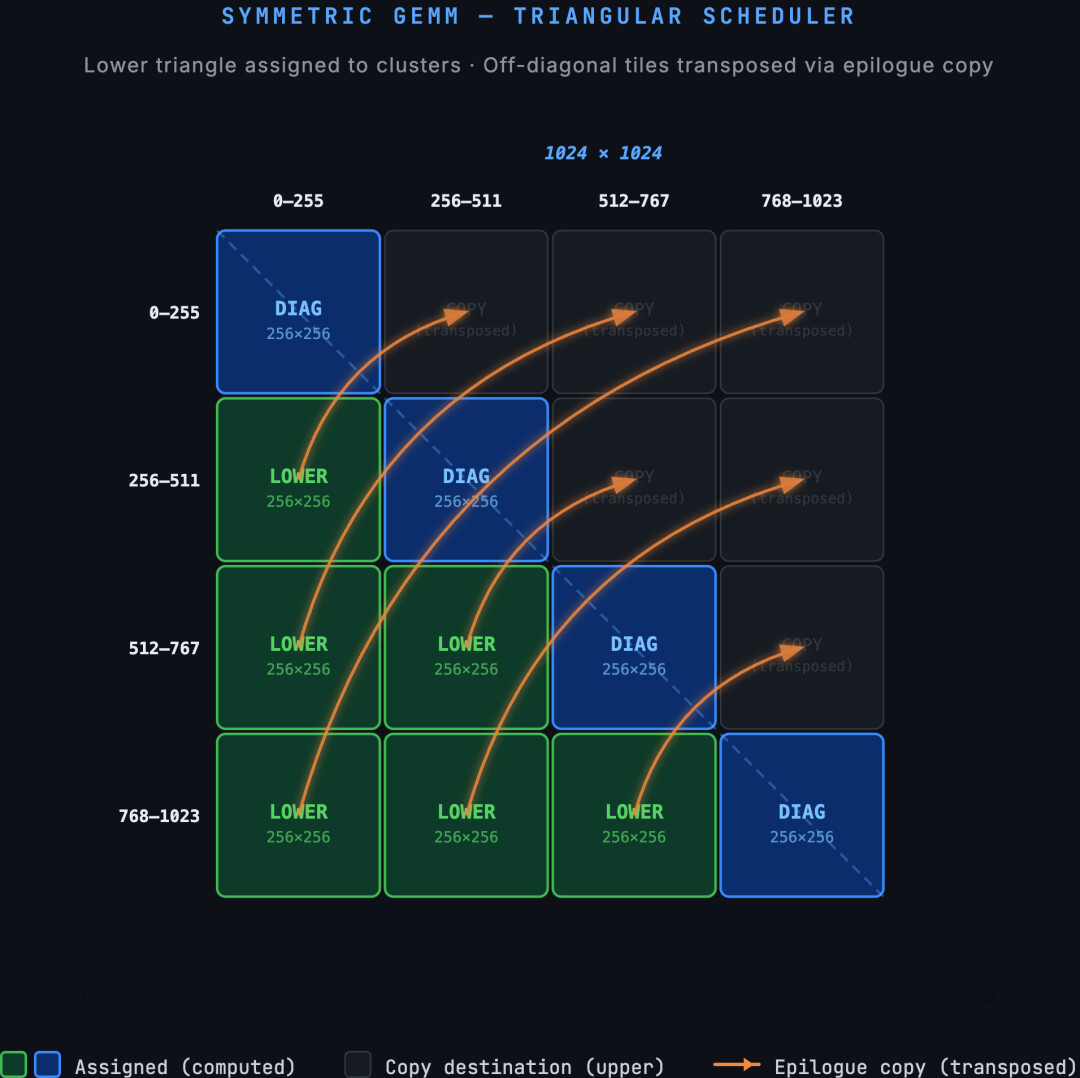
〓 对称矩阵乘法的三角形调度器示意
其核心是一个三角形调度器,仅将矩阵下三角区域的工作块分配给计算集群,并在底层内存回写时转置复制至上三角位置,确保负载均衡并消除冗余的内存访存。
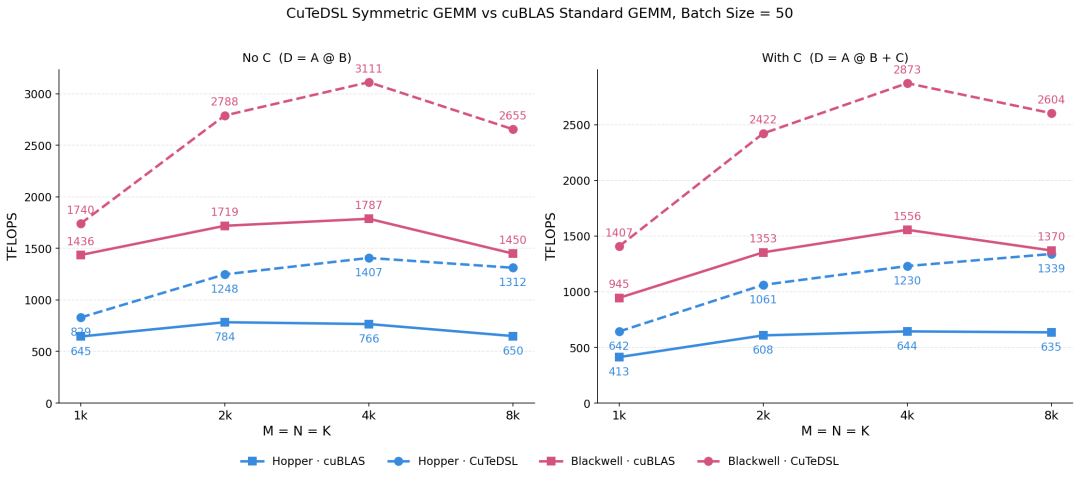
〓 定制对称算子与 cuBLAS 在不同架构下的 TFLOPS 吞吐量对比
4、实验验证与工程收益
在 Llama-430M、Qwen-600M、Gemma-1B 以及 10 亿参数规模的 MoE-1B 模型上进行的对比实验表明,使用 Gram Newton-Schulz 与原版 Muon 的验证集困惑度差异严格控制在 0.01 以内。
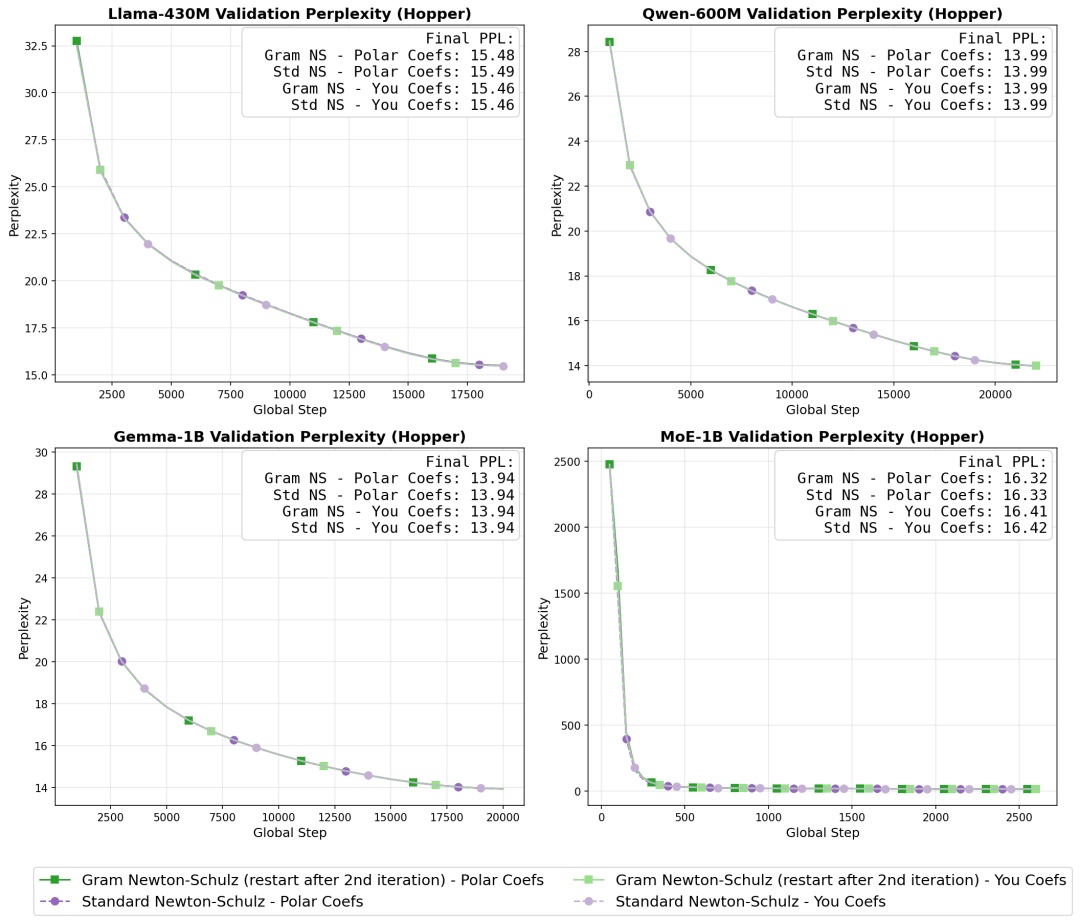
〓 不同模型上的验证集困惑度对比(Hopper 架构)
在实际训练耗时方面,新算法配合定制算子切实缩短了正交化的端到端耗时。
在模拟 Kimi K2 模型特定流水线阶段的真实并行负载测试中,Gram Newton-Schulz 实现了 2 倍的端到端正交化加速。
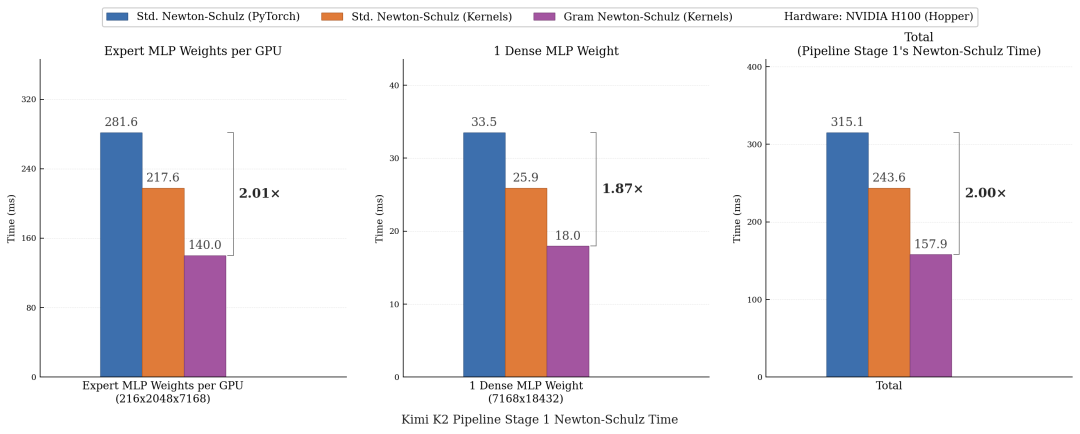
〓 Kimi K2 流水线切片下的端到端耗时对比
5、结语
Gram Newton-Schulz 通过底层的数学逻辑重构与针对性的数值稳定性修复,以及 GPU 架构级别的定制算子优化,打通了现代优化器在大规模并行训练中的效率瓶颈。
这为极度消耗算力的矩阵正交化问题提供了一条可行路径,也再次印证了算法与硬件协同设计的实用价值。
目前,研究团队已将 Gram Newton-Schulz 完整开源。在实际工程应用中,唯一需要微调的超参数仅为重启迭代的节点。
为此,开源库中提供了一个自动化调参脚本,只需输入一组多项式系数,即可自动分析并建议最优的重启节点。
这套兼具理论深度与工程可用性的工具,为受限于算力瓶颈的大模型训练提供了一份切实可用的优化方案。
