掌握数值特征缩放:标准化、Robust缩放、幂变换、归一化,解决量级差异和异常值问题,提升模型性能。
原文标题:搞懂数值特征缩放!4 种常用方法(附代码)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到了PowerTransformer可以将偏态分布转化为接近正态分布。那么问题来了,在什么情况下我们必须要把数据转化为正态分布?不符合正态分布的数据一定不能用线性回归之类的模型吗?
3、文章最后总结了四种缩放器的适用场景,请结合你实际的经验,分享一个你使用某种缩放器后,模型性能显著提升的案例,并说明原因。
原文内容

来源:DeepHub IMBA本文约4000字,建议阅读8分钟本文介绍了四种数值特征处理方法及 Scikit-learn 实操与适用场景。
数值特征工程是机器学习模型训练中不可跳过的预处理环节。处理数值数据时需要面对两个核心问题:特征的量级差异和异常值。以年龄和薪资为例,两者的数值范围差了好几个数量级,如果不做任何处理模型很可能仅凭数值大小就给薪资分配更高的权重,完全忽略年龄的作用。
偏斜分布是另一个问题。很多特征的值集中在一个很小的范围内,但同时存在少量极端值。比如一个表示兄弟姐妹数量的特征,绝大多数样本的值在 0-2 之间,但偶尔出现的 8 或 10 会把整个分布拉偏。有时可以直接丢弃这些极端样本,但多数情况下它们携带了真实的信息不能直接删除。
应对这些问题的常用方法有四种:标准化(Standardization)、Robust缩放(Robust Scaler)、幂变换(Power Transformer)、归一化(Normalization)。
下面用 scikit-learn 内置的 California 住房数据集来逐一演示。选取"Median Income"和"Population"两个量级差异明显的特征:
dataset = fetch_california_housing()
X_full, y_full = dataset.data, dataset.target
feature_names = dataset.feature_names
df = pd.DataFrame({
"MedInc": X[:, 0],
"Population": X[:, 4],
})
df.describe()
+---------+------------+-------------+
| Metric | MedInc | Population |
+---------+------------+-------------+
| count | 20640 | 20649 |
| mean | 3.870671 | 1425.476744 |
| std | 1.899822 | 1132.462122 |
| min | 0.499900 | 3 |
| 25% | 2.5634 | 787 |
| 50% | 3.5348 | 1166 |
| 75% | 4.743250 | 1725 |
| max | 15.0001 | 35682 |
+---------+------------+-------------+
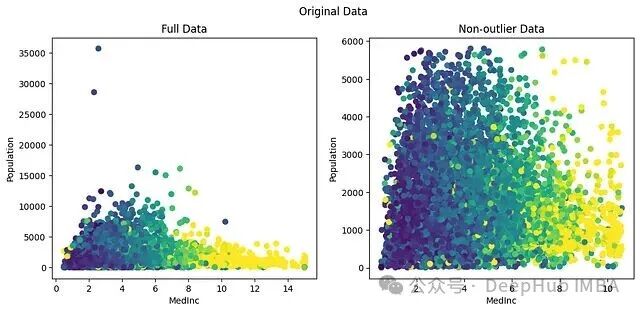
先看未经任何缩放或变换的原始数据,分别展示包含异常值和去除异常值(第 0-99 百分位)后的散点图:
X = X_full[:, [0,4]]
outlier_range = (0, 99)
cutoffs_median_inc = np.percentile(X[:, 0], outlier_range)
cutoffs_population = np.percentile(X[:, 1], outlier_range)
non_outliers = np.all(X > [cutoffs_median_inc[0], cutoffs_population[0]], axis=1) & np.all(
X < [cutoffs_median_inc[1], cutoffs_population[1]], axis=1
)
non_outlier_X = X[non_outliers]
non_outliers_Y = y_full[non_outliers]
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
fig.suptitle('Original Data')
ax1.set_title('Full Data')
ax1.scatter(X[:, 0], X[:, 1], c=y_full)
ax1.set_xlabel('MedInc')
ax1.set_ylabel('Population')
ax2.set_title('Non-outlier Data')
ax2.scatter(non_outlier_X[:, 0], non_outlier_X[:, 1], c=non_outliers_Y)
ax2.set_xlabel('MedInc')
ax2.set_ylabel('Population')
plt.show()
接下来逐一看看上述四种技术分别如何变换数据。
标准化(Standardization)
标准化把数值特征变换到零均值、单位方差的尺度上。
年龄相差 10收入相差 50k,这对模型来说,收入的信号远比年龄"响亮"得多。将所有特征标准化为均值 0、方差 1 后,不同特征的数值就落到了同一个可比较的区间内。
z 分数的计算公式:
z = ( x — mean ) / standard_deviation.
标准化后的特征和那些对输入分布有正态假设的算法契合度较高,线性回归、逻辑回归、支持向量机、PCA 等降维方法都属于这一类。
Scikit-learn 中对应的实现是 StandardScaler:
standard_scaler = StandardScaler()
standardized_x = standard_scaler.fit_transform(X)
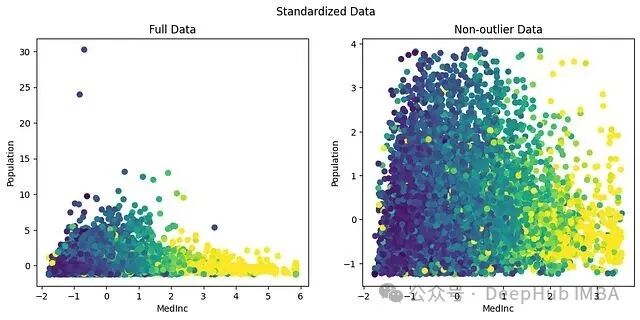
原始数据中 Population 的范围在 0 到 35k,MedInc 在 0 到 14。标准化后二者分别缩放到 [0,35] 和 [-2,6],量级上已经可比。
不过标准化有一个明显的弱点:它对异常值极其敏感。从上图可以看出,最大值虽然从 35k 缩放到了 30 左右,但异常值的存在拉高了均值,导致大部分数据被挤压到 [-1,4] 的狭窄区间里。换句话说,标准化只改变数值的尺度,不改变分布的形状,数据原本偏斜,标准化之后依然偏斜。
两个特征的主体数据确实落到了可比较的范围:MedInc 在 [-2,4],Population 在 [-1,4]。
Robust 缩放(Robust Scaler)
RobustScaler 是标准化的一个变体,核心区别在于它用中位数和四分位距(IQR,通常取第 25 到第 75 百分位)代替了均值和标准差。标准化在面对极端异常值时会被"带偏"——均值被拉高,方差被放大,缩放效果大打折扣。而 IQR 只关注中间 50% 的数据,少数极端值对它几乎没有影响。
异常值本身并不会被移除,特征中依然保留着那些极端样本,但特征的主体数据会落在一个更合理的区间内。
roubust_scaler = RobustScaler(quantile_range=(25.0,75.0),
with_scaling=True, with_centering=True, unit_variance=True)
robust_x = roubust_scaler.fit_transform(X)
默认分位数范围 (25,75) 意味着两端各忽略 25% 的极端数据,这正是"鲁棒"一词的来源。
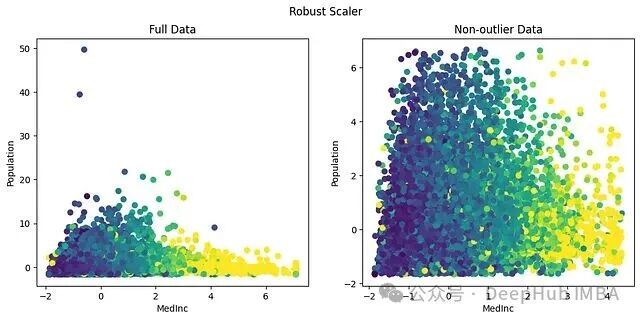
从图中可以看到,两个特征的主体数据落在了相近的区间:MedInc 在 [-2,5],Population 在 [-2,6]。
StandardScaler 和 RobustScaler 都能把特征拉到可比较的尺度上,但都无法根本性地消除异常值带来的分布偏斜。要解决这个问题,需要引入非线性变换——对数变换、幂变换、分位数变换都属于此类。
幂变换(Power Transformer)
收入、房价这类现实世界的数据有一个共同特点:大量值集中在较低区间,同时存在少数极大的异常值。线性回归或逻辑回归试图找到一条到所有数据点距离最小的拟合线,一个极端异常值就像跷跷板一端的重物,足以把整条线拽偏,破坏对其余样本的拟合。
神经网络虽然对数据形态的容忍度更高,但单个极端值在某一训练步中带来的梯度冲击,叠加上相对较大的学习率,同样可能引发损失曲面上的剧烈震荡。
PowerTransformer 的做法是压缩分布的长尾,将异常值拉近数据主体,从而把偏斜分布整形为接近钟形曲线的形状。异常值的信息得以保留,但它们不再以极端的数值扭曲模型。Scikit-learn 中除了 PowerTransformer,QuantileTransformer 也能达到类似效果。
先用箱线图直观感受一下 Population 特征的长尾:
plt.figure(figsize=(12, 4))
sns.boxplot(x=df['Population'], color='skyblue')
plt.title('Box Plot of Population (Visualizing Outliers)')
plt.xlabel('Population Value')
plt.axvline(1425, color='orange', linestyle='--', label='Mean: 1425')
plt.legend()
plt.show()
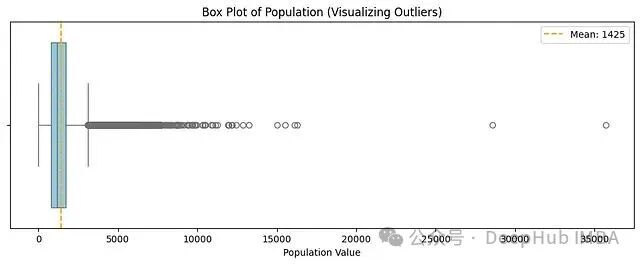
箱体对应的是数据主体(四分位距范围),右侧那一长串散点就是可能"掀翻跷跷板"的极端 Population 值。
对 Population 应用 PowerTransformer:
from sklearn.preprocessing import PowerTransformer
pt = PowerTransformer(method='yeo-johnson')
pt_transformed = pt.fit_transform(X[:,[1]])
绘制变换前后的直方图对比:
import matplotlib.pyplot as plt
import seaborn as sns
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
sns.histplot(standardized_x[:,1], ax=ax1)
ax1.set_title("Before: Standardized Population (Skewed)")
ax1.set_xlabel("Value")
sns.histplot(pt_transformed[:,0], ax=ax2)
ax2.set_title("After: PowerTransformed Population (Normal-like)")
ax2.set_xlabel("Transformed Value")
plt.tight_layout()
plt.show()
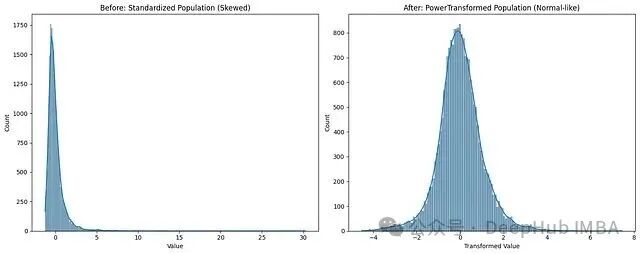
效果非常明显,PowerTransformer 把原本右偏的分布变换成了接近正态的形状。
再看变换前后的箱线图:标准化后的数据主体仍然偏左,长尾向右延伸;PowerTransformer 处理后,箱体居中,两侧须线基本对称。
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
sns.boxplot(x=standardized_x[:,1], ax=ax1)
ax1.set_title('Standardized Population\n(Scale changed, outliers remain)', fontsize=13)
ax1.set_xlabel('Z-Score')
sns.boxplot(x=pt_transformed[:,0], ax=ax2)
ax2.set_title('PowerTransformed Population\n(Shape changed uniform tails)', fontsize=13)
ax2.set_xlabel('Transformed Value')
plt.tight_layout()
plt.show()
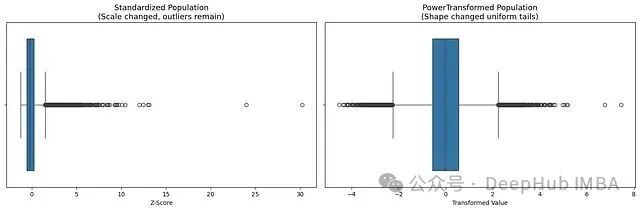
左图(标准化)中数值分布跨度很大。线性回归一旦在异常值上产生错误预测,平方误差会被放大到一个极端的量级,拟合线被迫朝异常值方向偏移,整体拟合质量随之下降。右图(幂变换)中异常值与主体数据的距离被大幅缩短,误差分布更加均匀,模型可以把注意力放在数据的主体上。
对比标准化后的 MedianInc 和经过 PowerTransformer 处理的 Population:
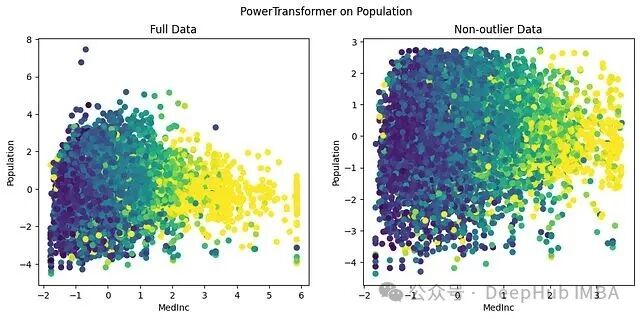
与标准化不同,异常值被拉入了数据主体的邻域。数据分布均匀,没有被压缩到一个狭窄的区间里。在 MedianInc 最高的第 6 档中,Population 的取值分散在 [-4, 2] 之间,模型能够捕捉到这些细微的差异并发现特征间的关联。
归一化(Normalization)
归一化将所有数据重新缩放到 0-1 的范围内。KNN 等基于距离的算法对数值的绝对大小敏感,归一化对这类算法尤为重要。
在神经网络中,归一化还能缓解梯度消失问题。较大的输入值(比如年龄为 99)容易让激活函数进入饱和区,梯度趋近于零,权重不再更新,学习就此停滞。将输入缩放到 0-1 之间,恰好落在多数激活函数的敏感区域内。
最常用的归一化方法是 Min-Max 缩放,公式为:
x_norm = (x — x_min) / (x_max — xmin).
Min-Max 缩放有一个致命的弱点:一旦出现一个极端异常值——比方说某人收入为 10 亿美元——它会被映射为 1,其余所有正常值全部被压缩到接近 0 的微小区间里,数据中的细微差异被彻底抹平。
看看归一化对当前数据集的实际效果:
min_max_scaler = MinMaxScaler()
nomralize_x = min_max_scaler.fit_transform(X)
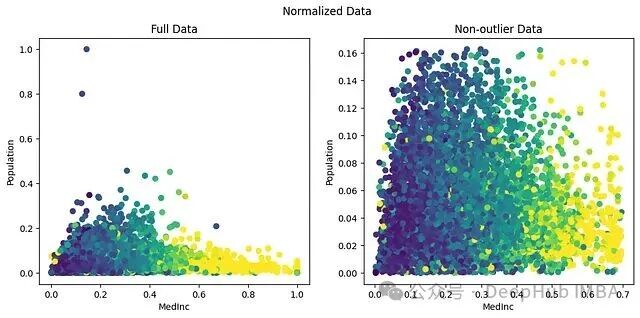
Min-Max 缩放把 Population 的最大值映射为 1.0,而几乎全部数据都被挤压到了 0-0.16 的区间内。回顾前面的箱线图——Population 最大值达到 35k,数据主体集中在 1000-2000 之间。35k 被映射为 1 后,1000-2000 这个区间只能占据 1/35 的宽度,有意义的分辨率荡然无存。
归一化最适合的场景是输入特征的边界已知且固定,典型的例子是 RGB 图像的像素值——取值范围恒定在 0-255。
以下表格汇总了四种缩放器的适用场景:
.----------------------.---------------------------.-------------------------------------------------------.
| Issue | Best Tool | Why? |
:----------------------+---------------------------+-------------------------------------------------------:
| Different Scales | StandardScaler | Makes features comparable. |
:----------------------+---------------------------+-------------------------------------------------------:
| Heavy Skew | Power/QuantileTransformer | Normalizes the distribution shape. |
:----------------------+---------------------------+-------------------------------------------------------:
| Extreme Outliers | RobustScaler | Uses Median and IQR, unaffected by marginal outliers. |
:----------------------+---------------------------+-------------------------------------------------------:
| Neural Network Input | Min-Max Scaler | Matches the "expected" range of neurons. |
'----------------------'---------------------------'-------------------------------------------------------'
使用这些缩放器时有一条铁律:fit() 只在训练数据上调用。
.fit():计算统计量(均值、标准差等),只能在训练集上执行。
.transform():用已有的统计量做变换,训练集、测试集、线上数据都要执行。
如果在测试集上调用了 fit,等于模型提前"看到"了测试数据的分布——这就是数据泄露。部署模型时,缩放器的参数也必须一起打包上线。
by Aparna Suresh
