PoundNet重新审视AI图像检测范式,兼顾泛化与知识保留。通过可学习提示和平衡目标函数,提升模型在未见数据上的检测能力。
原文标题:TPAMI 2026 | 跨十大数据集验证,PoundNet重新审视AI图像检测范式
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到现有方法容易对下游任务过度拟合,导致对未知AI生成器泛化能力下降。在你的研究或工作中,是否遇到过类似的情况?你是如何解决的?
3、PoundNet 使用 CLIP 模型作为基础,并进行微调。你认为选择 CLIP 的原因是什么?如果替换成其他预训练模型,例如 Stable Diffusion,效果会如何?
原文内容

本文约2000字,建议阅读5分钟兼顾泛化与知识保留的AI 图像检测。
随着 AI 生成图像技术快速演进,伪造内容在网络传播风险持续上升,高鲁棒性检测技术因此成为学界与产业界关注的关键问题。
然而,现有不少方法过于追求单一数据集上的短期收益,往往仅围绕“真/假”二分类目标对大规模预训练模型进行专门化微调。
这类做法虽然能够提升局部基准上的检测精度,却容易破坏模型原有的广泛语义知识,从而削弱其对未见生成器、未见数据域的泛化能力。
针对这一“贪小利而失大局”的问题,哈工大与南安普顿大学联合提出 PoundNet 框架,从“检测泛化”与“知识保留”双重目标出发,重新审视 AI 生成图像检测的训练范式。

论文标题:Penny-Wise and Pound-Foolish in AI-Generated Image Detection
论文链接:https://arxiv.org/abs/2408.08412
代码链接:https://github.com/iamwangyabin/PoundNet
当模型学会“抓假”,却忘了“看懂世界”
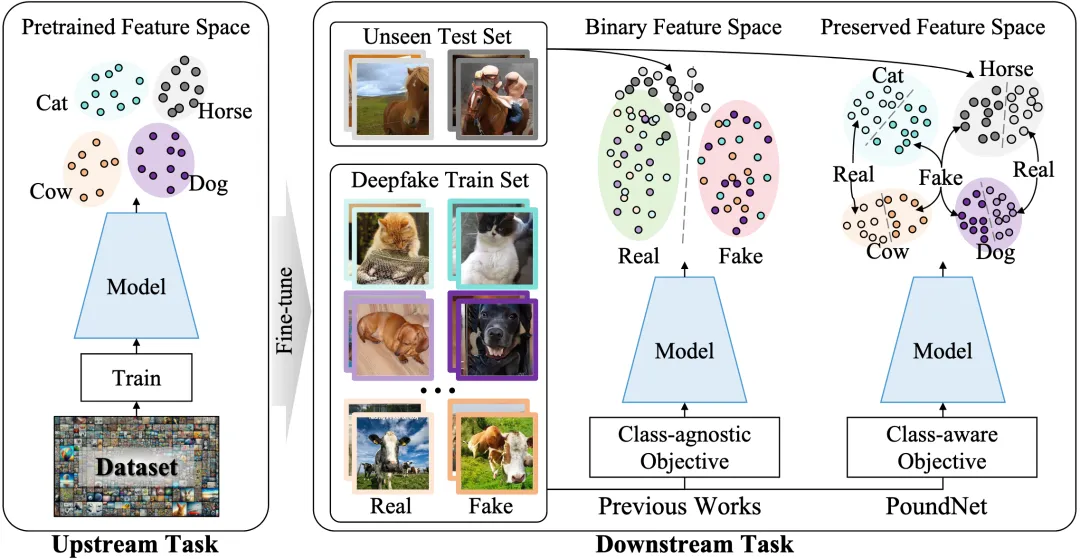
为了应对层出不穷的AI生成图像,目前的主流做法是利用预训练的大模型(如CLIP),并在特定的伪造数据集上使用“类别无关的二分类目标”进行微调。
然而,我们发现这是一种典型的“短视”策略(Penny-Wise):模型虽然在训练见过的伪造类型上得分很高,但却灾难性地遗忘了预训练模型中宝贵的广泛语义知识。
这种对下游任务的过度拟合,直接导致了模型对未知AI生成器泛化能力的大幅下降(Pound-Foolish)。
简而言之,模型为了学会“抓假”,反而连“画里是什么”都认不出了。
为此,我们提出了一种抗“因小失大”的学习框架 PoundNet。我们没有简单粗暴地进行二分类微调,而是基于 CLIP 设计了一套可学习的提示和平衡目标函数。
PoundNet 不仅要求模型学会区分真假,还强制模型在微调过程中保留对物体类别的分类能力,并在每个特定类别的上下文中进行真假判别。
PoundNet框架:一边“抓假”,一边“守住认知”
所提出的方法 PoundNet 旨在在实现类别感知的 AI 生成图像检测的同时,平衡泛化能力与知识保持能力,以更好地应对未见过的 AI 生成器。
PoundNet 基于 CLIP 构建,并通过我们设计的提示对(prompt pair)和提出的平衡目标函数对其进行微调。
理想情况下,我们可以使用如下提示格式:“a [real/fake] photo of a [CLASS]”,来引导 CLIP 模型完成下游的二分类 AI 图像检测任务。
然而,对于预训练的 CLIP 来说,理解“deepfake”这一抽象概念在自然语言中是具有挑战性的。
为了更好地对“a [real/fake] photo”这一上下文在 AI 生成图像检测场景中进行参数化,我们分别为真实和伪造图像引入了可学习的成对提示(下图左上)。
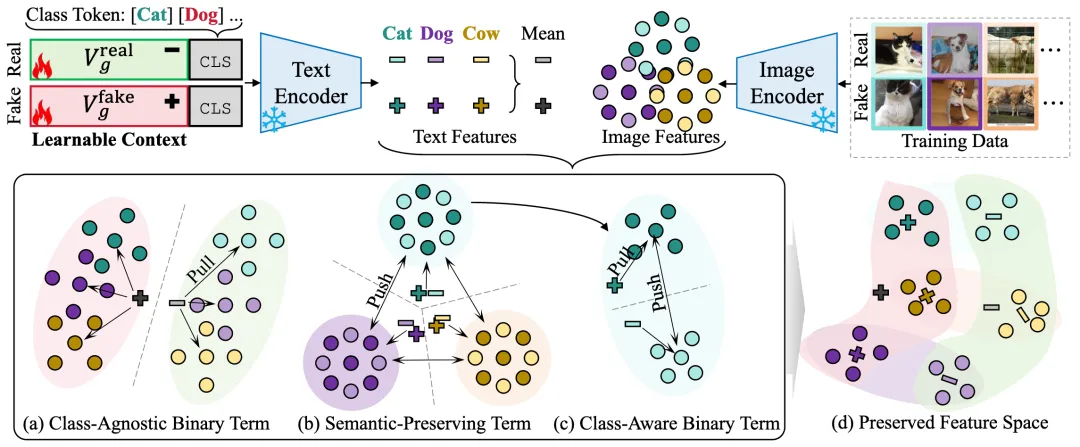
类别无关的二分类项(Class-Agnostic Binary term)(图(a)):该项对应一种高层次、抽象的概念,侧重于在不考虑具体语义类别的情况下区分真实与伪造样本,即进行通用的真假二分类。
语义保持项(Semantic-Preserving term)(图(b)):该项用于保留预训练模型中蕴含的广泛语义知识,而这一点往往被现有方法忽略,因为它们通常只依赖类别无关的二分类项进行过度微调。
类别感知的二分类项(Class-Aware Binary term)(图(c)):该项旨在区分不同类别内部的真实与伪造样本(例如,在猫的图像中检测伪造的猫图像),从而使 AI 生成图像检测更加精细和有效。
实验结果:跨10大数据集全面领先,泛化能力显著提升
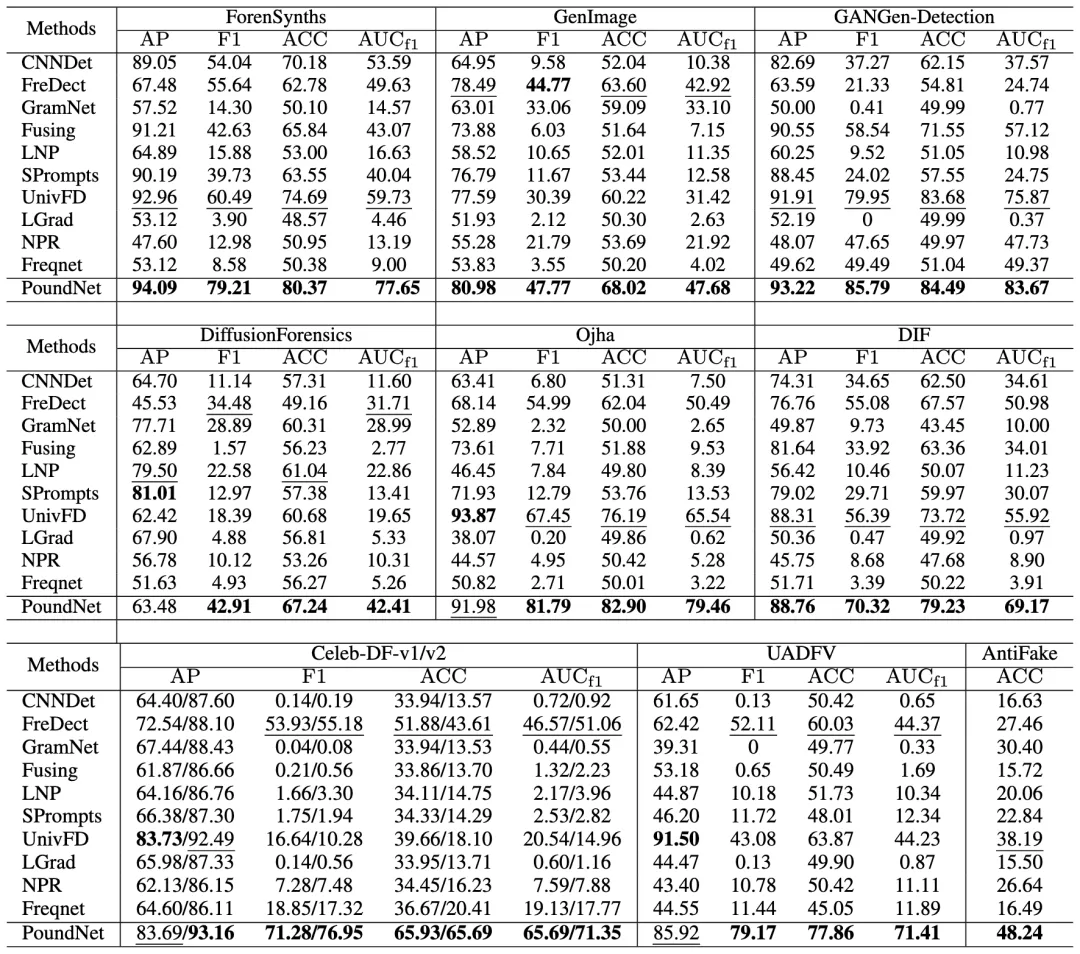
团队遵循领域内常见设定,仅使用单一标准 AI 图像数据集进行训练,随后在 10 个大规模公开AI生成图像检测数据集上、基于 5 项主要评测指标进行了系统测试,构建了当时规模最大的 AI 生成图像检测泛化评测集合之一。
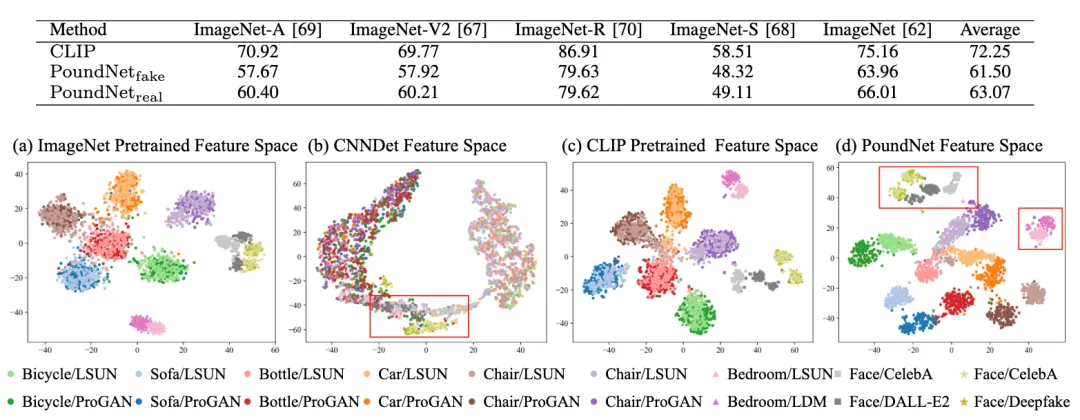
实验结果表明,PoundNet 相比现有先进方法实现了 19% 的相对性能提升。
同时,在目标分类任务上,PoundNet 仍保持 63% 的较强表现,体现出其在 跨域泛化、知识保持与检测鲁棒性 方面的综合优势。