斯坦福等提出SSD框架,并行化草拟和验证,突破大模型推理瓶颈,速度提升2倍!
原文标题:比全球最强推理引擎还快2倍,斯坦福、普林斯顿破解大模型「串行魔咒」
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到SSD可以和EAGLE技术以及token-tree推测结合,这两种技术分别是什么? 结合后能带来哪些好处?
3、文章提到,通过扩展草拟设备的数量以及推测缓存,延迟可以进一步减少。那么,仅仅通过增加更多的GPU来做推测,是不是就能无限提升性能? 瓶颈会在哪里?
原文内容
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。
近日,来自斯坦福、普林斯顿大学和 Together AI 的研究团队提出 SSD 框架及其优化算法 SAGUARO,成功实现了草拟和验证的并行化。

-
论文链接:https://arxiv.org/pdf/2603.03251
-
GitHub 链接:https://github.com/tanishqkumar/ssd
据介绍,该算法推理速度比世界上最强大的推理引擎都快 2 倍。
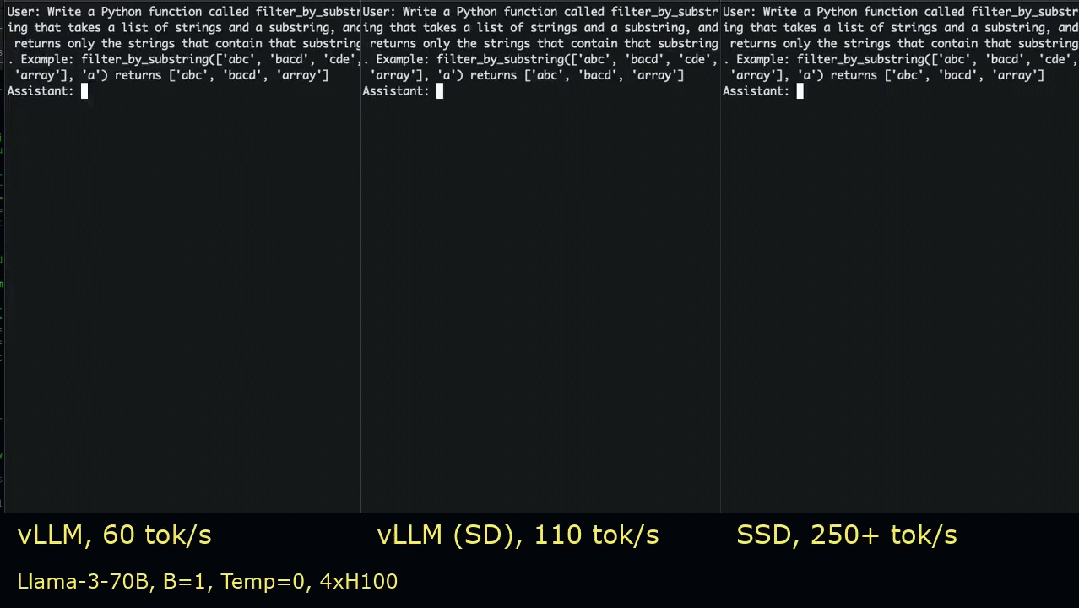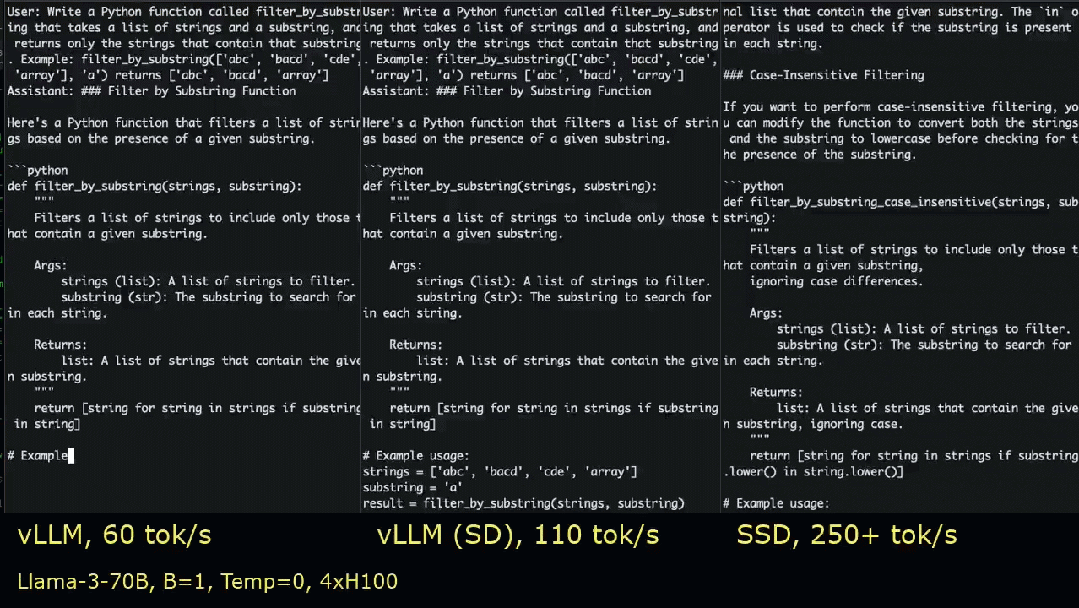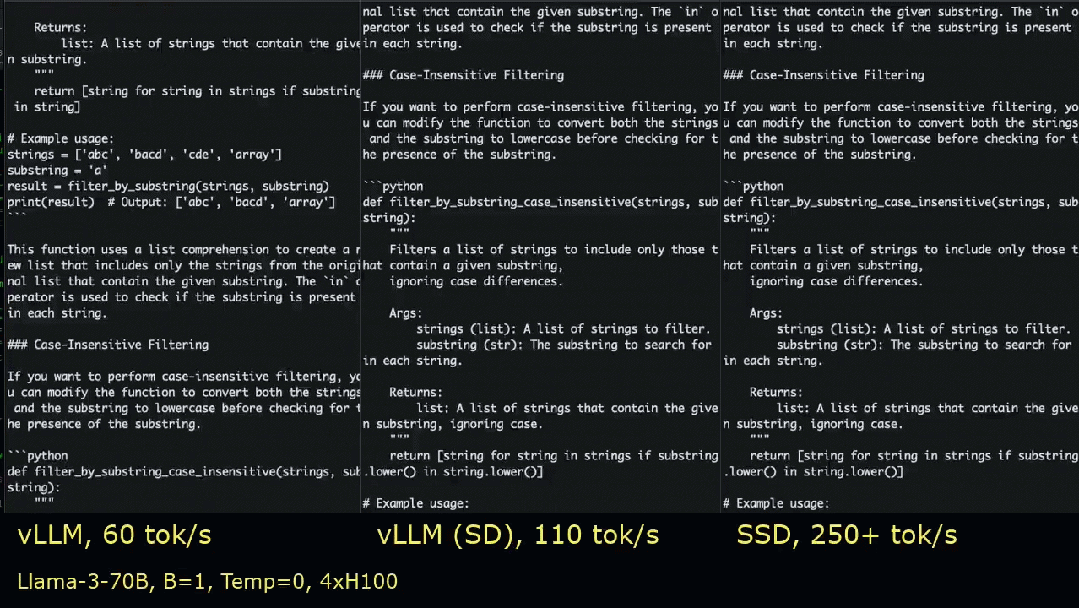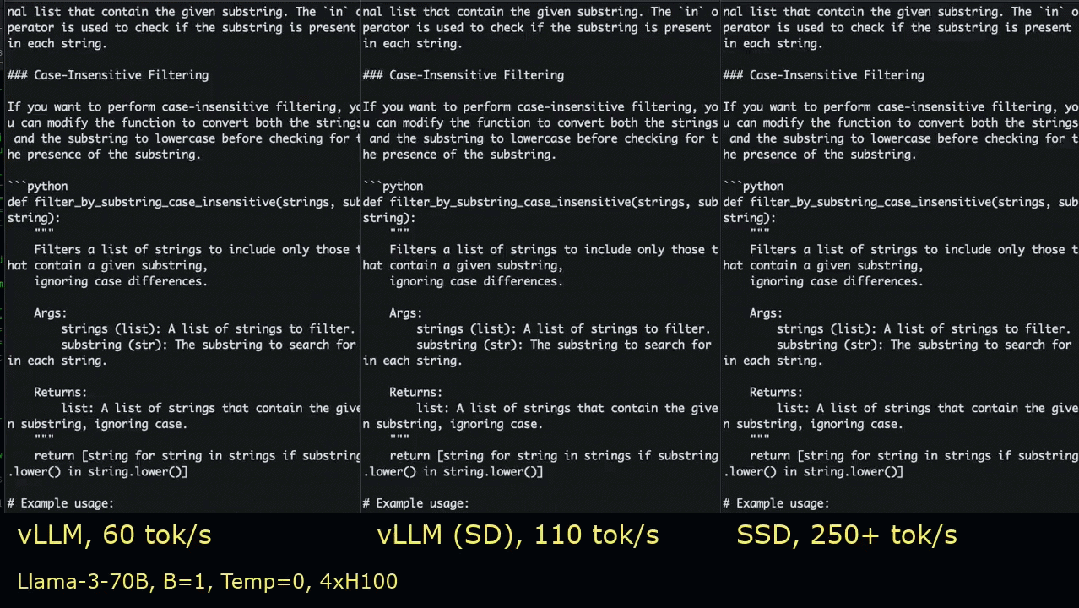
「推测性推测解码」(Speculative Speculative Decoding,简称 SSD),是一种新型的推测性解码 (SD)。在传统的 SD 中,一个小且快速的模型会先猜测大且慢的模型可能生成的下几个 token,然后大模型通过一次前向传播验证这些猜测,草拟和验证是依次进行的。
而在 SSD 中,这两个过程是并行发生的,完全消除了运行小模型的开销。
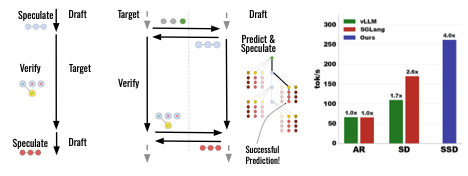
并行执行草拟和验证是很棘手的,因为你无法在某事物存在之前对其进行验证,也无法推测你不知道的前缀之外的内容。在 SSD 中,研究者预先设定验证结果,并在独立硬件上进行验证的同时进行推测。这样一来,如果其中一种验证结果出现,推测就能立即生效。
虽然论文对算法进行了详尽的理论描述,但在实践中,研究者大部分时间都花在如何让它与现代推理引擎中各种优化技术(Paged Attention、Prefix Caching、CUDAGraphs 等)协同工作上。
作者 Tanishq Kumar 表示,「真的,我花在了解 CPU/GPU 同步问题上的时间远远超过了我的预期」。

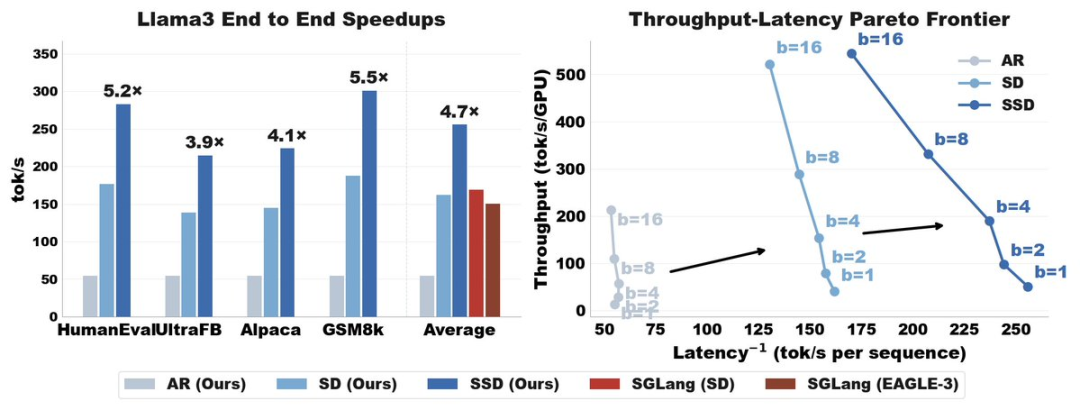
要使新算法达到 SOTA 水平,需要精心设计系统和算法。总的来说,SSD 推动了延迟 - 吞吐量帕累托前沿的发展,其方式与普通推测解码推进标准自回归算法的发展非常相似。
Tanishq Kumar 称:「我对快速推理感到兴奋,因为我非常关注的一个人工智能工作负载是超长时域推理。想象一下,一个拥有大量 B200 的数据中心完全用于运行一个模型,该模型需要处理数十亿个 token 来证明 P 与 NP 的区别。在这种情况下,延迟减半就意味着可以进行双倍深度的思考!」

SSD 如何实现草拟与验证并行?
现代 AI 对推理速度有着极高的要求。然而,标准的语言模型解码是按顺序生成单个 token,未能利用现代硬件上可用的大规模并行计算。
推测性解码(SD)是一种为了解决这个问题而引入的技术。它使用一个快速的「草拟模型」来预测目标模型可能将生成的下几个 token,而不是从目标模型中进行缓慢的自回归采样,然后通过目标模型的并行前向传播验证这些 token。这一验证是按照一个算法进行的,确保生成的 token 是从目标模型的分布中采样的。
在每次验证中,目标模型决定接受多少个推测的 token,并采样一个额外的奖励 token,该 token 跟随所有已接受的 token。尽管推测性解码有效,但它本身仍受限于串行依赖:必须等待当前验证完成后,才能开始下一轮推测。
那么,我们能否消除草拟和验证之间的顺序依赖呢?
研究者引入推测性推测解码(SSD),这是一个旨在并行化草拟和验证的统一框架。
在 SD 中,草拟模型必须等待验证完成,才能开始推测下一轮,而在 SSD 中,草拟模型会预测最可能的验证结果,并在验证进行的同时,针对所有可能的结果进行并行的提前推测。如果这些预准备的结果中的任何一个发生,草拟模型可以立即将预推测的 token 发送给验证器,从而避免草拟阶段的开销。与普通的推测性解码一样,SSD 也是无损的。不同之处在于,SSD 的草拟模型部署在与目标模型不同的硬件上。
优化 SSD 算法主要面临三大挑战。
首先,草拟模型必须准确预测验证结果,这不仅包括接受了多少个推测的 Token,还包括采样的奖励 token。其次,推测器的接受率与其预测验证结果的能力之间存在微妙的权衡,必须谨慎处理以最大化加速比。此外,任何 SSD 算法都必须具备处理预测失败的回退策略,因为在大批处理量和高随机性(Temperature)下,预测失败会频繁发生,若处理不当,即时补救的开销将抵消异步带来的收益。
为此,他们推出了 Saguaro,这是一个优化的 SSD 算法,针对上述挑战进行了定向优化。
-
将预测验证结果的问题转化为约束优化问题,并引入了一种技术,利用最可能的草拟 logits 来预测奖励 token,准确率最高可达 90%。
-
识别了预测准确性与生成高质量推测之间的张力,并开发了一种能够平衡二者的采样算法。
-
探讨了处理预测失败的多种策略,发现最优回退策略随批处理大小而异。通过采用这些优化,尽管 Saguaro 在处理每个批次元素时进行了更多计算(同时解码多种可能的结果),其表现仍比标准 SD 高出 20%。
总的来看,Saguaro 相比优化的推测性解码实现了高达 2 倍的加速,相比自回归生成实现了高达 5 倍的加速,并在各种批处理规模下均显著提升了吞吐量与延迟的帕累托前沿。
不过,该领域仍有许多值得探索的方向。SSD 可以自然地与 EAGLE 技术以及 token-tree 推测(Token-tree speculation)相结合,但这种联合设计及其权衡空间在很大程度上尚未被发掘。
此外,通过扩展草拟设备的数量以及推测缓存,延迟可以进一步减少,尽管回报最终会递减。最后,在集群层面跨多个目标模型部署共享推测端点——类似于预填充-解码分解)——是另一个自然的研究方向。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com