DVDF为跨域离线强化学习引入“动力学+价值”双重对齐,显著提升迁移效果。
原文标题:重构跨域RL框架!理论驱动「双重对齐」让跨域迁移「质变」
原文作者:机器之心
冷月清谈:
论文从理论上重构了跨域离线强化学习的分析目标,不再只盯着源域和目标域之间的性能偏差,而是直接分析目标域策略学习的次优性上界。由此得出结论:有效迁移不仅要考虑动力学对齐,还要考虑价值对齐,也就是源域数据是否真正包含有助于学习好策略的有效信号。
基于这一结论,作者提出DVDF框架,通过“双重对齐”过滤源域数据:一方面利用现有方法衡量动力学对齐程度;另一方面通过在源域上预训练离线RL模型,估计样本优势函数,用来评估数据价值。论文还比较了IQL和SQL作为预训练方法的效果,发现SQL能给出更准确的优势估计,从而提升过滤质量。
实验覆盖hopper、walker2d、halfcheetah、ant等多个控制任务,并设置关节偏移和形体偏移两类跨域场景。结果显示,DVDF作为插件接入IGDF、OTDF等方法后,在大多数任务上都带来稳定提升,说明“既像又值”的数据筛选思路比单纯看动力学更有效。
怜星夜思:
2、问题2:DVDF强调“价值对齐”,这是不是意味着以后跨域迁移里,数据质量会比动力学一致性更重要?
3、问题3:论文里用SQL而不是IQL来预训练优势函数,你觉得这说明离线RL里的“价值估计偏差”已经成了更核心的问题吗?
4、问题4:DVDF这种“先打分再过滤”的思路,能不能推广到机器人、自动驾驶之外的其他领域?
原文内容

本文作者来自香港城市大学、伊利诺伊大学厄巴纳 - 香槟分校、腾讯、中国电信人工智能研究院、清华大学等机构。作者包括乔钟健、杨瑞、吕加飞、白辰甲、李秀、高思阳、邱爽。其中,第一作者为香港城市大学乔钟健,通讯作者为香港城市大学邱爽。

-
论文标题:Efficient Cross-Domain Offline Reinforcement Learning with Dynamics- and Value-Aligned Data Filtering
-
文章链接:https://arxiv.org/pdf/2512.02435
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。因此,离线强化学习(offline RL)通过直接利用历史静态数据进行策略学习,规避了持续在线交互需求,为在高成本、高风险场景中应用强化学习提供了更可行的路径,成为推动强化学习走向真实世界的关键方向。
然而,当目标环境数据稀缺时(例如,新部署的机器人仅拥有少量演示数据),仅凭目标域数据难以支撑高性能策略的学习。这一困境催生了跨域离线强化学习(Cross-Domain Offline RL)这一范式 —— 它致力于借助源域(如动力学存在差异但数据丰富的仿真环境)中的知识,弥补目标域数据不足,为数据匮乏的目标域注入学习动能,促进目标域完成策略学习。
虽然跨领域离线强化学习的出发点很好,但源域与目标域之间往往存在动力学偏移(Dynamics Misalignment),即状态转移动力学规律不一致。在这种情况下,直接合并源域和目标域数据进行训练会引发严重的分布外动力学 (OOD Dynamics)问题:模型学习到的转移规律难以在目标域成立,因而性能往往会迅速退化,最终令训练崩溃。 目前解决这一问题的主流范式是动力学对齐驱动的数据过滤:首先通过对比学习或最优传输等方式度量源域样本和目标域的动力学偏移程度,然后过滤掉部分动力学明显不一致的源域数据,只保留那些动力学行为更接近目标域的样本参与训练。
然而,这一范式在逻辑上依赖于一个极强的隐藏假设:动力学相似性足以刻画源域数据的可迁移性,只要源域样本在转移动力学上与目标域的 “足够接近”,源域数据便一定值得保留并用于训练。但这一假设忽略了源域数据的另一项关键属性 —— 数据质量。在现实问题中,源域不仅仅与目标域存在动力学偏移,更重要的是源域数据所含学习信号也未必同等有效,进而影响其对目标域策略学习的实际贡献。如果一组源域数据在动力学上与目标域完全一致,却是从环境中随机收集的低质量数据,它对学习目标域策略的贡献真的大吗?
研究动机:动力学对齐真的充分吗?
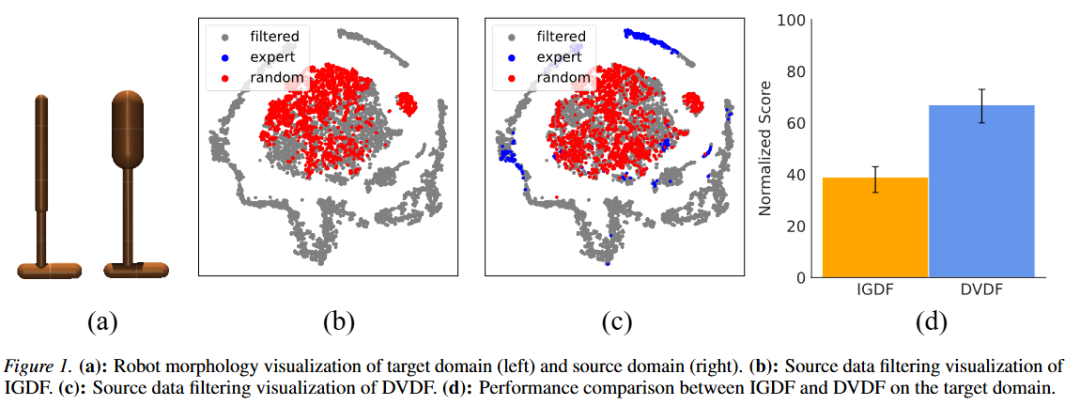
为了探究上述问题,作者们设计了一个启发性实验:在 Hopper 机器人控制任务中,源域数据由两种类别构成:动力学对齐,但低质量的随机样本;以及存在动力学偏差,但高质量的专家样本。按照现有的 IGDF 等方法,由于专家样本存在动力学偏差,它们会被立刻过滤掉,最终只会保留随机样本进行策略训练。然而,随机样本对策略性能的提升是相当有限的,这导致最终策略仅仅收敛到次优性能。这表明,低质量源域数据提供的有效信息较少,进而削弱其对目标域策略学习的贡献。
针对现有方法所存在的问题,论文首先从理论层面定位了其根源所在:现有跨域离线强化学习的主流分析框架与其真正的学习目标并不匹配。这一错位直接导致现有方法只聚焦于动力学对齐,系统性忽视了源域数据质量。为此,论文进一步重构理论框架,通过直接推导目标域策略学习的次优性差距(sub-optimality gap)上界,从理论上明确:高效的跨域离线强化学习必须兼顾动力学偏移与价值偏差。在该理论结论驱动下,论文提出 DVDF 方法:设计统一的数据过滤框架同时实现源域样本的动力学对齐与价值对齐,选择 “既像又值” 的源域数据用于训练。DVDF 可作为插件(plug-in)模块无缝集成到现有的方法中(如 IGDF、OTDF 等),并带来稳定的性能提升。
理论重构:修正跨域离线强化学习的优化目标
文章对现有的跨域离线强化学习的理论框架进行了重新审视。作者指出,以往的研究大多依赖于分析并优化以下源域 与目标域 的性能偏差界限:
其中 为常数。由上式可见,对任意的策略 , 该性能偏差 仅由源域状态转移模型 和目标域状态转移模型 之间的动力学偏移项 直接控制。想要保证目标 尽量小,优先选择动力学对齐的样本是该理论推导的自然结果。
然而,文章指出,上述优化目标和跨域强化学习的根本目标 —— 最大化策略在目标域的性能 —— 并不一致,因此优化这一性能界限并不能保证充分有效的策略迁移。基于该观点,文章重构了跨域强化学习的理论分析,提出直接优化策略在目标域 上的价值的次优界,即
,
其中 为目标域最优策略, 代表通过特定的源域数据学习所得的策略。这样的优化目标直接和强化学习的目标对齐,能够训练出更加有效的迁移策略。文章中进一步推导出了这样的次优界的上界,并引出价值对齐 (Value Alignment) 的概念:
其中, 为常数, 为源域样 本内最优策略 与源域最优策略 的价值函数差异,可视为常数的统计误差。上述的理论结果显示 主要是由动力学偏移 和价值偏移 来共同控制,从而揭示了一个新的结论:有效的策略迁移不仅需要关注动力学是否对齐,还需要关注价值是否对齐,即源域数据是否是高质量数据。数据质量则是通过在数据上所学策略 与源域样本内最优策略 所对应价值是否足够对齐来体现。而现有研究普遍忽略了价值对齐这一关键因素,这也为其性能次优提供了合理解释。
动力学和价值双对齐的数据过滤框架
基于以上分析,我们需要同时度量价值对齐和动力学对齐程度。对于动力学对齐,我们可采用现有工作中成熟的方案,如对比学习和最优传输等。文章需要解决的关键问题在于价值对齐程度的度量。为了解决这个问题,文章首先推导出了价值对齐项的上界:
其中, 为源域数据采样的行为策略。由上式可见,价值偏移项被源域样本内最优策略 所对应的优势函数 所控制,这启发我们可以使用源域数据上样本内最优策略的优势函数进行价值对齐的评估。然而在现实中,我们无法直接获得这样的优势函数。针对这一挑战,文章提出可使用特定的离线强化学习算法在源域数据上进行预训练,得到一个预训练策略 以估计样本内最优策略 ,预训练后得到的估计的 Q 函数 和价值函数 ,并估计策略 下的优势函数:
值得注意的是,预训练得到的优势函数的近似误差不可忽视。为了进一步降低近似误差的影响,文章首先推导出了优势近似误差的具体形式:
其中 , 。这里 是预训练策略 的真实优势函数(理论上存在但不可知),而 衡量的是估计值与真实值之间的差距。这一结果说明,想要最小化优势近似误差,我们选择的离线强化学习需要满足以下两个条件:(1) 优秀的性能,以最小化 ; (2) 准确的优势估计,以最小化 。IQL 作为一个常用的离线强化学习算法,具有优势估计简单以及性能卓越的优势。
然而,IQL 学习价值函数时,易受数据集中次优动作的影响,导致价值函数常被低估,从而导致优势函数被高估。进一步,为了解决该问题,我们选用了 Sparse Q-learning (SQL) 算法进行预训练。SQL 通过在价值函数训练中显式引入稀疏性,从而降低了次优动作对价值估计的影响,能够估计出更准确的优势函数。
在使用 SQL 算法在源域数据上进行预训练得到优势函数之后,文章提出动力学和价值双对齐的数据过滤算法框架 DVDF (Dynamics- and Value-aligned Data Filtering)。该框架的核心在于定义了一个重要的评分函数 用来过滤源域样本:
其中函数 是通过对比学习或最优传输得到的评估动力学对齐的得分函数, 是优势函数估计值以体现价值对齐程度, 是最小 - 最大归一化算子。由此可见,评分函数 同时考虑了动力学对齐和价值对齐,并且通过一个可调整的超参数 来平衡动力学对齐和价值对齐在源数据过滤的重要性。文章根据得分函数 来选择更好的源域样本,并通过最小化 训练得到 Q 函数:
其中, 为指示函数,用于过滤出给定比例的源域样本, 表示样本对应的 数值的第 分位数。对于策略优化,该方法利用学好的 Q 函数,通过标准的 IQL 算法进行训练得到最终的输出策略。
实验验证
1. 动力学偏移场景下的性能对比
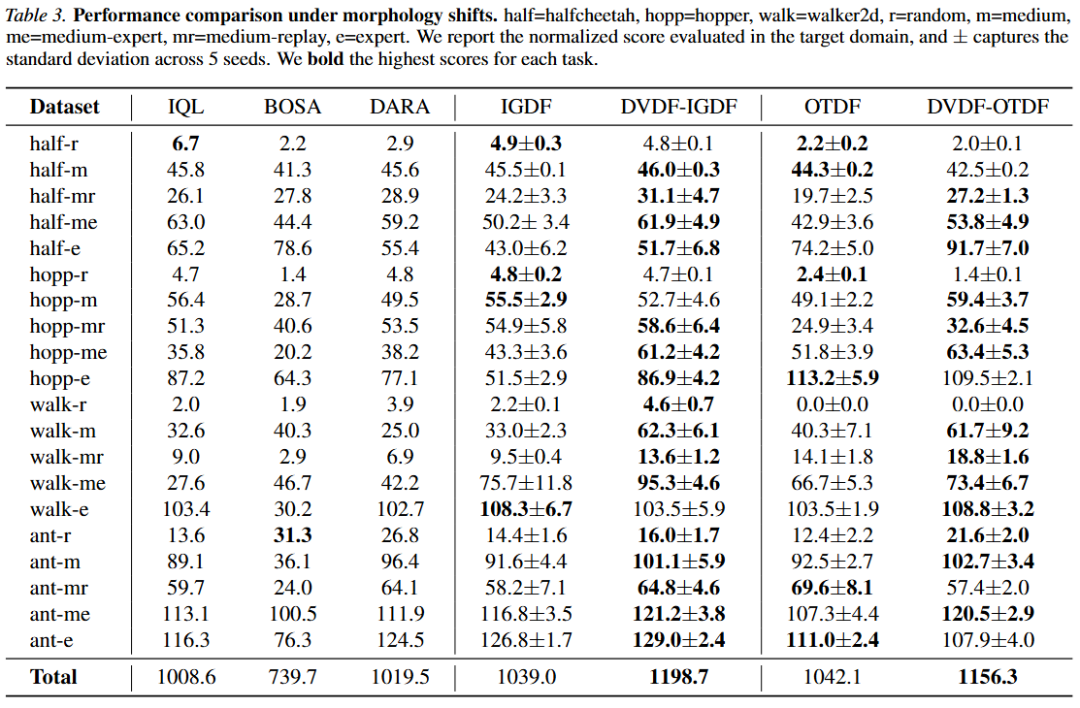
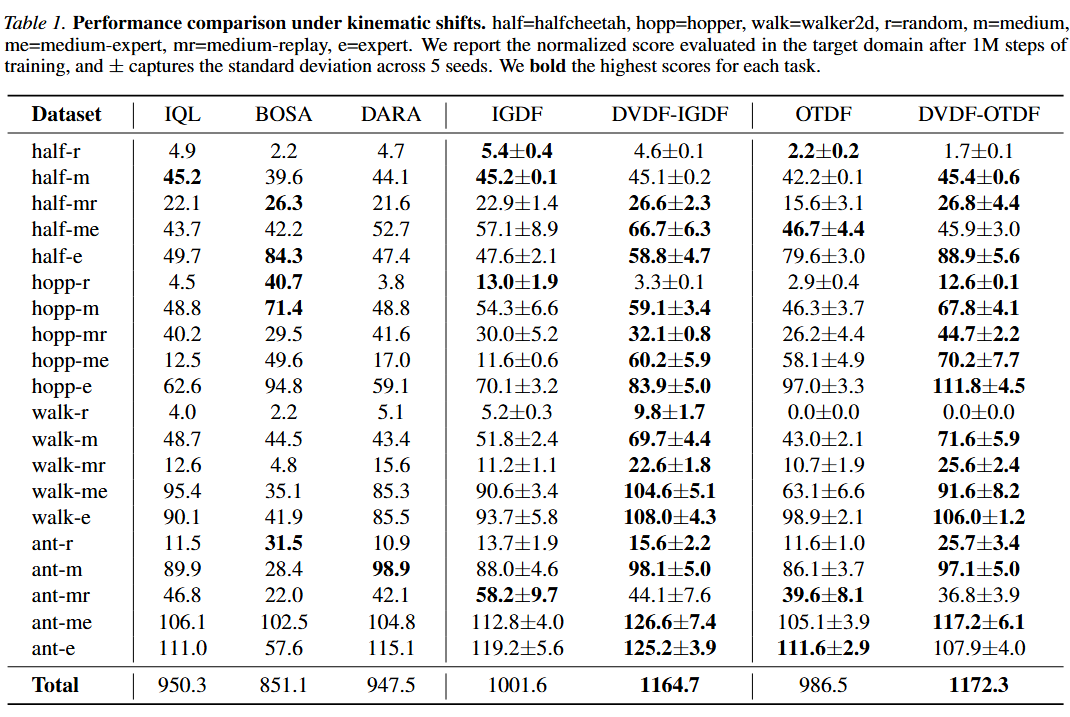
论文中设计了多个动力学偏移场景以验证 DVDF 的有效性。论文通过在四种机器人控制任务中(halfcheetah, hopper, walker2d, ant)引入两种动力学偏移:关节偏移(kinematic shifts)和形体偏移(morphology shifts)以构建源域环境,并在相应环境中收集不同质量的离线数据以构建源域数据集。同时,论文直接从标准的 D4RL 数据集中进行采样以构建目标域数据集。下表展示了在动态偏移场景下 DVDF 和多个基线方法的标准化得分(Normalized Score)对比。可以看出,DVDF 在绝大多数数据集中的性能都优于基线方法,这是因为 DVDF 利用了源域数据集中的数据质量的信息,能够筛选出更具有价值的高质量样本。
具体而言,在关节偏移场景下,DVDF 与多个基线方法的标准化得分对比。DVDF 为基础算法 IGDF 和 OTDF 带来了显著的性能提升:DVDF-IGDF 在 20 个任务中的 16 个上超越了原 IGDF 方法,总分从 1001.6 提升至 1164.7,增幅达 16.3%;DVDF-OTDF 则在 15 个任务上超越了原 OTDF 方法,总分从 986.5 提升至 1172.3,增幅达 18.8%。在形体偏移这一设定下,DVDF 依然保持了显著的性能优势。DVDF-IGDF 在 20 个任务中的 16 个上超越了原 IGDF 方法,总分从 1039.0 提升至 1198.7,增幅达 15.4%;DVDF-OTDF 则在 14 个任务上超越了原 OTDF 方法,总分从 1042.1 提升至 1156.3,增幅达 11.0%。
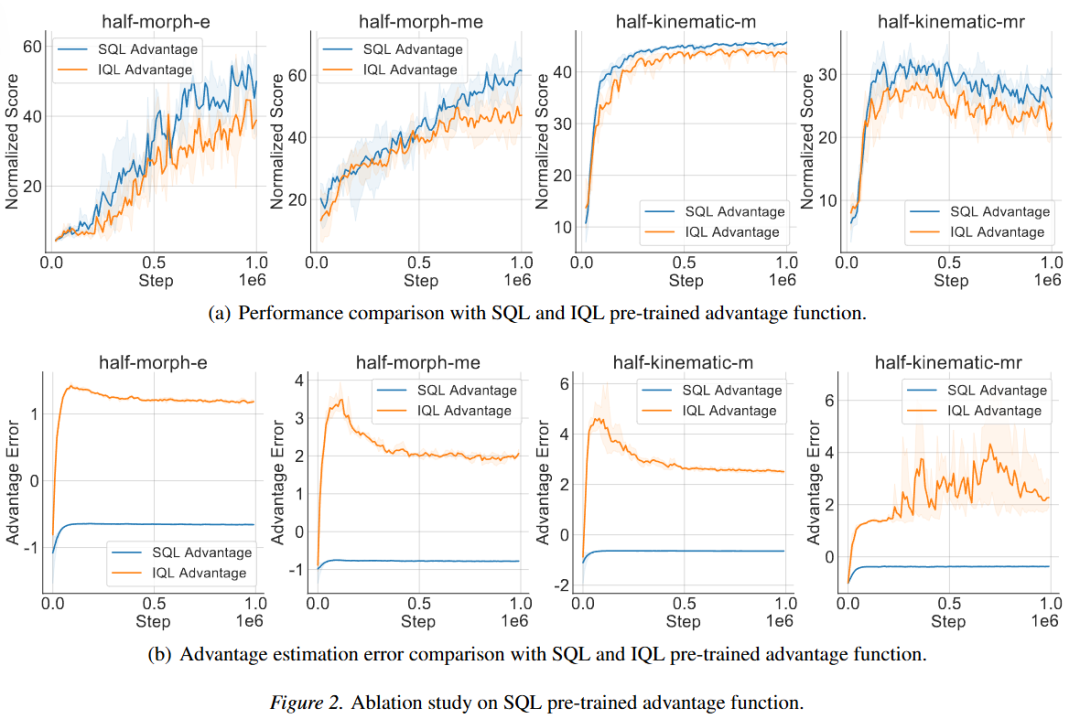
2. 消融实验
在消融实验部分,论文主要分析了分别使用 SQL 和 IQL 算法进行优势函数预训练对策略性能和优势估计偏差的影响。如下图所示,相比于 IQL 算法,使用 SQL 算法进行优势函数预训练能够得到更高的策略性能以及更低的优势估计误差。
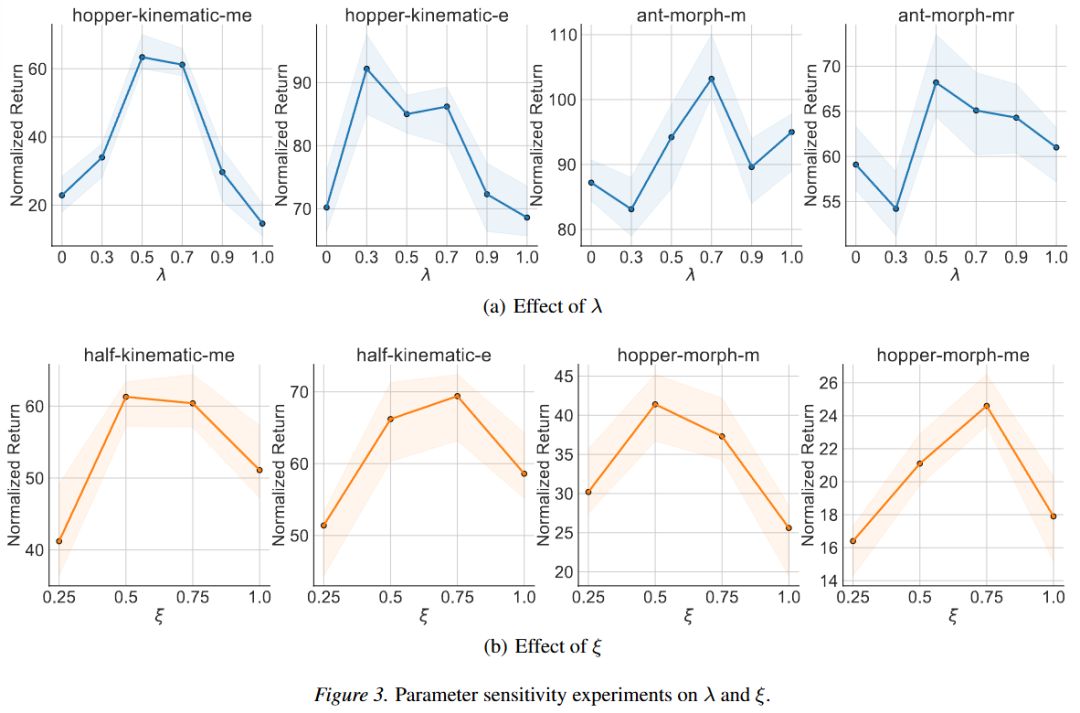
3. 参数敏感性实验
论文中探究了两个主要的超参数:对齐平衡系数 以及数据选择比例 对策略最终性能的影响。如下图所示,对于不同的数据集,最优的超参数各不相同。然而,论文中发现设置 以及 在大部分数据集上都能取得不错的性能,由此避免了繁重的超参数微调步骤。
总结
本论文聚焦于动力学偏移下的跨域离线强化学习,通过实验和理论层面的探究,证明了动力学和价值双重对齐对于跨域离线强化学习至关重要。基于这一发现,论文提出全新的跨域离线强化学习框架 DVDF。通过在源域上预训练优势函数来度量样本价值,并与动力学对齐相结合,DVDF 能够识别并筛选出对策略学习有价值源域样本。在多种场景下的实验结果表明,DVDF 都展示了比基线算法更高的性能,充分验证了其有效性。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com