Physion-Eval指出,AI视频越来越像真,但离真正符合物理规律仍差很远。
原文标题:Physion-Eval发布 | 别被「更像真的视频」骗了,AI视频生成,可能还远未真正学会物理世界
原文作者:机器之心
冷月清谈:
怜星夜思:
2、问题2:为什么现在很多视频模型已经很会做“真实感”,却还是频繁犯低级物理错误?你觉得症结更像是数据问题、模型结构问题,还是评测导向问题?
3、问题3:文章提到连多模态大模型当“自动评委”都不太靠谱。你觉得未来视频评测应该继续依赖人工,还是有可能做出更可靠的自动物理评估?
4、问题4:如果你是视频生成团队负责人,下一阶段你会优先补哪一类能力:物体持续性、接触关系、状态变化、时序一致性,还是因果结构?为什么?
原文内容

这两年,视频生成模型进步很快。清晰度更高了,镜头更稳了,人物和场景看上去也越来越自然。很多时候,我们判断一个模型强不强,看的就是它 “像不像真的”。但这其实只回答了一半的问题:它看起来像真的,不代表它真的符合现实世界的物理规律。这件事放在短视频生成里,也许只是 “偶尔有点怪”;但如果视频模型真的要往 world model、仿真系统、具身智能这些方向走,问题就不一样了。一个模型如果连物体怎么接触、状态怎么变化、事件怎么按因果顺序发生都搞不清楚,那它再像,也只是像。
现在的视频评测,更像是在比 “好不好看”
目前,视频生成领域常见的评测方式,要么看自动指标,要么让人直接选 “哪个视频更好”。这种方式当然有意义,它能比较清晰度、流畅度、观感这些东西,但它很难告诉你:视频里到底有没有违反基本物理常识。
比如,一个物体是不是无缘无故消失了;两个东西是不是明明没接触却发生了交互;一个动作的结果是不是和前面的过程根本对不上。这些问题,才真正关系到模型是在 “生成一个像真的画面”,还是在 “模拟一个可信的世界”。
Physion-Eval:从 “视觉真实” 走向 “物理真实” 的新 benchmark
这篇工作提出了 Physion-Eval。它不是再做一个 “谁的视频更好看” 的排行榜,而是想认真回答一个更关键的问题:AI 生成的视频,在物理层面到底有多真实。

-
论文标题: Physion-Eval: Evaluating Physical Realism in Generated Video via Human Reasoning
-
作者: Qin Zhang, Peiyu Jing, Hong-Xing Yu, Fangqiang Ding, Fan Nie, Weimin Wang, Yilun Du, James Zou, Jiajun Wu, and Bing Shuai
-
作者单位:Physion Labs,斯坦福大学,MIT,哈佛大学,Character AI
-
论文链接: https://arxiv.org/abs/2603.19607
-
数据集链接: https://huggingface.co/datasets/PhysionLabs/Physion-Eval
-
视频链接:https://www.youtube.com/watch?v=Vbn_W3WNUHw
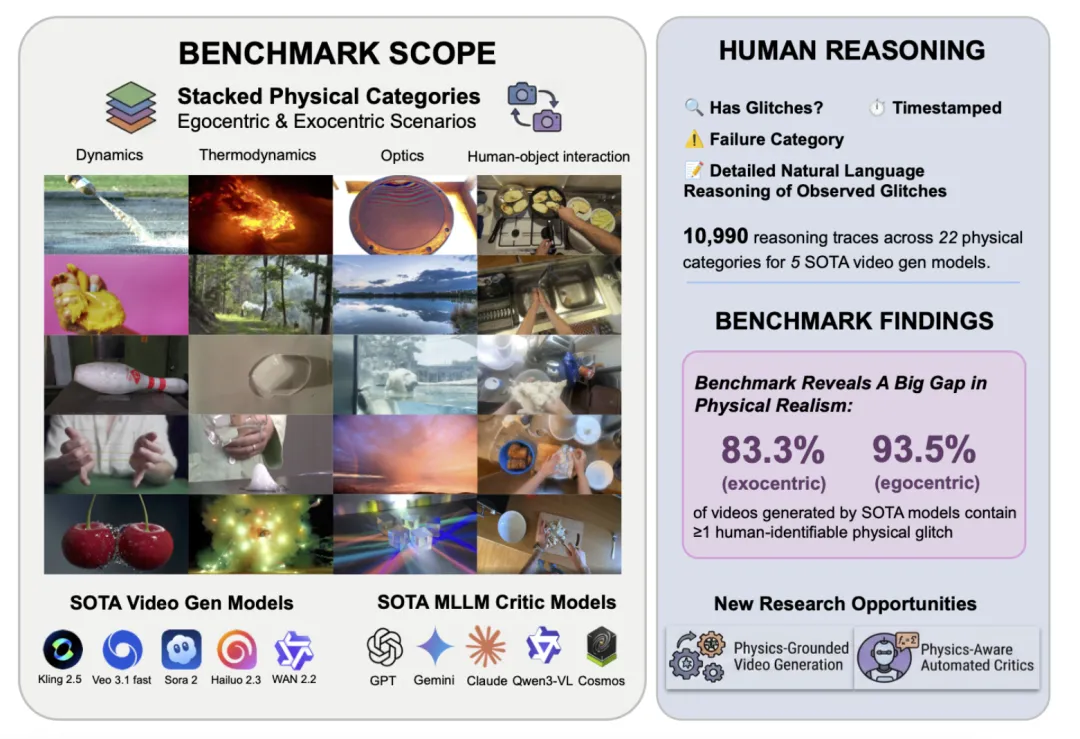
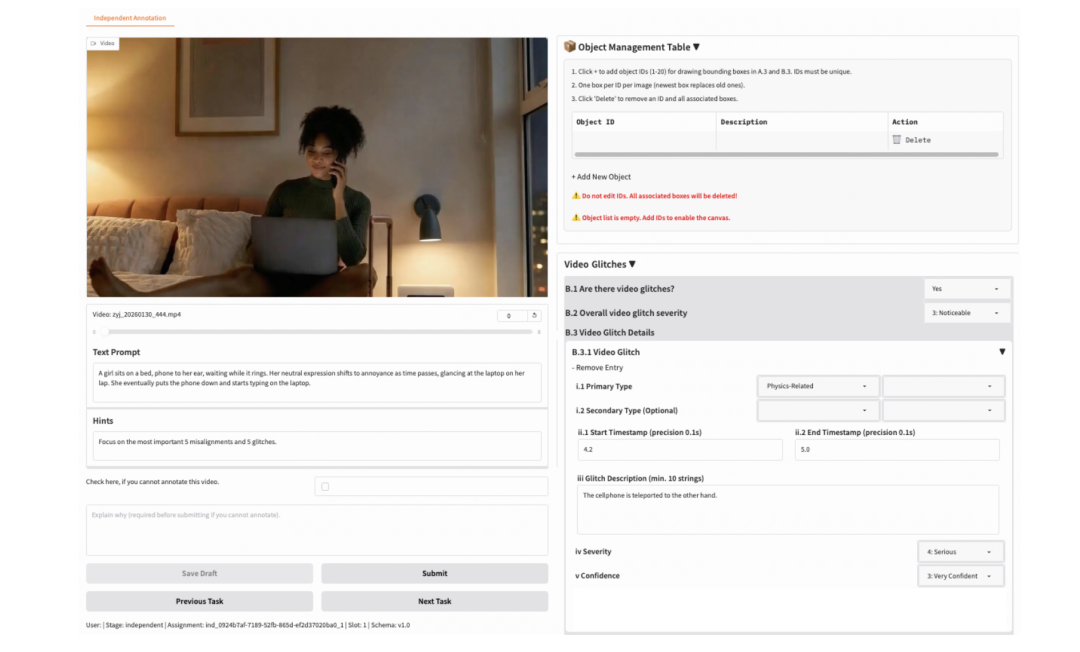
这个 benchmark 同时覆盖第一人称和第三人称场景,包含 10,990 条专家推理轨迹,覆盖 22 类细粒度物理现象。和常见评测不太一样的地方在于,这里的每条样本不只是简单打个分,而是会标出错误发生在什么时候、属于哪一类问题,以及为什么不对。
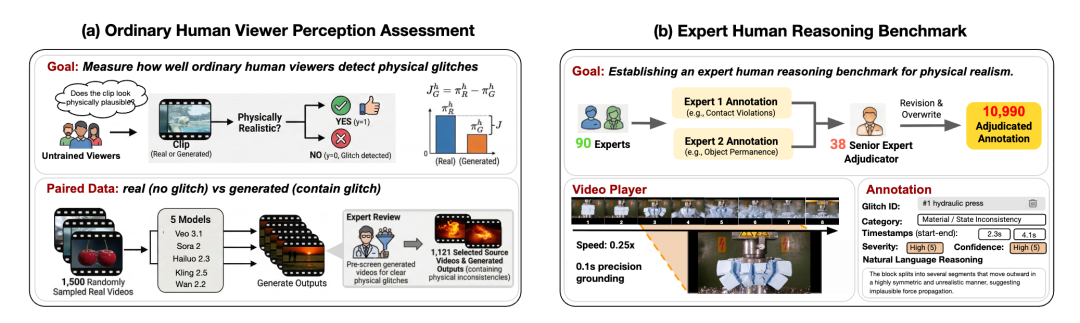
数据上,第三人称部分来自 WISA-80K,第一人称部分基于 EPIC-KITCHENS 构建。为了保证标注质量,论文组织了 90 位具有 STEM 背景并接受过本科物理训练的专家标注者,采用双人标注和资深专家裁决的流程,最后得到的是带时间戳、错误类别和文字解释的高质量标注。
在这一过程中,人类智能所展现出的优势尤为明显:人类不仅能够识别视觉上的异常,更能够基于物理直觉与因果理解,对复杂的动态过程进行推理和解释。相比之下,即使是当前最先进的多模态模型,在时序一致性、交互合理性以及隐含物理规律的判断上,仍存在明显不足。
最直接的结论:现在的模型,还远谈不上 “物理一致”
这篇工作的主结论其实很简单,也很扎眼:在物理过程敏感的场景里,83.3% 的第三人称生成视频和 93.5% 的第一人称生成视频,都至少包含一个人类可以明确识别的物理错误。这说明什么?说明今天的视频模型确实越来越会制造 “真实感” 了,但离 “真正符合物理规律” 还有很远。
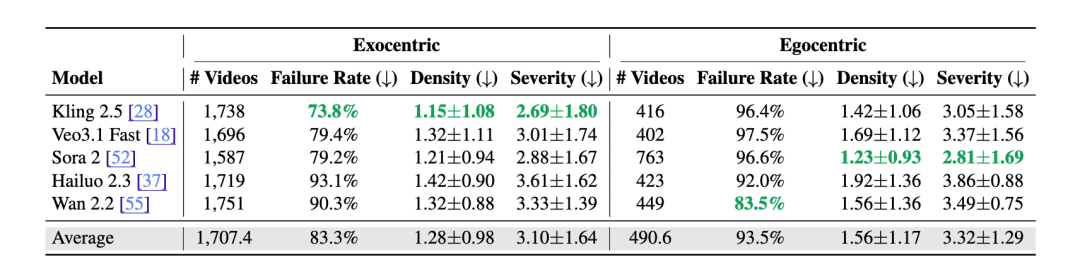
而且这些错误不是零零散散的小毛病,而是系统性的。论文里总结的典型问题包括:接触或交互失败、对象突然出现或消失、时间连贯性崩塌、因果顺序错乱、材料或状态变化异常、几何碰撞不合理等等。换句话说,问题不只是 “画面有点假”,而是模型对物体、接触、运动和结果之间最基本的关系,还经常搞错。

很多错误不是粗糙,而是 “看着像,但其实完全不对”
Physion-Eval 里最有意思的地方,其实是那些具体例子。它们不是那种一眼就看出来的低级 bug,而是第一眼好像还行,仔细一想却明显不符合常识。
比如,桌面上突然多出一把本来不存在的刀;瓶口朝下,液体却不往下流;水直接穿过锅底;又或者一个锅被两根手指以几乎不可能的方式拎起来。它们的问题不在于 “渲染不精细”,而在于直接违背了物体守恒、重力、不可穿透性和稳定接触这些最基本的物理规律。
这也是为什么我们觉得,这项工作不只是 “又多了一个 benchmark”。它更像是在提醒大家:今天很多模型也许已经很会生成 “像真的视频”,但还远没有学会 “世界为什么会这样动”。
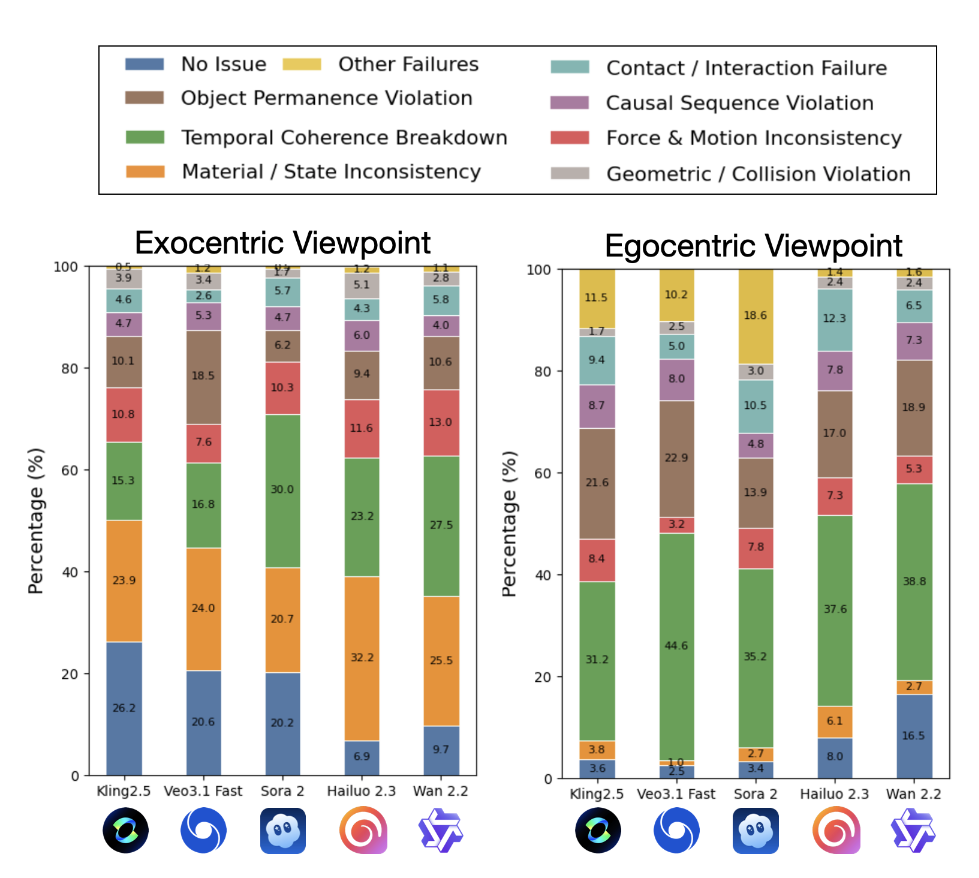
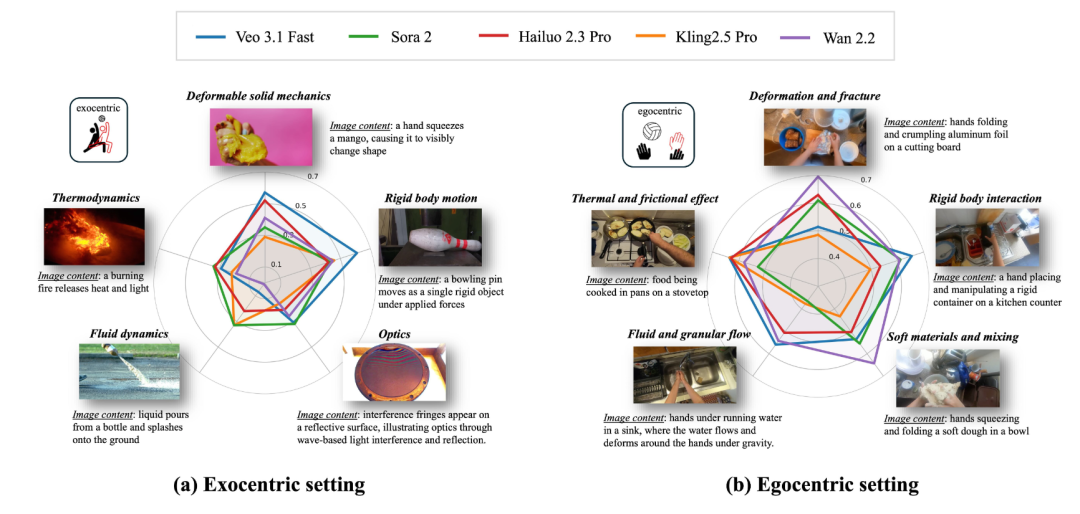
更麻烦的是,连最强的多模态模型也不太会看这些错误
论文还问了另一个很现实的问题:那能不能让现在的大模型来当 “自动评委”,替人判断一个视频有没有物理问题?
答案是,暂时还不行。
文章评估了 10 个开源和闭源的 MLLM critic,结果显示,它们和人类判断之间还有明显差距。以 Gemini 3.0 Pro 为例,它会漏掉超过 74.4% 的第三人称错误视频和 90.1% 的第一人称错误视频。而且它们不只是漏检,还会把错误发生的时间说错,甚至编出根本不存在的原因。
这点其实很关键。因为如果以后大家真想靠自动 critic 去评估 world model 或视频生成系统,那 critic 本身至少得先真的看懂视频里的物理过程。就目前来看,人类判断依然是最可靠的标准。
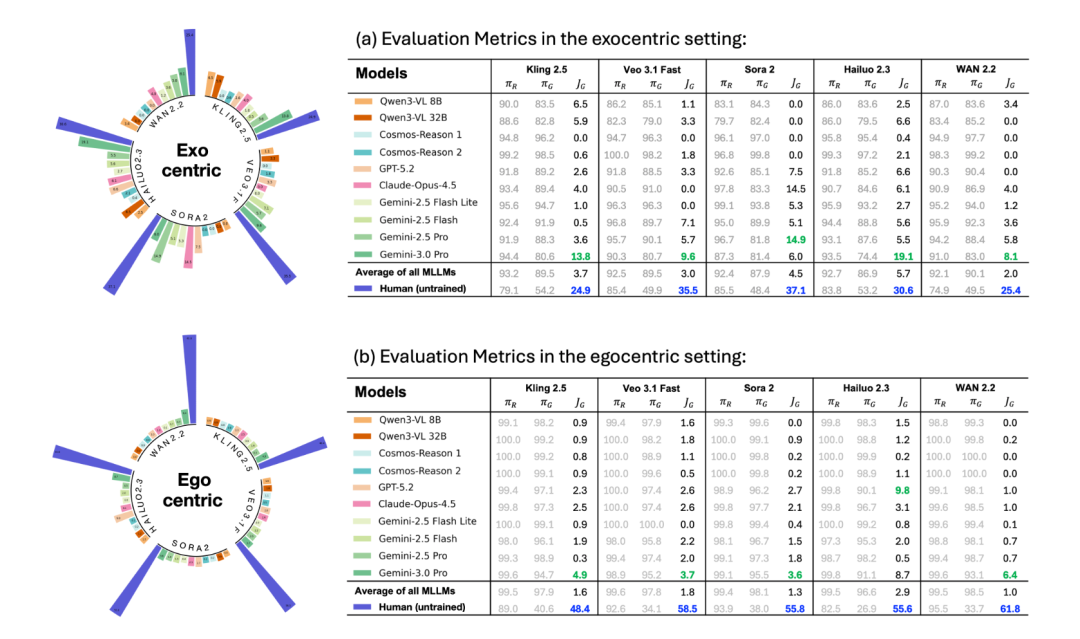



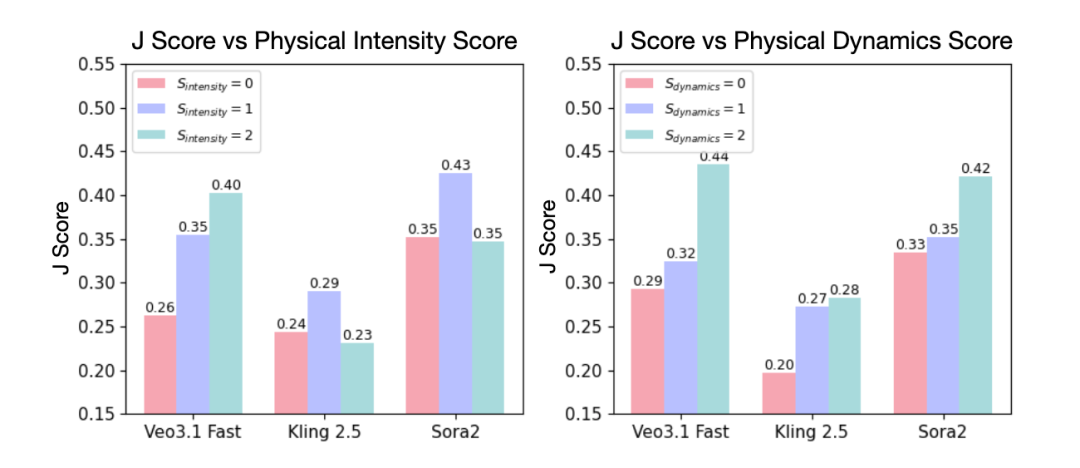
越是高动态的物理过程,越容易暴露当前模型的短板
论文进一步从 physical intensity 和 dynamics 两个维度分析了生成模型与市面上已有的 MLLM critic 的表现。结果表明,相比强度大小,过程本身的动态性和复杂性更容易暴露视频生成模型的物理建模缺陷。对 MLLM critic 来说也是如此:只有当错误足够明显时,它们才会表现出有限的判断能力,但整体仍明显落后于人类。


总结
Physion-Eval 想指出的,不只是 “现在的视频生成模型还不够强”,而是一个更根本的问题:当行业越来越关注视频 “看起来有多真” 的时候,我们可能忽略了它 “实际上对不对”。
对于真正想做 world model、机器人、具身智能和仿真的人来说,这个问题绕不过去。画面更清晰、动作更顺滑,当然重要;但如果物体会无故出现,液体不会往下流,动作结果和前因对不上,那模型就还没有真正学会世界的运行方式。
视频生成下一阶段,也许不该只继续卷观感,而应该更认真地去解决物体持续性、接触关系、状态变化、时序一致性和因果结构这些更本质的问题。“看起来对”,从来不等于 “实际上对”。
作者介绍
本文由来自美国顶级科技公司与世界一流高校的豪华作者阵容共同完成,集结 Physion Labs、斯坦福大学、MIT、哈佛大学及 Character AI 的核心研究者。其中,Physion Labs 团队(Qin Zhang、Peiyu Jing、Bing Shuai)长期专注于生成式视频与世界模型中的物理一致性问题,构建了面向行业的评估基础设施与数据闭环,致力于成为下一代生成模型的 “物理可信层”。其余作者包括斯坦福大学的 Hong-Xing Yu、Fan Nie、James Zou、Jiajun Wu,麻省理工学院的 Fangqiang Ding,哈佛大学的 Yilun Du,以及 Character AI 的 Weimin Wang 等业内顶尖学者。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com