综述基础模型驱动的具身导航,系统梳理任务、架构、训练、部署与评测挑战。
原文标题:从任务专用到通用智能:基础模型重塑具身导航
原文作者:机器之心
冷月清谈:
在系统设计上,综述从观测表征、记忆机制、决策控制到整体架构进行了拆解。重点梳理了视觉、文本、地图增强记忆,以及模块化、单策略、双系统、世界模型驱动等多种架构范式,指出关键不只是“是否用了大模型”,而是如何在表达能力、效率与控制可靠性之间平衡。
文章还总结了数据来源与训练方法,包括仿真合成数据、真实世界与网络视频、多模态通用数据,以及模仿学习、强化学习、辅助任务学习和视觉语言联合训练等路径。除此之外,作者特别强调端侧部署难题,分析了模型加速、云边协同、量化压缩和异步执行等工程方案。
在评测部分,综述提醒研究者不能只看单一分数,还要关注任务完成度、指令对齐、鲁棒性、安全性和实时性。作者认为,具身导航下一阶段的关键在于突破数据瓶颈、探索更清晰的Scaling Law,并推动视觉语言模型与世界模型进一步融合。
怜星夜思:
2、问题2:具身导航最卡脖子的地方,你更认同是数据不够、模型不够强,还是机器人硬件和部署限制太大?
3、问题3:未来评价一个导航系统强不强,单看任务成功率是不是已经不够了?还应该补哪些指标?
4、问题4:如果视觉语言模型和世界模型继续融合,你觉得机器人导航会先在哪类场景里真正实用起来?
原文内容

团队介绍:北京邮电大学徐梦炜副教授研究团队专注于端侧具身智能算法和系统软件,在相关领域的顶级会议及期刊发表论文50余篇,曾获中国高校首个USENIX ATC 2024最佳论文奖,推出了面向端侧异构算力芯片的高效推理引擎mllm(GitHub 1.4K Stars)。
具身导航是机器人从 “看懂环境” 走向 “真正行动起来” 的关键能力。无论是家庭服务机器人、仓储物流机器人,还是执行巡检与搜救任务的无人系统,都需要在复杂、开放、动态的真实世界中完成感知、理解、记忆、规划与控制的闭环。
长期以来,该方向主要依赖面向单一任务设计的专用模型。这类方法在特定场景下能够取得一定进展,但在跨环境泛化、长程决策、复杂语义理解和真实部署鲁棒性等方面仍存在明显局限。随着大语言模型、视觉语言模型和世界模型等基础模型的发展,具身导航研究正逐步从 “任务专用” 走向 “通用智能”。这也促使我们重新审视该领域的问题定义、方法体系与发展方向。
在这一背景下,北京邮电大学研究团队联合南京大学、清华大学和北京大学,完成了综述论文《Foundation Models for Embodied Navigation: A Survey》。文章围绕基础模型驱动的具身导航,从任务类型、具身形态、架构设计、状态表征、记忆机制、决策方式、数据与训练策略、部署效率及评测体系等方面进行系统梳理,重点讨论基础模型为具身导航带来的机遇与挑战。通过对代表性方法与研究趋势的统一分析,该综述为理解这一方向提供较为完整的研究框架,也为后续探索更通用、更可靠的具身智能系统提供参考。

-
论文标题:Foundation Models for Embodied Navigation: A Survey
-
论文主页:https://membodied.github.io/embodied-navigation-survey/
-
论文链接:https://membodied.github.io/embodied-navigation-survey/static/pdfs/foundation-models-for-embodied-navigation-a-survey.pdf
-
相关论文仓库:https://github.com/MEmbodied/awesome-embodied-navigation-paper-list
1. 具身导航问题定义与分类
基础模型驱动的具身导航是什么,研究对象又该如何界定?文章首先将具身导航定义为:智能体在部分可观测环境中,基于自中心观测理解导航目标、持续做出序列决策,并通过物理动作逐步到达目标位置。在此基础上,文章从任务目标形式出发,将现有研究系统归纳为语义导航、几何导航、交互式导航,以及面向真实复杂场景的复合与通用导航;又从机器人载体出发,区分轮式、足式和无人机等不同具身形态,并分析它们在感知配置、运动约束与规划复杂度上的差异。
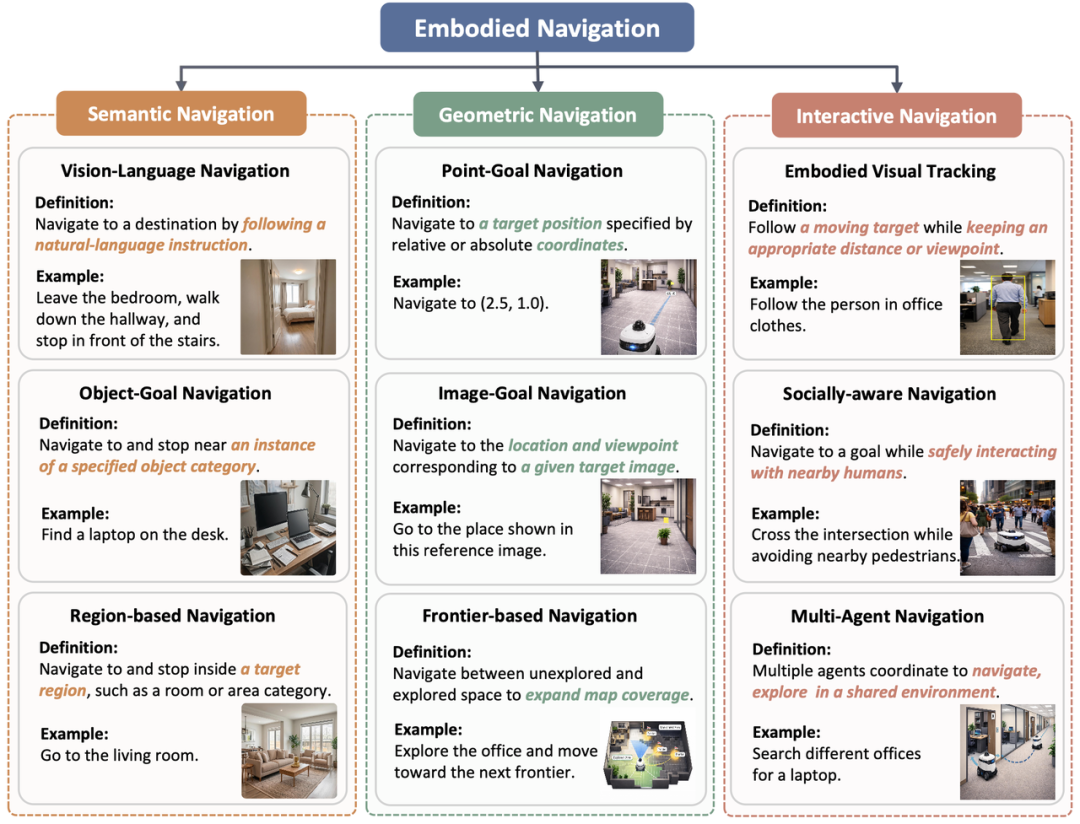
图1 具身导航任务分类
2. 具身导航关键系统设计
基础模型驱动的具身导航系统如何感知环境、维护记忆、形成决策,并转化成可执行动作?文章系统拆解了具身导航从输入到输出的关键设计链条。
首先,观测与表征既包括最基础的自中心 RGB、深度与多视角视觉输入,也包括将局部观测提升为空间结构的地图增强表示,以及支撑跨视角对齐与时序融合的相机内外参信息。第二,记忆机制被划分成视觉记忆、文本记忆与地图增强记忆三类,分别通过历史视觉上下文、语言摘要、显式空间结构来维护记忆。第三,在决策与控制层面,文章讨论了模型如何将感知与记忆转化为可执行动作,梳理了语义目标选择、离散动作预测、连续动作生成等不同动作空间设计,以及显式推理、适应性推理和仅在训练中使用推理监督等不同决策机制。
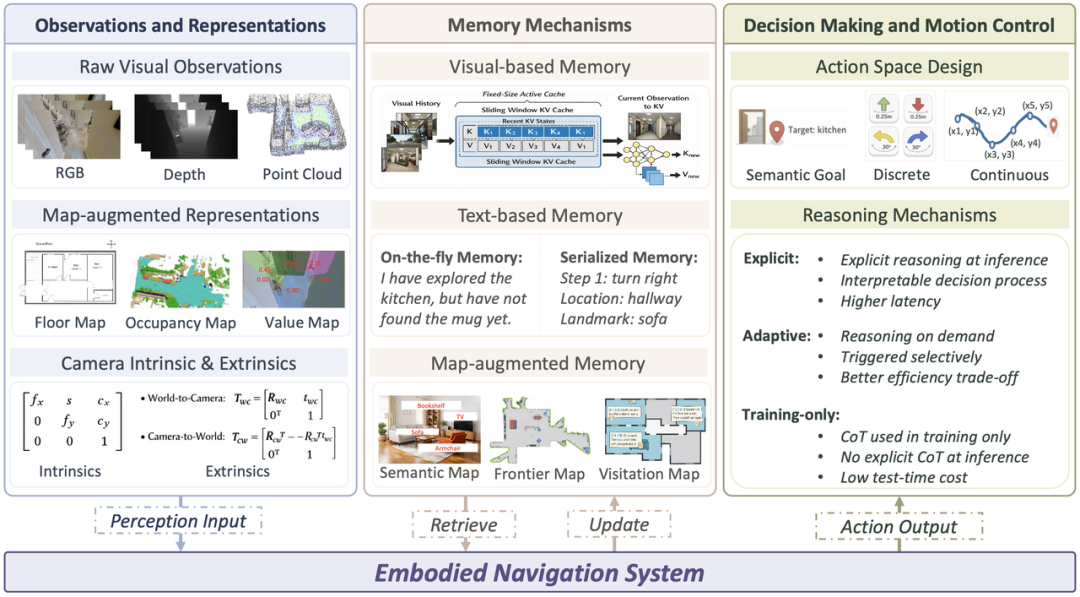
图 2 导航系统关键设计维度
在系统架构层面,文章围绕 “这些输入、记忆与输出模块究竟是如何被组织起来” 的问题,梳理了当前基础模型驱动的具身导航系统的几种代表性架构范式,包括将感知、建图、规划与控制显式拆分的模块化系统,以统一策略直接完成从多模态输入到动作输出映射的单策略系统,将高层慢速语义推理与低层快速控制分离的双系统架构,以及通过预测未来状态、地图或环境变化来增强规划能力的世界模型驱动系统。文章指出,不同方法之间的差异并不只在于 “用了什么大模型”,更在于它们如何在表达能力、计算效率与控制可靠性之间做出取舍。
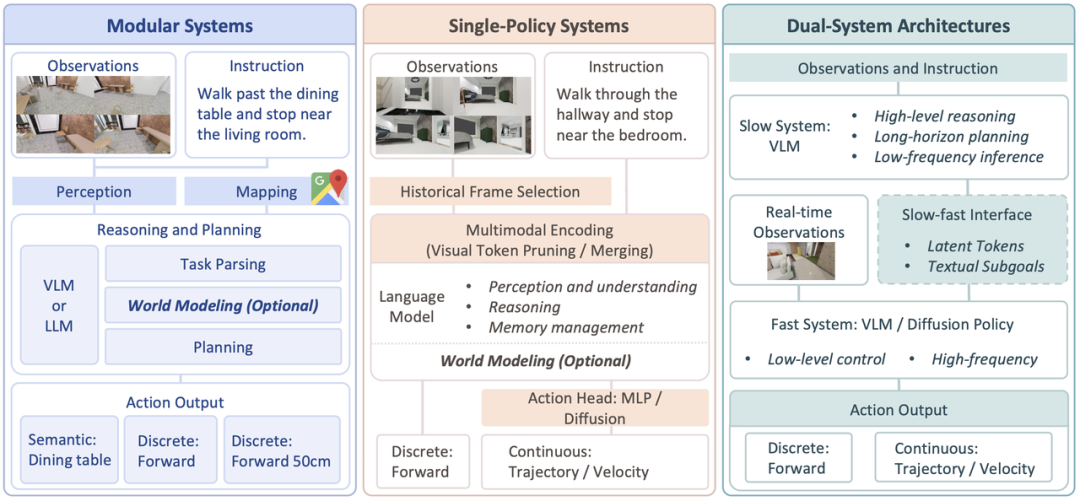
图 3 具身导航常见系统架构
3. 数据收集与模型训练
具身导航中的基础模型依赖什么样的数据获得对环境与任务的理解,又通过什么样的训练方式把这些数据转化为可执行的导航能力?文章从 “数据从哪里来” 和 “能力如何学出来” 两个层面展开系统梳理。在数据来源方面,现有导航数据可归纳为三类:一是仿真与合成数据,依托三维场景资产、模拟器后端和轨迹合成引擎来大规模所生成的带有观测、位姿和任务标注的导航样本,是最主要的监督来源;二是真实世界与网络视频数据,这类数据虽然缺乏仿真环境中的标准化与可控性,却提供了真实机器人运动噪声、感知误差和环境动态变化,有助于弥补仿真与真实差异;三是通用多模态数据,为模型补充视觉语言理解、语义先验、推理能力与社会规范知识。文章指出:基础模型驱动的具身导航系统不是单纯依赖 “轨迹数据” 学习行动,而是在多类数据混合中同时学习空间结构、语义理解、任务推理与行为对齐。
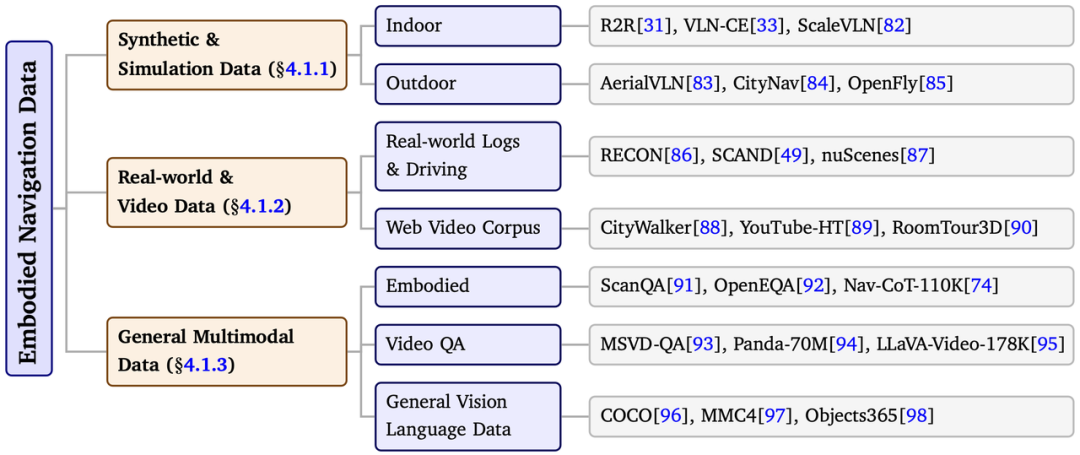
图 4 具身导航训练数据分类
在训练策略层面,文章总结了三类学习路径:一是直接获取导航能力,即通过模仿学习、序列预测、连续轨迹回归、扩散生成或后续强化学习等方式,直接学习动作或轨迹生成策略;二是辅助任务学习,通过中间目标预测、子任务分解、链式推理、未来状态建模、地图学习与奖励对齐等机制,让模型学会 “往哪里走、为什么这样走、接下来会发生什么”;三是视觉语言任务联合学习,通过将视觉通用数据与导航数据混合,避免模型丢失原有的通用语义能力,并增强指令理解、语义泛化和跨场景迁移能力。只有理解数据分布、监督形式与训练范式如何共同塑造导航模型,才能更准确地判断一个系统为什么有效、又为什么在真实环境中仍会失效。
4. 基础模型的端侧部署
怎么将基础模型部署运行在机器人端,而不是停留在离线实验或远程集群上?文章首先从不同具身平台出发,分析轮式机器人、足式机器人和无人机在真实部署中的差异。然后从加速技术角度总结当前解决方案:一类是在模型与算法层面进行结构性加速,例如通过快慢系统分解,将高层慢速推理与低层快速控制分离,通过输入压缩、关键帧筛选、视觉信息压缩以及 KV-cache 优化来降低长时上下文推理成本;另一类则是在软件系统层面进行工程优化,包括云边协同、异步执行、算子融合、量化压缩与流水线调度等,使大模型能够在异构硬件上以更低延迟和更高能效运行。只有把机器人本体约束、模型结构设计与推理系统优化放在一起协同考虑,基础模型驱动的导航系统才能从离线评测走向稳定、可靠、可持续的真实世界运行。
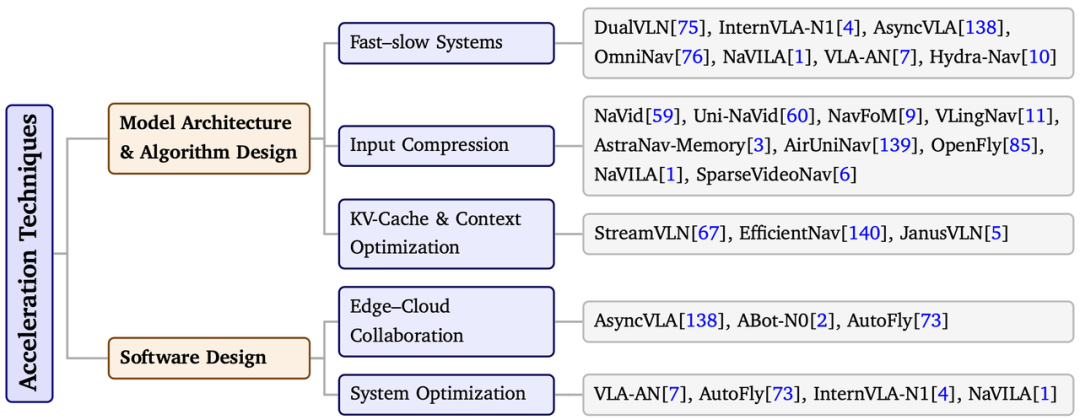
图 5 具身导航系统端侧部署加速技术
5. 评测基准与评估指标
如何判断一个基础模型驱动的具身导航系统是否真的更强,它的 “进步” 又应当由什么来衡量?文章将现 benchmark 所考察的核心能力归纳为五类:(1)自然语言转化为时序一致的行动;(2)在部分可观测环境中完成目标搜索与语义定位;(3)真正服务于信息获取与下游判断;(4)在持续变化的环境中保持安全稳定;(5)在机器人形态、感知接口和执行条件发生变化时,能力能否保留下来。
在评价指标层面,文章从四个层面展开分析:一是任务完成度,衡量系统是否到达目标;二是轨迹一致性与语义对齐,判断系统是否遵循指令;三是鲁棒性、泛化性与安全性,关注模型是否仍然可靠;四是实时部署能力,强调延迟对落地部署的重要性。只有明确不同 benchmark 在测什么以及不同指标所反映的能力,才能避免把局部分数误读为全面能力,把静态场景中的成功误读为真实部署中的可靠性。
6. 总结与展望
基础模型推动具身导航从面向单一任务的专用策略,逐步转向由统一多模态骨干支撑的通用决策范式。相比传统方法,这类系统在语义理解、任务泛化和复杂决策方面展现出更强潜力,也使具身导航开始真正连接感知、记忆、推理、规划与控制等多个环节。文章最后给出了基础模型驱动的具身导航系统值得重点关注的研究方向:
-
当前具身导航最核心的约束仍然是数据瓶颈,下一步发展在很大程度上取决于能否建立真正意义上的 Scaling Law。
-
未来的导航基础模型需要进一步走向视觉语言模型与世界模型能力的融合,从而同时具备语义理解、指令跟随与未来状态预测能力。
-
下一代评测体系需要进一步覆盖开放词汇目标、动态环境、社会约束、实时延迟与端侧部署等关键因素,同时推动算法设计更好适配真实机器人硬件条件。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com