OpenAI 新一代图像模型 GPT-Image-2 泄露,文字渲染和世界知识理解能力强大,或将超越谷歌 Nano Banana Pro。图像编辑和真实感显著提升,值得期待。
原文标题:一夜变天:GPT-Image-2流出,昔日王者Nano Banana Pro要被拉下神坛?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到GPT-Image-2解决了黄色滤镜的问题,你怎么看待AI图像生成中的偏见问题?除了颜色,还可能存在哪些其他的偏见?
3、GPT-Image-2被爆料在文字生成能力上有很大突破,你觉得这个能力在实际应用中有什么价值?会给哪些行业带来变革?
原文内容
OpenAI 的图像生成模型终于要更新了吗?距离上代 GPT-Image-1.5 推出已经近 4 个月的时间了。
今天,GPT-image-2 泄露的消息在海外社区传疯了。
很多人发现,OpenAI 正在大模型竞技场 Chatbot Arena,以多个代号对其新一代多模态模型进行测试。遗憾的是,相关测试已经下线。
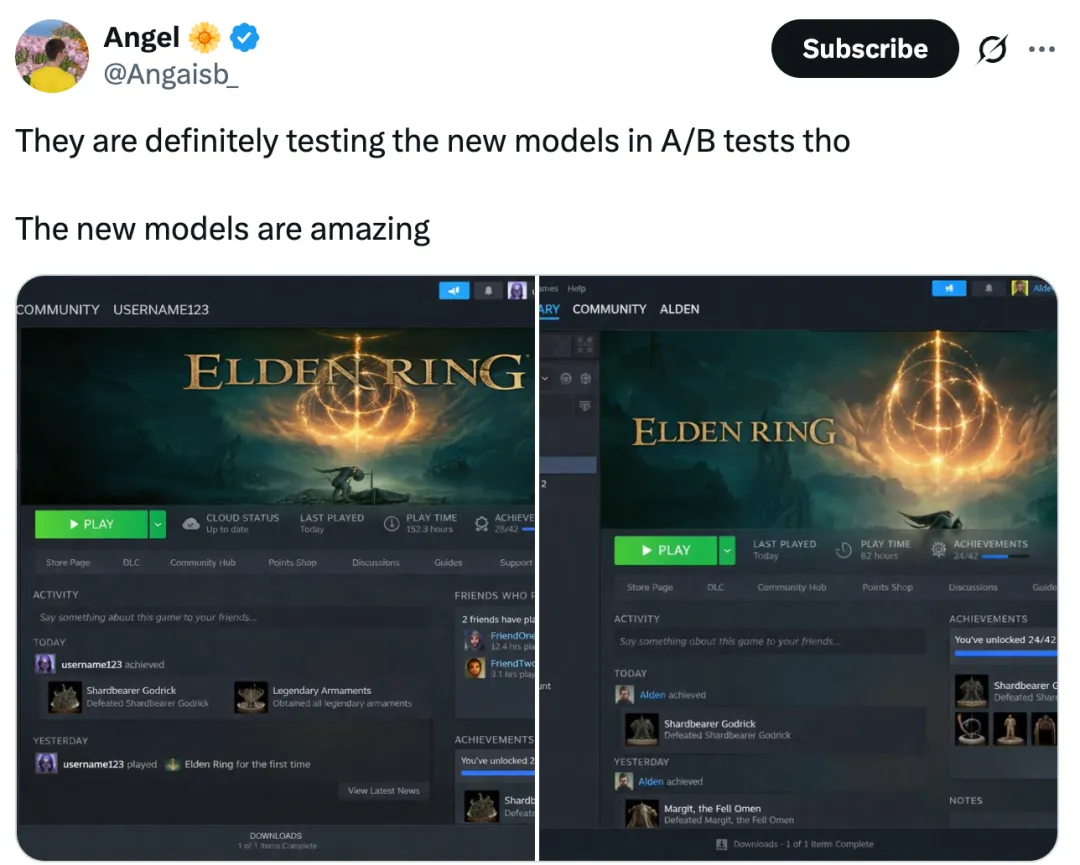
从已有的一些生成 Demo 来看,该模型在文字渲染能力上强得惊人。
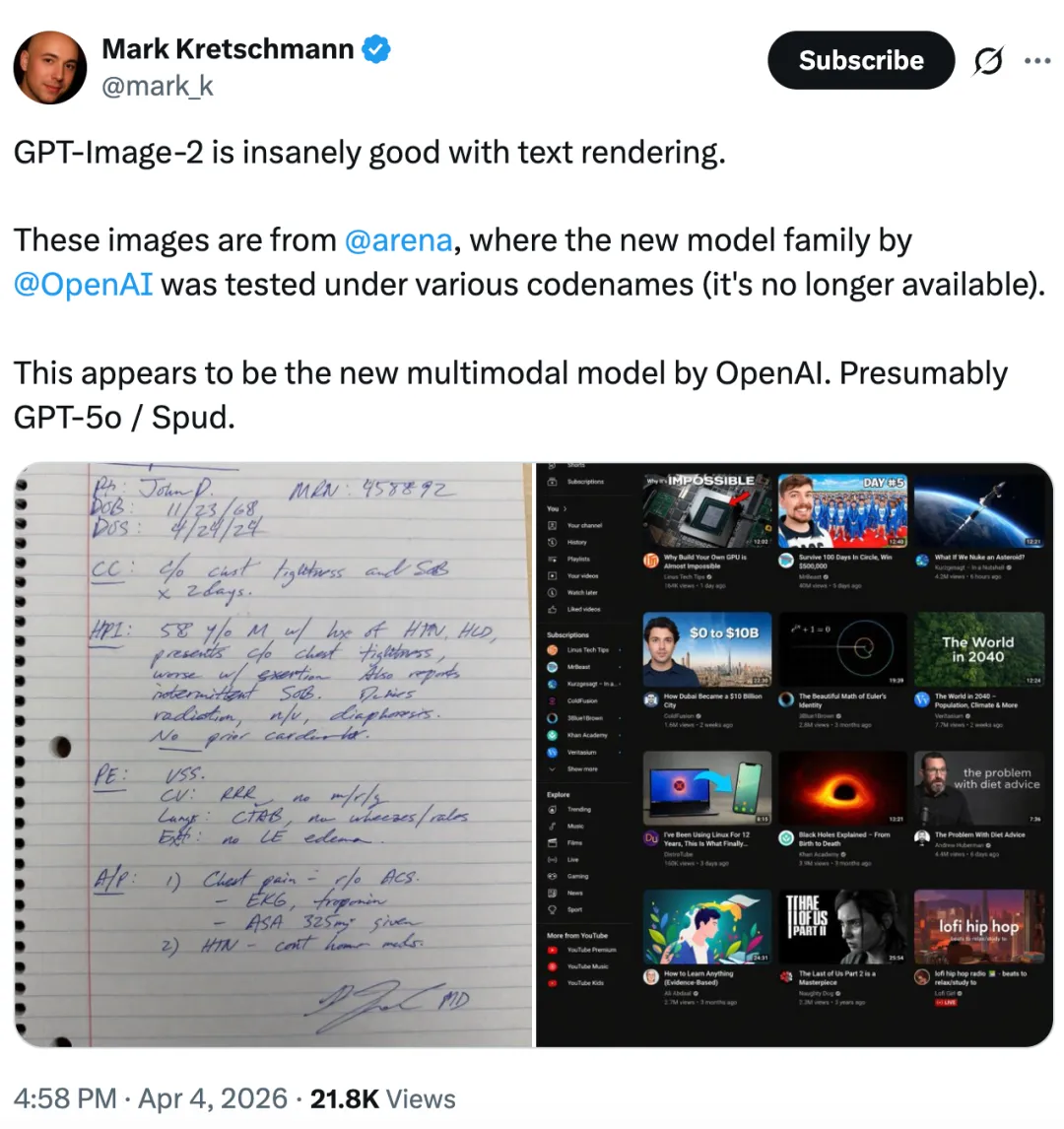
根据流出的更多信息,我们得知,GPT-image-2 曾以「maskingtape-alpha」、「gaffertape-alpha」和「packingtape-alpha」这几个代号进行测试。
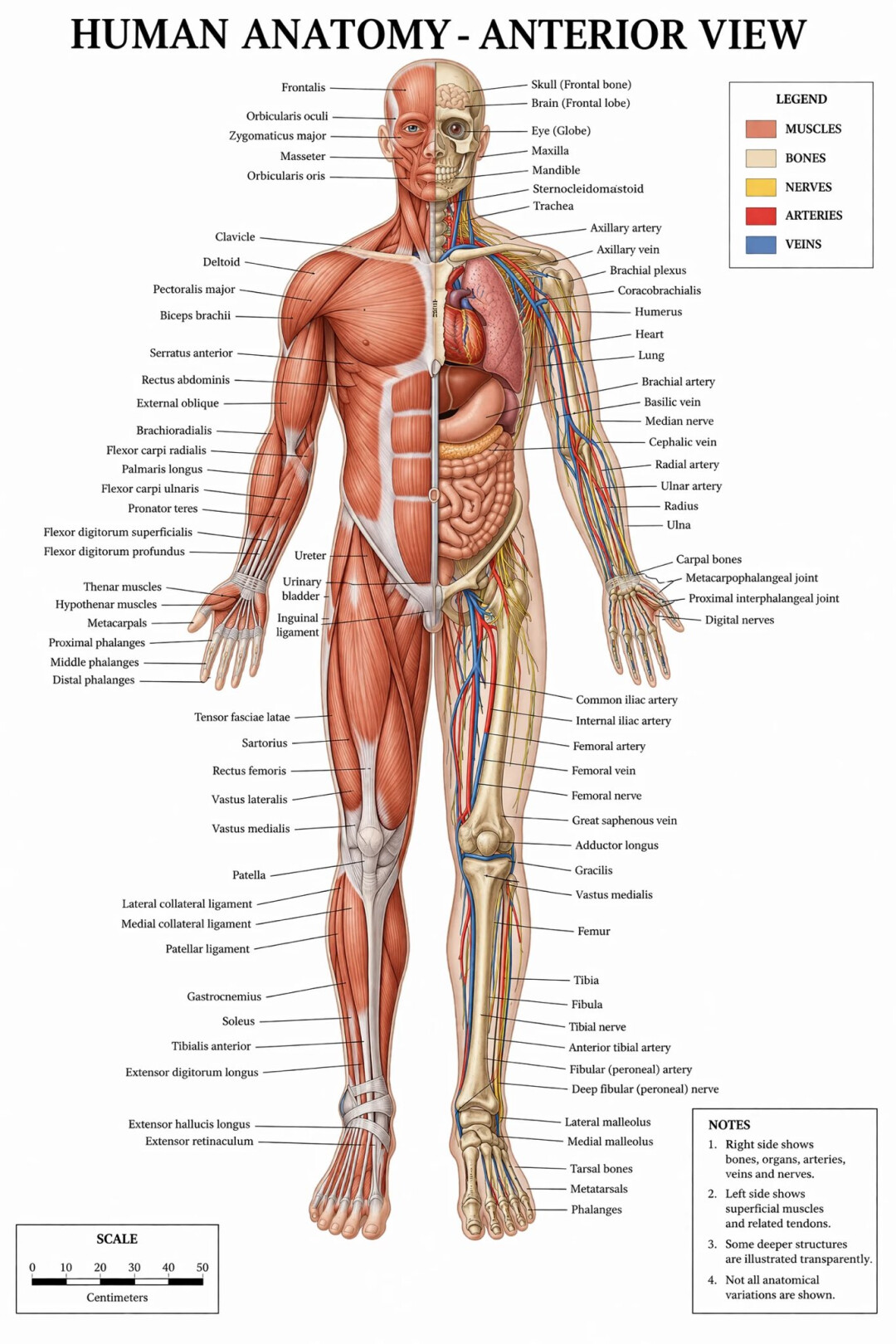
除了文字渲染能力优异之外,该模型在世界知识理解方面的表现也非常突出,整体水平甚至可能超过了谷歌的 Nano Banana Pro。

比如精细的人体解剖学前视图:
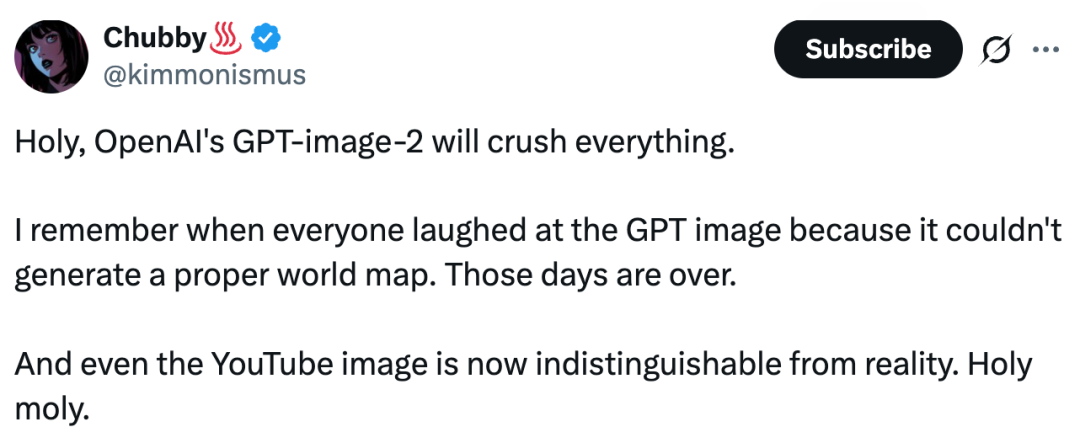
「天哪,OpenAI 的 GPT-image-2 简直要碾压一切了。我还记得以前大家都在嘲笑 GPT 图像模型,因为它连一张像样的世界地图都画不出来。但那样的时代已经过去了。现在,甚至连 YouTube 风格的图片都已经几乎和真实效果无法区分了。真的太夸张了。」
有人感叹,「几乎没有人意识到,我们在一夜之间已经完成了一次范式转变。过去,我们还在测试模型对单一对象的生成效果;而现在,已经开始直接用整张信息密度极高的网页作为测试对象,而且模型能够完成其中约 90% 的还原与理解。而这一切,竟然还只是发生在 2026 年初。」
「OpenAI 终于要解决 GPT Image 系列模型存在的黄色滤镜问题了。这一代很可能会成为目前最好的图像模型。」
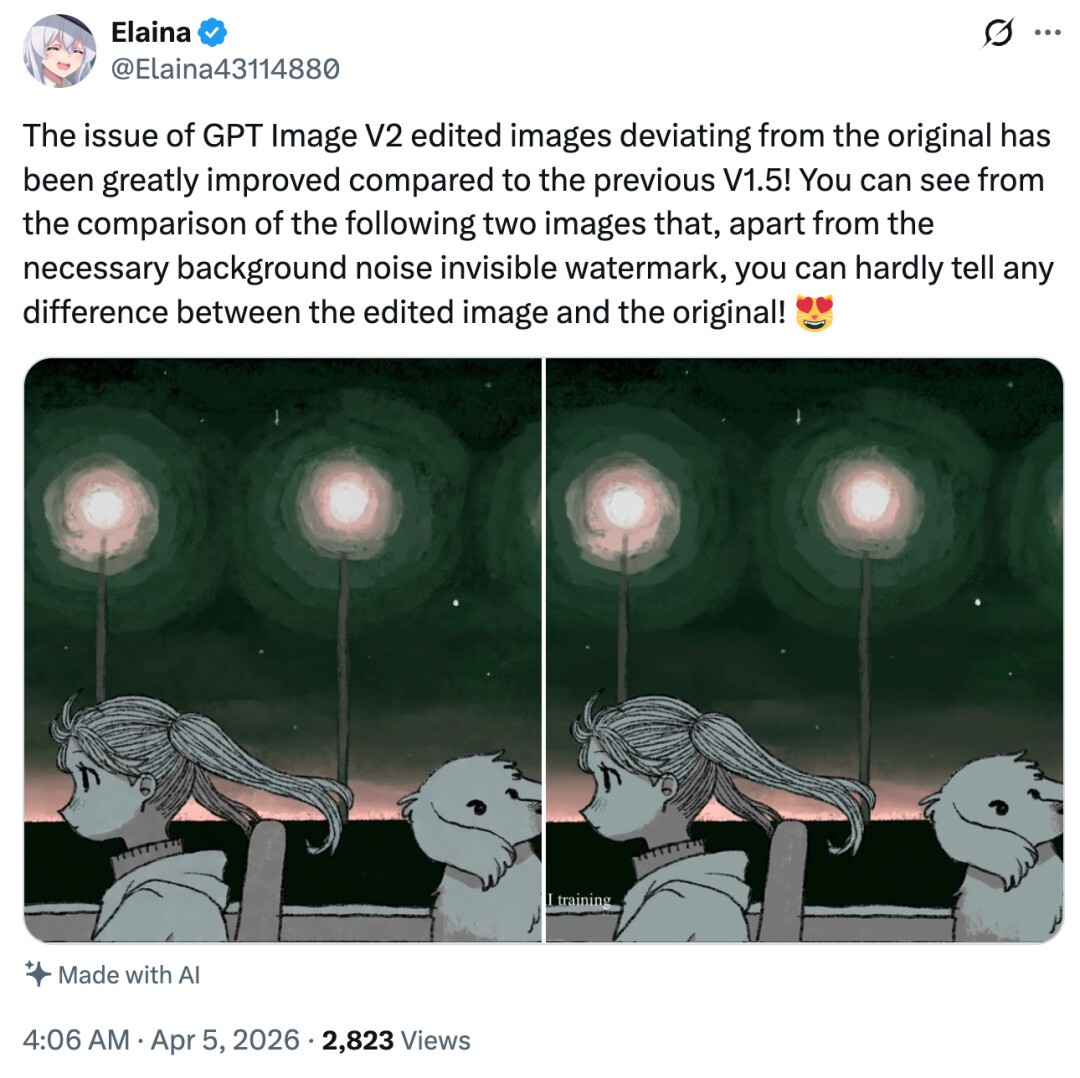
「相比前代 V1.5,GPT-image-2 在图像编辑过程中出现偏离原图的问题已经得到了显著改善。从下面两张对比图可以看出,除了必要的、不可见的背景噪声水印之外,编辑后的图像几乎与原图没有任何可察觉的差异。」
「我们可以观察奥特曼的自拍,如果生成结果看起来真的很像他,那基本可以确定是 Image-2;如果只是像下面那样有点滑稽的粗略模仿,那大概率还是 Image-1.5。」

看起来,大家伙对 OpenAI 新一代图像模型的表现非常认可。
更多网友实测,Nano Banana Pro 慌了吗
除了在 Chatbot Arena 测试之外,GPT-Image-2 已经开始向部分 ChatGPT 用户逐步开放。
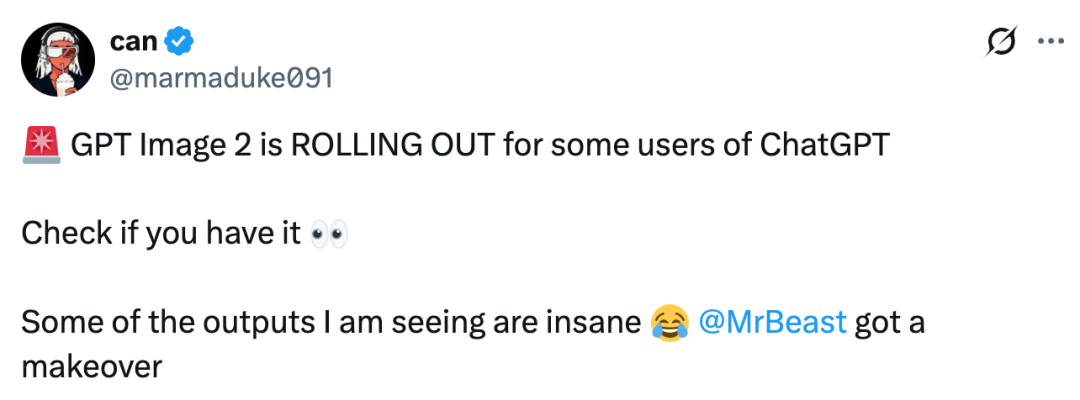
「Nano Banana Pro 被彻底碾压了,GPT-image-2 在各个方面完成了超越。」
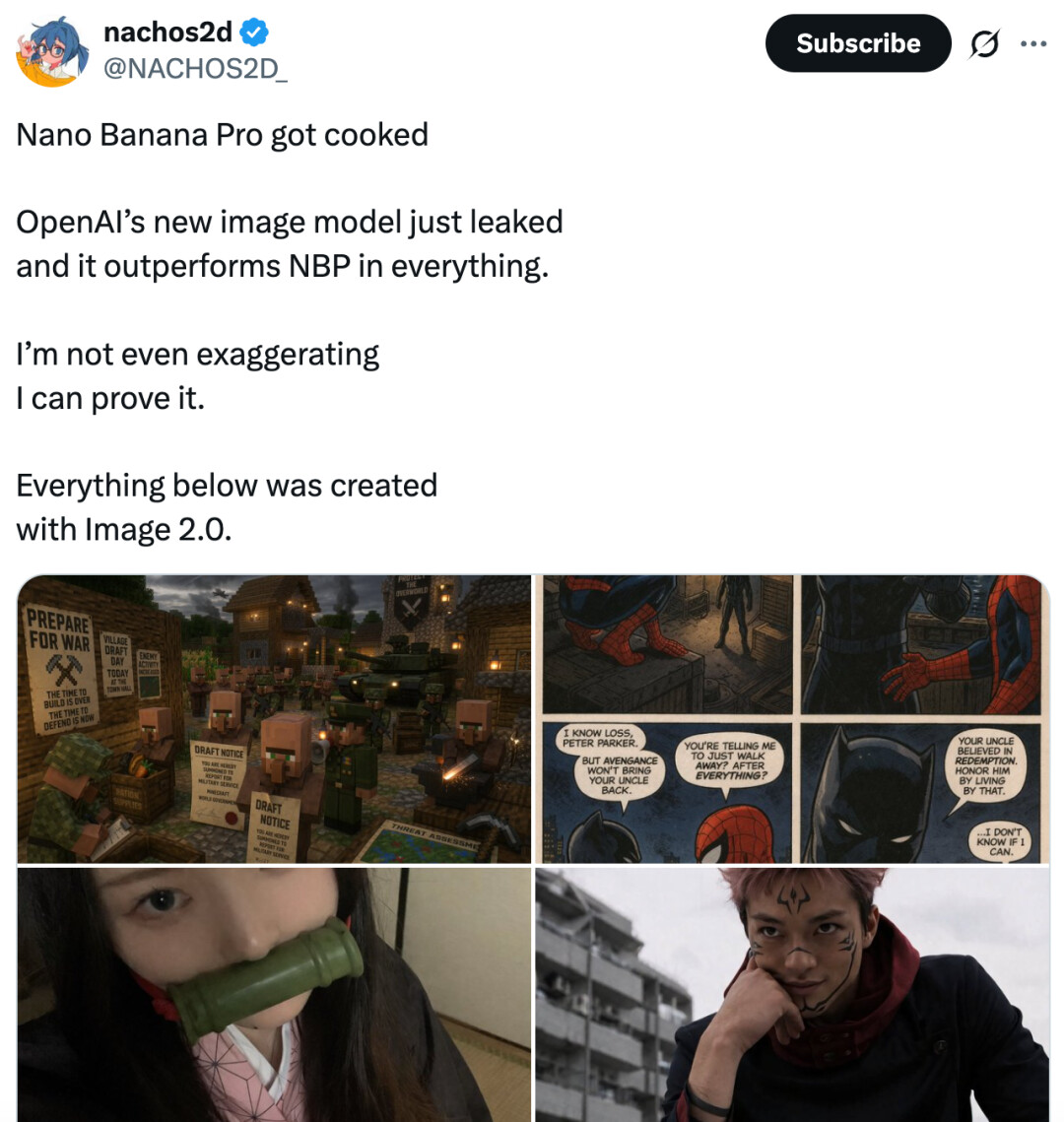
奥特曼与马斯克的「和解」:
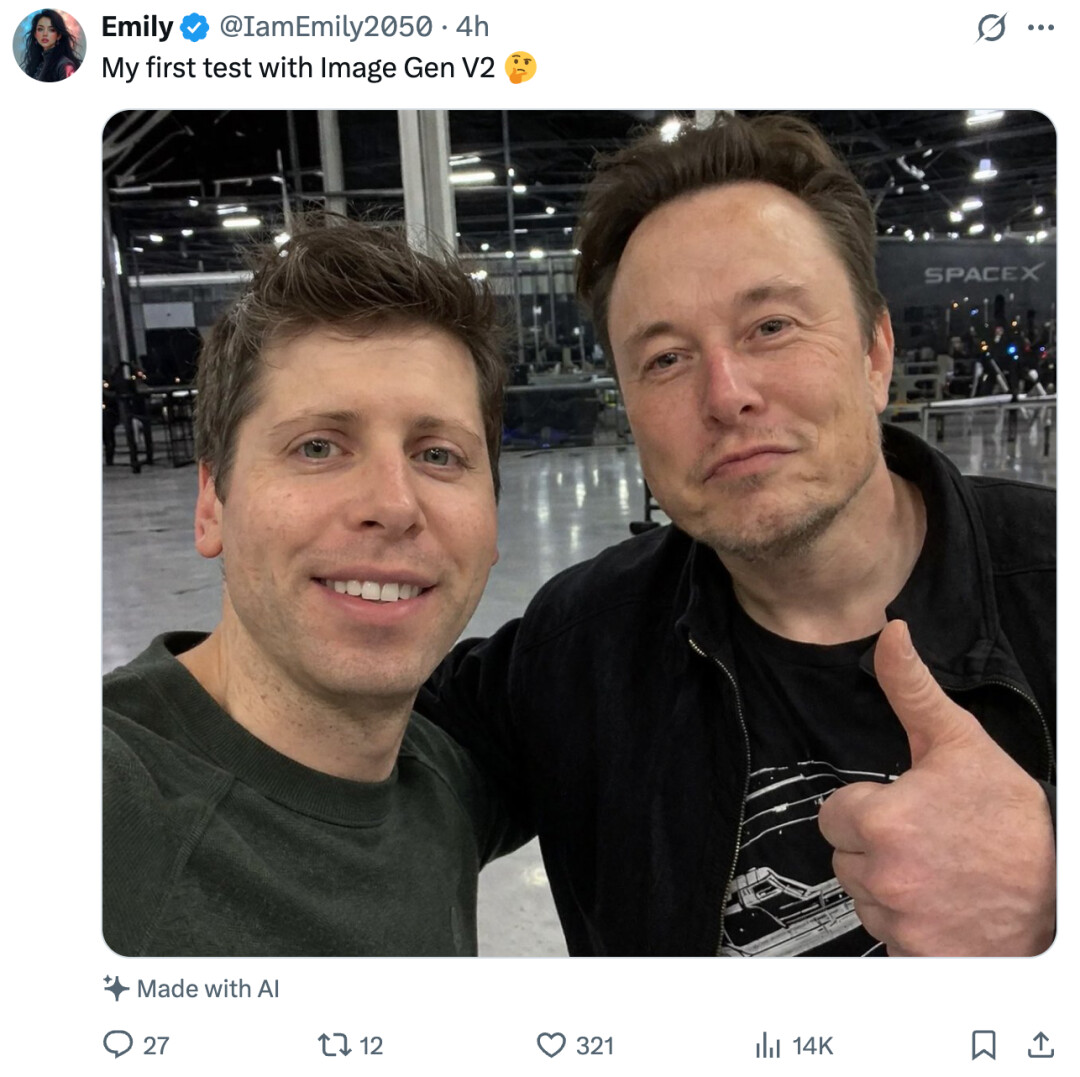
「这个模型在真实感和文字生成能力上表现极其出色,可以说,DeepMind 终于迎来了真正意义上的竞争对手。接下来几个月,很期待看看它与 Nano Banana Pro 2 的正面对比表现会如何。」

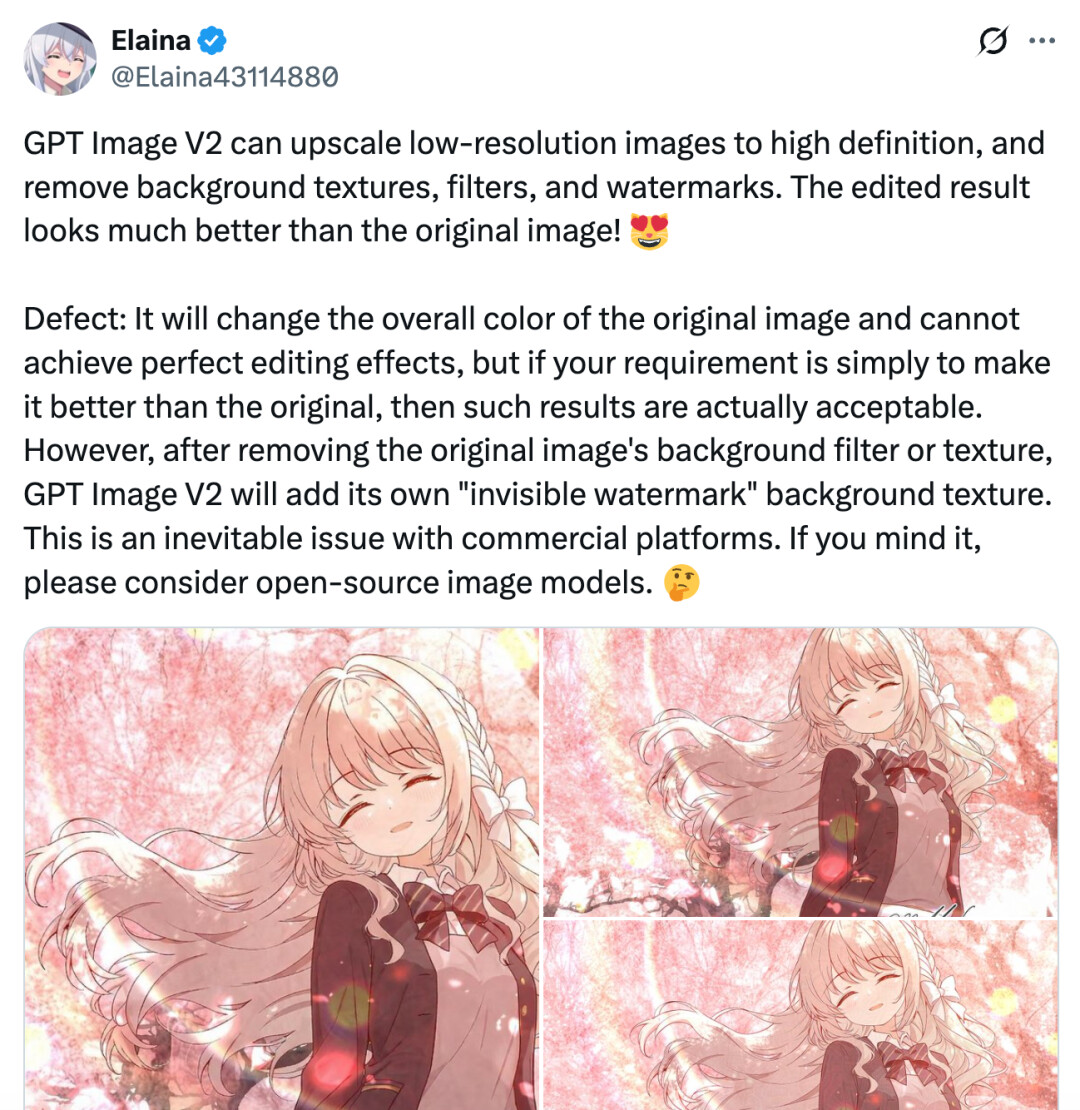
「GPT-Image-2 可以将低分辨率图片提升为高清效果,同时还能去除背景纹理、滤镜以及水印等干扰元素。经过处理后的图像质量明显优于原图,整体观感有了显著提升。」
已经开始期待正式版登场了。
参考链接:
https://x.com/kimmonismus/status/2040338389526822933
https://x.com/mark_k/status/2040353421052551483
https://x.com/minchoi/status/2040419534507512306
https://x.com/marmaduke091/status/2040338311873515597

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com