Karpathy提出LLM Wiki:让Agent持续整理、维护并增强可生长的结构化知识库。
原文标题:Karpathy知识库「LLM Wiki」火爆了,全网围观讨论
原文作者:机器之心
冷月清谈:
这一体系大致分为三层:原始资料层、由 LLM 维护的 wiki 层,以及约束工作流程和结构规范的 schema 层。原始资料只读不改;wiki 由模型生成摘要、实体页、概念页和交叉链接;schema 则负责把通用模型变成“有纪律的知识库维护者”。
文章重点介绍了三类操作:一是 ingest,把新资料读入后整合进现有知识体系;二是 query,围绕 wiki 提问,并可将高质量回答反写回知识库;三是 lint,定期检查矛盾、过时结论、孤立页面和信息缺口。这样一来,知识不是每次问答都从零开始,而是在使用中不断沉淀和增强。
Karpathy认为,这种模式更像一种人机协作管理知识的元框架,适用于个人记录、研究学习、读书整理、团队内部 wiki 等场景。它强调长期积累、结构化组织和持续演化,也提出了一个值得关注的方向:未来知识可能不仅存在于上下文中,还会逐步通过合成数据与微调内化进模型。
怜星夜思:
2、问题2:把知识库交给LLM持续维护,最大的风险是“幻觉”还是“错误被长期固化”?你会怎么防?
3、问题3:文章里提到中等规模下未必需要传统RAG,只靠索引和摘要也能支撑检索与推理。你认同吗?
4、问题4:如果把“LLM Wiki”用在团队或企业内部,最难落地的环节会是什么?
原文内容
还记得前几天,AI 领域知名学者 Andrej Karpathy 做客一档节目时,半开玩笑地提到:token 用不完会让人焦虑,就像患上了某种「」。
这句话当时听起来有点夸张,但当你仔细看他最近在做的一系列东西,会发现他确实在用 AI 不断试各种路径。
就在近日,Karpathy 构建的 LLM 知识库「LLM Wiki」爆火,在社区迅速传播,引发大量讨论。

就连 Karpathy 自己都忍不住自夸一句:哇,我这条推文真的火爆了!
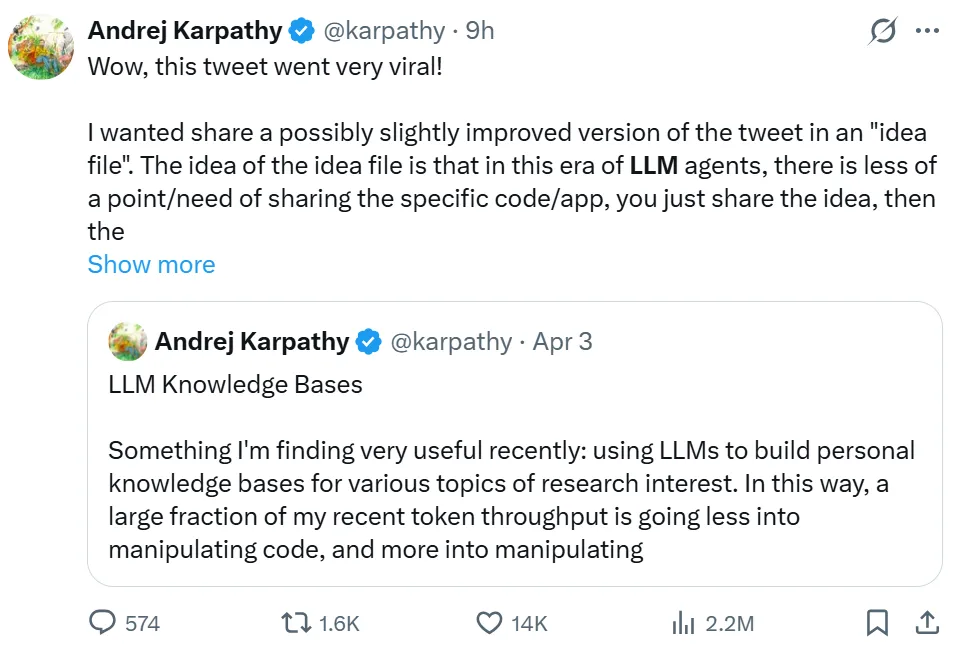
这条爆火的推文介绍了「LLM Wiki」的构建思路。Karpathy 表示,他把最近的想法稍微整理、优化了一下,然后用一个「idea file」的形式分享出来。在 LLM agent 时代,分享具体代码或应用的意义正在变弱,现在只需要分享想法,然后把它交给 Claude、Grok 等 Agent,它就可以根据你的需求,自动搭建一个属于你自己的个人知识库。
Karpathy 把这个想法整理成 gist 形式进行分发:你可以把它交给你的 agent,它会帮你构建一个属于你自己的 LLM wiki,并指导你如何使用等等。
地址:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
这个思路可以说是有点超前,在 Agent 时代,这意味着我们已经不需要再分享具体代码或应用了!只需要把「想法」交给对方的 Agent,让它根据你的需求自动完成定制和实现!
有观点认为,这不只是一个 AI 工具,而更像是一种元框架(meta-framework)。它并不依赖某个具体模型或技术栈,而是在尝试定义一种人类与 AI 协作管理知识的方式。随着模型不断迭代、框架持续演进,让 LLM 帮助编译并维护一个持续生长的 Wiki 这一模式,反而具备更长期的稳定性和适用性。
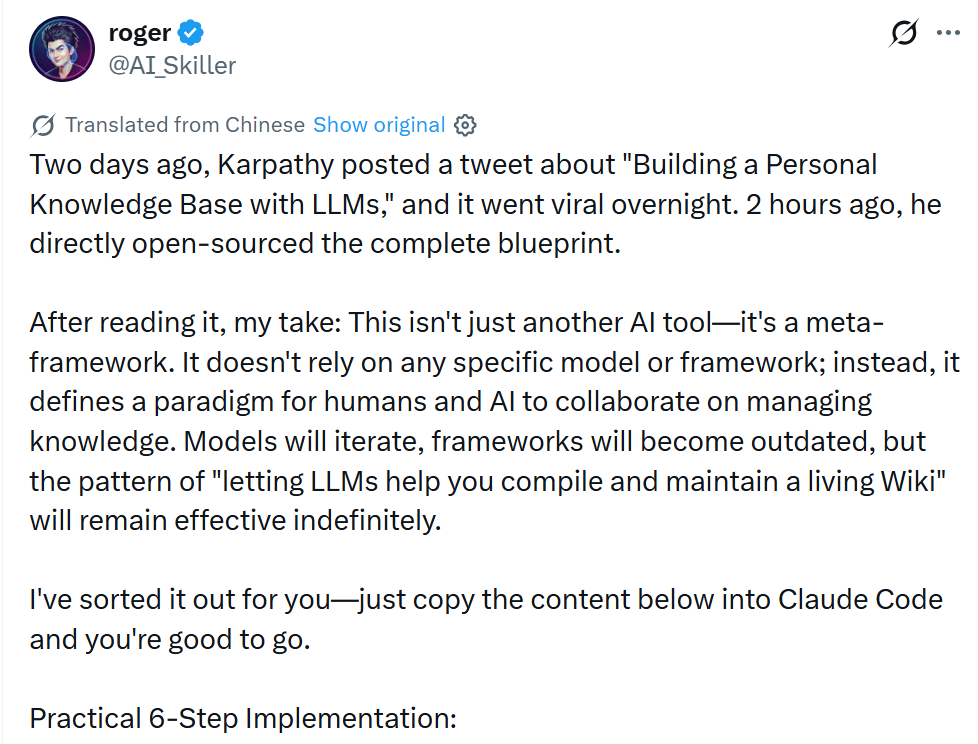
还有观点将这套「LLM Wiki」的工作方式梳理成一个更清晰的闭环,方便大家理解其核心逻辑:
-
将原始资料(论文 / 文章 / 代码 / 图片等)整理到 raw/ 目录中
-
由 LLM 将其编译为一个结构化的 wiki(包含 .md 文件、反向链接以及概念分类)
-
使用 Obsidian 作为前端进行浏览
-
当 wiki 达到一定规模(他的案例是:100 篇文章、40 万字)后,可以直接围绕整个 wiki 提出复杂问题
-
将每一次问答的输出重新归档回 wiki—— 这一点我认为是核心;知识库会随着使用不断变强
-
由 LLM 定期进行健康检查:发现矛盾数据、补全缺失信息、挖掘新的研究方向
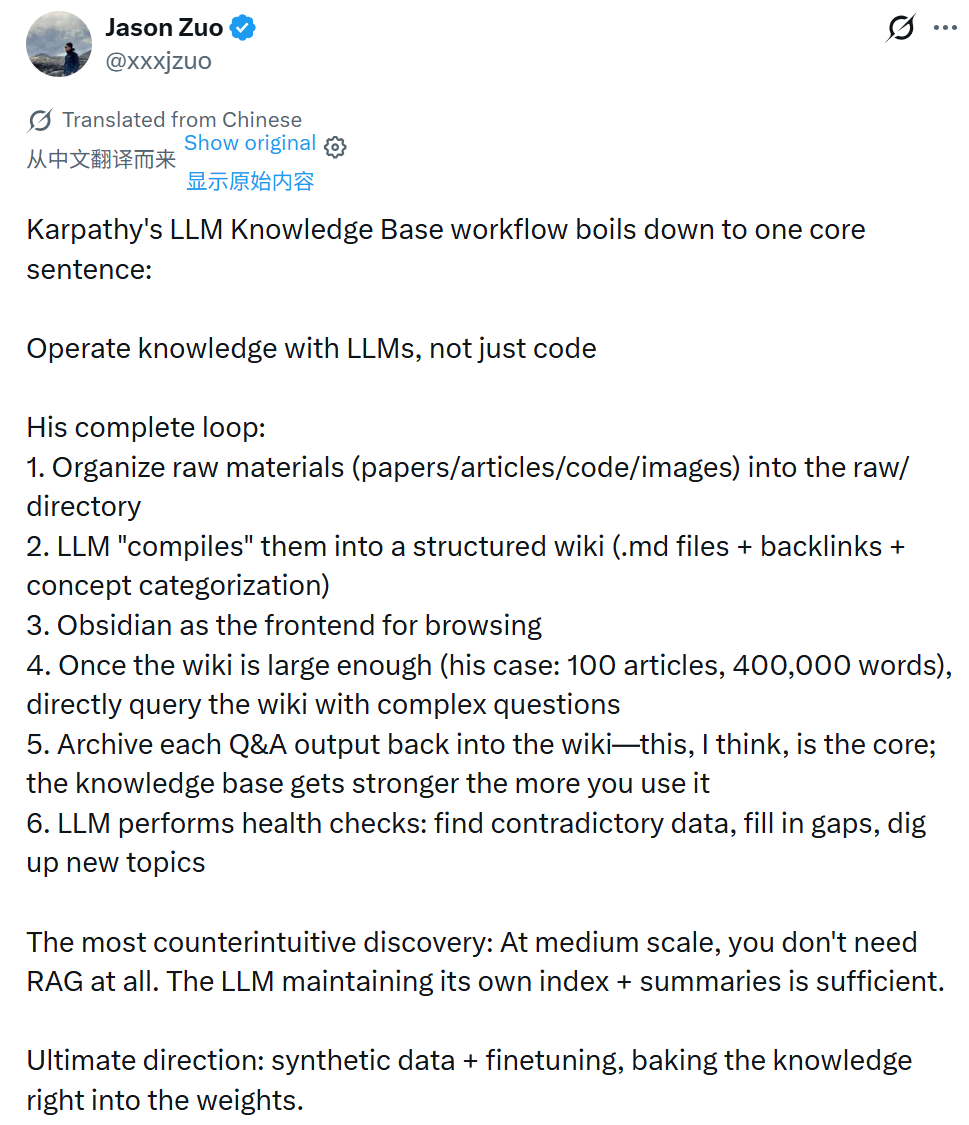
在这一过程中,一个颇具启发性的判断是:在中等规模下,这套体系并不依赖传统意义上的 RAG。只要 LLM 能够维护好索引和摘要,就已经可以支撑起有效的检索与推理。
进一步看,这一思路的延伸方向也逐渐清晰,通过合成数据与微调,将知识逐步内化进模型权重,而不再仅仅依赖上下文窗口进行调用。
从这个角度来看,这已经不只是一个使用技巧,而是在逼近一种自我增强的知识系统形态,也可以被视为一个具备产品潜力的雏形。
为何要构建「LLM Wiki」
Karpathy 表示,大多数人使用 LLM 处理文档的方式,基本都类似于 RAG:你上传一组文件,模型在查询时检索相关片段,然后生成答案。
这种方式是有效的,但问题在于每一次提问,模型都在从零重新发现知识。没有积累。如果你问一个需要综合五篇文档的复杂问题,模型每次都要重新去找相关片段,再拼接起来。没有任何东西被沉淀下来。像 NotebookLM、ChatGPT 文件上传,以及大多数 RAG 系统,基本都是这种模式。
「LLM Wiki」提出的是一种不同的思路,不是在查询时直接从原始文档中检索,而是让 LLM 逐步构建并维护一个持续存在的 wiki,一个结构化、相互链接的 Markdown 文件集合,作为你和原始资料之间的中间层。
当你添加新的资料时,模型不只是简单地索引以备后用,而是会真正去阅读它,提取关键信息,并将其整合进现有的 wiki:更新实体页面、修订主题总结、标记新信息与旧结论之间的冲突,对整体认知进行强化或修正。知识被编译一次,并持续更新,而不是在每次查询时重新推导。
用 Karpathy 的话来说,这个 wiki 是一个持续存在、不断累积的产物。交叉引用已经提前建立,矛盾已经被标注,综合结论已经反映了你读过的所有内容。随着你不断加入新资料、提出新问题,这个 wiki 会持续变得更丰富。
你几乎不需要(或者很少需要)亲自去写这个 wiki,所有内容都由 LLM 来生成和维护。你负责的是提供资料、进行探索、提出问题;而模型负责所有苦活:总结、建立关联、归档整理、维护结构,让知识库随着时间真正变得有用。在实际使用中,通常是一边打开 LLM agent,一边打开 Obsidian:模型根据对话不断修改内容,而你可以实时浏览结果,点开链接、查看知识图谱、阅读更新后的页面。
这么说吧,Obsidian 是 IDE,LLM 是程序员,wiki 是代码库。
「LLM Wiki」是如何构建的?
这个系统可以分为三个层次:
原始数据:这是你整理好的原始资料集合,包括文章、论文、图片、数据文件等。这一层是不可变的:LLM 只读取它们,但不会对其进行任何修改,这是整个系统的事实来源。
Wiki 层(The wiki):一个由 LLM 生成的 Markdown 文件目录,包含摘要、实体页面、概念页面、对比分析、整体概览以及综合性总结等内容。这一层完全由 LLM 负责:它会创建页面,在新增资料时更新内容,维护交叉引用,并保证整体一致性。你负责阅读它;LLM 负责编写和维护它。
Schema 层(The schema):一份指导性文档(例如给 Claude Code 用的 CLAUDE.md,或给 Codex 用的 AGENTS.md),用于告诉 LLM:这个 wiki 的结构是什么、遵循哪些规范,以及在处理数据(ingest)、回答问题、维护内容时应采用什么样的工作流程。
这是整个系统的关键配置文件,正是它让 LLM 从一个通用聊天模型,变成一个有纪律的 wiki 维护者。随着你在具体领域中不断实践,这一层也会与你和 LLM 一起持续演化、不断优化。
操作(Operations)
数据摄取(Ingest):你将新的资料加入到原始数据集合中,并让 LLM 对其进行处理。一个典型流程是:LLM 读取资料,与你讨论关键要点,在 wiki 中写出一篇摘要页面,更新索引,同时更新整个 wiki 中相关的实体页和概念页,并在日志中追加一条记录。一个来源往往会影响 10–15 个 wiki 页面。Karpathy 个人更倾向于一次处理一个来源,并保持参与,他会阅读摘要、检查更新,并引导 LLM 强调重点。但你也可以选择批量导入多个来源,减少监督。最终,你可以形成一套适合自己风格的工作流,并将其记录在 schema 中,供后续使用。
查询(Query):你可以围绕 wiki 提出问题。LLM 会搜索相关页面,阅读内容,并综合生成带引用的回答。回答形式可以根据问题而变化,可以是一个 Markdown 页面、一个对比表、一份幻灯片(Marp)、一张图表(matplotlib),甚至是一个画布(canvas)。关键的一点是:好的回答可以被重新归档进 wiki,成为新的页面。无论是一次对比分析、一段推理,还是你发现的一条关联,这些内容都具有价值,不应该消失在聊天记录里。通过这种方式,你的探索会像导入的资料一样,在知识库中持续积累。
质量检查(Lint):可以定期让 LLM 对 wiki 进行健康检查。重点包括:页面之间是否存在矛盾;是否有被新资料取代的过时结论;是否存在没有入链的孤立页面;是否有被提及但尚未建立页面的重要概念;是否缺少交叉引用;是否存在可以通过网页搜索补充的数据空缺。LLM 也很擅长提出新的研究问题和建议新的信息来源。这一过程可以帮助 wiki 在不断扩展的同时,保持结构清晰和内容一致。
「LLM Wiki」应用场景
这种方式可以应用在很多不同场景中,例如:
个人层面:记录你的目标、健康、心理状态、自我成长过程,整理日记、文章、播客笔记,逐步构建一个关于你自己的结构化认知。
研究场景:围绕某个主题深入数周甚至数月,阅读论文、文章、报告,逐步构建一个不断演化的完整知识体系和核心观点。
读书场景:随着阅读进度整理每一章内容,建立人物、主题、情节线索之间的关联页面。读完之后,你会得到一个丰富的配套 wiki。可以类比像 Tolkien Gateway 这样的维基,由社区多年构建的、包含人物、地点、事件、语言等内容的庞大知识网络。现在,你可以在阅读过程中个人构建类似系统,由 LLM 完成所有的关联和维护。
企业 / 团队:一个由 LLM 维护的内部 wiki,持续接入 Slack 对话、会议记录、项目文档、客户沟通等信息,必要时由人工参与审核更新。由于维护工作由模型承担,这个 wiki 能够保持实时更新,而不再依赖团队成员额外投入精力。
竞品分析、尽职调查、旅行规划、课程笔记、兴趣深度研究,任何需要长期积累知识、并希望其被系统化组织而不是零散分布的场景,都可以采用这种模式。
最后,Karpathy 还强调了,关于「LLM Wiki」,他只是提供了一种思路,而不是一个具体实现。具体的目录结构、schema 规范、页面格式以及工具链,都会取决于用户使用场景、个人偏好以及所选择的 LLM。
上面提到的所有内容都是可选且模块化的,有用的就用,不合适的可以忽略。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com