Claude Code 团队分享智能体工具设计经验:工具要匹配模型能力,并随模型进化持续调整。
原文标题:构建Claude Code的经验教训:从智能体的视角观察
原文作者:AI前线
冷月清谈:
文中以 AskUserQuestion 工具为例,说明结构化提问能力需要通过实验逐步打磨:直接在计划工具中加问题会让模型混淆,单靠输出格式约束又不稳定,最终独立工具更适合承载用户交互。
在任务管理上,Claude Code 早期依赖 TodoWrite 和系统提醒帮助模型保持目标,但随着模型能力提升,固定待办事项反而可能限制模型调整计划。因此团队改用更灵活的任务工具,支持依赖关系、子智能体协作和动态更新。
搜索能力方面,文章强调让模型主动构建上下文的重要性。从 RAG 到 Grep,再到技能和渐进式披露,Claude 逐渐具备了自主探索代码库和文档的能力。对于不常用的信息,团队更倾向通过子智能体或文档检索按需提供,而不是塞进系统提示。
作者最后指出,智能体工具设计没有固定公式,需要持续观察模型行为、反复实验,并随着模型能力变化不断修正工具假设。
怜星夜思:
2、文章里说模型能力提升后,原来的工具可能会变成限制。你在实际使用 AI 编程工具时有这种感觉吗?
3、让智能体自己搜索代码库,比直接把 RAG 检索结果塞给它更好吗?
4、AskUserQuestion 这种“专门提问”的工具,会不会让智能体变得太依赖用户确认?
原文内容

构建智能体工具带中最困难的部分之一是构建其动作空间。
Claude 通过工具调用来执行操作,但是在 Claude API 中有很多方法可以使用原语,比如 bash、skills 和最近添加的代码执行来构造工具(阅读 @RLanceMartin 的新文章,了解更多关于 Claude API 的编程工具调用)。
考虑到所有这些选项,你如何设计智能体的工具?你是否只需要一个像代码执行或 bash 这样的工具吗?如果你有 50 个工具,每个工具对应一个智能体可能遇到的用例,那会怎么样?
为了将自己置于模型的思维中,我喜欢想象被给予一个困难的数学问题。你想用什么工具来解它?这要看你自己的技术了!
纸张是最基本的,但你将受限于手动计算。计算器会更好,但你需要知道如何操作更高级的选项。最快和最强大的选择是计算机,但你必须知道如何使用它来编写和执行代码。
这是一个设计智能体的有用框架。你想给它提供适合它自身能力的工具。但你怎么知道这些能力是什么呢?你要集中注意力,阅读它的输出,进行实验。你要学着像智能体一样看问题。
以下是我们在构建 Claude Code 时从关注 Claude 中学到的一些经验教训。
改进 Elicitation 和
AskUserQuestion 工具
在构建 AskUserQuestion 工具时,我们的目标是提高 Claude 提问的能力(通常称为启发)。
虽然 Claude 可以直接问问题,但我们发现回答这些问题似乎花费了不必要的时间。我们怎样才能降低这种摩擦,增加用户和 Claude 之间的交流带宽呢?
我们首先尝试的是向 ExitPlanTool 添加一个参数,以便在计划旁边放置一系列问题。这是最容易实现的事情,但这让 Claude 感到困惑,因为我们同时要求制定一个计划,并提出一系列关于计划的问题。如果用户的回答与计划内容相冲突怎么办?Claude 需要调用 ExitPlanTool 两次吗?我们需要另一种方法。
(你可以在我们关于提示缓存的文章中阅读更多关于我们为什么 要创建 ExitPlanTool 的信息)
接下来,我们尝试修改 Claude 的输出指令,以使用稍微修改的 markdown 格式来提问。例如,我们可以要求它输出一个带有括号中替代选项的要点问题列表。然后,我们可以解析该问题并将其格式化为用户的 UI。
虽然这是我们能做的最通用的更改,Claude 甚至似乎能够很好地输出这个,但这并不能保证。Claude 会附加额外的句子,省略选项,或者完全使用不同的格式。
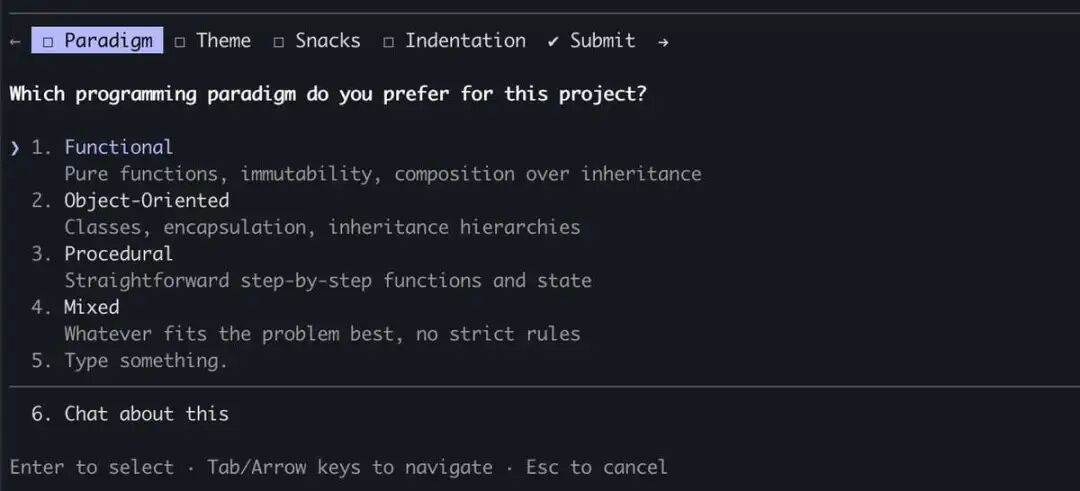
最后,我们决定创建一个 Claude 可以在任何时候调用的工具,但特别提示在计划模式期间这样做。当工具触发时,我们会显示一个模态框来显示问题,并阻止智能体的循环直到用户回答。
这个工具允许我们提示 Claude 进行结构化输出,并帮助我们确保 Claude 给用户提供多个选项。它还为用户提供了组合此功能的方法,例如在代理式 SDK 中调用它或在技能中引用它。
最重要的是,Claude 似乎很喜欢调用这个工具,我们发现它的输出效果很好。即使是最好的设计工具,如果 Claude 不知道如何调用它,也是行不通的。
这是 Claude Code 中启发的最终形式吗?我们不确定。正如你将在下一个例子中看到的,适用于一个模型的方法可能不适用于另一个模型。
当我们第一次发布 Claude Code 时,我们意识到模型需要一个待办事项列表来保持它的正常运行。可以在开始时编写待办事项,并在模型工作时进行检查。为此,我们给了 Claude TodoWrite 工具,它可以编写或更新待办事项并将其显示给用户。
但即便如此,我们也经常看到 Claude 忘记了它的职责。为了适应这种情况,我们每 5 个回合就会插入系统提醒,提醒 Claude 它的目标。
但随着模型的改进,它们不仅不需要被提醒待办事项列表,而且还会发现它的局限性。收到待办事项清单的提醒使 Claude 认为它必须坚持而不是修改它。我们还看到 Opus 4.5 在使用子智能体方面做得更好,但是子智能体如何在共享的待办事项列表进行协调呢?
看到这一点,我们用任务工具代替了 TodoWrite(阅读更多 关于任务的内容)。待办事项的作用是保持模型的正常运行,而任务的作用更多的是帮助智能体相互沟通。任务可以包括依赖关系,在子智能体之间共享更新,模型可以更改和删除它们。
随着模型功能的增加,你的模型曾经需要的工具现在可能会限制它们。重要的是要不断地回顾之前关于需要什么工具的假设。这也是为什么坚持支持一小组具有相当相似的功能配置文件的模型是有用的。
对 Claude 来说,一组特别重要的工具是搜索工具,可以用来构建自己的上下文。
当 Claude Code 首次推出时,我们使用了一个 RAG 向量数据库来查找 Claude 的上下文。虽然 RAG 功能强大且速度快,但它需要索引和设置,并且在许多不同的环境中可能很脆弱。更重要的是,Claude 被赋予了这个上下文,而不是自己找到上下文。
但如果 Claude 能在网络上搜索,为什么不搜索你的代码库呢?通过给 Claude 一个 Grep 工具,我们可以让它自己搜索文件和构建上下文。
这是我们看到的一个模式,随着 Claude 变得越来越聪明,如果给它合适的工具,它就会越来越善于构建它的环境。
当我们引入智能体技能时,我们正式定义了渐进式披露的概念,它允许智能体通过探索逐步发现相关的上下文。
Claude 可以读取技能文件,然后这些文件可以引用模型可以递归读取的其他文件。事实上,技能的一个常见用途是为 Claude 添加更多的搜索功能,比如告诉它如何使用 API 或查询数据库。
在一年的时间里,Claude 从不能真正建立自己的上下文,到能够在几层文件中进行嵌套搜索,以找到它所需要的确切上下文。
渐进式披露现在是我们在不添加工具的情况下添加新功能的常用技术。
Claude Code 目前有大约 20 个工具,我们不断地问自己是否需要所有这些工具。添加新工具的门槛很高,因为这给模型提供了更多的选择。
例如,我们注意到 Claude 对如何使用 Claude Code 了解不够。如果你问它如何添加 MCP 或者斜杠命令的作用,它将无法回答。
我们本可以将所有这些信息放在系统提示中,但考虑到用户很少询问这些信息,这将增加上下文的腐朽并干扰 Claude Code 的主要工作:编写代码。
相反,我们尝试了一种渐进披露的形式。我们给了 Claude 一个文档的链接,他可以下载这个链接来搜索更多的信息。这是有效的,但我们发现 Claude 会把很多结果放到上下文中来找到正确的答案,而你真正需要的只是答案。
因此,我们构建了 Claude Code 指南子智能体,当你询问它自己时,Claude 会被提示调用,子智能体有关于如何很好地搜索文档以及返回什么内容的大量说明。
虽然这不是完美的,Claude 仍然会感到困惑,当你问它如何设置自己,它是比以前好得多!我们能够在不添加工具的情况下向 Claude 的动作空间添加东西。
如果你希望有一套关于如何构建工具的严格规则,很遗憾,这不是本指南。为模型设计工具既是一门科学,也是一门艺术。这在很大程度上取决于你正在使用的模型,智能体的目标以及它所处的环境。
经常实验,阅读你的成果,尝试新事物。像一个智能体一样看待问题。
原文链接:
https://x.com/trq212/status/2027463795355095314

