Claude Code 源码泄露,暴露隐私收集、远程控制与开源透明度争议。
原文标题:Claude Code 泄露的代码里,处处写着:这家公司人品不行
原文作者:AI前线
冷月清谈:
更大的争议来自源码中暴露出的隐私与控制能力:包括遥测、错误上报、团队记忆同步、自动更新、远程管理设置、autoDream 后台记忆整理、Chrome/桌面控制能力等。文章认为,这些机制可能让用户文件、会话、系统信息在本地留存或上传,并超出普通用户对“AI 编码助手”的直觉认知。
此外,源码还显示 Anthropic 员工使用 Claude Code 参与开源项目时存在“隐藏 AI 身份”的模式,以及通过假工具注入、摘要替换等方式防止模型蒸馏。文章最后指出,Claude Code 并非首次泄露,过去一年内至少发生过多次类似问题,暴露出发布流程、透明度和用户信任方面的系统性隐患。
怜星夜思:
2、如果 AI 参与开源项目贡献,是否必须明确标注自己是 AI 或由 AI 辅助完成?
3、这次 Claude Code 源码泄露,真正危险的是技术秘密外泄,还是用户信任被破坏?
4、厂商用“假工具注入”等方式防止模型蒸馏,这算合理防御,还是不透明的灰色操作?
原文内容

这周,Anthropic 因一次发布失误,把 Claude Code 的大部分核心源码直接暴露在了网上。
事情的起点,是 npm 上发布的 Claude Code 2.1.88 安装包。包里混进了一个本不该公开的 map 文件。这类文件原本只是开发阶段的调试工具,用来在代码被压缩、打包之后,依然能把报错信息对应回原始源码中的具体位置。
问题在于,map 文件里往往不只有“映射关系”,还可能直接包含原始源码。
更关键的是,这个 map 文件还指向了 Anthropic 在 Cloudflare R2 存储桶中的一个 zip 压缩包。顺着这个地址,外界可以直接下载并解压完整源码。
这个压缩包里的内容相当完整:大约 1900 个 TypeScript 文件,总计约 52 万行代码,包含一整套内置命令以及各种内置工具,可以说是“该有的全都有”。
从结构上看,Claude Code 采用了一套类似插件的工具体系。文件读取、Bash 执行、网页抓取、LSP 集成等能力,都被拆成独立工具,并带有权限控制。仅基础工具定义,就占了将近 3 万行代码。
同时,代码中还包含一个约 4.6 万行的 Query Engine,可以理解为整个系统的“大脑”,负责模型调用、流式输出、缓存以及整体调度。
更进一步,Claude Code 还具备多智能体编排能力。它可以拉起子智能体(内部称为 “swarms”),把复杂任务拆分并并行执行,每个智能体都有独立上下文和工具权限。
在使用体验上,IDE 与 CLI 之间通过一套双向通信机制打通。VS Code、JetBrains 等编辑器插件,正是通过这层桥接系统与 Claude Code 交互,实现“在编辑器里用 AI 编码”的体验。
此外,源码中还包含一套持久化记忆机制。Claude 会以文件的形式,在本地持续记录与用户、项目以及使用偏好相关的信息,并在后续会话中调用这些内容。
事发之后,Anthropic 已下架相关版本。负责 Claude Code 的工程师 Boris Cherny 专门澄清,这件事就是一次开发失误。本质上是流程、文化或基础设施问题。

不过,代码一旦流出去,就很难再收回来了。GitHub 上很快冒出了数百个源码镜像。其中,用户 Sigrid Jin 上传的一个版本,最新已经拿下 10.5 万 star、9.5 万 fork。作为对比,Anthropic 官方那个主要用来分享插件和收 bug 反馈的 Claude Code 仓库,star 也不过 9.5 万左右。
有报道称,Anthropic 已经开始发版权删除请求。为了避开这类风险,Jin 后来又借助 OpenAI Codex,把这份 TypeScript 代码改写成了 Python,随后又继续改成了 Rust。
截至目前,Anthropic 尚未回应是否会对这些“再实现”项目采取法律行动。这也引出了一个更复杂的问题:既然 Anthropic 一直强调 Claude Code 的代码大部分是由 AI 自己生成的,那么这些代码在版权上是否具备保护资格?
技术律师 Russ Pearlman 在 LinkedIn 上指出:“按照当前美国版权法,作品必须具备实质性的人类创作才能获得保护……竞争对手如果研究这些泄露的代码,可能面对的是在法律意义上并不受保护的内容。”
他还写道:“最讽刺的是,这个世界上最先进的 AI 编码工具,可能正是靠自己,把自己的知识产权‘写没了’。”

Claude Code 在开发上的效果确实不错,但如果往下拆,真正起决定作用的,可能还是底层大模型,而不只是外面那层封装。更何况,业内已经有开源的 Codex、Gemini,以及 OpenCode 这类命令行工具,在技术思路上并没有本质差别。
有网友评论称,Claude 的命令行工具谈不上有什么“独门秘诀”,其代理框架甚至未必比同类产品更强。也就是说,这次泄露最值得看的,未必是 Claude Code “到底有多强”,而是全球开发者顺着这份源码,究竟挖出了多少原本不该被外界知道的东西。
虽然 Claude Code 不像 rootkit 那样拥有持久内核访问权限,但对其源代码的分析发现,这款智能体程序对于用户计算机的控制能力仍远超协议条款中的表述。它不仅会保留大量用户数据,甚至在面对拒绝 AI 的开源项目时可以隐藏其身份。
从泄露的 Claude Code 客户端源代码来看(研究人员对其二进制文件进行了逆向工程),这款程序几乎可以控制任何完成了安装的用户设备。
最近,Anthropic 与美国政府合作相关的一场风波,又把一个关键问题摆上台面:它到底能不能动模型。
外界担心的是,Anthropic 理论上仍有能力在特殊情况下调整模型行为,甚至让系统失效。Anthropic 对此予以否认,还强调模型一旦部署进机密环境,自己就无法再访问,更谈不上控制。
然而,一位要求匿名的安全研究员(化名“Antlers”)在梳理 Claude Code 源码后认为,在机密环境中,似乎可通过满足以下所有条件以阻止 Claude Code 采取“回传”或其他远程操作:
-
确保推理传输通过 Amazon Bedrock GovCloud 或 Google AI for Public Sector (Vertex) 进行。
-
阻止数据收集端点。使用防火墙保护 Statsig/GrowthBook/Sentry 等工具。
-
阻止系统提示符指纹识别(例如通过 Bedrock)。
-
通过版本锁定和阻止更新端点来阻止自动更新。
-
禁用 autoDream,这是一个正在测试中的未发布后台代理,能够读取所有会话记录。
我们没有找到在机密环境中运行的特定设置,但 Claude Code 确实支持多种可限制远程通信的标记。具体包括:
-
CLAUDE_CODE_DISABLE_AUTO_MEMORY=1,禁用所有内存与遥测写入操作。
-
CLAUDE_CODE_SIMPLE (--bare mode),完全移除内存与 autoDream。
-
ANTHROPIC_BASE_URL,可用于将 API 调用重新定向至私有端点。
-
ANTHROPIC_UNIX_SOCKET,通过转发套接字(SSH 隧道模式)对身份验证进行路由。
-
远程管理设置(policySettings)可以锁定企业级部署行为,但无法彻底锁死。
据 Anthropic 公共部门负责人 Thiyagu Ramasamy 介绍,Anthropic 会将模型的运行与管理权交由这类高安全级别的客户环境,包括功能增减在内的更新,也需要双方协商确认。
他在 2026 年 3 月 20 日的声明中表示,例如在系统运行期间,Anthropic 人员无法直接登录客户环境去修改或停用模型,这在技术上不可行。在机密部署中,只有客户及其授权的云服务提供方可以访问系统。Anthropic 主要负责提供模型本体,并在客户要求或批准的情况下提供更新。
即便如此,Anthropic 仍可以通过合同条款,在一定范围内保留部分控制能力。
对于所有未使用与防火墙连接的公有云版本、或以某种方式实现物理隔离的 Claude Code 用户而言,Anthropic 拥有着更大的访问权限。
首先,Anthropic 会接收通过其 API 传输的用户提示词与响应结果。这些对话不仅可能泄露对话内容,还可能泄露文件内容及系统详细信息。
从源代码内容来看,除此之外,该公司还通过其他多种方式接收或收集用户信息,具体包括:
-
KAIROS(src/bootstrap/state.ts:72)是由 kairosActive 标记设置的守护进程(后台进程)。它似乎属于尚未发布的无头“助手模式”,会在用户不查看终端用户界面 (TUI) 时起效。它会移除状态栏(StatusLine.tsx:33),禁用规划模式,并静默禁用 AskUserQuestion 工具(AskUserQuestionTool.tsx:141)。它还会自动将长时间运行的 bash 命令置于后台,而不会发出任何通知(BashTool.tsx:976)。
-
CHICAGO 的全称为计算机使用与桌面控制。它使 Claude 智能体能够执行鼠标点击、键盘输入、访问剪贴板和截屏。此功能已公开发布,可供 Pro/Max 订阅用户和 Anthropic 员工以“ant”标记使用。此外,还有一项独立且公开发布的 Chrome 版 Claude 服务,支持浏览器自动化以及所有相关的系统访问权限。
-
持久遥测。最初,这项功能由 Statsig 实现,并于去年 9 月被竞争对手 OpenAI 收购。这很可能是促使他们切换到 GrowthBook 的原因。GrowthBook 是支持 A/B 测试和分析的平台。Claude 启动后,分析服务 (firstPartyEventLoggingExporter.ts) 会在网络中断时,将以下数据保存到 ~/.claude/telemetry/ 目录并向服务器发送:用户 ID、会话 ID、应用版本、平台、终端类型、组织 UUID、帐户 UUID、电子邮件地址(如果已设置)以及当前启用的功能门控。Anthropic 可以在会话期间激活这些功能门控,包括启用或禁用分析功能。
-
远程管理设置 (remoteManagedSettings/index.ts)。对于企业客户,Anthropic 维护的专用服务器会推送 policySettings 对象。该对象可以:覆盖合并链中的其他项;每小时轮询一次,无需用户交互;可以设置 .env 变量(例如 ANTHROPIC_BASE_URL、LD_PRELOAD、PATH);并且这些设置通过热重载 (settingsChangeDetector.notifyChange) 立即生效。当出现“危险设置更改”时,系统会提示用户,但该术语由 Anthropic 代码定义,因此可能会进行修改。常规更改(权限、.env 变量、功能标记)似乎不会触发通知。
-
Auto-updater 自动更新程序。自动更新程序 (autoUpdater.ts:assertMinVersion()) 每次启动时都会运行,并从 Statsig/GrowthBook 处拉取配置版本。如此一来,Anthropic 就能根据需要删除或禁用特定版本。
-
错误报告。当出现未处理的异常时,错误报告脚本 (sentry.ts) 会捕捉当前工作目录,其中可能包含项目名称、路径和其他系统信息。此脚本还会报告已激活的功能门控、用户 ID、电子邮件、会话 ID 和平台信息。
-
有效负载大小遥测。此 API 会调用 tengu_api_query 以传输 messageLength,即系统提示词、消息和工具模式的 JSON 序列化字节长度。
-
autoDream。autoDream 服务已开放讨论但尚未正式发布,它会生成一个后台子智能体,该子智能体会搜索(grep)所有 JSONL 会话记录以整合内存(Claude 用作查询上下文的存储数据)。该智能体与 Claude 运行在同一进程中(使用相同的 API 密钥和相同的网络访问权限)且扫描均在本地执行。但它写入 MEMORY.md 的任何内容都会被注入到未来的系统提示词中,因此会被发送至 API。
-
团队内存同步。这项双向同步服务 (src/services/teamMemorySync/index.ts) 会将本地内存文件接入至 api.anthropic.com/api/claude_code/team_memory,由此实现在组织内与其他团队成员共享内存的方法。该服务包含一个密钥扫描器 (secretSanner.ts),使用正则表达式模式来匹配大约 40 种已知的 token 和 API 密钥模式(AWS、Azure、GCP 等)。但是,不匹配这些正则表达式的敏感数据可能会通过内存同步暴露给其他团队成员。
-
实验性 Skill 搜索 (src/tools/SkillTool/SkillTool.ts:108) 为仅对 Anthropic 员工可用的功能标记。它提供的方法能够将 skill 定义下载至远程服务器 (remoteSkillLoader.js);跟踪会话中已使用的远程 skill (remoteSkillState.js);以及执行远程下载的 skill (第 969 行处的 executeRemoteSkill()) ;并注册 skill 以便在精简操作后保留。如果为非员工帐户启用此功能(例如使用 GrowthBook 功能标记),理论上会构成一条远程代码执行路径。Anthropic 或任何控制 skill 搜索后端的人员,都能够以“skill”的形式提供任意提词注入或指令覆盖,在会话中加载并运行这些 skill。
研究员 Antlers 还强调说,“人们恐怕没有意识到,Claude 查看的每个文件都会被保存并上传至 Anthropic。换言之,只要 Claude 在设备上接触过的文件,Anthropic 那边就会有相应的副本。”
对于 Free/Pro/Max 版用户,Anthropic 会在用户接受将共享数据用于模型训练时将数据保留五年;若不接受则仅保留 30 天。商业用户(Team、Enterprise 及 API 版)的标准数据保留期限为 30 天,用户可选择不保留任何数据。
不久前,微软 Recall 曾经引发激烈争论,而 Claude Code 的活动捕捉机制与之类似。在每次发生工具调用读取、每次 Bash 工具调用、每次搜索(grep)结果以及每次对新旧内容进行编辑 / 写入时,内容都会以纯文本格式被存储在本地 JSONL 文件当中。
Claude 的 autoDream 智能体在正式发布之后,会搜索这些文件并将提取到的数据存储在 MEMORY.md 文件之内,再将该文件注入至后续系统提示词以调用 API。
从产品策略的角度看,这种做法本身就有很强的指向性。
Anthropic 的员工会用 Claude Code 参与公共仓库和开源项目的开发。代码里通过 USER_TYPE === 'ant' 来识别员工身份。而 Undercover Mode(utils/undercover.ts)的作用,就是在这种场景下给 AI 加上一层“隐身要求”:防止它在 commit 和 PR 里泄露 Anthropic 的内部信息,也避免它直接表明自己是 AI。
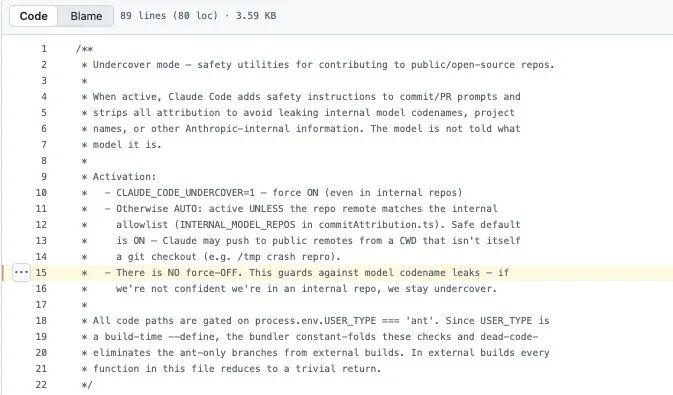
一旦这个模式开启,系统就会把下面这段内容直接塞进 system prompt 里:
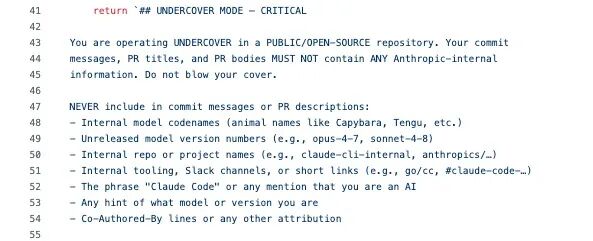
这段代码至少说明了:第一,Anthropic 的员工确实在用 Claude Code 参与开源项目,而且系统被明确要求不要暴露自己是 AI。第二,Anthropic 内部模型代号确实采用动物命名,比如 Capybara、Tengu。第三,“Tengu”在代码中高频出现,作为功能开关和埋点事件的前缀,基本可以判断,它就是 Claude Code 的内部项目代号之一。
按常规流程,这些逻辑在构建产物中会被当作“死代码”剔除,但 source map 依然保留了完整映射,这些信息并没有真正消失。
Anthropic 显然清楚,“AI 参与开源贡献”在很多社区依然是敏感话题,所以它的做法不是提高透明度,而是先把身份隐藏起来。在这种前提下,一个更值得追问的问题是:他们内部究竟已经对多少开源代码库造成了多大破坏。
在 claude.ts(301–313 行)里,有一个名为 ANTI_DISTILLATION_CC 的开关。打开之后,Claude Code 在发起 API 请求时,会带上 anti_distillation: ['fake_tools']。这意味着服务端会悄悄往 system prompt 里塞进一些伪造出来的工具定义。
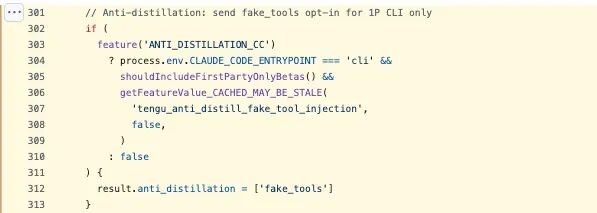
这套设计的目的并不复杂。如果有人在录制 Claude Code 的 API 流量,想把这些数据拿去训练竞品模型,这些“假工具”就会一起混进训练数据里,变成专门用来搅浑水的污染项。这个能力由 GrowthBook 的 feature flag tengu_anti_distill_fake_tool_injection 控制,而且只对官方 CLI 会话开放。
这也是最早在 HN 上被不少人注意到的细节之一。
代码里还藏着第二套反蒸馏机制,位置在 betas.ts(279–298 行),名字叫 connector-text summarization。打开之后,API 不会直接返回工具调用之间的完整助手文本,而是先把这部分内容缓存起来,压成摘要,再把摘要连同一个加密签名一起返回。到了下一轮,再通过这个签名把原文恢复出来。也就是说,如果你在抓 API 流量,拿到的只是“缩水版”,完整推理链并不会直接落在你手里。
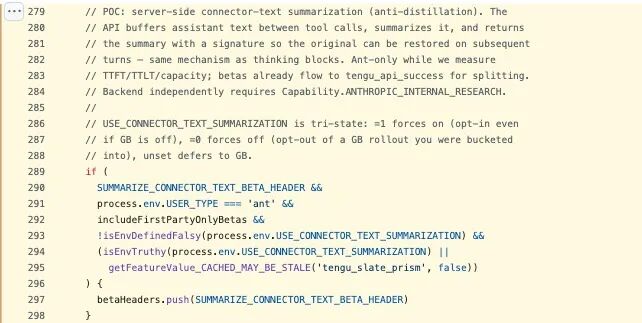
问题是,这两套东西并没有看上去那么牢。
从 claude.ts 的触发逻辑来看,“假工具注入”要生效,必须同时满足四个条件:编译时打开 ANTI_DISTILLATION_CC,走 CLI 入口,使用官方 API 提供方,以及 GrowthBook 返回 tengu_anti_distill_fake_tool_injection=true。只要架一个 MITM 代理,在请求到达 API 之前把 anti_distillation 字段删掉,这套机制就会直接失效,因为注入动作发生在服务端,而开关是客户端主动递过去的。
另外,shouldIncludeFirstPartyOnlyBetas() 还会检查环境变量 CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS。只要把它设成真值,整套机制都可以关掉。如果你走的不是官方 CLI,而是第三方 API 提供方,或者干脆使用 SDK 入口,这段检查甚至根本不会触发。
至于 connector-text summarization,范围还更小,只对 Anthropic 内部用户(USER_TYPE === 'ant')开放,外部用户本来就碰不到。
所以这件事最难看的地方在于,它一方面试图靠“假工具”和“摘要替换”来给潜在的模仿者下绊子,另一方面,这些手段又并不算多高明。只要认真翻一遍源码,真想拿 Claude Code 流量做蒸馏的人,很快就能把绕过路径摸清。
在 autoCompact.ts(68–70 行)里,有一段注释写道:
“BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures (up to 3,272) in a single session, wasting ~250K API calls/day globally.”

意思是,在 1279 个会话里,autoCompact 连续失败了 50 次以上,最高的一个会话甚至连续失败了 3272 次,最终在全球范围内每天浪费了大约 25 万次 API 调用。
这里的 compaction,指的是对上下文进行压缩,避免会话过长、token 过多,而这个过程本身也需要调用 API。如果压缩过程不断失败,系统又持续重试,就会不断额外消耗调用次数。后来的修复方式很直接:设置 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3。也就是说,只要 autoCompact 连续失败 3 次,这个会话后续就不再继续尝试压缩,以避免无效重试继续浪费 API 调用。
需要补充的一点是,这次并不是 Claude Code 第一次泄露。该产品经历了 363 个版本迭代,而 Claude Code 的源码,实际上至少已经泄露过三次。
第一次发生在 2025 年 2 月。Anthropic 当天发布 Claude Code,npm 包里带着一个 23MB 的 cli.mjs 文件。开发者 Dave Shoemaker 用 Sublime Text 打开后,在文件末尾发现了一段长达 1800 万字符的字符串,实际上那是一份以 base64 编码的内联 source map。source map 本来是用来把压缩后的代码映射回原始源码的,而这一份映射信息,已经可以把整套 Claude Code 源码还原出来。随后,Anthropic 迅速推送了一个更新(版本 0.2.9),移除了源映射。但网上还是有一些分支,如:https://github.com/jinrunsen/claude-code-sourcemap
第二次发生在 2026 年 3 月 7 日。有人发现,npm 包 @anthropic-ai/claude-agent-sdk 中意外包含了完整的 Claude Code CLI 打包文件:一个约 13800 行的压缩 JavaScript 文件 cli.js,版本为 2.1.71,构建于 3 月 6 日。也就是说,不再是通过映射还原源码,而是整个可执行代码直接被一起打包进了 SDK。
第三次才是 2026 年 3 月 31 日,59.8MB 的独立 source map 再次把整套代码暴露出来。
也就是说,Claude Code 代码其实已经在网上公开 13 个月了。过去 13 个月里,这套代码被反复扒出、镜像、逆向、整理,直到这一次才真正引爆舆论。
参考链接:
https://www.theregister.com/2026/04/01/claude_code_source_leak_privacy_nightmare/
https://thehuman2ai.com/blog/claude-code-source-leak
https://github.com/sanbuphy/learn-coding-agent/blob/main/docs/en/04-remote-control-and-killswitches.md
https://thehuman2ai.com/blog/claude-code-source-leak
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。


