微软发布三款低价AI模型,性能比肩OpenAI和谷歌,目标是实现AI“完全独立”。
原文标题:跟OpenAI撕破脸、微软喊话要“完全独立”!靠不到10人、 一半GPU用量,推出三款王炸低价模型
原文作者:AI前线
冷月清谈:
怜星夜思:
2、文章中提到微软的模型在 GPU 资源使用上具有优势,你认为这种优势对于 AI 行业的整体发展有什么意义?是否预示着未来 AI 模型的发展方向?
3、微软强调其 AI 模型的训练数据“干净合规”,你认为在 AI 模型训练中,数据合规性有多重要?可能会对模型的性能和应用产生哪些影响?
原文内容

昨日,科技巨头微软旗下研究实验室 Microsoft AI 宣布推出三款基础 AI 模型,可生成文本、语音和图像。目前三款模型均已登陆 Microsoft Foundry,其中转录和语音模型也已在 MAI Playground 中开放使用。
此次发布标志着微软在仍与 OpenAI 保持合作的同时,持续推进构建自有多模态 AI 模型体系,更计划在模型研发上与 OpenAI、谷歌及其他前沿实验室直接竞争。
正面硬刚 OpenAI 和谷歌,
更便宜还更强?
MAI-Transcribe-1 是本次发布的核心产品。据介绍,这款语音转文本模型专为复杂、真实场景下的世界级转录质量而设计,可将全球使用量最高的 25 种语言的语音转录为文本,说话人分离、上下文定向优化与流式转写功能均标注为 “即将推出”。根据微软的基准测试结果,该模型在全部 25 种语言上优于 OpenAI 的 Whisper-large-v3,在 22 种语言上超过谷歌 Gemini 3.1 Flash,并分别在 15 种语言上领先 ElevenLabs 的 Scribe v2 与 OpenAI 的 GPT-Transcribe。
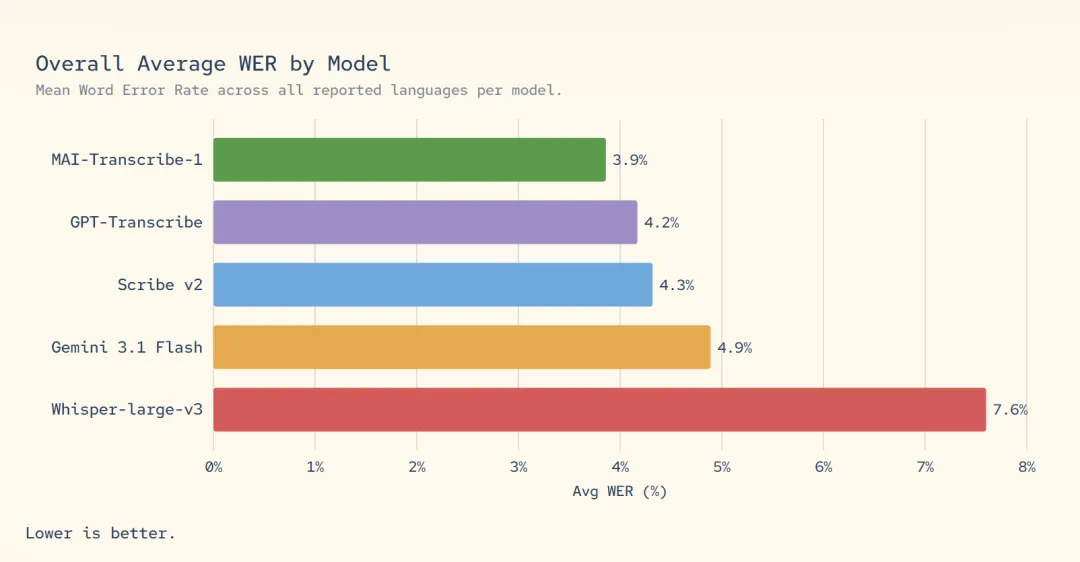
该模型采用基于 Transformer 的文本解码器与双向音频编码器,支持 MP3、WAV、FLAC 格式文件,最大容量 200MB。微软表示,其批量转写速度是现有 Azure Fast 服务的 2.5 倍。在行业标准多语言测试基准 FLEURS 上,该模型针对微软产品使用量最高的 25 种语言,实现了最低的平均词错误率,仅为 3.8%。微软已在 Copilot 语音模式和 Microsoft Teams 中测试 MAI-Transcribe-1 用于对话转写,这一细节也凸显出该公司正计划迅速用自研模型替代第三方或旧版内部模型。
MAI-Voice-1 是一款音频生成模型,支持用户在 1 秒内生成 60 秒自然流畅的音频,GPU 利用率极高。它能够生成自然逼真的语音,细节丰富、情感饱满且富有表现力,即使在长内容中也能保留说话人的音色特征。并且,微软在 Microsoft Foundry 中新增了安全创建自定义语音的功能,仅需几秒音频即可完成,能够极大简化开发者构建语音交互体验与智能语音助手的流程。
而 MAI-Image-2 为视频生成模型,专为摄影师、设计师和视觉叙事创作者打造,满足他们对自然光影、精准肤色与纹理的要求,同时可在图表、版式和视觉设计中生成清晰的画面内文字。最初,该模型于 3 月 19 日在全新大语言模型测试工具 MAI Playground 上线,在 Arena.ai 榜单上跻身前三模型系列后,进一步大幅提升了 Copilot 上的图像生成性能与速度。根据实际生产流量数据,用户在 Foundry 和 Copilot 上的生成速度至少提升至原来的 2 倍,同时画质保持一致。该模型也正在逐步向 Bing 和 PowerPoint 分批推送。

微软在博客中表示,在日益拥挤的 LLM 市场中,这些模型的一大卖点是定价低于谷歌和 OpenAI 的同类产品。MAI-Transcribe-1 定价起步为每小时 0.36 美元。MAI-Voice-1 起步价为每百万字符 22 美元,MAI-Image-2 则为文本输入每百万 tokens 5 美元、图像输出每百万 tokens 33 美元。
微软此次发布恰逢其处境微妙之际。这家公司的股票刚迎来 2008 年金融危机以来表现最差的一个季度,投资者愈发要求微软拿出证据,证明其数千亿美元的 AI 基础设施投入能够转化为实际收入。 这批定价极具竞争力、且旨在降低微软自身销售成本的模型,正是其应对这一压力的首个答卷。
不足 10 人研发,
GPU 用量仅为竞品一半
这些模型由微软 MAI Superintelligence 团队研发,同时也是团队打响的第一枪。该 AI 研究团队由微软 AI 负责人 Mustafa Suleyman 牵头,于 2025 年 11 月正式组建并公布,目标是实现他所称的 “AI 自给自足”。
在公开发布前的采访中,Suleyman 表示:“我非常激动,我们首批推出的模型就已达到全球顶尖的转写水准。不仅如此,我们实现同等效果所需的 GPU 资源仅为当前行业顶尖竞品的一半。”同时,Suleyman 对其当前的竞争地位信心十足:“我们现已跻身前三的 AI 实验室,仅次于 OpenAI 与 Gemini。”
而 Suleyman 透露的最令人震惊的细节,是研发这些模型的团队规模之小。“语音模型由 10 个人打造,速度、效率与准确率的大幅提升,绝大部分来自模型架构和我们使用的数据。图像团队同样不足 10 人。一切都源于模型与数据层面的创新,最终实现了顶尖性能。” 他表示,“我的理念一直是:人员要少而精,充分放权。因此我们采用极度扁平化的管理结构。”
与之形成对比的是 Meta,Suleyman 在采访中将其策略形容为 “大量招人,而非打造高效团队”,据称该公司为顶尖研究员开出的薪酬包高达 1 亿至 2 亿美元。其次,小团队就能产出顶尖成果,极大优化了经济效益。如果微软仅用 10 名工程师、竞品一半的 GPU 资源,就能做出行业顶尖的转写模型,其 AI 业务的利润结构,将与那些烧钱换取相似基准成绩的公司截然不同。
当被问及团队工作模式时,Suleyman 形容其环境更像初创公司的交易大厅,而非传统的微软工程部门。“团队成员围坐在圆桌旁,不是传统办公桌,用笔记本电脑而非大屏显示器。 他们全天并肩协作,沉浸式编码,一个房间里有五六十人,从早到晚。”
此外,Suleyman 一直在为微软的 AI 业务构建一套名为 “人文主义 AI” 的理念品牌。他表示,“我认为,人文主义超智能的初衷,是打造真正服务于人类的技术。人类将始终处于主导地位,技术也会始终与人类利益保持一致。”在模型发布的博客文章中,Suleyman 也写道:“在 Microsoft AI,我们正在打造 Humanist AI。我们在创建 AI 模型时有独特理念,以人为中心针对人类真实沟通方式进行优化,面向实际应用进行训练。很快,大家将在 Foundry 以及微软各类产品和体验中看到我们推出更多模型。”
Suleyman 还强调数据来源是微软的竞争优势,称他曾与微软 CEO Satya Nadella 讨论,要打造 “数据来源干净合规的模型体系”。他隐晦地与开源方案做对比,指出 “很多开源模型的训练数据来源可以说并不合规,这可能存在安全隐患。”
与 OpenAI 重新谈判,
微软计划实现 “完全独立”
要理解这批模型的重要性,就必须看清促成这一切的协议层面重大转变。尽管推出了自有模型,Suleyman 在接受外媒采访时重申,微软仍将继续履行与 OpenAI 的合作承诺。不过他也透露,近期双方对合作关系的重新谈判,为微软真正开展超智能研究扫清了障碍。
2025 年 10 月之前,微软受合同限制,无法独立研发通用人工智能。2019 年与 OpenAI 签署的原始协议中,微软获得 OpenAI 模型授权,作为交换为其搭建所需云基础设施。但当 OpenAI 试图将算力合作拓展至微软之外,与软银等方达成合作时,微软重启了协议谈判。正如 Suleyman 在 2025 年 12 月接受外媒采访时所述,修订后的协议意味着 “就在几周前,微软还因合同条款,被禁止独立研发通用人工智能或超智能模型”。新条款让微软得以自研前沿模型,同时保留至 2032 年使用 OpenAI 所有模型的授权。
Suleyman 也在最新采访中直言不讳地描述了这一变化。“去年 9 月,我们重新谈判了与 OpenAI 的协议,这让我们能够独立推进自研超智能模型。” 他表示,“自那之后,我们开始整合算力、组建团队,并采购所需数据。”
同时,他迅速强调,与 OpenAI 的合作关系保持不变。 Suleyman 称,“与 OpenAI 的合作不会有任何改变,我们至少会合作至 2032 年,希望能更久。他们一直是我们极为出色的合作伙伴。” 目前,微软已向该 AI 研究实验室(OpenAI)投资超 130 亿美元,并通过一项多年期合作协议,将其模型集成到微软各类产品中。他还提到,微软通过 Foundry API 提供 Anthropic 的 Claude 访问服务,将自身定位为 “平台中的平台”。
但 Suleyman 的潜台词显而易见:微软正在构建独立发展的能力。据外媒报道,Suleyman 今年 3 月在一份内部备忘录中写道,他的目标是 “未来 5 年,将全部精力投入超智能项目,为微软打造世界级模型”。这一架构调整让 Suleyman 从 Copilot 日常产品工作中脱身,前 Snap 高管 Jacob Andreou 接任执行副总裁,负责整合后的消费及商用 Copilot 体验业务。
Suleyman 在采访中明确表示,语音转写、语音与图像生成只是开端。当被问及微软是否会打造可与 GPT 正面竞争的前沿大语言模型时,他态度毫不含糊:“我们必将在所有模态上推出顶尖模型。我们的目标是:一旦微软有需要,就能以最高效率、最低价格提供世界一流技术,并实现完全独立。”
据悉,Suleyman 接受采访之时,整个团队正齐聚此地开展为期一周的常规线下集中会议,Nadella 也专程到场。Suleyman 还透露了多年路线图,包括 “搭建合适规模的 GPU 集群”,规划 “未来 2 至 4 年实现 AI 自给自足所需完成的全部目标,以及对应的算力布局路线”。
参考链接:
https://microsoft.ai/news/today-were-announcing-3-new-world-class-mai-models-available-in-foundry/
https://venturebeat.com/technology/microsoft-launches-3-new-ai-models-in-direct-shot-at-openai-and-google
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。