探讨分区大表因统计信息不准确导致的性能问题,并提供多种解决策略,助力数据库性能优化。
原文标题:分区大表统计信息不准确引发的性能问题
原文作者:牧羊人的方向
冷月清谈:
怜星夜思:
2、文章提到Hint和绑定执行计划可以解决统计信息不准带来的问题,但同时也增加了维护成本和风险。在你看来,这两种方法更适合哪些场景?应该如何降低其带来的负面影响?
3、文章中提到了分区裁剪,那么在你的实际工作中,你遇到过哪些因为分区裁剪失效导致的性能问题?你是如何排查和解决的?
原文内容
随着数据量的爆炸式增长,分区表已成为关系型数据库管理大型数据集的关键技术,尤其在时间序列、日志记录和交易流水等场景中应用广泛。在实际应用使用过程中,可能因为分区统计信息更新不及时,引发数据库性能问题。本文以GaussDB数据库为例,介绍分区大表由于新分区插入数据未及时更新统计信息导致执行计划走偏的案例。
1、分区表的统计信息自动收集策略
分区表(Partitioned Table)指在单节点内对表数据内容按照分区键以及围绕分区键的分区策略对表进行逻辑切分。从数据分区的角度来看是一种水平分区(horizontal partition)策略方式,将表按照指定规则划分为多个数据互不重叠的部分。从数据分布而言,分区表分为主表和子表,主表是一个逻辑上的概念,实际的数据是存放在表分区子表之上,表分区可以增加删除、修改,存放的文件系统也可以不同,主表只需要同步全局的表结构和维护全局分区表的字典信息以及统计信息。
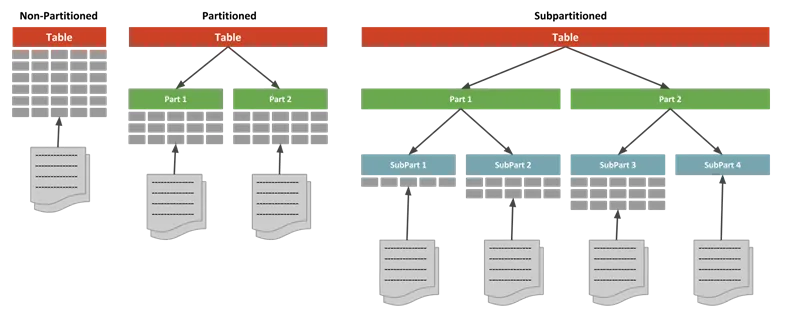
相比较普通表,分区表不仅可以提升数据库查询性能,在分区裁剪的场景下只需要查询指定的分区,不需要对所有分区扫描,从而提升查询效率;另外如果某个分区出现故障,表在其它分区的数据依然可用。
那么分区表的统计信息搜集策略是怎样,有两个维度:
-
分区表的维度,当所有分区的增删改达到表统计信息自动收集的阈值,会触发统计信息自动收集,对所有满足条件的分区收集统计信息,并汇总到分区表中;全表级别和字段级别的统计信息分别存放在pg_class和pg_statistic系统视图中。
-
表分区维度,当全局表没有达到自动收集的阈值,但是单个分区的增删改达到这个阈值时,也会触发该分区的统计信息自动收集。从数据库的表现来看,当单个分区的统计信息收集后,并没有同步更新到分区表上。分区级统计信息保存在pg_partition视图中。
在前文“”[1]中介绍过GaussDB数据库的统计信息自动收集策略,基于autovacuum_analyze_threshold(默认50行)和autovacuum_analyze_scale_factor(默认10%)参数,当数据变更量(增删改)超过阈值时会自动触发。对于一张分区大表而言,每天新插入到新分区的记录尚未达到全表的更新量阈值,也就不能触发全表统计信息的自动更新。
以一个特定的场景为例:一张按月分区的流水表sales_log,已经存在了3年,共36个分区,总计10亿行数据。由于全表记录数为10亿行,触发全局统计信息更新所需的变化量(10%)为1亿条,假如每天新增记录100w条,那么最近3个月新增的总记录也未达到自动收集统计信息的阈值。这样数据库的全局统计信息,包含总行数、索引基数、字段值分布等,停留在上一次统计信息收集的状态。对于数据库优化器而言是无法知道最新的数据分布情况,在执行计划评估时就可能存在偏差。
2、分区大表统计信息不准确的影响
分区裁剪分为静态分区裁剪和动态分区裁剪。当WHERE子句中对分区键的过滤条件为常量时为静态分区裁剪,例如“WHERE partition_key = ‘2026-03-21’”,优化器在查询解析阶段就能精确地确定需要访问哪些分区,因此静态分区裁剪受表级别的统计信息影响较小。动态分区裁剪是当WHERE子句中对分区键的过滤条件来自于与其他表连接的结果时发生,在复杂的多表关联查询中经常出现。例如以下语句:
SELECT s.*
FROM sales_log s
JOIN promotion_campaigns p ON s.campaign_id = p.id
WHERE p.campaign_type = 'NewYearSpecial';
在这个查询中,sales_log表需要访问哪些分区,取决于promotion_campaigns表中哪些活动属于NewYearSpecial类型,以及这些活动的id对应到sales_log表中的哪些分区。优化器必须在执行阶段,通常是在执行JOIN操作时,才能确定要裁剪掉哪些分区。

上述例子中如果分区大表sales_log的全局统计信息过于陈旧,最终会导致动态分区裁剪的性能远低于预期:
-
连接基数估算:在上面的例子中,优化器首先需要估算promotion_campaigns表中满足campaign_type = 'NewYearSpecial’的行数
-
连接成本估算:接下来,优化器需要决定sales_log和promotion_campaigns的连接顺序和方法。它会参考sales_log的全局统计信息。由于统计信息是旧的,优化器并不知道最新的分区p_2026_03中可能包含了大量与NewYearSpecial相关的销售记录。
-
生成次优的执行计划:基于以上成本估算,优化器可能会认为sales_log 表相对较小,从而选择了一个不恰当的连接算法,比如嵌套循环连接(Nested Loop Join)。嵌套循环先从promotion_campaigns表中找出活动ID,然后对每个ID,去 sales_log 表中探测一次。
在嵌套循环时,虽然每次探测sales_log都会进行分区裁剪,但整个过程是“驱动表驱动被动表”的模式。如果优化器因为错误的统计信息选择了错误的驱动表,那么即使每次探测都做了分区裁剪,整体的I/O和计算开销也会非常大。
跨分区的大表访问在分析统计类的业务场景下经常遇到,比如以下SQL统计2026年第一季度的销售总额:
SELECT product_category,SUM(sale_amount) as total_sales
FROM sales_log
WHERE status=’T’ and sale_date >= '2026-01-01' AND sale_date < '2026-04-01'
GROUP BY product_category
ORDER BY total_sales DESC;
该查询需要访问p_2026_01、p_2026_02和p_2026_03三个分区的数据。由于新增分区的数据量未达到全表的统计信息自动收集,全局的统计信息中未包含该三个分区的统计信息。优化器在执行计划成本估算的时候会出现偏差,有可能认为全表扫描这几个分区的数据比走索引的成本更低,最终导致性能上的劣化。
3、如何解决大表统计信息不准的问题
不仅仅是GaussDB数据库,其它如MySQL系、TiDB等数据库都存在问题。那么对于分区大表的统计信息如何进行更为精细化的管理和维护?
1)自适应的统计信息更新阈值
目前大多数数据库的统计信息自动更新阈值是固定的,比如更新量超过一定的pages或者整表数据量的10%等。对于一些大表而言会存在统计信息更新不及时的问题,因此需要数据库底层支持自适应的阈值更新,根据表数据量的级别进行动态的适配调整,比如1000w数据量的阈值为10%、1亿条数据的阈值为1%等。
2)大表单独设置更新阈值
有些数据库厂商是支持对单表设置统计信息更新阈值的,比如在GaussDB数据库中通过语句“ALTER TABLE xx SET (autovacuum_analyze_scale_factor=0.01)”对大表设置不同的阈值,比如0.01对于1亿大表更新量超过100w即自动收集统计信息。这样的好处是大表的统计信息能及时的更新到,不过这个阈值该怎么定义、频繁触发统计信息收集比如在业务高峰期的性能影响等,都需要事先评估确认清楚。有些数据库厂商建议这种做法,虽然会增加一定的维护成本。
3)定期手动收集统计信息
对于分区大表新增分区已经更新统计信息但全局表未及时收集的,通过SQL语句可以定期排查出清单,在周末等业务低峰期进行手动的统计信息收集。定期收集统计信息在传统DB2、Oracle数据库中使用较多,也是增加了运维成本。
4)应用使用Hint或者绑定执行计划
在SQL中指定hint方式强制走某个索引如SELECT /*+ INDEX(sales_log idx_date) */ …,防止因为统计信息不准确导致的执行计划走偏进而引发性能问题。这种方式对应用具有侵入性并且需要修改业务代码。另外就是使用执行计划绑定方式,在统计信息准确时,捕获一个查询的“良好”执行计划,并将其“绑定”到这条SQL语句上。之后,无论统计信息如何变化,只要这条SQL被执行,优化器都会优先使用这个被绑定的计划。不过这两种方法都会增加维护成本,并且随着数据量的变化或者复杂的多表关联查询语句,之前的hint或执行计划并不是最优的,会带来一定的风险。
综合而言,分区大表统计信息不准确是一个常见的数据库性能劣化场景,也没有通用的实施优化标准。有些厂商建议使用表级别的统计信息收集阈值、有些会使用hint方式、也有定期收集统计信息维护策略。根本上还是需要从被动依赖向主动管理转变,提前发现潜在的风险和问题。
参考资料: