RocketMQ LiteTopic为AI推理场景提供精细化流量治理方案,实现毫秒级限流和分钟级调度,解决队列阻塞和并发效率问题。
原文标题:AI 推理精细化流量治理实战:RocketMQ LiteTopic 的“千人千面”流控方案
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、LiteTopic 方案提到了百万级的 Topic 数量,这在实际应用中会带来哪些运维上的挑战?我们应该如何应对这些挑战?
3、文章提到 LiteTopic 已经与阿里云百炼网关达成合作,那么 LiteTopic 在大模型服务中,除了流量治理之外,还可以发挥哪些作用?
原文内容

引言
随着大模型推理服务成为主流,消息队列在 AI 场景下的精细化流量治理,正面临前所未有的挑战。
传统互联网应用的业务流程固定、请求耗时短,消息队列的限流机制已相对成熟。然而,在 AI 推理场景下,业务流程高度动态、单次任务可持续数分钟甚至更久。这让传统方法显得力不从心,并引发两大核心痛点:
-
队列头部阻塞:单个用户的慢任务,会阻塞队列中其他用户的消息处理。
-
并发效率受损:简单粗暴的限流措施,会导致整个系统吞吐量急剧下降。
为解决这些问题,Apache RocketMQ 5.x 版本推出了专为 AI 场景设计的核心特性——轻量主题模型 LiteTopic。它支持百万级轻量主题的创建和高性能动态订阅。基于 LiteTopic 的精细化流量治理方案,既能实现毫秒级的实时限流,又能支持分钟级的忙闲调度,真正做到了“千人千面”的个性化流量治理。
AI 推理场景下的消息队列新挑战
AI 应用与传统互联网应用存在本质差异,在于其执行模式和任务耗时。传统应用流程固定可预测、耗时短(秒级)、多为单向一次性交互;AI 应用更偏主动执行,会自主拆解目标并动态调整策略,流程不确定,单次任务耗时长(分钟级且不可预测),还常伴随多轮对话交互。

这种差异,导致消息队列在 AI 推理场景下面临两大严峻挑战:
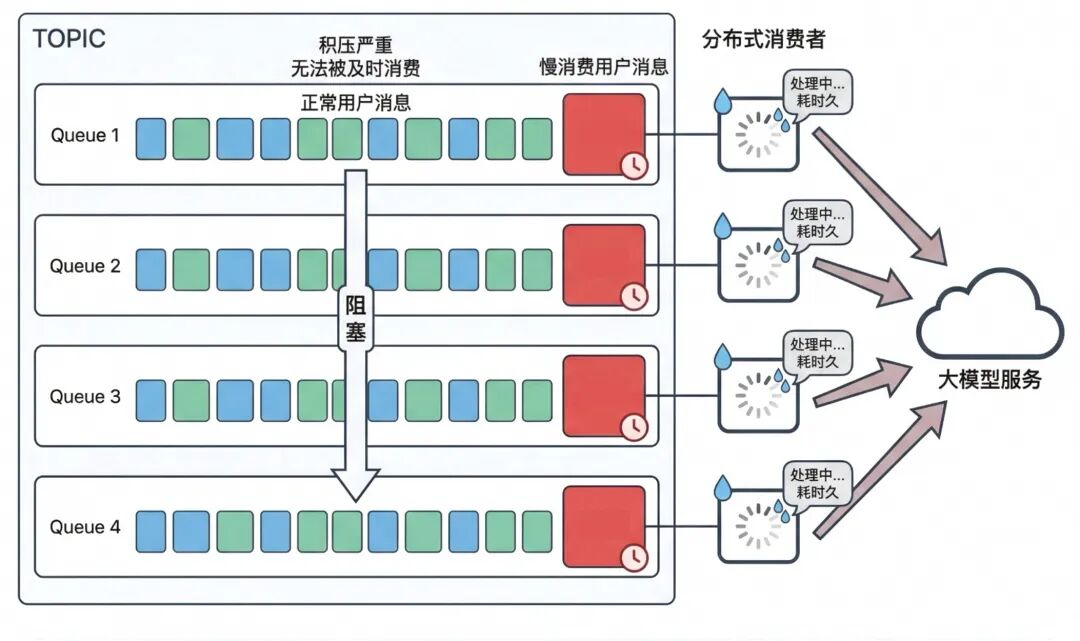
1. 队列头部阻塞
传统业务中,不同用户的请求耗时较均衡(通常为秒级),即便多租户共享队列,也不会长期占用队列头部,阻塞问题不明显。因此,只需设置几个队列即可满足需求。
但在 AI 推理场景下,不同用户的请求耗时差异巨大(几秒到几十分钟不等且不可预测)。多租户共享队列时,一条长耗时消息(如复杂推理任务)占据队列头部,会阻塞后续所有消息的处理,导致同队列其他用户的正常消息无法被及时处理。若某个用户密集提交慢任务,可能长期抢占全部队列头部位置,形成资源独占,导致其他用户延迟飙升,破坏系统公平性。
2. 并发效率受损
在 AI 推理场景中,当某个用户短时间内密集提交大量推理请求时,系统需要对该用户实施流量控制。然而,传统的限流措施(如 Thread.sleep())会阻塞消费者线程,这会导致一个严重的问题:
即使队列中还有其他健康用户的消息等待处理,但由于所有消费线程都在处理限流用户的请求而被阻塞,这些健康用户的正常消息也无法得到处理。随着被限流的用户增多,大量线程陷入阻塞状态,整个系统的并发处理能力将急剧下降。
传统方案为何在 AI 推理场景中失效?
面对 AI 推理场景的流量洪峰,业界通常采用两种“老套路”来限流,但都“治标不治本”。
▍方案一:消费失败重试法
简单粗暴地让消息失败,并自动重回队列排队。这听起来似乎很取巧,实则埋下了“定时炸弹”:
-
重试机制不可控:依赖中间件内置重试机制,缺乏时间精度控制,易造成延迟放大;
-
服务质量不稳定:无法保证时效性,消息可能在队列里躺上好几轮才被处理,影响业务 SLA;
-
资源浪费严重:失败重试会消耗额外的网络、磁盘和 CPU 资源,增加系统整体负载,降低系统稳定性。
▍方案二:线程阻塞限流法
当检测到某个用户短时间内请求频率过高或资源消耗过大时,通过Thread.sleep()等同步阻塞 API 暂停消息处理线程,直接让处理线程“睡一会儿”。这看似控制住了消息处理频率,实则是在“饮鸩止渴”:
-
资源利用率低:大量线程被无效阻塞,不仅占用内存,还增加调度开销,导致并发能力下降,长期运行有资源耗尽风险;
-
租户隔离失效:在共享线程池中,对某个队列的限流会波及由同一线程处理的其他队列,从而破坏多用户间的隔离性;
-
吞吐量受损:阻塞机制与高性能设计的初衷背道而驰,严重损害了系统整体的消息处理能力。
这两种传统方法,要么过度依赖中间件机制,要么牺牲系统性能,都无法从根本上解决多租户环境下的精细化流量控制难题。
RocketMQ LiteTopic 流量治理:
千人千面,优雅调度
▍1. 毫秒级实时限流:让每个用户都有“专属 VIP 通道”
AI 推理请求可能在毫秒级内剧烈波动,需要毫秒级的精细化限流能力来应对瞬时流量洪峰。
RocketMQ 基于 LiteTopic 打造了一套精细化限流方案,通过构建完整的资源隔离与调度体系来实现高效的流量治理:
-
物理隔离:为每个用户/会话创建独立 LiteTopic,从物理层面实现用户级资源隔离,彻底消除交叉干扰。
-
弹性扩容:LiteTopic 支持百万级规模的按需创建,无论是小批量测试还是大规模生产,都能从容应对。
-
精准流控:每个 LiteTopic 可独立执行限流策略,支持按用户配置差异化阈值,真正实现“千人千面”的个性化流量治理。
-
消费挂起:当检测到用户请求超限时,不是简单地拒绝(失败重试)或等待(阻塞线程),而是优雅地“请用户稍等片刻”(挂起),既保护了系统资源,又不影响用户体验。
在实际应用中,流量处理流程如下图所示:
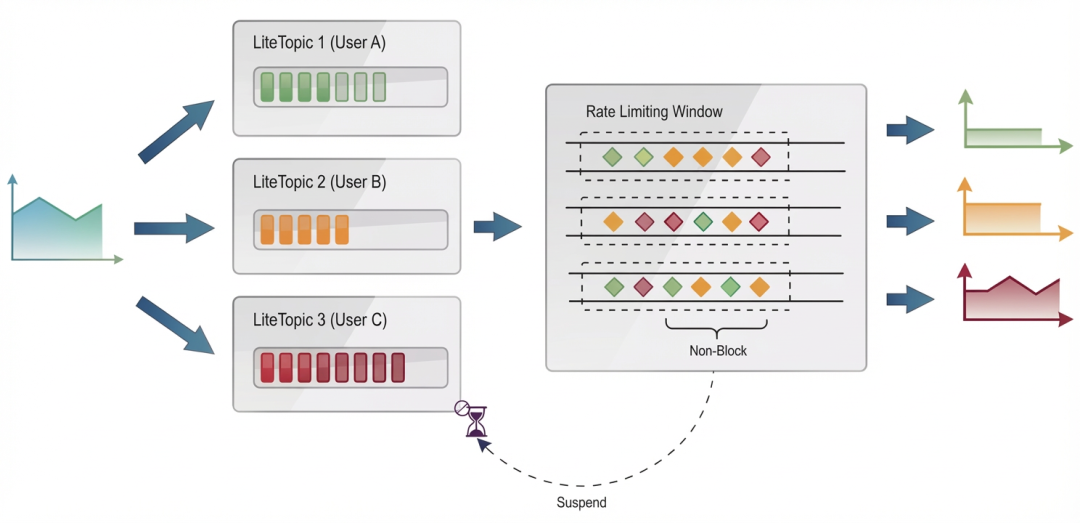
1. 消息分流:上游业务消息根据用户标识(如 userId)分流到每个独立用户对应的专属 LiteTopic,实现物理隔离。
2. 并行拉取:消费者通过长轮询并行拉取各 LiteTopic 的消息,在限流窗口中对每个 LiteTopic 独立执行限流判断。
3. 限流判断:
-
未超限:当某用户请求未触发阈值时,正常消费并输出流量;
-
已超限:当检测到请求超限时,返回 Suspend 挂起状态。
4. 消费挂起:该 LiteTopic 立即挂起,消费者释放处理线程并暂停服务端对该用户的拉取,支持毫秒级精确控制挂起时长,确保限流策略的灵活性和响应速度。
5. 线程复用:释放的线程即时转交其他用户请求,实现资源的弹性调度与高效复用。
6. 自动恢复:挂起的 LiteTopic 将在指定时间后自动恢复消费。
以下消费代码示例展示了如何在实际业务中实现这套机制:
LitePushConsumer litePushConsumer = PROVIDER.newLitePushConsumerBuilder()
.setClientConfiguration(clientConfiguration)
.bindTopic(TOPIC)
.setConsumerGroup(GROUP)
.setMessageListener(messageView -> {
//【物理隔离】以userId作为liteTopic名称,实现用户级物理隔离
// 每个用户独享一个独立的物理队列,确保资源完全独立,避免相互干扰
String userId = messageView.getLiteTopic();
//【精准流控】根据业务规则判断是否需要触发限流
// 支持按用户配置差异化阈值,实现"千人千面"的个性化流量治理
if (shouldThrottle(userId)) {
//【消费挂起】返回suspend,立即释放当前处理线程
// 服务端暂停对该用户的拉取,避免无效资源消耗
// 支持毫秒级精确控制,100ms后自动重投递,释放的线程可被重新分配给其他用户请求
return ConsumeResultSuspend.of(Duration.ofMillis(100));
}
// 正常处理消息
processMessage(messageView);
return ConsumeResult.SUCCESS;
})
.build();
上述代码的核心是引入了“消费挂起”机制。
与传统消息队列仅支持“消费成功”与“消费失败”两种状态不同,这里新增了第三种消费状态——Suspend,实现了精准的时间窗口控制:
-
状态扩展:消费者返回 ConsumeResultSuspend 状态时,可携带下次可见时间戳,指定消息在时间窗口内的不可见期;
-
资源释放:系统立即释放处理线程,清理该队列的本地缓存,避免资源占用;
-
自动恢复:服务端维护定时调度器,到达指定时间后自动唤醒队列,重新参与拉取消费。
这一机制让瞬时限流不再阻塞线程,既保护了系统资源,又确保了其他用户请求的正常处理,完美契合 AI 推理场景下的实时流量治理需求。
▍2. 分钟级忙闲调度:让延迟任务“错峰出行”
除了毫秒级的瞬时流量控制,RocketMQ LiteTopic 的消费挂起机制同样适用于分钟级甚至小时级的长时间窗口调度,实现延迟不敏感任务的错峰调度。
在实际业务场景中,可能存在大量延迟不敏感的任务,如:
-
跑批任务:数据统计、报表生成等批量处理作业;
-
异步处理:非核心链路的异步通知、日志分析等;
-
资源消耗型任务:模型训练、离线推理等计算密集型操作。
这类任务无需实时处理,但可能占用大量计算资源。通过消费挂起机制,我们可以将这些任务智能调度到业务空闲时段执行:
1. 长时间窗口挂起:设置秒级甚至分钟级的挂起时长(如 Duration.ofMinutes(30)),将任务延迟到低峰期处理;
2. 动态感知业务负载:实时监控系统负载,当检测到资源紧张时,主动挂起低优先级任务的消费;
3. 轻量级任务调度:在无需引入额外调度系统的情况下,通过消息队列本身实现任务的延迟执行和资源错峰,降低系统复杂度。
LitePushConsumer litePushConsumer = PROVIDER.newLitePushConsumerBuilder()
.setClientConfiguration(clientConfiguration)
.bindTopic(TOPIC)
.setConsumerGroup(GROUP)
.setMessageListener(messageView -> {
String taskType = messageView.getUserProperty("taskType");
//【忙闲调度】识别延迟不敏感任务
if ("BATCH".equals(taskType) || "LOW_PRIORITY".equals(taskType)) {
// 检测系统是否处于繁忙状态
if (isSystemBusy()) {
//【长时间挂起】将任务延后到空闲时段处理
// 挂起30分钟后自动恢复,实现错峰调度
return ConsumeResultSuspend.of(Duration.ofMinutes(30));
}
}
// 正常处理消息
processMessage(messageView);
return ConsumeResult.SUCCESS;
})
.build();
这种忙闲调度能力,让 RocketMQ LiteTopic 在消息队列的基础上,扩展了延迟任务处理能力。无需引入额外的调度组件,即可在保障核心业务 SLA 的同时,最大化系统资源利用率。
RocketMQ LiteTopic 技术揭秘:
如何实现百万级物理隔离?
LiteTopic 是 Apache RocketMQ 专为 AI 场景设计的轻量主题模型,具备轻量资源、自动化生命周期管理、高性能订阅和顺序性保障等特点。
其底层基于创新的存储架构和分发机制,支撑了百万级 LiteTopic 的高效管理,在不牺牲性能的前提下,实现了海量 LiteTopic 资源的物理隔离,为 AI 场景下的精细化流量治理提供了坚实的技术基础。
关键技术点包括:
-
统一存储、多路分发:所有消息数据统一存储在底层 CommitLog 文件中且仅存储一份,采用追加写入模式避免磁盘碎片化,保障极致写入性能。同时,通过多路分发机制为不同 LiteTopic 生成独立的消费索引。
-
RocksDB KV 存储引擎:摒弃传统文件型 CQ 结构,替换为高性能的 KV 存储引擎 RocksDB,将队列索引信息和消息物理偏移量作为键值对存储,充分发挥 RocksDB 顺序写入的高性能优势,实现对百万级元数据的高效管理。
-
订阅关系管理:Broker 负责管理消费者的订阅关系集,支持增量更新,能够实时、主动地感知消息与订阅的匹配状态。
-
事件驱动与就绪集维护:每当新消息写入时立即触发订阅匹配,将符合条件的消息聚合到就绪集中。
-
高效批量拉取:消费者只需一次 poll 请求即可批量拉取来自多个 LiteTopic 的消息,显著降低网络交互频率,确保在海量订阅场景下的低延迟与高吞吐。
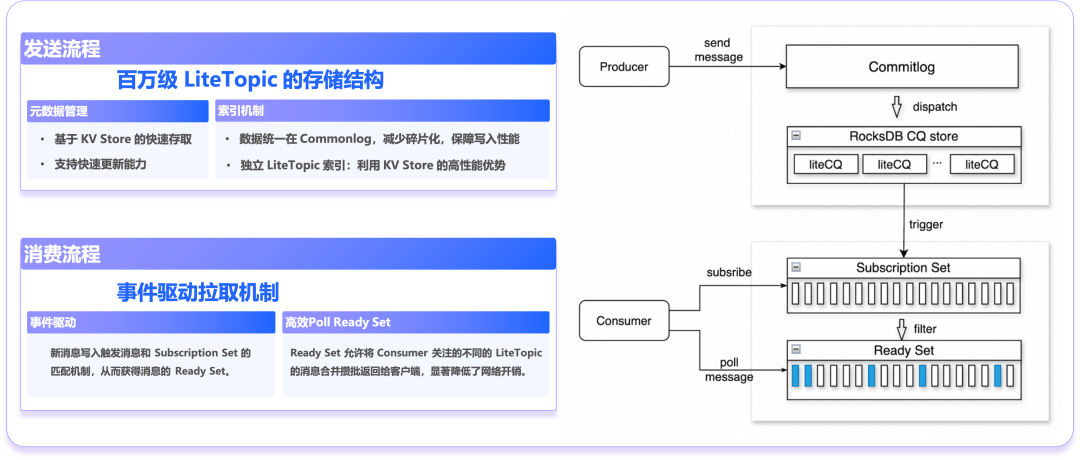
百万级 LiteTopic 高并发性能的发送和消费流程
结语
随着 AI 推理日益普及,传统消息队列限流方式已难以满足精细化流量控制需求。
基于 RocketMQ LiteTopic 的精细化流量治理方案,通过物理隔离、弹性扩容、精准流控和消费挂起四大核心特性,系统性解决了队列头部阻塞和并发效率受损两大痛点,为 AI 推理场景提供了从毫秒级实时限流到分钟级忙闲调度的全方位消息处理保障,实现了真正意义上的“千人千面”个性化流量治理。
值得一提的是,该方案已与阿里云大模型服务平台百炼网关达成深度合作,利用 RocketMQ LiteTopic 的精细化流控能力,帮助其更好地管理 AI 推理请求的流量峰值与资源调度。
目前,LiteTopic 的核心能力已在阿里云云消息队列 RocketMQ 版 5.x 系列实例中发布,若要在实际业务中使用,请点击下方阅读原文链接查看帮助文档。
未来,我们将继续探索更多创新技术,推动消息队列在 AI 时代的演进与发展。
欢迎钉钉搜索(群号:110085036316)加入 RocketMQ for AI 用户交流群,与我们交流探讨~