阿里提出REG4Rec模型,通过推理增强范式提升生成式推荐的个性化能力,已在Lazada大规模部署并取得显著商业收益。
原文标题:从匹配困境到推理突破:阿里REG4Rec 激活生成式推荐的个性化潜力
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文中使用GRPO对模型进行推理增强,能否详细解释一下GRPO的具体实现方式?除了文中提到的三类奖励信号,是否可以引入其他的奖励机制来优化模型?
3、REG4Rec在线上部署时采用了反思剪枝和多步松弛策略,这两种策略分别解决了什么问题?在实际应用中,如何平衡这两种策略的强度,避免过度剪枝或过度松弛?
原文内容

来源:机器之心本文约6000字,建议阅读15分钟阿里国际智能技术团队提出了基于推理增强范式的生成式推荐模型 REG4Rec。
一、引言
从内容分发到商业转化,推荐系统早已成为互联网平台的关键基础设施。它在海量信息与有限注意力之间完成筛选和排序,直接影响内容曝光、商品成交以及流量变现效率。
用户在电商平台上看到的商品列表、在信息流里刷到的内容、广告位中呈现的链接,通常并非随机展现,而是推荐系统在毫秒级完成特征理解和排序决策的结果。
近年来,大语言模型(LLM)在语义理解、内容生成和多步推理方面取得快速进展,推动业界重新审视推荐系统的形态:推荐是否可以不再局限于一次性打分和相似度匹配,而是像人类决策一样,在生成过程中进行多步推理与自我修正,逐步逼近用户的真实意图。
基于此,「生成式推荐」开始成为一个重要研究方向,尝试将 “理解 — 生成 — 推理” 融为一体,让推荐过程从静态匹配转变为面向用户意图的动态决策。
在实际电商环境中,生成式推荐面临的主要挑战不在于生成商品本身,而在于生成过程是否具备「可推理、可控且稳定」的能力。
电商场景下,用户行为信号噪声高、兴趣多样且频繁变化,模型需要在多步生成过程中持续校准语义方向、维持推理轨迹的一致性。若仍采用经典自回归解码,早期预测偏差容易被不断放大,推理路径收缩到少量固定模式,导致生成精度受限、长尾兴趣覆盖不足,难以稳定命中用户真实需求。
针对上述问题,阿里国际智能技术团队提出了基于推理增强范式的生成式推荐模型 REG4Rec。该模型从表征学习、训练目标和推理策略三个层面进行了系统设计,以提升生成式推荐的推理能力与稳定性。离线实验显示,REG4Rec 在多个关键指标上优于现有生成式方法,并呈现出随推理步数增加而性能持续提升的 Scaling Up 特性。
目前,REG4Rec 已在 Lazada 推荐广告场景完成大规模工业化部署。线上结果显示:广告收入提升 5.60%、商品交易总额(GMV)提升 3.29%、点击率提升 1.81%,带来显著商业收益。
本工作相关成果已被数据挖掘领域顶级会议 ICDE 2026 接收。

-
论文标题:REG4Rec: Reasoning-Enhanced Generative Model for Large-Scale Recommendation Systems
-
论文链接:https://arxiv.org/pdf/2508.15308
二、从判别打分走向多步生成,难点在于「推理」
长期以来,主流推荐模型大多遵循判别式范式:给定用户与候选物品,模型通过一次性打分来估计二者的交互概率。
这种方式高效且易于部署,但也天然受限,当用户兴趣快速演化、意图高度隐式且多维交织时,单次判别打分无法显式建模用户的决策路径,也无法在推理过程中对路径进行修正。换言之,它更擅长回答是不是,却不擅长回答你真正想要什么、以及为什么。
在这一背景下,生成式推荐开始受到关注。它把推荐从「一次判断」改写为「多步生成」:不再直接对候选打分,而是将物品表示从连续向量离散化为一串语义 ID(Semantic IDs),并让模型在解码阶段逐步生成这些 ID。每一步生成都在补全一部分意图线索、收缩候选语义空间,最终由一组语义 ID 组合定位到目标物品。
相比单次打分,这种范式天然接近推理式决策,模型在生成过程中主动选择、组合并纠偏,从而有机会捕捉更细粒度、更个性化的兴趣表达。
围绕语义 ID 与生成式范式,阿里国际智能技术团队在工业场景中持续探索。2024 年,团队将残差式语义 ID 引入召回阶段的负采样,实现了负样本难度与规模的可控调度(WWW’25 ESANS [1])。
同时团队搭建并部署了行为大模型基座,针对多模态异构 token 带来的噪声问题,提出基于分层 Transformer 的去噪建模方案(SIGIR’25 HeterRec [2])。这些前置工作表明,生成式范式的关键并不止于「能生成」,更在于如何让生成过程具备更强的「推理能力」与「可控性」。
基于此,团队提出了推理增强生成式推荐模型 REG4Rec,并将面临的核心挑战概括为三点:
-
挑战一:码本信息分布不均,步间语义割裂。当前主流生成式推荐方案多采用残差式层级语义 token,但在多步生成中存在两类问题。其一,语义信息过度集中在浅层,深层 token 的信息量随层数快速衰减,从而带来层间学习难度不一致、训练收敛不稳定等问题。其二,不同层级 token 之间语义关联弱,缺乏跨步承接,使后续生成难以有效利用前序先验,每一步都像在全新空间里重新开始,从而显著抬高整体解码难度。
-
挑战二:解码路径固定,难以刻画 “因人而异” 的决策逻辑。现有生成式推荐通常固定语义 ID 的生成顺序,相当于为所有用户预设同一条推理轨迹。然而,同一商品可能因品牌、风格、价格、类目等不同因素被不同用户触发,固定顺序限制了模型描绘「个体化决策路径」的能力,压缩了个性化表达空间。
-
挑战三:自回归解码的误差累积问题。生成式解码通常采用自回归方式,缺少对当前生成状态进行显式评估与修正的机制。一旦早期 token 出现偏差,错误便会在后续步骤中持续传导并逐步累积,最终导致失之毫厘,谬以千里。
三、REG4Rec:让生成式推荐从匹配走向多步推理
3.1 方案设计
针对上述挑战,REG4Rec 从语义 ID 表征、推理路径建模、推理增强训练和线上推理部署四个层面进行系统设计,构建端到端的生成式推理方案:
1. 超长并行语义码本:用 MMQ 并行码本替代 RQ-VAE 残差层级码本,缓解码本信息分布不均和步间语义割裂问题,使码本规模与推理步数能够稳定扩展。
2. 上下文感知的动态推理路径:在推理阶段支持自适应的 token 生成顺序,使解码路径随用户意图动态变化,更好刻画 “因人而异” 的决策逻辑。
3. 基于 GRPO 的推理增强:引入多维反馈信号(如 token 命中、类目一致性、语义一致性等)对推理过程做偏好对齐,提升对早期误差和错误前缀的鲁棒性,增强自我纠偏能力。
4. 基于反思剪枝与多步松弛的线上部署:在推理阶段引入一致性度量进行 “反思剪枝”,过滤语义不一致的解码路径。在商品检索时则允许少量 token 不匹配的模糊召回,在保证推理稳定性的同时提升长尾覆盖能力。
图 1 REG4Rec 算法架构
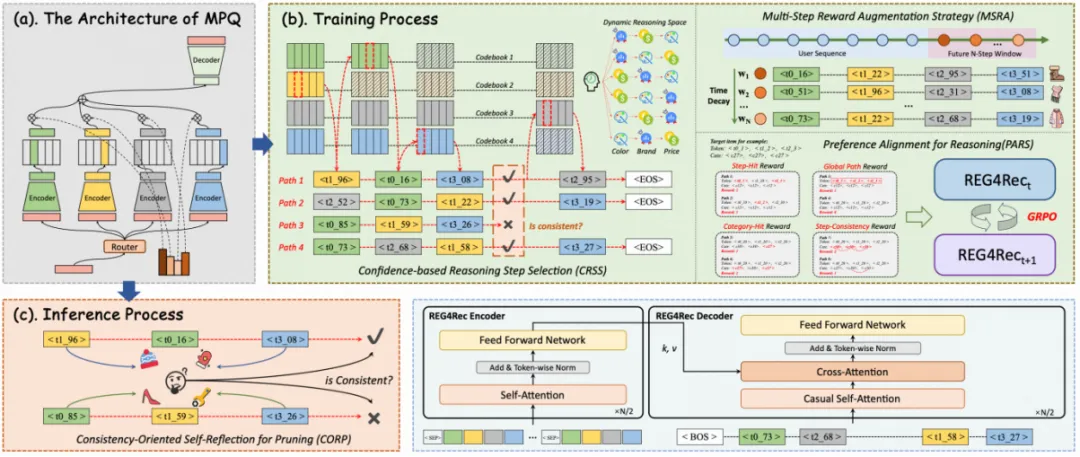
3.2 超长并行语义码本
工业界常用 RQ-VAE 来构造语义 ID,其残差层级结构更适合压缩表示,并不天然适配多步推理式生成。随着解码步数增加,新增码本往往难以贡献同等水平的增量语义信息,训练过程中也更容易出现层间收敛不同步的问题。
更重要的是,层级残差把语义拆到彼此相对割裂的空间里,后续步骤难以继承前序推理结果,导致多步生成难以实现「随步数增加而持续提升」,反而更容易放大早期偏差。这意味着如果不改变语义 ID 的组织方式,推理步数和收益都很难可持续扩展。
图 2 基于 MoE 的并行语义码本 MMQ
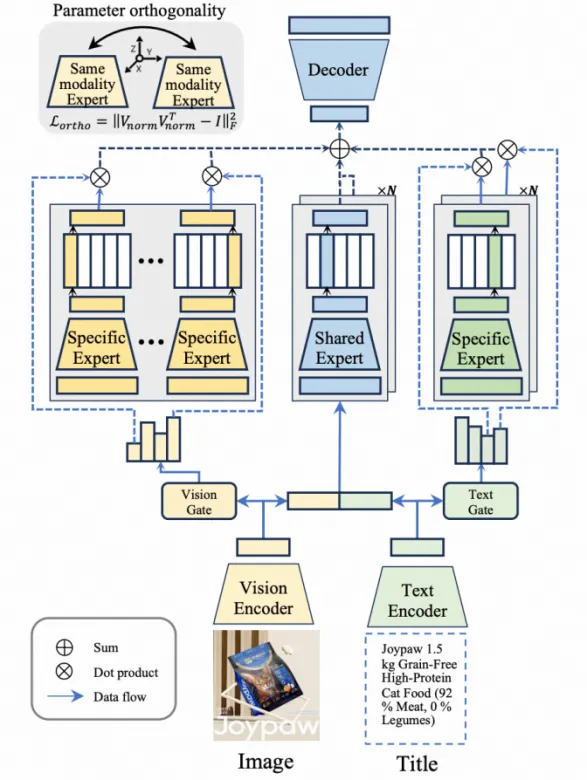
为了解决这些问题,阿里国际智能技术团队提出了一套基于 MoE 的并行语义码本方案 (WSDM’26 MMQ [3])。该方案通过多个专家从不同语义视角对同一商品进行编码,生成一组平行的语义 token 空间;同时引入路由机制,为各 token 维度清晰分工,避免语义信息过度集中在少数维度,其余维度逐步退化为残差噪声。
在这一设计下,码本规模与推理步数能够更稳健地扩展,为更长推理链路的 Scaling Up 奠定基础。同时,生成的核心目标也从「压缩商品表示」转向「刻画用户兴趣空间」:模型在多个语义维度上逐步推理出用户偏好,再通过检索策略从商品库中取回满足这些语义约束的目标物品。
3.3 上下文感知的动态推理路径
在现有生成式召回架构中,商品通常被编码为一条固定顺序的语义 token 序列,对于残差码本往往对应由粗到细的层级顺序。这种确定性表征隐含了一个强假设:所有用户都应沿着同一套语义维度依次理解商品。但在真实推荐场景中,用户的决策线索往往因人而异。同一商品包含品牌、价格带、颜色、款式等多维属性,不同用户产生兴趣的触发点可能完全不同,有人先看品牌,有人更在意外观风格,也有人优先关注价格。若解码顺序被绑定到单一静态路径,就相当于把不同用户的推理过程压缩到同一条决策链上,模型可表达的推理空间被显著收窄,个性化效果也因此受限。
图 3 基于上下文感知的动态推理路径
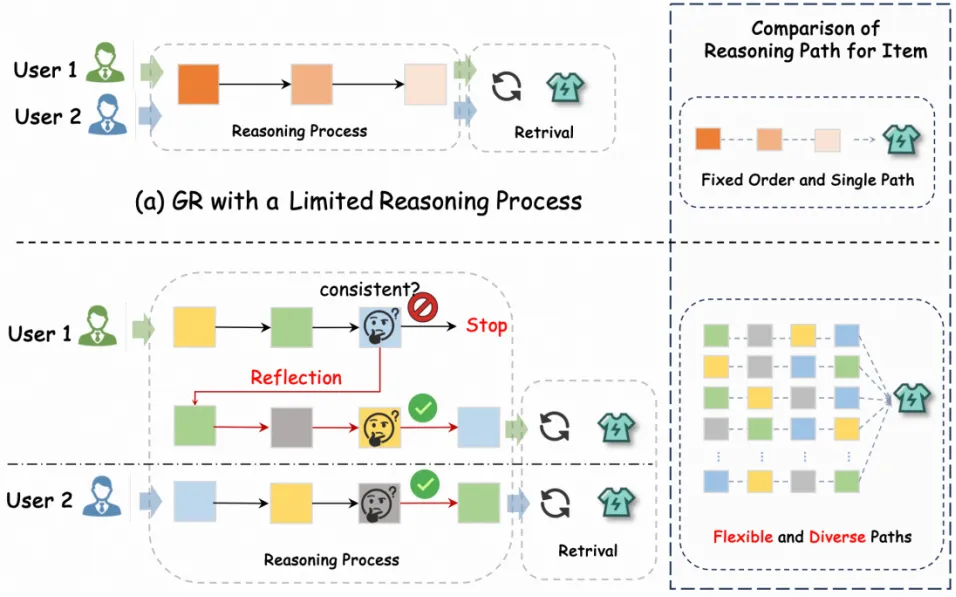
为此,REG4Rec 设计了上下文感知的动态推理路径。模型在每一步生成前,综合用户历史行为、实时意图信号以及已生成的 token 前缀,自适应决定下一步从哪个语义维度进行解码。这样,解码不再受预设顺序约束,而是围绕用户当前关注点动态选择并组合语义维度,逐步形成更贴近个体决策逻辑的推理轨迹。
这一设计将个性化能力前置到生成过程之中,使模型不仅学习「生成哪些语义线索」,也学习「先生成哪些线索、再补全哪些约束」。在并行码本提供的多视角语义空间上,动态路径显著扩展了可探索的推理组合,有助于更精准地捕捉复杂多变的用户意图。
3.4 基于 GRPO 的推理增强
受大语言模型中「推理即生成」范式的启发,REG4Rec 将推荐从传统的「表征匹配」升级为「可控的逻辑推理」,更细致地刻画用户行为背后的决策路径与真实兴趣。
为此,REG4Rec 在训练阶段引入强化学习框架,基于 GRPO 进行偏好对齐,引导模型在大规模生成空间中探索更优推理路径。奖励函数设计主要包括三类信号:
-
面向结果的奖励:根据生成结果与目标商品语义 ID 的命中程度给予奖励。即使前缀出现偏差,只要后续检索的商品命中目标,仍会持续给予正反馈,从而缓解自回归误差累积,并促使模型学到错误前缀下的更优策略,提升离线与线上表现的一致性。
-
面向过程的奖励:包含两项信号,一是类目命中奖励,在难以精确命中商品时先对齐到正确类目,为模型提供更稳定的中间目标;二是语义一致性奖励,约束相邻步骤的语义漂移,避免推理链路发生明显跳变,保障生成过程的连贯性。
-
面向集合检索的松弛奖励:当生成结果命中足够多的语义 token 即给予奖励,与线上集合检索逻辑对齐,促使模型学习更有效的 token 组合策略,从而提升长尾覆盖与整体鲁棒性。
通过上述 GRPO 后训练,模型能够在多步生成中更好平衡命中率、推理方向与语义连贯性,显著提升推理路径的可控性与结果稳定性。
3.5 基于反思剪枝与多步松弛的线上部署
在线上部署环节,REG4Rec 围绕稳定性与泛化性,对推理与检索两个关键环节做了针对性改造。
推理阶段的反思剪枝:在 Beam Search 扩展候选路径时,不再仅依赖累计生成概率进行排序,而是引入一致性信号,对生成轨迹进行在线「自检」。对于语义前后不连贯、出现明显漂移的路径及时剪枝,优先保留语义一致的候选,从而降低多步解码的不确定性,让输出更稳定、更可靠。
检索阶段的多步松弛:在商品检索时,不再将 token 序列完全一致作为硬约束,而是允许少量 token 不匹配的候选进入召回集合。这样可以显著降低局部预测偏差带来的漏召风险,同时几乎不增加额外推理开销,并进一步提升对长尾兴趣与相似商品的覆盖能力。
3.6 性能与效率:在大规模业务场景跑得动
训练优化:随着模型参数和推理步数增加,训练时间显著变长,对离线迭代速度带来压力。REG4Rec 团队从特征处理、高效率算子引入,量化和显存管理等多个维度进行优化,将单次训练时间缩短至原来的约一半,加快训练迭代和实验回收效率。部分关键的优化点如下:

推理优化:在生成式推荐的推理链路中,同样包含特征处理与模型计算部分。REG4Rec 的优化重点主要集中在模型推理侧,一方面借鉴 LLM 推理优化思路,另一方面结合搜索与广告场景下的生成式推荐特点进行定制化设计,主要包括:
通用优化:将 LLM 推理优化的方法应用到生成式推荐中,如 FlashAttention、量化、KV cache 等,以提升算子效率和硬件利用率。
定制优化:针对生成式召回中 beam size 增大会导致 batch size 膨胀的问题,引入 TreeAttention 等机制控制计算规模;同时开发多种高性能融合算子(基于 Triton 或 CUDA),进一步降低推理延迟。

四、实验
4.1 离线实验
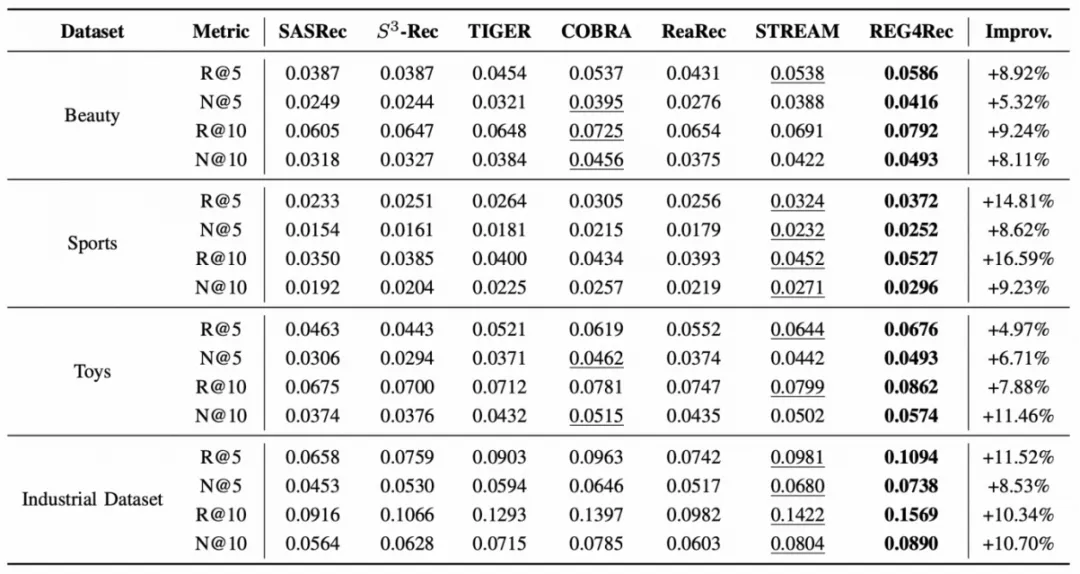
为了验证 REG4Rec 的有效性,实验采用 Recall@K 和 NDCG@K 作为离线评估指标,并在三个公开数据集和一个工业数据集上,与多个主流推荐模型进行了系统对比。结果显示,REG4Rec 在各项核心指标上均显著优于现有的判别式与生成式推荐基线,整体召回效果取到了稳定领先。
图 4 REG4Rec 离线实验结果
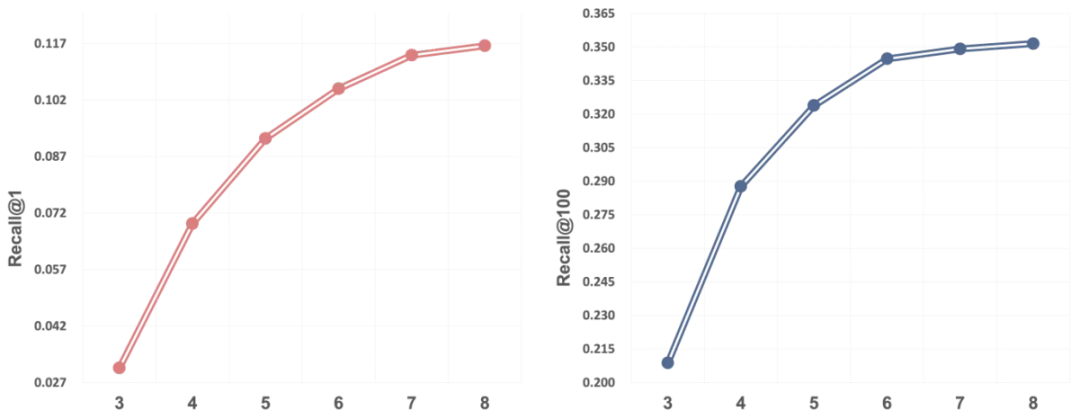
此外,REG4Rec 在生成过程中引入了更长的推理与选择机制。在并行码本设定下,对比了不同推理步数对召回效果的影响。可以看到,随着推理步数增加,离线指标呈现稳定的 Scaling Up 趋势。模型能够在多步生成中逐步细化用户意图,并通过迭代推理持续收紧语义约束,从而生成结果更贴合个体偏好。
尤其当推理步数从 3 步提升到 5 步时,Recall 指标出现明显跃升,其中 Recall@1 提升 123%,Recall@100 提升 37%。当推理步数进一步增加到 6 步时,REG4Rec 的 Recall@100 开始超越传统检索式方法,这表明,推理增强的生成式推荐不仅在个性化表达与意图理解上具备优势,也在泛化能力与召回效果上超过判别式范式。
图 5 REG4Rec 推理步数 Scaling Up
4.2 在线实验
在阿里巴巴 Lazada 推荐广告业务中,REG4Rec 进行了超大规模线上 A/B 测试中。REG4Rec 在多项核心业务指标上取得显著提升,并已完成全流量推全。
图 6 REG4Rec 在线实验效果

五、总结与展望
生成式推荐正在从「能生成」走向「会推理」。当推荐不再停留在表征匹配,而是像大语言模型一样把推理过程纳入生成本身,模型就能在多步生成中持续思考、选择和反思,从而更贴近用户真实兴趣与决策逻辑。REG4Rec 沿着这一思路,将「推理即生成」的范式落到工业级推荐系统中,并围绕表征、训练与部署三条主线打通端到端链路。
在表征侧,MMQ 并行语义码本与动态解码空间共同扩展了更大规模的决策空间;在训练侧,基于 GRPO 的偏好对齐与多步奖励设计,显式引导模型在该空间内进行有效探索,逐步学习到更一致、更可靠的语义轨迹;在部署端,一致性驱动的反思剪枝配合多步松弛检索,在控制计算开销的同时抑制语义漂移、降低漏召风险,让生成策略与线上检索机制更自然对齐。展望未来,生成式推理仍有三条值得持续深入的方向:
-
更具结构化的反思纠偏机制:当前线上主要依靠一致性信号对解码轨迹做实时筛选与剪枝,能够有效压制语义漂移,但对早期错误往往缺少可学习的定位与修正能力。下一步更关键的是把反思从规则化过滤升级为模型内生的推理能力,在生成过程中引入结构化的反思与纠偏机制,让模型能够显式识别偏差并进行针对性修正,从源头缓解自回归带来的误差累积,进一步提升长链推理的稳定性与可控性。
-
更具差异性的多目标建模:电商推荐天然是多目标系统,点击信号密集而转化信号稀疏,二者的学习难度与决策逻辑并不对等,但不少方法在点击与转化上仍沿用近似同构的结构与训练目标。未来可以面向转化等高价值行为做更有针对性的建模与训练,让模型在推理时更聚焦高指示性线索,真正做到按目标组织推理路径与生成策略。
-
更灵活的奖励融合机制:目前的多奖励融合仍相对简单,难以刻画不同信号之间的协同与制约关系。后续需要探索更自适应的奖励融合与权衡策略,使模型在命中率、语义连贯、类目对齐与检索覆盖之间实现更稳定的平衡,持续逼近帕累托最优,并提升跨场景迁移与泛化能力。
团队介绍:本文来自阿里国际-智能技术-Lazada推荐广告算法团队。团队聚焦生成式推荐、大模型算法、用户超长序列建模与多场景建模等前沿方向,致力于构建工业级推荐大模型,通过更深刻地洞察用户个性化偏好与决策逻辑,持续提升商家投放效益与平台收益。近年来,团队在前沿算法领域持续深耕,已在 WWW、SIGIR、CIKM、WSDM 等顶级学术会议发表多篇高质量论文。也欢迎感兴趣的同学加入我们,共同开创AI推荐的新篇章。
组内前序工作:
[1]. Haibo Xing, Kanefumi Matsuyama, Hao Deng, Jinxin Hu, Yu Zhang, and Xiaoyi Zeng. 2025. ESANS: Effective and Semantic-Aware Negative Sampling for Large-Scale Retrieval Systems. In Proceedings of the ACM on Web Conference 2025 (Sydney NSW, Australia) (WWW ’25). Association for Computing Machinery, New York, NY, USA, 462–471.
[2]. Hao Deng, Haibo Xing, Kanefumi Matsuyama, Yulei Huang, Jinxin Hu, Hong Wen, Jia Xu, Zulong Chen, Yu Zhang, Xiaoyi Zeng, et al . 2025. Heterrec: Heterogeneous information transformer for scalable sequential recommendation. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3020–3024.
[3]. Yi Xu, Moyu Zhang, Chenxuan Li, Zhihao Liao, Haibo Xing, Hao Deng, Jinxin Hu, Yu Zhang, Xiaoyi Zeng, and Jing Zhang. 2025. MMQ: Multimodal Mixture-of-Quantization Tokenization for Semantic ID Generation and User Behavioral Adaptation. arXiv:2508.15281 [cs.IR] https://arxiv.org/abs/2508.15281
