FedDRM开启联邦学习新范式,从“聚合”到“引导”,让服务器具备客户端智能路由能力,提升系统准确率。
原文标题:ICLR 2026 | 从「聚合」到「引导」:FedDRM开启客户端智能路由新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到FedDRM在医疗影像数据集上取得了显著提升,那么除了医疗领域,你认为FedDRM在哪些其他领域有潜在的应用价值?
3、文章中提到,FedDRM通过密度比估计来解决客户端路由问题,这个思路是如何体现“利用异质性”而非“消除异质性”的?
原文内容

本文第一作者为中国人民大学王梓鉴,通讯作者为中国人民大学张琼老师 (https://sarahqiong.github.io/) 。其他作者还包括中南财经政法大学章晓菲老师以及华东师范大学刘玉坤老师。
在传统联邦学习(Federated Learning, FL)中,统计异质性常被视为一种系统性障碍。具体而言,客户端之间数据分布的差异性,往往导致训练统一的全局模型难以适配所有客户端的需求;而个性化方法虽能提升本地性能,却往往令系统陷入客户端「各自为政」的僵局,从而丧失了整体的协同能力。对此,本文提出一种不同观点:数据异质性并非噪声,而是信息。关键不在于消除它,而在于利用它。
本文提出的 FedDRM 将联邦学习从传统的「聚合范式」拓展到「路由范式」:服务器不再只负责模型聚合,还能对来自系统外部的请求进行判断,并将其路由到最合适的客户端来处理。

-
论文地址:https://arxiv.org/abs/2509.23049v2
-
代码地址:https://github.com/zijianwang0510/FedDRM
要点速览
一句话概括,FedDRM 让服务器第一次具备了「把问题交给最合适的客户端处理」 的能力。
-
首次把联邦学习中的客户端路由问题建模为密度比估计问题
-
通过密度比模型(Density Ratio Model, DRM)+ 经验似然(Empirical Likelihood, EL),自然地得到了一个统一的目标函数,可以同时学习:模型预测能力和客户端路由能力
-
无需额外的生成模型,只需在现有网络上增加一个轻量分支即可实现系统级智能
-
在通用自然图像数据集 CIFAR-10/100 与专业医疗影像数据集 RETINA 上,系统准确率取得稳定提升
为什么现有联邦学习方法不会「客户端路由」?
设想一个真实场景:不同医院各自擅长治疗不同疾病。当一位新患者出现时,最关键的问题其实并不是把所有医院的意见汇总起来做决策,而是这位患者应该被转诊到哪一家最合适的医院就诊。
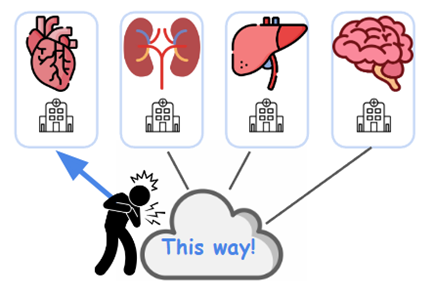
遗憾的是,现有联邦学习方法并没有回答这个问题。主流个性化 FL(如 FedAvgFT、FedRep) 虽然训练出了多个客户端本地模型,但在系统层面仍存在明显不足,当面对系统外部的请求时:
-
服务器缺乏对请求进行匹配与分发的机制与依据
-
通常只能采用平均、投票或随机选择等粗粒度策略
换句话说,它们训练的是多个「好模型」,但缺少的是选择哪个模型的能力。
把「客户端路由」变成一个可以学习的问题
如果希望服务器真正具备客户端路由的能力,就必须回答一个更基础的问题:给定一个新样本,它更像是来自哪个客户端的数据?
一旦这样表述,客户端路由问题就自然转化为了一个跨客户端的样本边际分布估计与判别问题。
FedDRM 将每个客户端的样本边际分布建模为对一个共享的基础分布的指数倾斜,用少量参数刻画客户端之间的统计异质性。
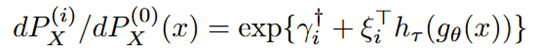
另一个关键挑战是:一旦对基础分布作出强参数化假设,若与真实生成过程不符,就会引入模型误设偏差,并进一步影响路由决策。
因此,FedDRM 进一步引入了经验似然方法,使得基础分布不依赖具体的参数形式,而是完全由数据驱动。
在 DRM+EL 框架下,可以证明,最大化经验似然函数等价于最小化两个交叉熵风险之和:
-
目标分类损失:学习任务本身
-
客户端分类损失:学习样本来自哪个客户端
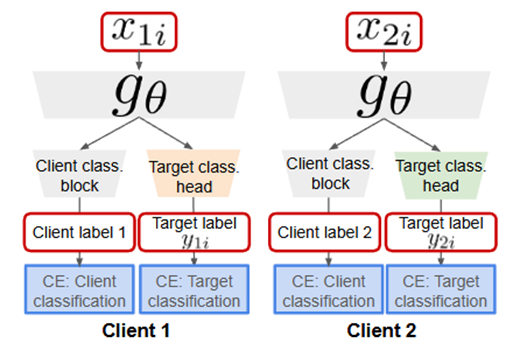
因此,这并不是人为拼接的多任务技巧,而是统计建模推导出的必然形式。模型在训练中,同时获得了两种能力:1)对任务的判别能力;2)对数据来源的识别能力。从而在同一个模型中,自然统一了个性化建模与系统级路由决策。
如何评估一个联邦系统是否具备「路由能力」?
传统 FL 只聚焦于客户端本地准确率,无法反映出系统层面的关键能力:当一个来自系统外部的全新查询到来时,服务器能否做出正确的分发决策,把请求交给最合适的客户端处理。因此,我们引入系统准确率(System Accuracy):
1. 服务器先根据样本特征预测最匹配的客户端
2. 再由相应的客户端的本地模型完成预测
这更接近真实部署流程,而非理想化的已知归属测试。
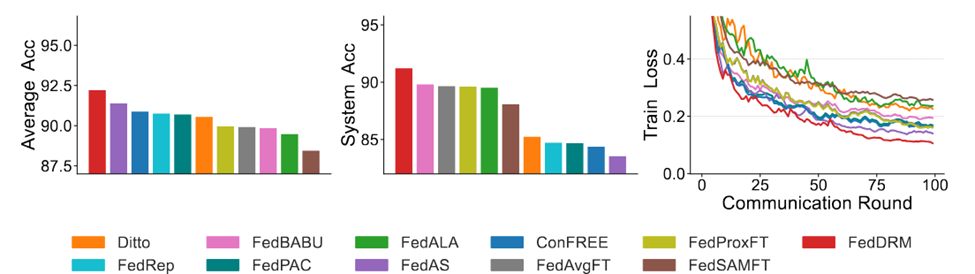
实验结果:系统与个性化的双赢
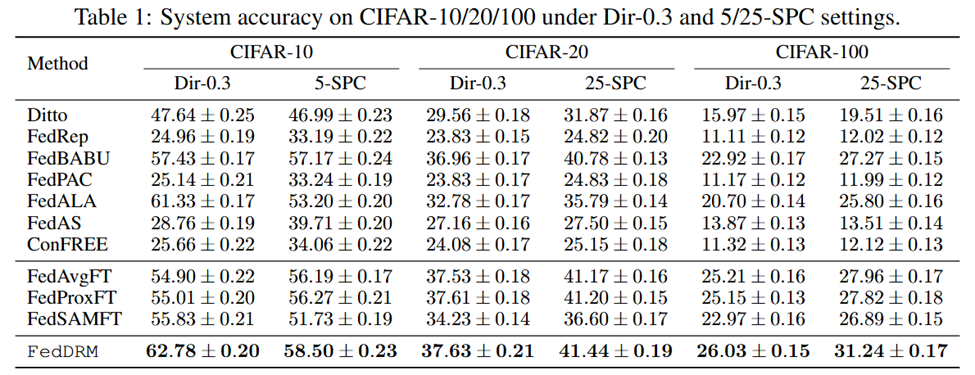
在 CIFAR-10/100 与 RETINA 数据集上的实验表明:
-
系统级准确率相比现有个性化 FL 方法取得一致提升
-
在真实医疗数据集 RETINA 上的提升约 1.41%–7.67%
-
训练过程稳定,无需复杂的生成模型
这意味着什么?
FedDRM 改变的不只是模型性能,更是联邦学习系统作为整体的服务方式。服务器不再仅仅做参数共享与模型聚合,而是能够对外部请求进行分布推断与路由决策,把查询交给最合适的客户端处理,从而使联邦系统首次以一个整体的身份对外提供服务。这为许多真实场景提供了新的可能性:
-
医疗协作:将病例自动匹配到最合适的医院模型
-
金融风控:根据用户分布差异调用专属风险模型
-
物联网:让边缘节点成为可调度的「专家网络」
联邦学习不再只是保护隐私的训练框架,而开始成为一个具备结构化决策能力的智能系统。我们也非常期待来自各方的讨论与反馈,一起探索:当系统真正「理解异质性」之后,联邦学习还能走多远。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com