北大彭宇新团队提出NS-Diff,为扩散模型装上“物理引擎”,结合物理约束与强化学习,显著提升视频生成的物理真实感,有效降低运动误差和流体发散。
原文标题:CVPR 2026 | 给扩散模型装上「物理引擎」: 北大彭宇新团队提出NS-Diff,使扩散模型学会流体与刚体力学
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到的“最小急动度原则”和“简化纳维-斯托克斯方程”分别是如何约束刚体和流体运动的?在实际应用中,这些约束会带来哪些挑战?
3、NS-Diff 如何平衡物理真实性和视觉质量?仅仅是符合物理规律的视频就足够了吗?
原文内容

本文是北京大学彭宇新教授团队在文本生成视频领域的最新研究成果,相关论文已被 CVPR 2026 接收。

-
论文标题:NS-Diff: Fluid Navier–Stokes Guided Video Diffusion via Reinforcement Learning
-
论文链接:http://39.108.48.32/mipl/download_paper.php?fileId=202601
-
开源代码:https://github.com/PKU-ICST-MIPL/NS-Diff_CVPR2026
-
实验室网址:https://www.wict.pku.edu.cn/mipl
背景与动机
想象一下,当你让 AI 生成一段「牛奶倒入咖啡产生丝滑旋涡」的视频时,却发现 AI 根本无法生成出你想要的「丝滑旋涡」。虽然如今的 Sora、Wan 等视频生成模型已经能做出如电影般华丽的画面,但它们往往只是「画皮难画骨」—— 因为 AI 并不真正懂得现实世界的物理定律,导致生成的视频经常出现违背常识的「穿帮」镜头。
在物理世界中,液体的流动遵循着复杂的纳维 - 斯托克斯(Navier-Stokes)方程,而刚体的运动则有着严谨的轨迹规律。实现视频生成从「视觉真实」向「物理真实」的跨越,是当前 AIGC 领域的重大挑战。
针对这一难题,北京大学彭宇新教授团队提出了给扩散模型装上「物理引擎」的新方案 ——NS-Diff。该研究将物理约束与强化学习相结合,通过物理动力学检测器和物理条件注入模块,让 AI 像人类一样在生成画面的同时,脑子里还紧绷着一根「物理定律」的弦。
实验表明,NS-Diff 将视频中的运动急动度(jerk)误差降低了 43%,流体发散度降低了 33%,使 AI 生成的每一帧画面不仅好看,而且遵循物理规律。这一成果表明将经典物理约束融入视频生成大模型,是解决视频生成中物理失真问题的有效途径。
技术方案
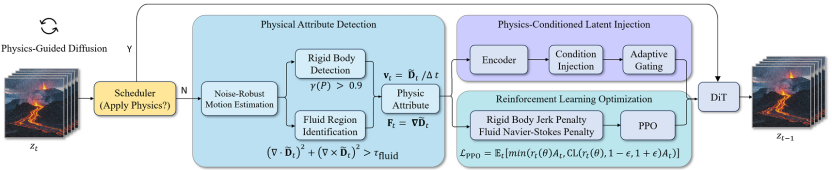
图 1. 物理引导的视频生成强化学习框架 NS-Diff
本文提出了一种物理引导的视频生成强化学习框架 NS-Diff,将物理约束融入视频扩散过程中,以提升生成视频的物理真实感。其主要贡献包括:(1)噪声鲁棒的物理动力学检测器:设计了可在含噪潜在帧中精准分析运动信息的检测器,实现对刚体与流体区域的有效区分。(2)物理条件潜在注入模块:将速度场、形变梯度等关键物理信息编码,并通过交叉注意力机制注入 DiT 去噪器,从而实现对生成过程的物理引导。(3)强化学习优化模块:引入强化学习,通过策略梯度对流体施加简化的纳维 - 斯托克斯约束,对刚体施加最小化急动度(Jerk)原则,确保了视频生成中动态过程的物理合理性。具体如下:
1. 噪声鲁棒的物理动力学检测器
实现物理引导去噪的关键在于高噪声环境下对运动和材料属性的精准估计。由于去噪过程在隐空间(latent space)中运行,直接在 RGB 帧上使用 ARFlow 是不可行的。为此,本文设计了一种结合隐空间解码的运动估计方案,具体流程如下:
(1)全局运动补偿 (Global Motion Compensation):在检测局部刚体或流体区域前,首先利用全局单应性矩阵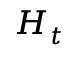 估计相机的全局运动。通过对原始光流
估计相机的全局运动。通过对原始光流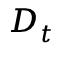 进行补偿,消除由相机移动引起的运动干扰,后续的区域检测均在补偿后的光流上进行。
进行补偿,消除由相机移动引起的运动干扰,后续的区域检测均在补偿后的光流上进行。
(2)隐空间 - RGB 空间解码 (Latent-to-RGB Decoding):在选定的去噪步![]() ,使用预训练 VAE 解码器将潜变量
,使用预训练 VAE 解码器将潜变量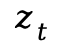 解码为低分辨率的 RGB 代理图像
解码为低分辨率的 RGB 代理图像 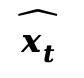 。这种部分解码在保持计算效率的同时,能提供足够的空间结构信息用于光流估计。随后,利用 ARFlow 计算代理图像间的运动光流。
。这种部分解码在保持计算效率的同时,能提供足够的空间结构信息用于光流估计。随后,利用 ARFlow 计算代理图像间的运动光流。
(3)噪声鲁棒的光流估计:通过在噪声样本上微调的 ARFlow ,计算相邻代理图像间的光流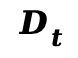 ,并利用
,并利用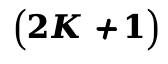 帧的时间滤波器得到平滑光流
帧的时间滤波器得到平滑光流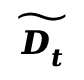 。
。
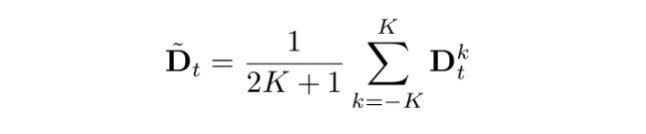
(4)材质区域分割:针对每个分块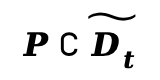 ,本文通过求解仿射变换(矩阵
,本文通过求解仿射变换(矩阵![]() 捕捉线性变形 / 旋转,
捕捉线性变形 / 旋转,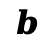 捕捉平移)来显式建模平面刚体运动。
捕捉平移)来显式建模平面刚体运动。
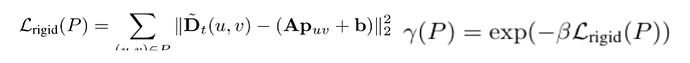
根据该分数,本文将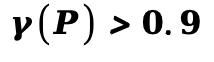 的区域标记为刚体区域;同时,将满足速度场散度与旋度平方和大于阈值
的区域标记为刚体区域;同时,将满足速度场散度与旋度平方和大于阈值 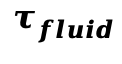 的区域标记为流体区域。
的区域标记为流体区域。
2. 物理条件潜在注入
为了将物理特征反馈给扩散模型,本文设计了 PCLI 模块,将运动动力学和材质嵌入整合进 DiT 的中间特征中。本文为每个分块提取物理描述符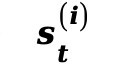 ,包含:速度场
,包含:速度场 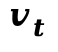 (光流的时间导数)、变形梯度
(光流的时间导数)、变形梯度 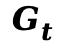 (运动的空间雅可比矩阵)以及材质嵌入
(运动的空间雅可比矩阵)以及材质嵌入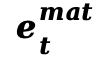 。这些特征通过一个双层 MLP 投影为
。这些特征通过一个双层 MLP 投影为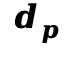 维的物理嵌入向量
维的物理嵌入向量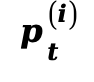 。
。
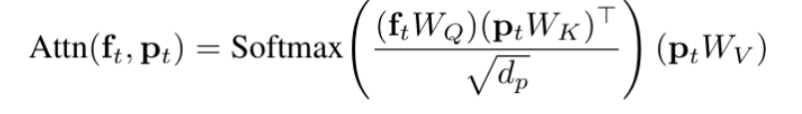
此外,本文引入了一个自适应门控机制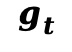 ,确保在去噪轨迹的不同阶段动态调整物理约束的影响力。
,确保在去噪轨迹的不同阶段动态调整物理约束的影响力。
3. 物理引导的强化学习优化
本文将扩散器![]() 参数化为一个随机策略
参数化为一个随机策略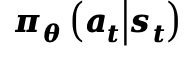 ,动作
,动作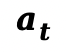 (预测的噪声残差)从以
(预测的噪声残差)从以 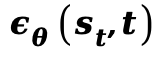 为中心的控制分布中采样。
为中心的控制分布中采样。
(1) 刚体平滑度正则化:最小加加速度原则 (Minimum-Jerk Principles) 针对刚体区域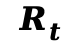 ,本文采用最小急动度先验来消除非物理的高频振荡。该约束通过惩罚运动轨迹的高阶导数(加速度的变化率)来确保时间连续性。
,本文采用最小急动度先验来消除非物理的高频振荡。该约束通过惩罚运动轨迹的高阶导数(加速度的变化率)来确保时间连续性。
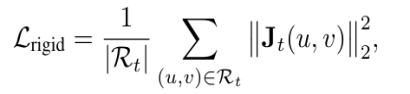
(2) 流体动力学惩罚:简化纳维 - 斯托克斯方程 (Navier-Stokes Constraints),针对流体区域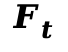 ,本文采用了 Navier-Stokes 方程的轻量化近似。核心在于最小化速度场散度的空间梯度,作为压力修正的微分代理,从而在不求解复杂泊松方程的情况下诱导流体趋向不可压缩状态。
,本文采用了 Navier-Stokes 方程的轻量化近似。核心在于最小化速度场散度的空间梯度,作为压力修正的微分代理,从而在不求解复杂泊松方程的情况下诱导流体趋向不可压缩状态。
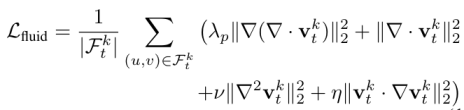
(3) 策略更新 (PPO Objective):最终,物理感知奖励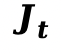 定义为刚体与流体惩罚项的负加权和。本文应用近端策略优化(PPO)算法来更新 DiT 策略参数
定义为刚体与流体惩罚项的负加权和。本文应用近端策略优化(PPO)算法来更新 DiT 策略参数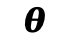 。
。
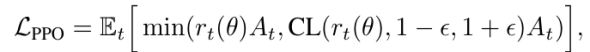
4. 物理引导的自适应激活
由于去噪初期的噪声水平过高,会导致运动估计不可靠。本文引入了一个自适应激活调度器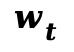 。
。
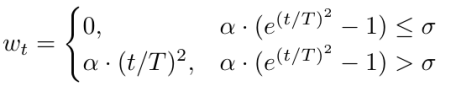
该权重同时作用于 PCLI 的注入强度和强化学习的奖励值,使得物理引导在去噪后期(噪声较低、物理估计较准确时)平滑地达到满额强度,从而确保训练的稳定性。
实验结果
1. 实验设置
本文在 PhysVideoBench 以及 UCF-101(包含 13,320 个真实世界人类动作视频)和 WebVid-10M(包含 1000 万个带有文本描述的互联网视频)。本文从物理合理性和视觉质量两个角度对本文方法进行评估。
(1)物理指标:
-
急动度误差(Jerk Consistency,
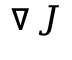 ):通过计算质心轨迹的三阶时间导数的幅值,来衡量刚体运动的时间平滑度。
):通过计算质心轨迹的三阶时间导数的幅值,来衡量刚体运动的时间平滑度。 -
流体散度误差(Fluid Divergence Error,
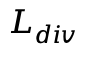 ):根据光流真值计算得出的散度误差
):根据光流真值计算得出的散度误差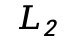 范数。
范数。
(2)视觉指标:
-
VBench:综合视频质量指标。本文遵循 VideoJam 的方法计算视频外观和运动质量。
-
Fréchet Video Distance(FVD):衡量真实视频与生成视频之间的分布距离。
-
Frame Consistency:相邻帧的 CLIP 图像嵌入之间的平均余弦相似度,反映了时间上的连贯性。
2. 对比实验结果
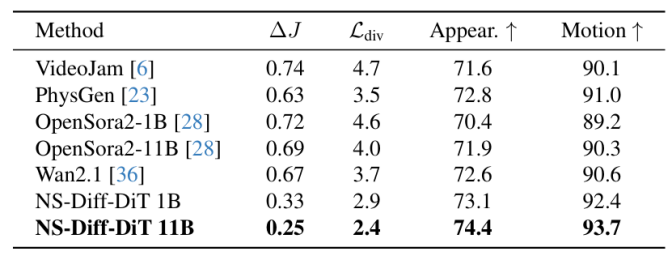
表 1. PhysVideoBench 数据集结果
在 PhysVideoBench 上,NS-Diff 在所有指标上均实现了最佳性能。通过潜空间注入(Latent Injection)以及 Jerk / 散度损失(Jerk/divergence losses)引入物理先验,提升了运动的真实性,尤其是在刚体和流体区域。相比于在给定用户外力情况下模拟刚体动力学的 PhysGen,NS-Diff 在不需要预定义外力或模拟的情况下实现了更好的泛化能力,同时保持了更高的保真度和更低的散度误差。实验表明,本文的方法将 Jerk 误差降低了 43%,流体散度降低了 33%,并使 FVD 提升了 22.7%,实现了更高的物理合理性和视觉质量。
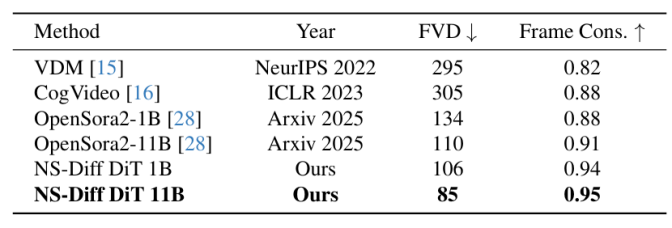
表 2. UCF-101 数据集结果
在 UCF-101 基准测试中,本文的 NS-Diff 模型表现出色。具体而言,NS-Diff DiT 1B 版本的 FVD 为 106,帧一致性(Frame Consistency)达到 0.94;而 NS-Diff DiT 11B 版本则进一步将 FVD 降低至 85,帧一致性提升至 0.95。这表明本文的方法不仅提升了运动的物理准确度,还显著增强了生成视频的时间连贯性。
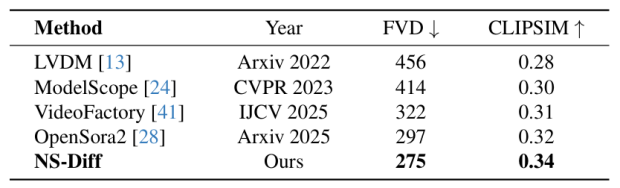
表 3. WebVid-10M 数据集结果
为了评估物理引导学习框架在受限基准测试之外的开放世界场景中的泛化能力,本文在 WebVid-10M 数据集上进行了文本生成视频(Text-to-Video)合成测试。实验旨在测试物理约束(刚体 / 流体动力学)在面对包含新颖物体交互和环境的未知文本描述时,是否仍能保持合理性。本方法在运动质量(FVD)和文图对齐(CLIPSIM)两个指标上均优于 VideoFactory。

图 2. 可视化对比结果
图 2 展示了 NS-Diff 与 ModelScope、PhysGen、Wan2.1 以及 OpenSora2 的视觉效果对比。结果分析表明,本文方法生成的视频在刚体和流体运动方面表现得更加真实,显著减少了诸如物体无故出现或消失、以及非自然的拆分或合并等不符合物理规律的伪影。此外,本文方法还大幅提升了帧间一致性,在处理篮球投篮、火山熔岩流、玻璃破碎等物理密集型场景时,能够比对比模型展现出更高的时间连贯性和运动可信度。
结论
本文提出了一种基于强化学习的物理引导视频扩散框架 NS-Diff。该框架通过抗噪物理动力学检测器,实现了对视频潜空间中刚体与流体区域的精准识别。利用物理条件潜空间注入技术,速度场、变形梯度及材料掩码被有效整合至去噪流程中。此外,本文方法通过强化学习优化机制,将纳维 - 斯托克斯方程与最小急动度(Minimum-Jerk)原则转化为训练约束,强制模型遵循物理运动规律。实验结果表明,NS-Diff 在 PhysVideoBench、UCF-101 等多个基准数据集上超过现有方法,在显著降低物理运动误差的同时,确保了视觉生成质量。研究表明,将经典物理约束深度融合于生成模型,是解决视频生成中物理失真问题的有效途径。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com