北航、清华、北大联合提出HACRL:一种新的异构智能体协同强化学习范式,实现异构智能体训练时协同优化、推理时独立执行,有效提升性能并降低采样成本。
原文标题:北航,清华,北大联合发布: 异构智能体协同强化学习!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、HACPO算法中的“能力感知的优势估计”是如何避免“强者恒强,弱者恒弱”的马太效应,从而保证所有智能体都能受益的?
3、HACRL范式在未来的发展中,可能面临哪些挑战?你认为应该如何应对这些挑战?
原文内容


-
论文标题:Heterogeneous Agent Collaborative Reinforcement Learning
-
论文链接:https://arxiv.org/abs/2603.02604
-
Github Page: https://zzx-peter.github.io/hacrl/
-
Huggingface: https://huggingface.co/papers/2603.02604
主要贡献
-
异构协同强化学习(HACRL)新范式:多个在参数状态、模型规模乃至架构家族上存在异构性的智能体,在训练阶段共享经过验证的 rollouts 实现协同策略优化,而在推理阶段各自独立部署执行。该范式既不同于需协同执行的多智能体强化学习,也区别于单向的 "教师 — 学生" 知识蒸馏 ——HACRL 首次实现了异构智能体间的双向互学与独立部署的统一:训练时协同优化,推理时各自独立运行。
-
异构协同策略优化(HACPO) 算法,通过四项关键技术弥合智能体间的能力与策略分布差异。
-
实验结果:在多个数学推理基准上,使所有参与智能体的性能均获得一致提升,平均性能超越基线方法 3.3%,同时仅需一半的采样成本,为实现高效的多智能体协同学习指明了新方向。
问题背景:昂贵的 “单打独斗”,宝贵的 “异构数据”
-
当前大模型强化学习微调中,rollout 采样与校验成本是整个微调流程的核心瓶颈,严重制约训练效率与规模化落地。同时,现有的强化学习微调范式普遍采用孤立优化范式,模型各自独立采样、验证与策略更新。这就导致模型生成的高质量轨迹仅用于自训练迭代,宝贵探索经验无法复用,样本利用率极低,造成巨大算力浪费。
-
与此同时,大模型生态呈现显著异构性,不同架构、尺寸、状态的模型面向同一任务生成的 rollouts,在任务目标与格式上高度兼容,且携带互补知识。然而现有多智能体强化学习主要针对多智能体组成统一的系统,无法支持异构模型训练时协同优化,推理时各自独立运行的场景;知识蒸馏难主要针对同构模型单向学习,难以支持异构模型的双向学习。目前的范式中,异构数据的价值没有被有效发掘。
论文的核心问题是:一个智能体能否利用其他异构智能体生成的 rollouts 来同时提升效果和效率?
异构智能体共享 Rollout:HACRL 范式
为了解决训练过程中模型的 “单打独斗”,该工作提出了一个新方法 HACRL (Heterogeneous Agent Collaborative Reinforcement Learning),多个异构智能体在训练时可以共享彼此的 Rollout (Response + Reward),推理时则各自独立完成任务。HACRL 范式使得原本独立的智能体可以互相学习,同时提高了 Rollout 利用率。
HACRL 和现有的其它范式可不能混为一谈:
-
HACRL 不同于多智能体强化学习 (MARL): HACRL 强调多个独立的智能体在训练时共享 Rollout 进行协同优化,但是在推理时彼此是独立的;MARL 则是多个智能体在推理时相互合作。总结来说,HACRL 训练多个独立的模型,而 MARL 则是在训练一个整体的系统。
-
HACRL 也不同于在线 / 离线的蒸馏: HACRL 支持多个异构的智能体相互学习,而蒸馏则是更强的教师模型单向地向弱小的学生模型传递知识。总结来说,HACRL 是异构模型的相互学习,而蒸馏则是同构模型的单向传递。
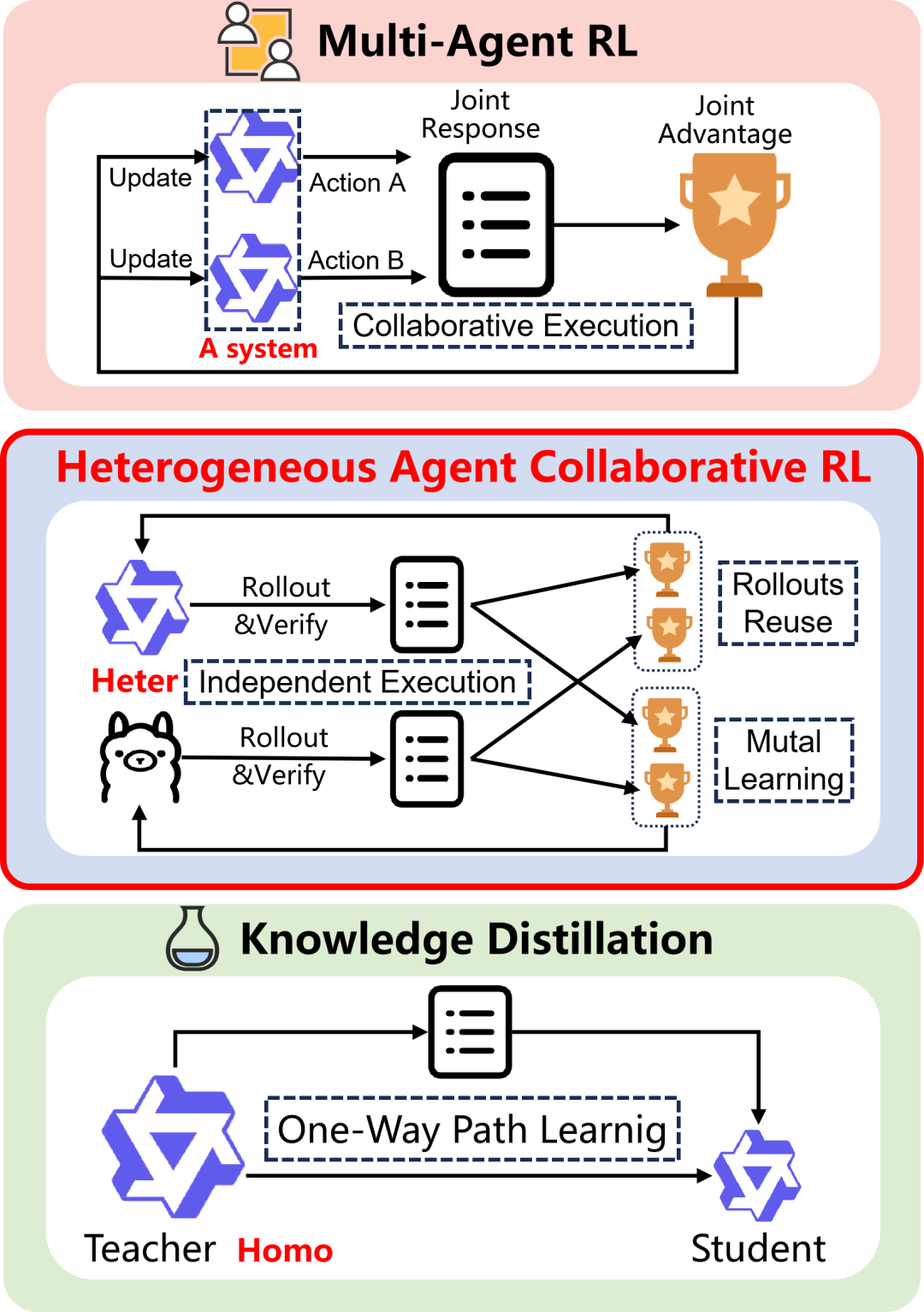
异构智能体强化学习 (HACRL) 与多智能体强化学习 (MARL)、知识蒸馏 (KD)
核心算法:HACPO
HACRL 可不是简单的 Rollout 共享!因为异构智能体之间存在着能力差异和策略分布差异,如果异构模型来自于不同的厂家,那么模型的分词器也会不同,在共享数据时出现工程问题。
为了求解 HACRL 问题,该工作提出了一个新算法 HACPO (Heterogeneous Agent Collaborative Policy Optimization)。它在基础的强化学习优化方法之上,引入了四项量身定制的修改,以弥合异构智能体之间的能力与分布差异。同时,该工作在理论证明了,利用自身和其它智能体 rollout 进行的梯度更新方向,在期望上具有小于 90 度的夹角。这表明 HACPO 是有效的。
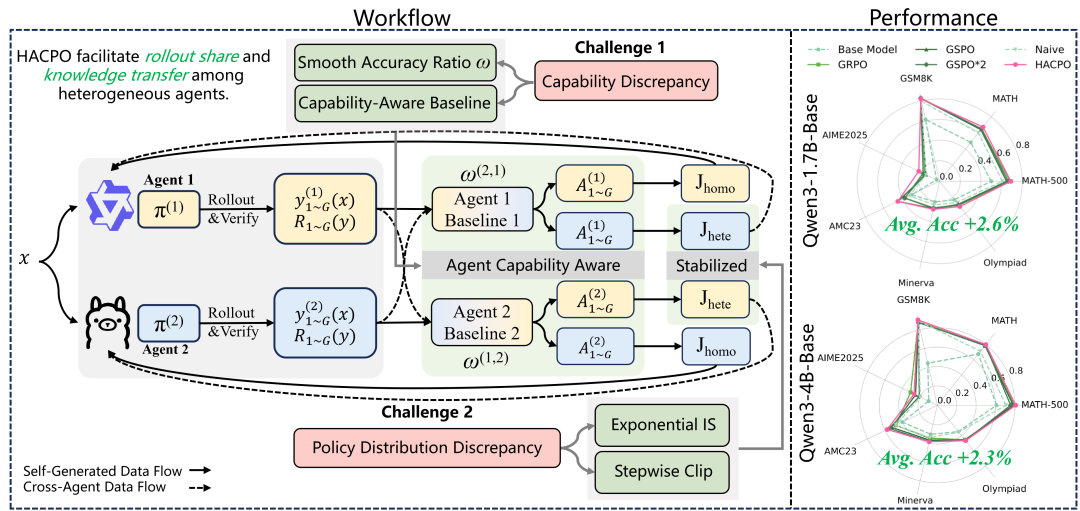
HACPO 的算法流程图
1. 智能体能力感知的优势估计 (Agent-Capability-Aware Advantage Estimation)
该工作提出了一种能力感知的估计器,它根据每个智能体的相对性能,为其分配不同的组间优势基线。直观上,如果一个回应由更强的智能体生成,其优势应更高;若由更弱的智能体生成,则其优势应更低。理论上,该估计器是无偏的。
在训练步骤 中,针对智能体 的第 个响应的优势是:
基线 的计算方式为:
其中, 是能力比率( 是智能体 在步骤 时的平滑准确度)。
2. 模型能力差异系数 (Model Capabilities Discrepancy Coefficient)
为了鼓励向更强的智能体学习,同时对较弱的智能体保持保守,该工作使用能力比率来调节有效优势。能力比率
扮演两个互补的角色:(i)基线校准 — 在估计能力感知基线时重新缩放奖励,以对齐异构智能体间的奖励统计量;(ii)梯度调制 — 它作为一个类似学习率的因子,放大来自更强智能体的梯度,并衰减来自更弱智能体的梯度。调制后的优势为:
3. 指数重要性采样 (Exponential Importance Sampling)
该工作采用序列级别的重要性比率并将其扩展到异构多智能体设置,同时引入了非梯度指数重加权。这种设计使智能体偏向于从那些输出分布与其自身更一致的 rollout 中学习。对于具有不兼容分词器的异构智能体组合,将对应反分词器(detokenizer)得到文本,再使用目标智能体的分词器(tokenizer)重新进行分词。
其中, 控制保守性的程度。
4. 逐步裁剪 (Stepwise Clipping)
跨智能体重要性采样比率在步骤之间和步骤内部都会不规则地波动。该工作首先对跨智能体回应应用非对称裁剪边界,以确保跨智能体回应只能被降权,而永远不会被增权。然后,应用逐步裁剪策略,以防止跨智能体经验在批次内的后期更新中占据主导地位,从而提高训练稳定性。
其中, 表示当前步骤内执行的参数更新次数, 表示每次更新的收紧因子。
实验现象:尺有所短,寸有所长
异构模型间的取长补短
实验设置与对比基线
该工作在 MATH 数据集 上选取 7500 道高质量数学问题,并在 七个具有挑战性的基准测试 上评估 HACPO 的性能。为严格验证协同训练范式的有效性,将 HACPO 与下列三类基线方法进行了对比:
-
标准单智能体基线:包括 GRPO、GSPO(Rollout 成本相同,参数更新成本只有 HACPO 的一半)
-
等资源基线(GSPO×2):用双倍 rollout 和更新次数,以排除因为数据量增大带来的提升(Rollout 成本是 HACPO 的一倍,参数更新成本相同)
-
朴素协同基线(Naive):简单共享 rollouts 的多智能体设置,但不包含 HACPO 的创新模块(Rollout 和参数更新成本都和 HACPO 相同)
该工作总结了三类异构,并分别进行了验证实验:
|
异构类型 |
定义 |
示例 |
|
状态异构 |
架构和参数相同,权重不同 |
Qwen3-4B 和 Qwen3-4B-Instruct |
|
尺寸异构 |
同一模型厂家,不同参数规模 |
Qwen3-1.7B-Base 和 Qwen3-4B-Base |
|
模型异构 |
不同模型厂家,架构、分词器都不同 |
Qwen3-4B-Base 和 Llama3.2-3B-Instruct |
主实验结果
结果分析
该工作在状态异构、尺寸异构、模型异构三中 setting 下进行了多种实验,实验结果表明了 HACPO 的有效性。同时,将 HACPO 的效果归因为以下两种机制:
-
能力驱动的指导:强模型提供更多高质量正确解,帮助弱模型更快提高。
-
互补知识的交换:弱模型作为 “不同探索器”,会产生强模型较少覆盖的推理路径与信息性错误,甚至少量强模型未采到的正确解,从而使强模型也获得可学习的补充信号。
状态异构:
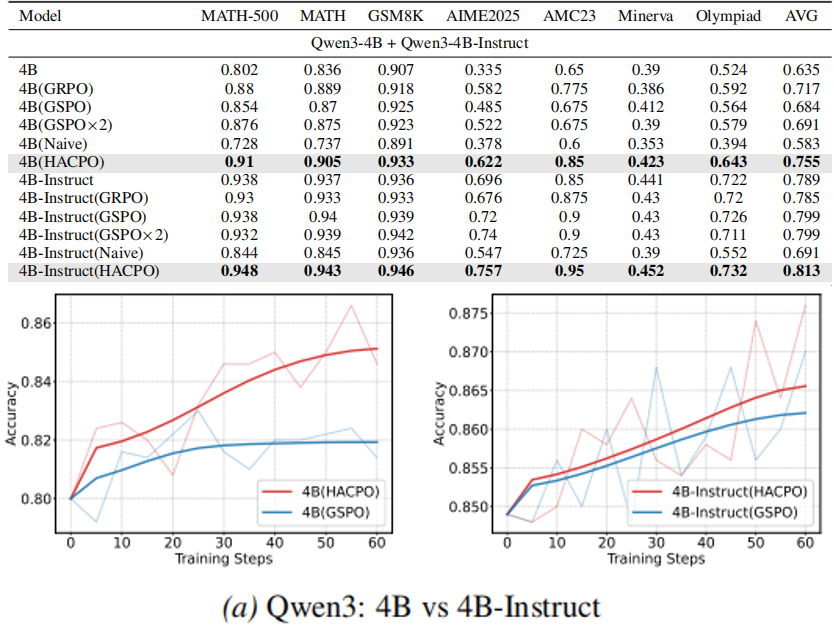
弱模型(Qwen3-4B)提高 7.1%,强模型(Qwen3-4B-Instruct)提高 1.4%。模型异构性低,因此主要是强模型帮助弱模型,而弱模型难以对强模型有帮助。
尺寸异构:
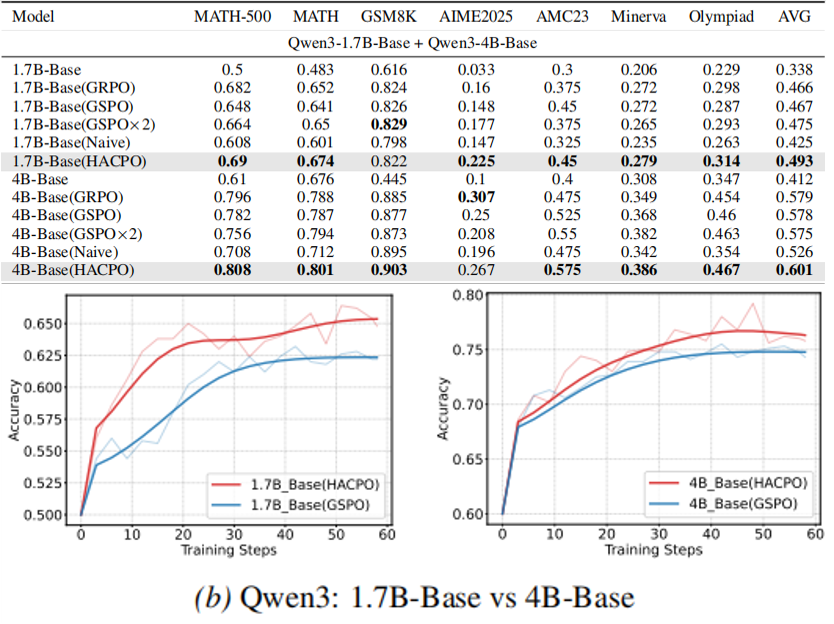
大小模型都有提升,Qwen3-1.7B-Base 提升 2.6%,Qwen3-4B-Base 提升 2.3%。尽管小模型的准确率低于大模型,其仍然可以为大模型提供一些难以覆盖到的错误路径和少量正确路径,提供互补知识。
模型异构:
即使模型异构程度很大,两个模型也都有提升。Qwen3-4B-Base 提高 1.9%,Llama3.2-3B-Instruct 提高 3.9%。这表明 HACPO 算法的通用性和鲁棒性。
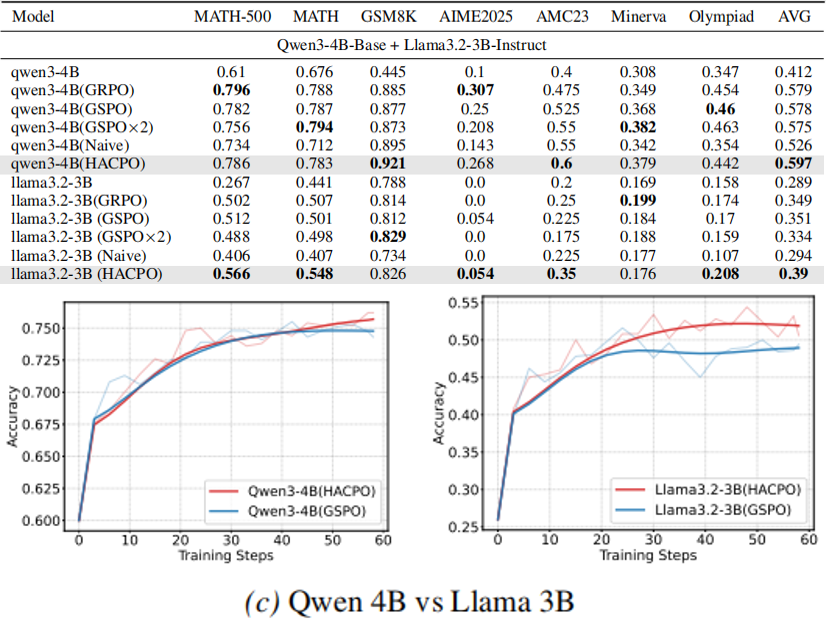
效率、效果双提升:
与等资源基线(GSPO×2)进行对比,HACPO 仅使用一半的 Rollout 成本,就实现了 3.3% 的性能提升。
消融实验
对于核心算法 HACPO 中的四个模块进行消融,实验证明了缺失任何一个模块都会导致模型性能的下降,表明了四个模块都是有效的。同时,指数重要性采样中的最佳指数在不同的模型组合上也会有不同。
讨论和展望
本文针对当前智能体强化学习面临的孤立优化采样成本高、异构大模型生态知识利用效率低的核心行业痛点,提出了异构智能体协同强化学习(HACRL)全新范式。该范式突破知识蒸馏单向师生传递的固有局限,实现了训练阶段异构智能体协同优化、推理阶段独立执行的核心设计。
面向未来,HACRL 范式的拓展方向主要包括以下几个方面:一是将适用场景从数学推理任务延伸至代码生成、多模态理解等更广泛的大模型核心下游任务,以验证其在通用场景下的普适性;二是探索更大规模的异构智能体协同训练网络,深入研究智能体间相互学习的效果边界与影响机制。此外,HACPO 的提出为跨异构智能体的数据统一复用奠定了初步框架,未来在迈向通用人工智能(AGI)的进程中,构建跨模型、跨领域的统一知识学习平台同样是不可或缺的重要方向。
作者:第一作者为北京航空航天大学本科生张之夏与博士生黄子轩,通讯作者为北京航空航天大学班义琨教授。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com