创智&Sand.ai开源daVinci-MagiHuman音视频基座模型,突破音视频生成三大难题,单流Transformer架构,高效且易于优化。
原文标题:创智刘鹏飞、Sand.ai曹越,两大AI青年学者团队联手,开源音视频基座模型
原文作者:机器之心
冷月清谈:
daVinci-MagiHuman 采用 Sandwich 式主干网络、无显式 timestep 条件注入和 Attention-Head 门控等技术,提升了生成质量和效率。同时,模型还结合隐空间超分、Turbo VAE 解码器、全图编译优化和模型蒸馏等手段,实现了快速高效的音视频生成。该模型在人物中心生成任务中表现出色,支持多种语言,并在主观和客观评测中均表现出领先水平。
此次开源包括完整的模型栈和推理代码,旨在为开源社区提供一个更简单、可扩展、易于优化的音视频生成基础系统。
怜星夜思:
2、daVinci-MagiHuman 模型在推理效率上做了很多优化,例如隐空间超分和 Turbo VAE 解码器。这些优化方法对最终的生成效果有什么影响?是否存在牺牲生成质量来换取效率的可能性?
3、该模型支持多种语言的音视频生成,这对模型的泛化能力提出了更高的要求。在多语言支持方面,daVinci-MagiHuman 可能采用了哪些技术手段?未来,如何进一步提升模型在小语种或方言上的表现?
原文内容
开源多模态生成领域,迎来架构级的底层突破。
视频生成已成为当前生成式 AI 最前沿的方向,但在音视频联合同步生成领域,开源界仍面临三重局限:
-
音视频不同步:视频和音频往往语义对齐精度不足。
-
架构设计复杂:现有方案要么将音频视为从属信号,要么通过复制骨干网络来处理音频,参数成本翻倍且推理优化困难。
-
生成速度慢:现有的音视频联合生成模型往往因为模型架构设计复杂、难以充分优化,从而导致生成速度较慢,难以满足交互式场景的需求。
今日,由上海创智学院(SII)生成式人工智能研究实验室(GAIR)与 Sand.ai 联合研发的 daVinci-MagiHuman 正式开源发布,打破了开源界的这三重局限。
作为演绎级人像音视频的开源基座模型,daVinci-MagiHuman 以 150 亿参数的单流 Transformer 为核心,实现了文本、视频、音频在统一骨干网络下的联合建模,彻底告别了跨注意力和模态专属分支。
-
代码仓库:https://github.com/GAIR-NLP/daVinci-MagiHuman
-
模型权重:https://huggingface.co/GAIR/daVinci-MagiHuman
-
在线 Demo 体验:https://huggingface.co/spaces/SII-GAIR/daVinci-MagiHuman
研发团队介绍
这一成果由上海创智学院(SII)GAIR 实验室 与 Sand.ai 共同完成。
上海创智学院是由顶尖大学、头部企业和科研机构联合建设的新型人才培养机构;其 GAIR 实验室由刘鹏飞博士领导,聚焦生成式人工智能的前沿研究,涵盖多模态视频基座模型、文本大模型预训练及智能体构建等方向。在多模态世界模型方面,实验室已展开了系统性探索:从开源首个原生无扩散的多模态模型 Anole,到提出以生成图像进行思考的新范式 Thinking with Generated Images,再到面向实时交互场景的 LiveTalk,以及面向数字世界理解与模拟的数字基因工作,逐步构建起从多模态生成、视觉推理到实时交互的完整研究链条。近期,该实验室已产出 daVinci-MagiHuman、Data Darwinism、daVinci-Agency、daVinci-Dev 等一系列代表性工作。
Sand.ai 则是由马尔奖得主曹越博士所创立,专注于开发视频生成大模型,并以推动通用人工智能(AGI)为目标。先后发布全球首个自回归视频生成模型 Magi-1,以及主打「AI 演员」表现力的 GAGA-1 模型,在物理规则连贯性和原生音画同步等领域都取得了突破性成果。
演绎级人像音视频的开源基座模型
daVinci-MagiHuman 是音视频联合生成的开源基座模型。与许多依赖多流结构、跨注意力模块或模态专用融合分支的方案不同,daVinci-MagiHuman 采用了更为简洁的单流 Transformer 架构,以 150 亿参数的统一骨干网络联合建模文本、视频与音频三种模态,彻底告别跨注意力和模态专属分支。这一设计不仅降低了系统复杂度,也让训练与推理优化更加直接、统一。
在能力上,daVinci-MagiHuman 尤其擅长以人物为中心的生成任务,能够生成富有表现力的面部表情与自然语音,并实现精确的音视频同步,覆盖语音与口型协调、表情驱动、动作表现等场景。同时,模型具备较强的多语言泛化能力,支持中文(普通话与粤语)、英文、日文、韩文、德文、法文等多种语言的音视频生成。
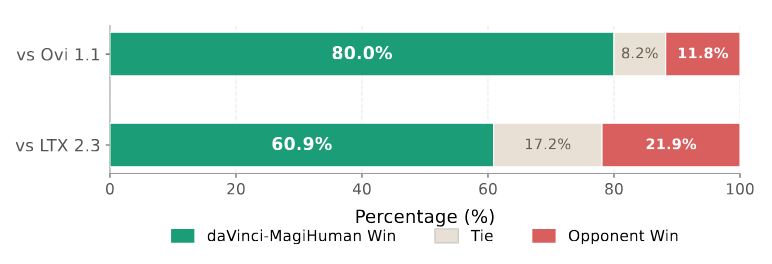
在推理效率方面,daVinci-MagiHuman 结合单流骨干网络、隐空间超分辨率与 Turbo VAE 解码器,在单张 H100 上仅需 2 秒即可生成 5 秒 256p 视频。在与 LTX-2.3、Ovi 1.1 的全面对比中,daVinci-MagiHuman 在成对人工评测中取得了 70.5% 的综合胜率,在客观基准上同样展现出领先表现。
核心技术揭秘:单流 Transformer 统管所有模态
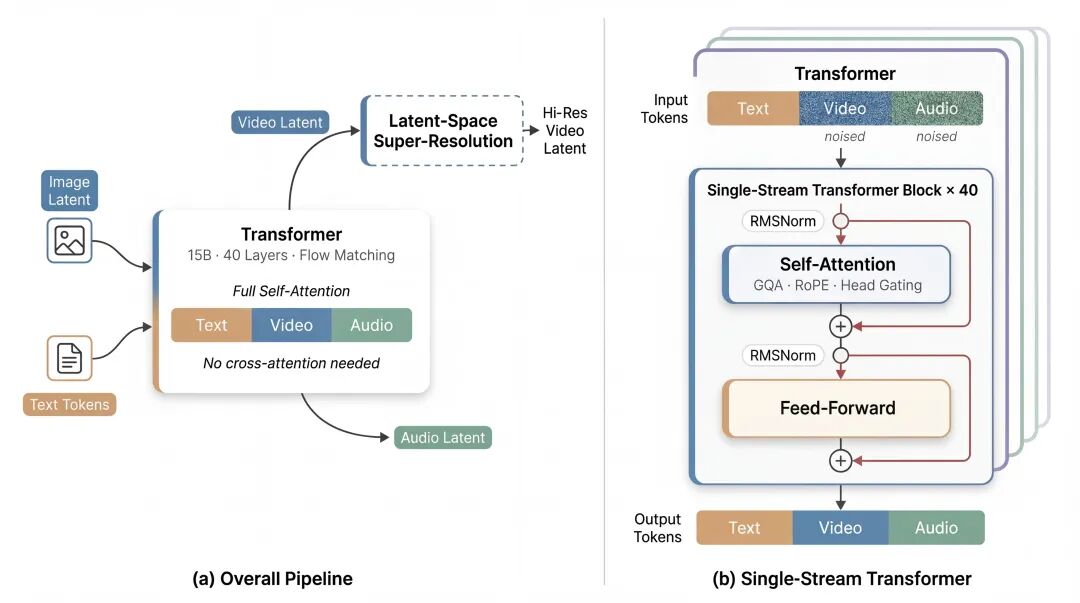
为了解决上述挑战,daVinci-MagiHuman 选择了一条更直接的路线:把文本、视频、音频统一放入同一个单流 Transformer 去噪网络中,以纯自注意力完成联合建模。在这一基础上,模型进一步采用了几项关键设计:
-
Sandwich 式主干网络:在单流 Transformer 去噪网络中,少数输入层和输出层保留模态相关参数化,主要的中间层主干网络共享参数,在模态特化与深层融合之间取得平衡。
-
无显式 timestep 条件注入:模型不再单独引入 timestep 条件,而是直接从当前噪声隐变量中推断去噪状态。
-
Attention-Head 门控:为了提升训练时的数值稳定性和提升 attention 的表达能力,研发团队进一步在每个 attention head 的输出引入了门控机制。
-
统一条件接口:文本、参考音频、参考视觉条件等都通过统一接口进入同一主干网络,而不是为不同任务单独设计融合结构。
面向效率的四层优化
除了去噪网络本身的先进设计,daVinci-MagiHuman 还围绕推理效率进行了系统级优化。
1. 隐空间超分
为了避免从头直接生成高分辨率视频带来的巨大开销,研发团队采用两阶段流水线:底模先在较低分辨率生成音视频隐变量,再通过隐空间超分对视频结果进行细化。整个超分过程直接在隐空间(latent space) 中完成,通过三线性插值、重新加噪和少量额外去噪步骤完成高分辨率细化,效果更好的同时避免额外的 VAE decode/encode 开销。
值得一提的是,这一阶段虽然主要服务于视频细化,但音频隐变量也会继续作为输入进入超分模型,并与视频一起在同一主干中联合建模。这种设计在底模分辨率较低、口型细节容易偏差的情况下尤其重要,有助于保持更好的唇形同步效果。
2. Turbo VAE Decoder
在视频编解码阶段,模型保留 Wan2.2 VAE 作为编码器,但在推理中使用更轻量的 Turbo VAE 解码器替换原始解码器,以降低视频解码延迟。由于解码位于底模生成和超分流水线的关键路径上,这一优化对整体推理速度非常重要。
3. 全图编译优化
研发团队进一步将自研的全图 PyTorch 编译器 MagiCompiler 集成到推理栈中。通过跨层算子融合、减少分布式通信开销等方式,它能够进一步提升推理吞吐与执行效率,并在 H100 上带来了约 1.2 倍的加速。
4. 模型蒸馏
研发团队还使用 DMD-2 技术对去噪网络进行蒸馏,从而实现了在推理阶段仅去噪 8 步就可以获得良好的音视频生成效果。
性能实测:全面对标开源 SOTA
先看实测效果:
研发团队针对 LTX-2.3、Ovi 和 MoVA 等最具代表性的开源模型进行了系统性测试。
主观评测:人工盲评
研发团队构建了 100 条样本的内部评测数据集,覆盖图文生音视频任务,由评审员从多个维度对各模型的生成结果进行盲评打分。
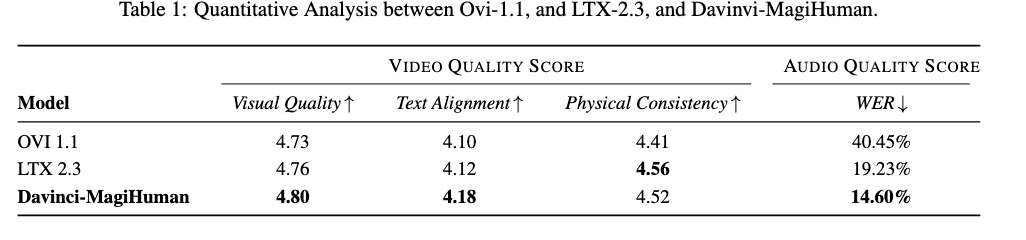
客观评测:VideoScore2 基准和 TalkVid-Bench 对比
VideoScore2 主要用来评测视频生成质量,其采用的指标包括视频生成质量(Visual Quality)、视频 - 文本一致性 (Text Alignment) 和物理一致性(Physical Consistency)。TalkVid-Bench 则主要用来衡量音频生成质量,其指标主要用词错误率(Word Error Rate, WER) 来衡量。 表 2 展示了客观指标的评测结果,daVinci-MagiHuman 在视觉质量、视频 - 文本一致性都领先于 LTX2.3,在物理一致性上与 LTX2.3 大致相当,优于 OVI 1.1。在音频质量上,daVinci-MagiHuman 则远优于 LTX2.3 与 OVI 1.1。
结语与未来展望
此次 daVinci-MagiHuman 的模型栈完整开源,包括生成模型、超分模型以及推理代码。这一发布有望能够为开源社区提供一个更简单、更可扩展、也更易于优化的音视频生成基础系统,持续降低音画同出大模型的开发与部署门槛,为 AI 社区贡献真正 “开箱即用” 的性能红利。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com