OpenAI暂停Sora 2之际,国产AI团队Sand.ai三连开源,包括150亿参数音视频大模型等,展现了其在AI视频生成领域的技术实力和开源胸怀。
原文标题:当Sora 2意外停摆,这个国产视频生成创业团队,直接「开源」三连击
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Sand.ai开源的三个组件,你觉得哪一个对行业的影响最大?为什么?
3、Sand.ai的Video Agent主要面向海外市场,你认为国内的AI视频创作生态还存在哪些机会?
原文内容
就在昨天,全球 AI 视频生成领域迎来了一场 “超级地震”——OpenAI 竟然意外叫停了万众瞩目的 Sora 2 项目。
然而,就在行业巨头调整研发节奏的同一周,开源社区迎来了一波扎实的技术推进。一家位于北京的 AI 初创公司,在 GitHub 上连续三天释出了其核心技术栈 —— 依次开源了 150 亿参数的 “演绎级” 音视频同出大模型、重新定义算力上限的分布式 Attention 组件,以及旨在突破显存瓶颈的全局编译框架。
这家持续向开发者社区贡献底层技术的公司,正是 Sand.ai。今天,我们就来深度拆解这家公司的技术脉络,看看这支中国团队是如何在当前的行业转折期中,走出一条独立的视频生成技术路线。
连续三天开源:一场自顶向下的技术拆解
第一天:演绎级音视频基座
针对当前 AI 视频 “表演僵硬” 与 “音画不同步” 的痛点,Sand.ai 联合上海创智学院(SII)GAIR 实验室,开源了 150 亿参数的音视频同出大模型。该模型采用单流 Transformer 架构,将文本、视频与音频进行统一联合建模,彻底告别了复杂的跨注意力分支。
第二天:分布式 Attention 组件
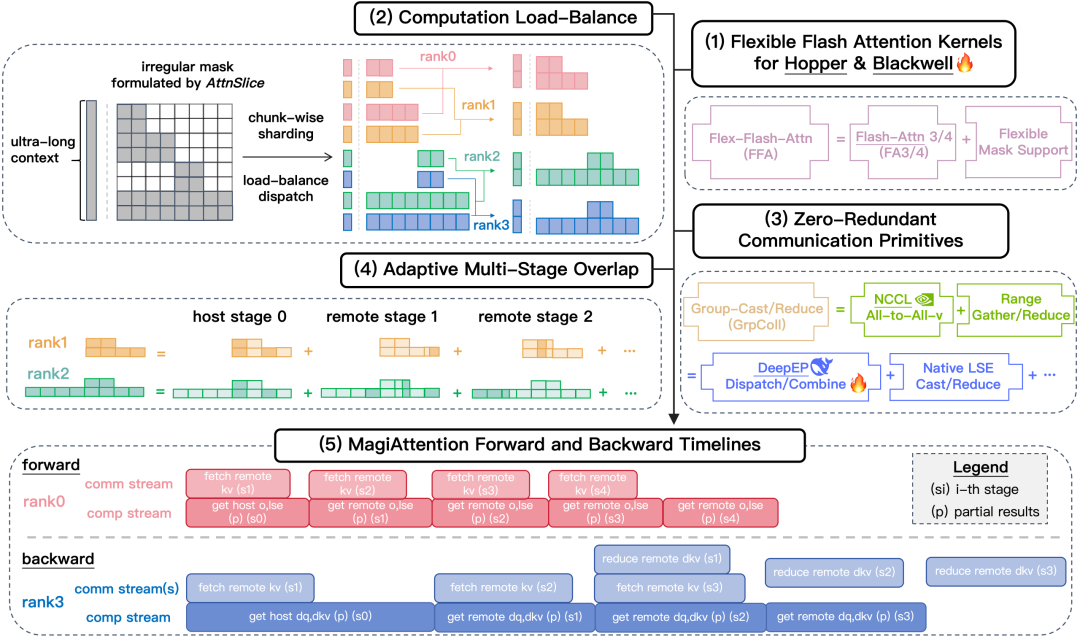
为了支撑超大模型的训练与极速生成,团队发布了深度适配 Hopper 与 Blackwell 架构的算力组件。它通过构建原生的 Group Collective 通信内核(以 NVLink 替代冗余的 RDMA 传输)来大幅降低跨机通信量,并引入 Dispatch Solver 实现全局负载均衡。
第三天:训推一体全局编译框架
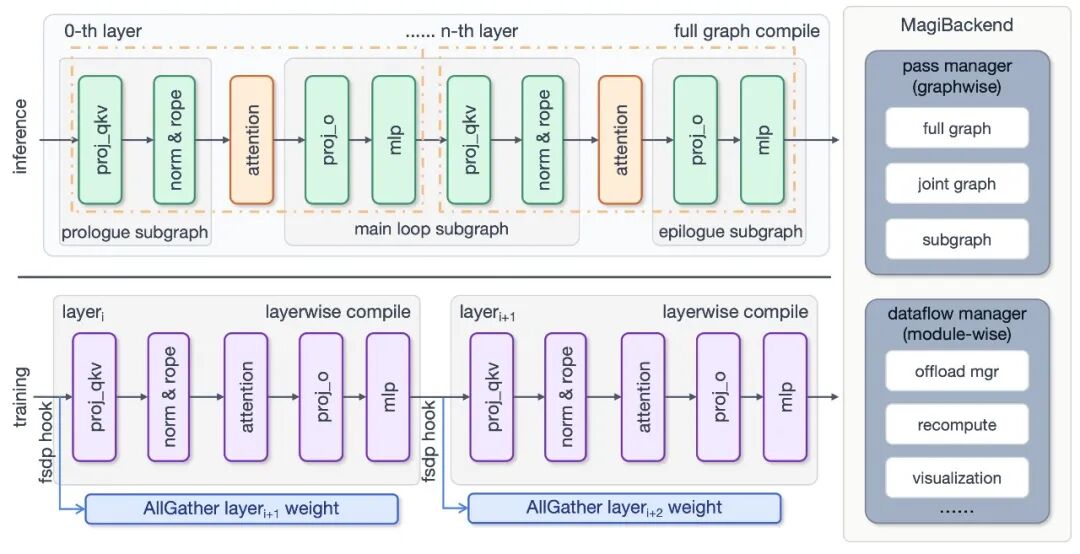
针对大模型开发中 “速度与显存难以兼得” 的技术矛盾,Sand.ai 释出了基于 torch.compile 深度优化的即插即用编译框架。它通过整图 / 整层编译、启发式自动重计算以及 JIT Offload 调度,全面接管了计算调度与显存生命周期。实测显示,在推理端甚至能让 RTX 5090 以近乎实时的速度运行超大视频模型。
团队介绍:“少数派” 的技术信仰
Sand.ai 成立于 2024 年,创始人是曹越博士。熟悉计算机视觉(CV)发展史的朋友对他绝对不陌生:在微软亚洲研究院(MSRA)期间,曹越作为核心作者发表的《Swin Transformer》一举拿下了 ICCV 最佳论文奖(马尔奖),目前其 Google Scholar 引用量已逼近 6 万次。联合创始人张拯同样是该论文的核心作者。

这是一支具有极强科研与工程背景的团队。成立不久,Sand.ai 便完成了由源码、今日、经纬等领投的多轮融资。有了充足的资金支持,Sand.ai 并没有选择直接跟随行业主流的 Sora 路线。当大部分团队都在追捧 DiT(Diffusion Transformer)架构时,他们坚信:通过自回归(Autoregressive)预测视频块序列来生成视频的世界模型,才是更接近物理世界第一性原理、且具备更强 Scaling 能力的终局。据悉,近期 Sand.ai 又快速完成了一轮数千万美金融资。
目前,Sand.ai 旗下主要布局了两款核心模型,分别针对影像创作周期中的不同核心诉求:
Magi-1:近期,实时生成的 “自回归世界模型” 正成为全行业追捧的热门方向,但 Sand.ai 早在近一年前,便发布了全球首个自回归视频生成大模型 Magi-1。它彻底告别了传统 AI 视频的 “慢动作” 与死板感,实现了极具爆发力的流畅动作、无限长度续写,以及精细到 1 秒的时间控制。

GAGA-1:国内首个推出的音画同出生成模型,主打 “AI 演员” 级别的极致表现力。解决了行业内最头痛的 “人物不一致” 和 “表情太假” 问题,在物理规则连贯性和原生音画同步上屡破纪录。
在深耕底层架构与开源基建的同时,Sand.ai 展现出的另一层核心壁垒,是其将前沿技术转化为实际应用的产品化能力。
据了解,Sand.ai 中较为低调的小团队还推出了一款 Video Agent,主要面向海外市场。据市场反馈,该产品目前在海外大受好评,主要体现在一键直出视频创作流程的智能化水平方面,海外商业化增长势头强劲,值得行业持续关注。
结语:Advance AI to Benefit Everyone
当 Sora 2 按下暂停键,AI 视频的故事并没有结束。Sand.ai 连续三天的开源不仅展示了其在模型、算力和编译框架上的全栈技术实力,更向我们展示了一家顶级 AI 公司应有的姿态:既有仰望星空的技术信仰,又有脚踏实地的底层死磕,更有拥抱世界、造福开发者的开源胸怀。
正如 Sand.ai 致力于将前沿技术转化为触手可及的生产力工具,将 “AI 演员” 和 “通用视频生成” 变为现实。这种对底层的坚守与对应用的探索,正是实现 “Advance AI to Benefit Everyone” 这一宏大愿景的必经之路。
技术的突破从来不是一蹴而就的。在这条布满荆棘但充满希望的道路上,我们有理由相信,像 Sand.ai 这样拥有清晰技术信仰、兼具科研与工程能力的 “少数派” 团队,正悄然改变着视听生成的未来。我们也期待,有更多拥有相同信仰、渴望在 AI 浪潮中留下扎实脚印的人才,能与他们并肩前行,共同推动 AI 技术的普惠发展。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com