AI检测器频频误判,人类作品也被识别为AI生成?专家45年前论文、经典文学都未能幸免!是技术缺陷还是另有隐情?
原文标题:糟糕,大佬45年前论文,被判AI生成
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到,AI检测器可能因为“写作水平越高(词汇更丰富、语法更规范),反而越容易被检测工具判定为AI写的”。如果是真的,这背后反映了什么问题?我们应该如何看待这种现象?
3、文章作者认为,AI检测器的问题在于“用人类创作的数据训练出来的,却反过来用来质疑人类的智能与原创性”。你认为除了这个原因,还有哪些因素导致AI检测器如此不靠谱?
原文内容
这是 AI 的时代,也是 AI 检测器的时代。
近段时间,随着 AI 生成的内容(AIGC)越来越多,其中还有不少试图假冒真实内容,AI 内容检测也正成为一种越来越迫切的需求,尤其是在注重实证、真实性至关的重要的论文写作上。
然而,这些 AI 内容检测器的表现究竟如何呢?
可能远远不及预期。
前两天,知名畅销书作家 Adam Kay 在社交媒体 X 分享了自己的经历:他心血来潮,把自己的作品丢进一款 AI 检测器里查重,结果系统信誓旦旦地判定其中有 29.7% 的内容由机器生成。
最尴尬的地方在于,这本书早在近十年前就已出版,当时的 AI 技术连他书中的一句长难句都读不明白。
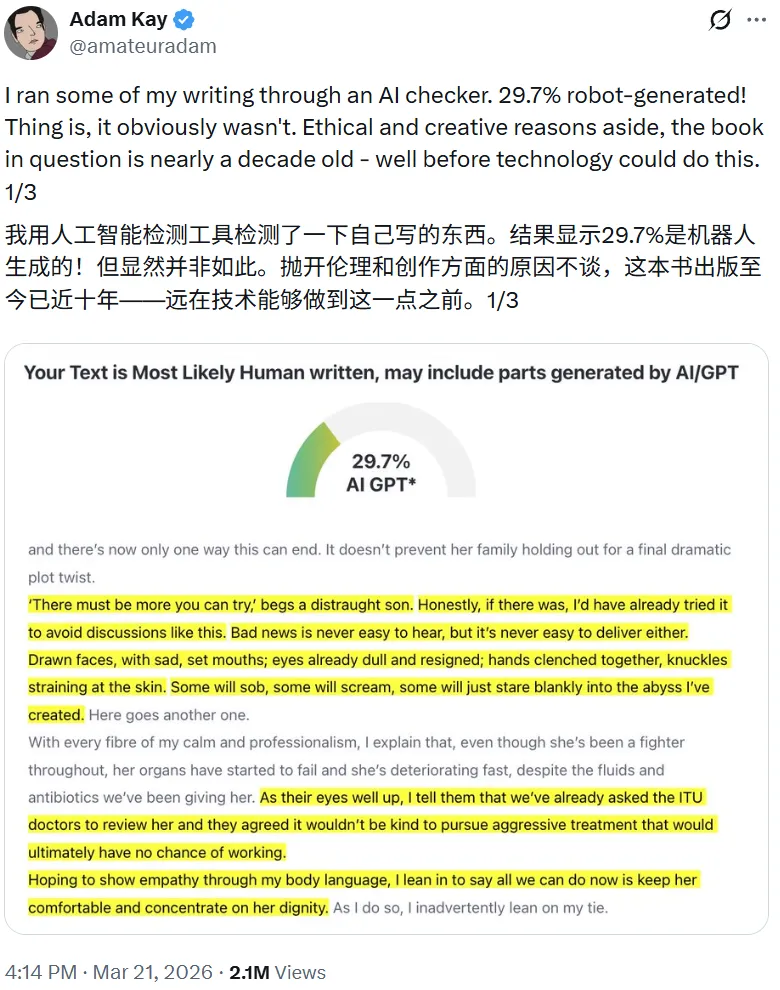
这条吐槽帖迅速引爆网络,目前浏览量已突破 210 万次,同时也激起了全网一场浩浩荡荡的「测谎仪大挑战」。越来越多的人拿着绝对不可能由 AI 生成的文本去测试,得到的结果无一不令人啼笑皆非。
学术界可谓是这场误判的重灾区。比如爱丁堡大学全球公共卫生教授兼主任 Devi Sridhar 教授的以前的文章就被检测判定有 90% 的内容都是 AI 生成的。

阿伯丁罗伯特戈登大学公共政策系的荣誉退休教授 Paul Spicker 45 年的一篇论文也被判定有 77% 的内容是 AI 生成的。
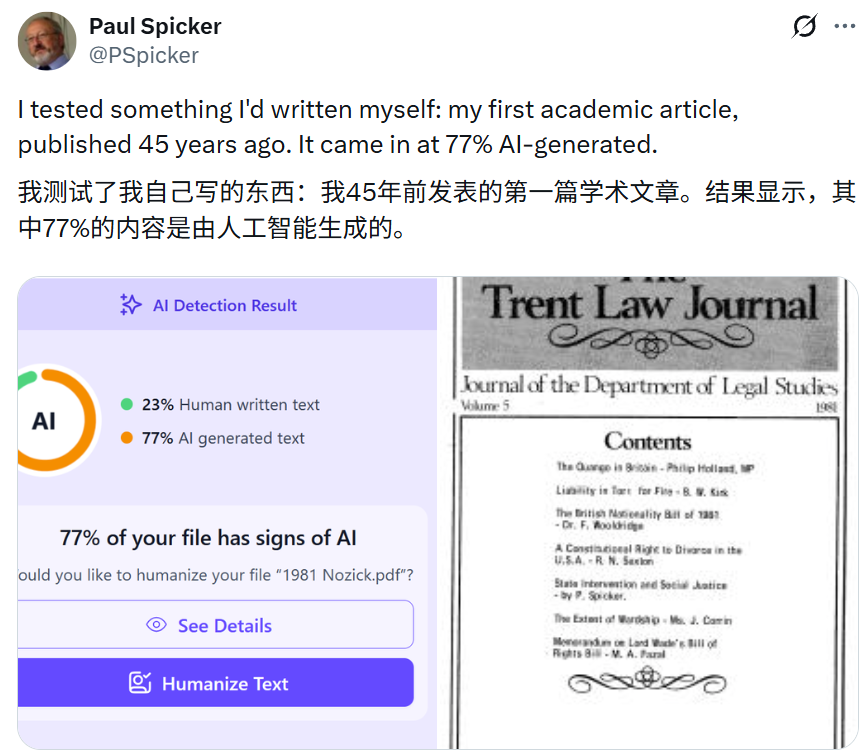
也有更多网友分享了自己的检测结果。比如网友 decentricity 用自己 2008 年的一篇关于 AI 的论文进行了检测,最终荣获 100% 纯 AI 生成的错误认证。这位网友调侃说自己用的是「GPT 负 6」。

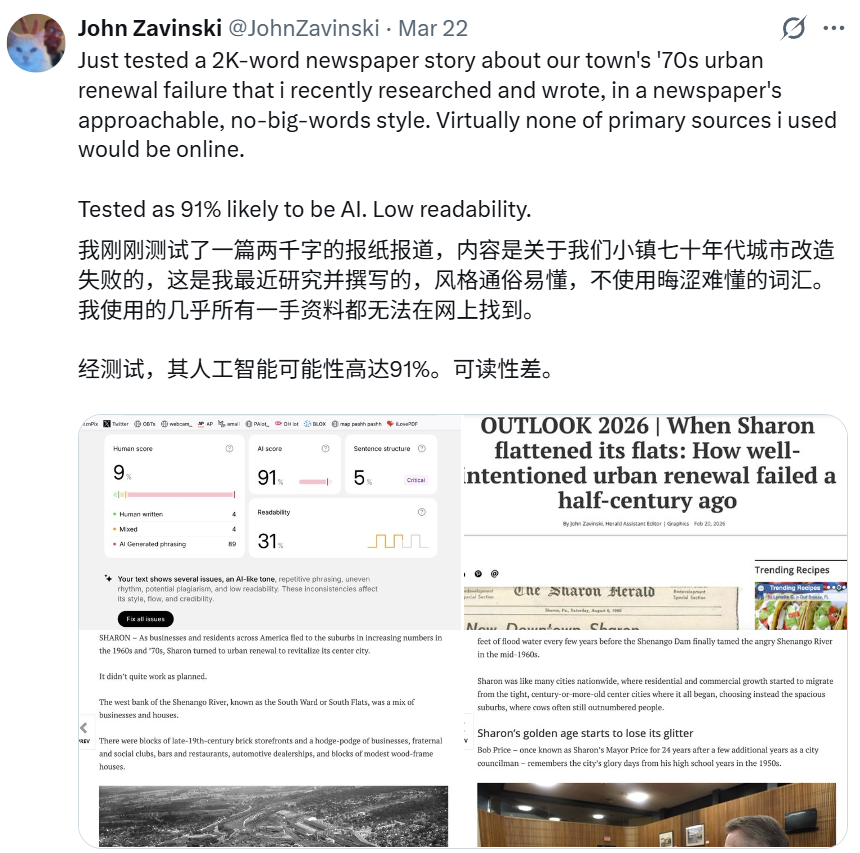
不仅学术圈,就连新闻报道也会被错误检测。比如在下面的例子中,Zavinski 测试了自己刚刚撰写的一篇 2000 字的报纸报道,复盘了当地小镇七十年代城市改造失败的历史。他特意使用了通俗易懂的平实文风,并且一手资料完全没有在互联网上公开过。即便如此,系统依然判定这篇报道有 91% 的可能性是 AI 写的,顺便还给出了「可读性差」的扎心评价。
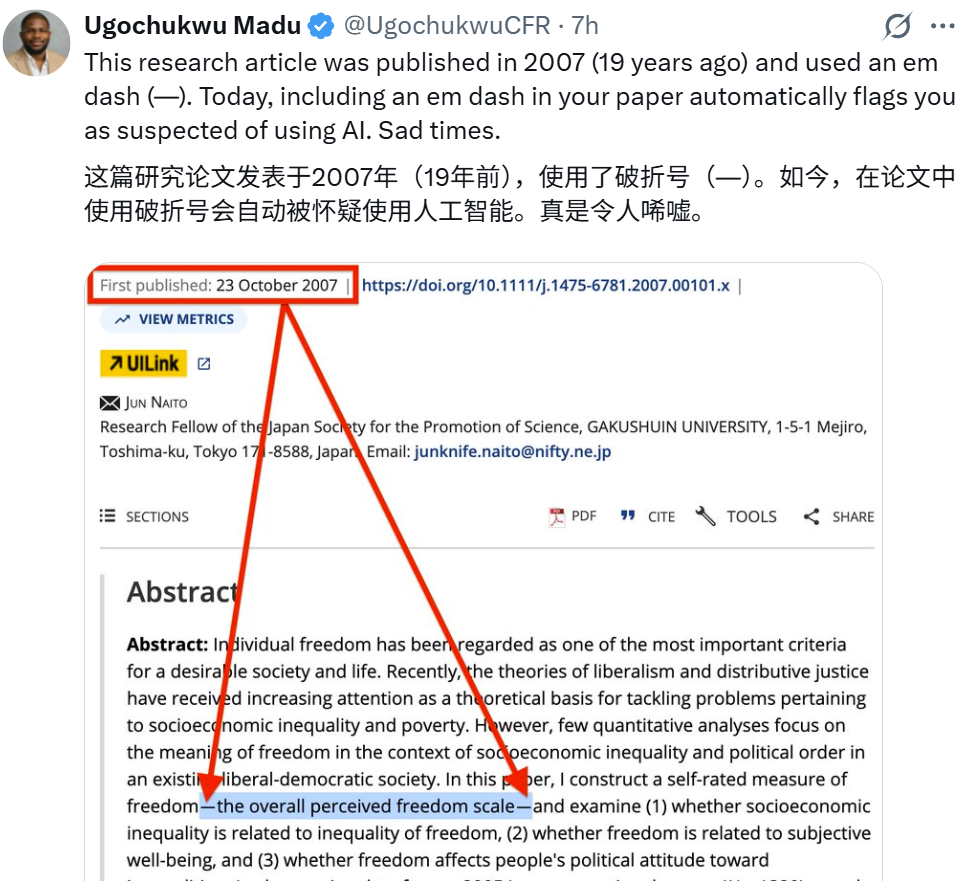
至于破折号识别法,更是几乎已经普及,也迫使相当多的人类作者改变自己的写作习惯。
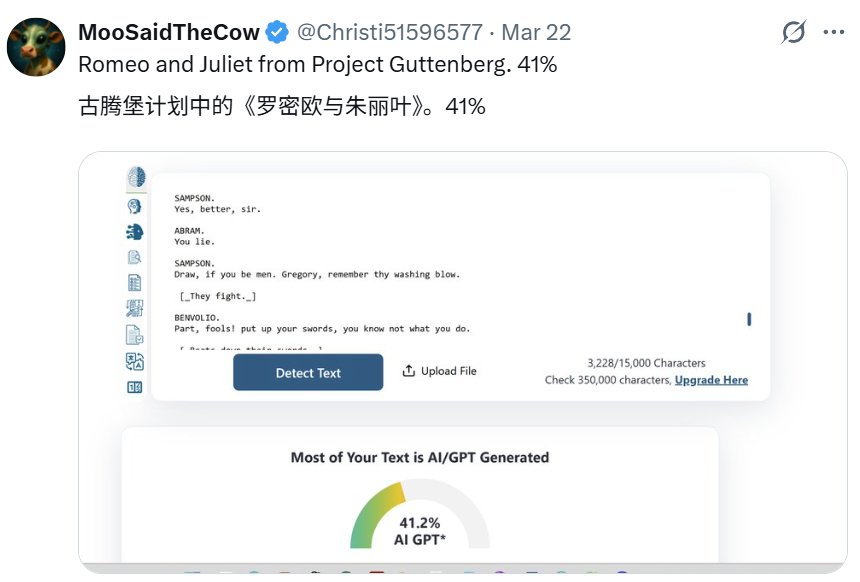
还有更离谱的,就连经典的《罗密欧与朱丽叶》原著也被认为有 41% 的内容是 AI 生成的:
就连《独立宣言》也未能幸免,AI 检测器认为有 99.99% 的内容来自 AI:

为什么 AI 检测器会给出如此让人大跌眼镜的结果?
作家 Adam Kay 给出了自己的见解,如今大量人类创作内容被 AI 公司用于模型训练,因此,当大模型判断某些段落像 AI 风格时,本质上并不是人在模仿 AI,而是 AI 在复现它曾经学习过的人类表达。
所以,在不久的将来,当出版商像教育机构一样,在印刷前把所有内容都拿去跑一遍 AI 检测时,那些被拿去训练的成千上万作者的作品,会不会反而被标记为 AI 生成?这正是当下这种局面带来的一个相当荒诞的副作用。

更是有网友指出,写作水平越高(词汇更丰富、语法更规范),反而越容易被检测工具判定为 AI 写的。

「AI 检测器简直就是个笑话。它们是用人类创作的数据训练出来的,却反过来用来质疑人类的智能与原创性。仅凭这一点就把某人的作品标记为 AI 生成,既不可靠,也不公平,而且在逻辑上站不住脚。」
这样的质疑并非个例。

这位网友表示「这些东西本质上都是胡扯,先用人类的集体知识去训练 AI,然后又用同一个 AI 来判断一段内容是不是由 AI 生成的,而这个判断本来就建立在它最初训练所依赖的人类智能之上。说到底,这真的是一种相当荒诞的逻辑。」

AI 写的内容,本来就来自人类,我们还怎么识别 AI?像不像 AI 这件事本身,或许就已经失去了明确的边界。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com