HIPPO框架通过语义感知剪枝和并行推测解码,实现视频大模型最高3.51倍推理加速,同时保持精度,为实时视频AI应用落地扫清障碍。
原文标题:论文速递|HIPPO:视频大模型推理加速框架,最高提速3.51倍
原文作者:机器学习算法与Python学习
冷月清谈:
怜星夜思:
2、HIPPO框架中“视频并行推测解码”是如何实现GPU算力零闲置的?这种并行策略在其他类型的AI模型推理中是否适用?
3、HIPPO框架在实验中表现出了良好的通用性,可以适配多种架构的视频大模型。你认为HIPPO框架未来在哪些实际应用场景中最有潜力?
原文内容
在多模态AI全面落地的当下,视频大语言模型(Video-LLMs)凭借跨视觉与语言的理解能力,成为视频问答、智能分析、内容生成等场景的核心技术。但海量时空数据带来的推理延迟、算力过载问题,始终制约着实时交互落地。
本文聚焦中科大、上海AI实验室、清华联合发布的HIPPO推理加速框架,按照标准论文解读结构拆解核心内容,从背景、相关工作到创新设计、实验数据,全方位剖析这项技术如何打破“速度与精度不可兼得”的行业困局。
📌 全文核心总结
HIPPO(全称Holistic-aware Parallel Speculative Decoding,整体感知并行推测解码)是一款专为视频大语言模型设计的推理加速框架,聚焦解决视频大模型Token冗余、推理串行低效、精度流失三大痛点。
框架通过语义感知Token保留实现精准剪枝,搭配并行推测解码压缩推理时延,在四大主流视频大模型、六大基准测试中,实现最高3.51倍推理加速,且能最大限度保留输出精度,不牺牲语义理解效果;同时具备强通用性,无需改动模型底层即可适配各类Video-LLMs,大幅降低实时视频AI落地门槛。
📄 论文基础信息
|
论文标题:HIPPO: Accelerating Video Large Language Models Inference via Holistic-aware Parallel Speculative Decoding 核心发布机构:中国科学技术大学、上海AI实验室、清华大学电子工程系 研究领域:多模态大模型、视频大语言模型、AI推理加速 核心成果:视频大模型最高3.51倍推理加速,兼顾精度与效率,适配多架构大模型 |
🌍 研究背景与行业痛点
随着视频内容爆发式增长,视频大语言模型的应用场景不断拓宽,但视频数据的时空密集性,让推理环节面临难以突破的瓶颈,也是本次研究的核心出发点。
1. 数据层面:Token海量过载,算力消耗激增
视频是连续帧组成的时空数据,以常规1080P、60帧/秒的高清视频为例,短短几分钟编码后就能产生上百万个视觉Token。传统自回归逐一生成Token的模式,导致算力开销呈指数级增长,单帧推理延迟动辄超1秒,完全无法满足实时交互需求。
2. 落地层面:实时性与精度难以兼顾
行业内为缓解算力压力,普遍采用Token剪枝、推理优化等手段,但要么加速效果微乎其微,要么误剪关键语义Token,导致模型理解偏差、输出失真;想实现视频AI实时响应,只能盲目堆高配显卡,落地成本居高不下。
3. 技术缺口:缺乏高效通用的加速方案
现有视频大模型推理优化方案,大多针对单一模型或特定场景设计,通用性差;且未解决Token剪枝偏见、推测解码串行低效等核心问题,难以实现规模化落地。
🔍 相关工作与现有技术缺陷
在HIPPO之前,学界和工业界已有两类主流视频大模型推理优化方案,但均存在明显短板,这也是HIPPO的创新突破方向。
1. 注意力剪枝技术
这是最常用的Token精简方案,通过注意力分数筛选保留Token,但存在严重位置偏见:画面边缘的静止背景(墙壁、天空等)因靠近查询位置易被保留,而人物面部、关键动作等核心语义Token反而被剪掉,高剪枝率下模型准确率大幅下滑,属于“盲目减负”。
2. 传统推测解码技术
通过轻量草稿模型先生成候选Token,再由大模型验证,理论上可提速,但视频场景下草稿模型与目标模型串行执行,草稿模型的推理开销直接抵消加速效果;即便大幅剪枝,草稿模型仍需处理海量数据,效率存在明显天花板。
综上,现有相关工作要么牺牲精度换速度,要么速度提升有限,亟需一套兼顾语义保留、并行提速、通用适配的全新方案。
💡 HIPPO核心创新设计
HIPPO框架针对性破解现有技术痛点,核心围绕“精准减冗余+并行提效率”两大目标,打造两大独创技术模块,实现协同增效。
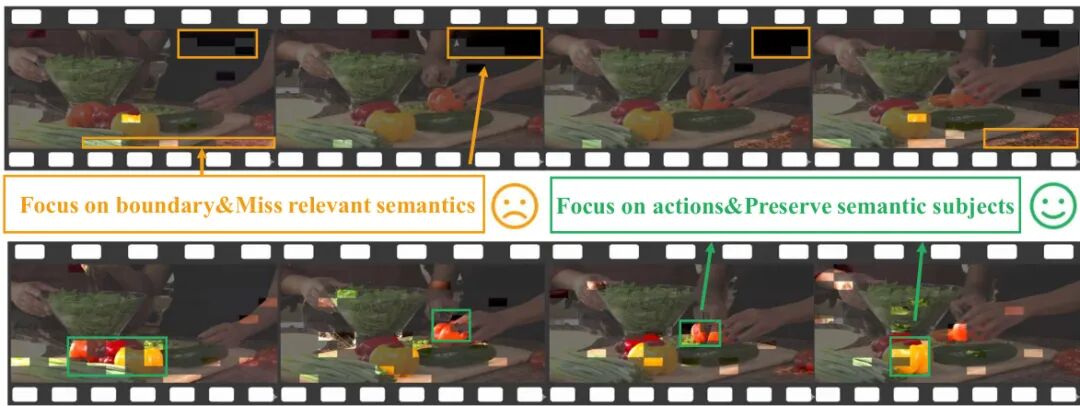
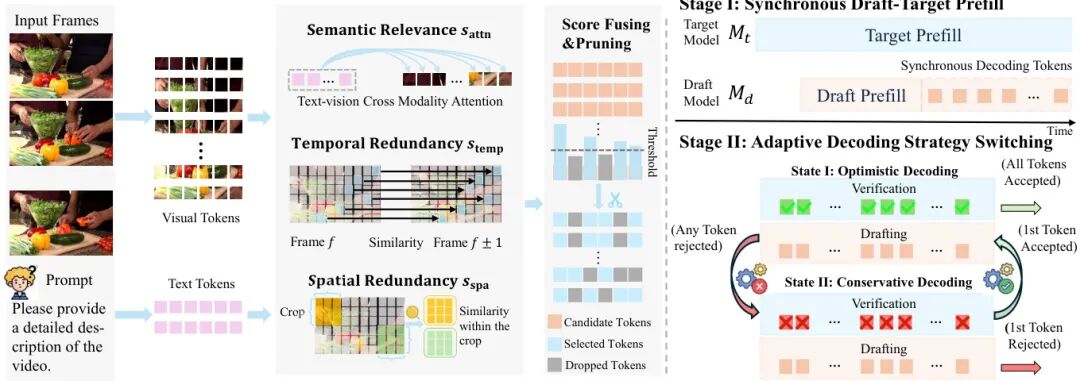
模块一:语义感知标记保留(精准剪枝)
抛弃单一注意力评分逻辑,搭建三维价值评分体系,从全局、时间、空间维度精准评估Token语义价值,只保留关键信息、删除冗余数据,从源头降低算力负荷。
-
全局语义相关性评分:计算视觉Token与文本查询的跨模态注意力权重,优先保留和用户需求、视频核心内容强相关的Token,杜绝无关信息抢占算力
-
帧间时间冗余评分:对比相邻帧Token相似度,动态内容(动作、场景变化)重点保留,静态背景直接标记为冗余删减,动态场景Token保留率提升37%
-
帧内空间冗余评分:识别画面复杂度,高方差区域(面部、细节纹理)保留,纯色均匀背景精简,彻底解决位置偏见问题
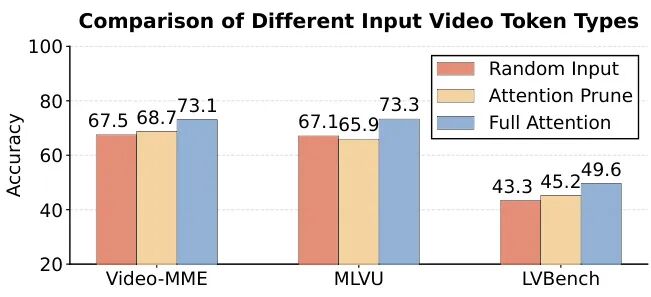
该模块可实现90%剪枝率的同时,保住89.2%的关键语义Token,远优于传统剪枝的71.3%保留率。
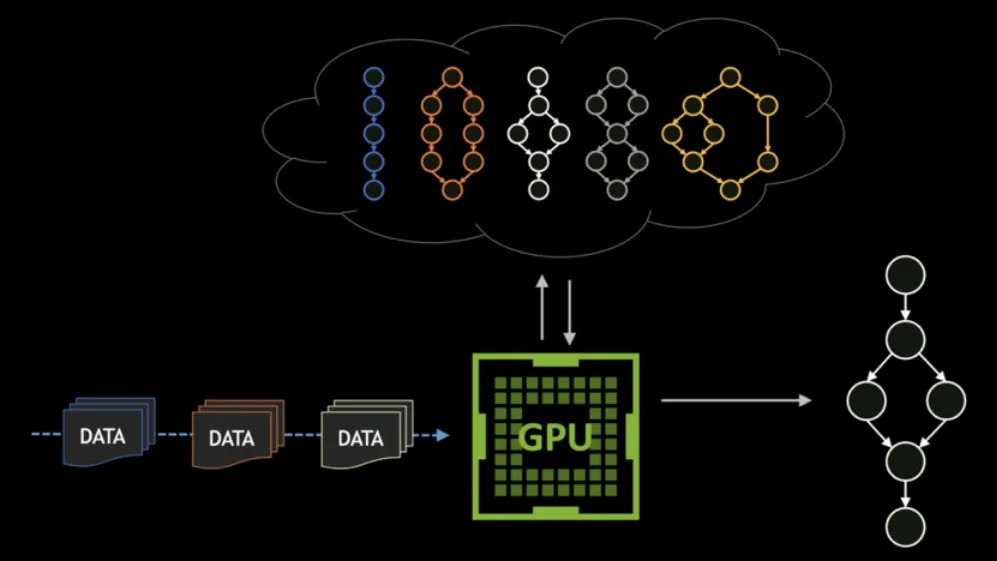
模块二:视频并行推测解码(提速核心)
打破传统串行解码逻辑,将草稿模型生成与目标模型验证解耦+重叠执行,充分利用GPU算力空档,隐藏推理开销、压缩端到端延迟。
-
同步草稿-目标预填充:利用目标模型视觉编码的延迟间隙,草稿模型同步生成候选Token缓冲区,提前储备待验证内容,实现算力零闲置
-
自适应解码策略切换:流畅场景启用乐观模式,草稿生成与目标验证并行,计算重叠率高达82.4%;场景突变启用保守模式,暂停无效计算,减少67.3%的冗余开销
该模块让GPU利用率从45%飙升至79%,端到端推理延迟直接降低41.7%。
📊 实验数据与结果验证
研究团队在NVIDIA H200 GPU平台开展严格对照实验,覆盖四大主流视频大模型、六大行业基准,验证HIPPO的加速效果与通用性。
1. 实验配置
-
测试模型:video-SALMONN2+、Qwen2.5-VL、LLaVA-OneVision、Qwen3-VL(7B-72B全参数量覆盖)
-
测试基准:Video-MME、MLVU(视频问答)、LVBench、LongVideoBench(视频描述)等六大权威数据集
-
对比方案:传统注意力剪枝、经典推测解码、同类视频推理加速框架
2. 核心实验结果
-
加速效果:最高加速3.51倍(Qwen3-VL),最低加速3.17倍,长视频、复杂场景优势更突出
-
精度表现:剪枝+提速后,模型问答准确率、描述契合度仅下降0.3%-0.8%,几乎无精度损耗
-
通用性:卷积、Transformer、混合架构模型均可适配,无需修改模型底层,集成成本极低
-
消融实验:移除任一核心模块,加速比下滑27%以上,证明两大创新模块缺一不可、协同增效
✍️ 总结
HIPPO框架通过语义感知剪枝解决Token冗余问题,依靠并行推测解码提升推理效率,用极低的精度损耗换取数倍加速效果,兼具创新性与实用性。这项研究不仅攻克了视频大模型实时推理的行业难题,更为多模态大模型推理优化提供了全新思路,后续随着框架迭代优化,有望推动实时视频AI走进更多生活与生产场景。