清华&无问芯穹发布WideSeek-R1多智能体系统,探索AI“广度扩展”,4B模型性能比肩671B模型,为信息搜索带来新思路。
原文标题:不止Deep,更要Wide:清华、无问芯穹发布多智能体系统WideSeek-R1,4B模型比肩671B模型!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、WideSeek-R1采用MARL进行端到端训练,解决了多智能体协作中的哪些难题?这种训练方式对多智能体系统的性能提升有多大帮助?未来MARL在多智能体系统中的应用前景如何?
3、WideSeek-R1的数据构建流水线如何弥补开源社区在广度信息搜索任务上的空白?这种自动化数据构建方式有哪些优势和挑战?未来我们应该如何构建更有效、更通用的训练数据?
原文内容

DeepSeek-R1 的成功证明了「深度扩展(Depth Scaling)」在解决复杂逻辑推理上的巨大潜力。AI 社区开始思考另一个维度的可能性:当任务不仅需要深度的推理,更需要极宽广度的信息搜集时,单一的大模型还是最优解吗?
设想这样一个场景:你需要整理 “2025 年全球前 50 大科技公司的营收、净利润及研发投入对比表”。这是一个典型的广度信息搜索任务。对于单个大模型而言,哪怕它是拥有 671B 参数的超大模型,面对这种需要数十次检索,往往会陷入上下文信息干扰和串行效率低的问题,而显得力不从心。
近日,来自清华大学与无问芯穹的 RLinf 团队提出了一种全新的互补维度 ——「广度扩展(Width Scaling)」,并以此发布了多智能体系统 WideSeek-R1 。不同于以往依赖人工设计工作流的多智能体系统,该工作采用了一种 「Lead-agent-Subagent」的分层多智能体框架 ,并通过多智能体强化学习(MARL)进行端到端训练,展现出灵活的规模化调度与高效的并发处理能力。
实验结果显示,4B 参数的 WideSeek-R1 在广度搜索任务上的表现达到了40%的 Item F1指标,不仅看齐 671B 参数的 DeepSeek-R1 单智能体,更大幅超越了同参数规模的基线模型。

-
论文标题:WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
-
论文链接:https://arxiv.org/abs/2602.04634
-
项目主页:https://wideseek-r1.github.io
-
代码文档:https://rlinf.readthedocs.io/en/latest/rst_source/examples/agentic/wideseek_r1/index.html
-
Hugging Face 模型和数据:https://huggingface.co/collections/RLinf/wideseek-r1
1. 只有「深度」还不够,
搜索需要「广度」
过去一年,大模型的进步主要集中在深度扩展上。像 OpenAI o1 或 DeepSeek-R1 这样的模型,通过增加推理步数来解决复杂难题。
然而,随着任务广度的增加,瓶颈从 “个体能力” 转移到了 “组织能力”。
在广度信息搜索任务中,单智能体面临两大痛点:
1. 上下文干扰: 随着检索信息的堆积,无关信息会干扰模型对后续子任务的判断。
2. 串行效率低: 依次处理数十个独立的子任务不仅慢,而且容易因序列过长而遗忘有用信息,导致任务失败。
对此,WideSeek-R1 给出的答案是:用多智能体系统 + MARL 实现广度扩展。
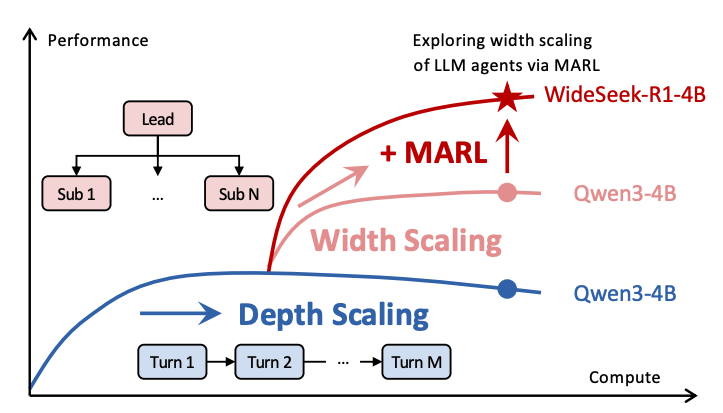
图1:深度扩展与广度扩展的对比
当传统的深度扩展(蓝色曲线)依赖单智能体多轮串行推理而逐渐遭遇性能瓶颈时,广度扩展(粉色曲线)通过增加智能体个数,通过多智能体并行执行开辟了新的增长路径;而我们提出的 WideSeek-R1(红色星号),通过多智能体强化学习(MARL)进一步实现了调度与执行的协同优化,证明了在广度信息搜索任务中,协同的 “宽度” 扩展能带来比 “深度” 更显著的性能飞跃。
2. WideSeek-R1:采用端到端 MARL
训练 “编排” 和 “执行” 能力
现有的多智能体系统大多依赖手动设计的工作流(Hand-crafted workflows)或简单的轮流对话,难以实现真正的并行高效协作。
WideSeek-R1 引入了一个「Lead-agent-Subagent」的层级框架,并用多智能体强化学习(MARL)端到端训练:
-
Lead-agent: 负责将一个宽泛的复杂问题分解为独立的子任务,可调度多个 Subagents 并行执行。同时也需要对 Subagent 返回的结果进行总结归纳,判断应该直接返回最终答案,还是进行下一回合的任务分解。
-
Subagent: 在隔离的上下文中并行工作,利用搜索和浏览等工具获取特定信息。
为了训练这个系统,研究团队在 GRPO 算法基础上,针对多智能体、多回合场景进行了两项关键改进:
-
多智能体优势分配(Multi-Agent Advantage Assignment): 多智能体协作中,最大的难题是 “功劳归谁”。WideSeek-R1 将同一个样本的最终奖励共享给所有参与的 Agent,确立 “荣辱与共” 的协作目标,避免复杂的信用分配导致的 Reward Hacking 。
-
优势双重加权归一(Dual-Level Advantage Reweighting):
-
Token 级加权归一: 类似于 DAPO,确保长思维链的 Turn 在某一智能体里获得足够高的权重;
-
Agent 级加权归一: 确保增加 Agent 数量是为了真正提高质量,而非仅仅为了 “凑人头”。
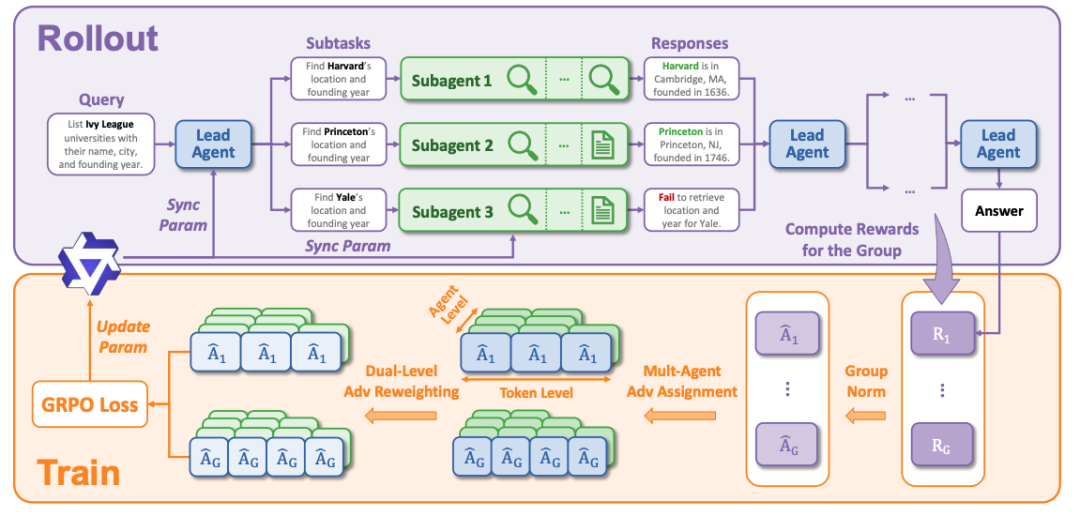
图2:WideSeek-R1 推理与训练流程概述
3. 构造广度信息搜索任务训练数据:
弥补开源社区领域空白
当前开源数据集通常关注深度搜索任务,尽管已有一些广度搜索训练集,但是数据量较小,无法满足大规模 RL 训练。研究团队填补了社区空白,开发了一套全自动的数据构建流水线,基于 HybridQA 数据集,合成了 20,000 条高质量的广度信息搜索任务。
这一流水线包含三个阶段 :
1. 问题生成: 提取用户意图并转化为具有特定约束的广度信息搜索问题;
2. 答案生成: 利用 Gemini-3-Pro 独立生成两个答案及唯一标识列;
3. QA 对过滤: 通过对两个答案的一致性校验和难度过滤,得到最终高质量数据集。
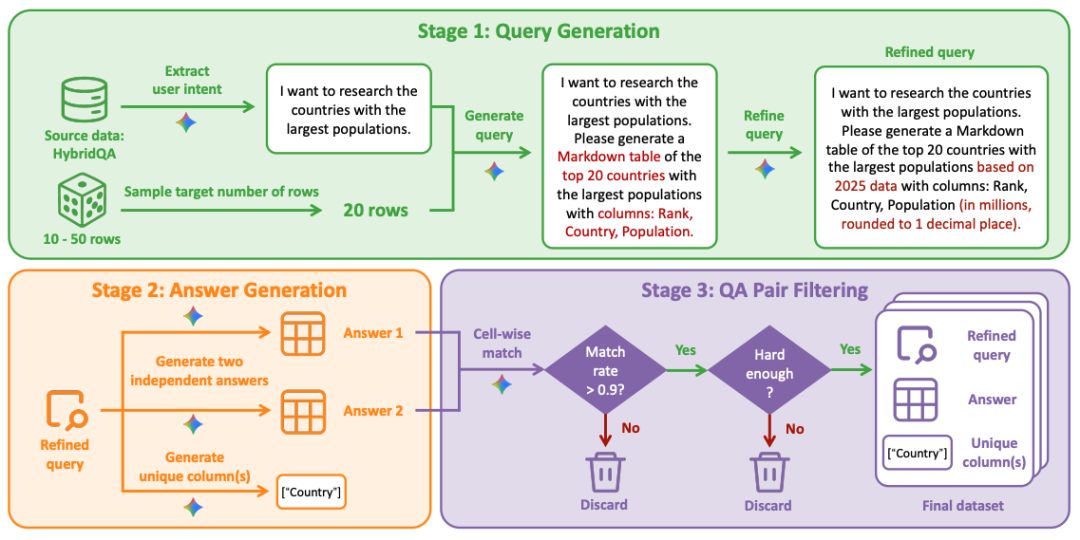
图3: 三阶段自动化数据构建流程概述
4. 实验结果
(1) 多智能体 4B 模型在 WideSearch 上追平单智能体 671B 模型
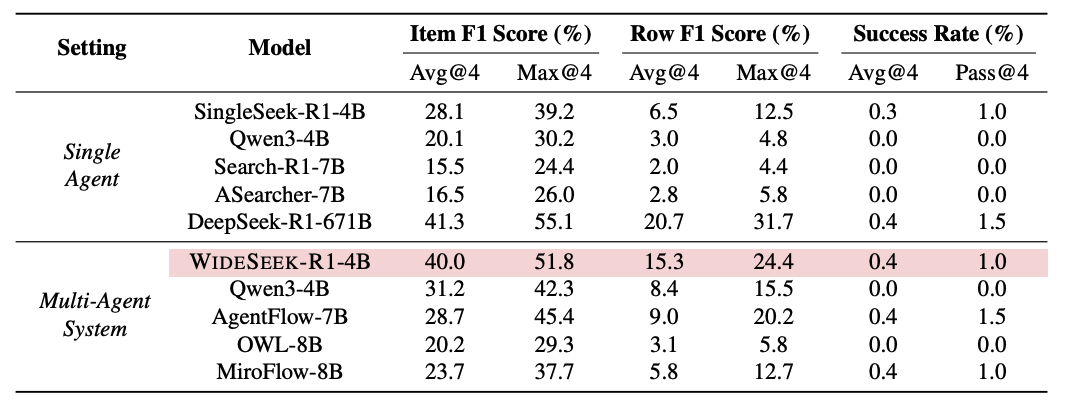
表1: WideSearch 主实验结果
研究团队在公开的广度信息搜索测评任务 WideSearch 上,对现有单智能体、多智能体 baseline 进行测试,实验数据显示,WideSeek-R1-4B 取得了 40.0% 的 Item F1 分数:
-
相比未训练的 Qwen3-4B 多智能体基线提升了 8.8% 。
-
相比同参数的单智能体版本 SingleSeek-R1-4B 提升了 11.9% 。
-
最重要的是,这一成绩与单智能体 DeepSeek-R1-671B 几乎持平,而参数量仅为后者的 1/170 。
(2) 验证「广度扩展」定律
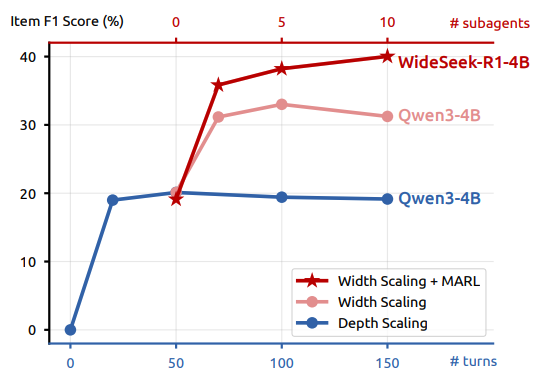
图4: 面向测试时计算资源的深度与广度扩展性能对比
文章最核心的发现之一在于 Scaling 行为的对比:
-
深度扩展(Depth Scaling): 随着推理步数增加,单智能体性能很快饱和,甚至因上下文过长而下降。
-
广度扩展(Width Scaling): 在单智能体性能饱和情况下,增加并行 Subagent 的数量(从 1 到 10)展现了持续的性能增长潜力。在此基础上,MARL 训练通过优化协作机制,进一步显著提升了系统的性能上限。
(3) 在标准 QA 上保持性能
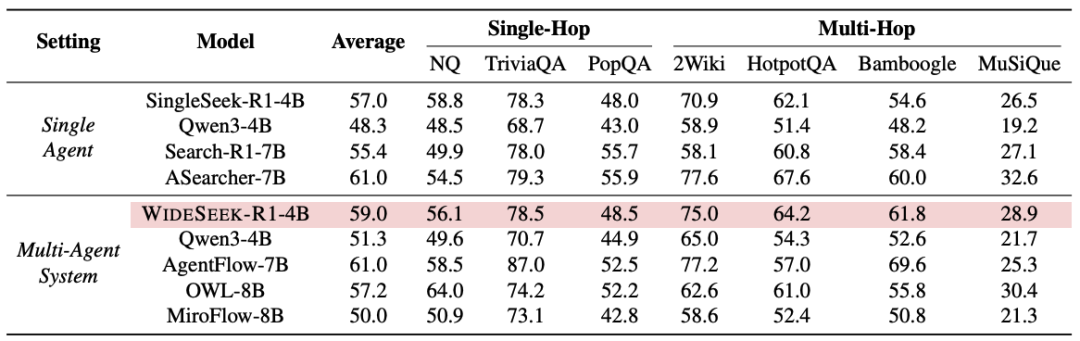
表2: 在传统单跳与多跳QA任务上的实验结果
在 NQ、HotpotQA 等 7 个标准问答数据集上,WideSeek-R1-4B 同样表现出色,平均分达到 59.0%,优于部分 7B/8B 的多智能体基线(如 AgentFlow, OWL 等),证明了模型并未因专注于广度搜索而牺牲通用搜索能力。
(4) 消融实验
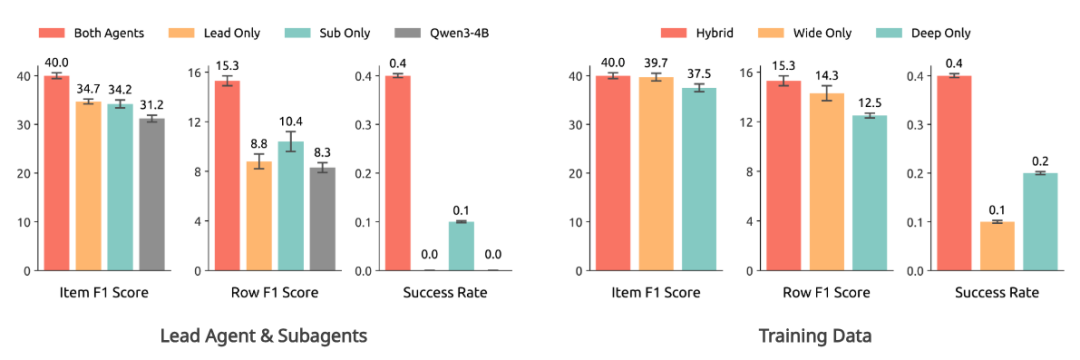
图5: 智能体模型的消融实验(左图),训练数据的消融实验(右图)
左图:我们发现只有当 Lead-agent 和 Subagent 同时使用 WideSeek-R1-4B 时才能达到最佳性能,这验证了端到端多智能体强化学习训练的重要性。
右图:在相同数据集规模的前提下,在混合数据集(广度 + 深度)上训练的模型表现始终优于仅在单一类型数据集上训练的模型,表明广度数据与深度数据提供了互补的增益。
5. 算法背后的工程哲学:
RLinf 的关键支撑
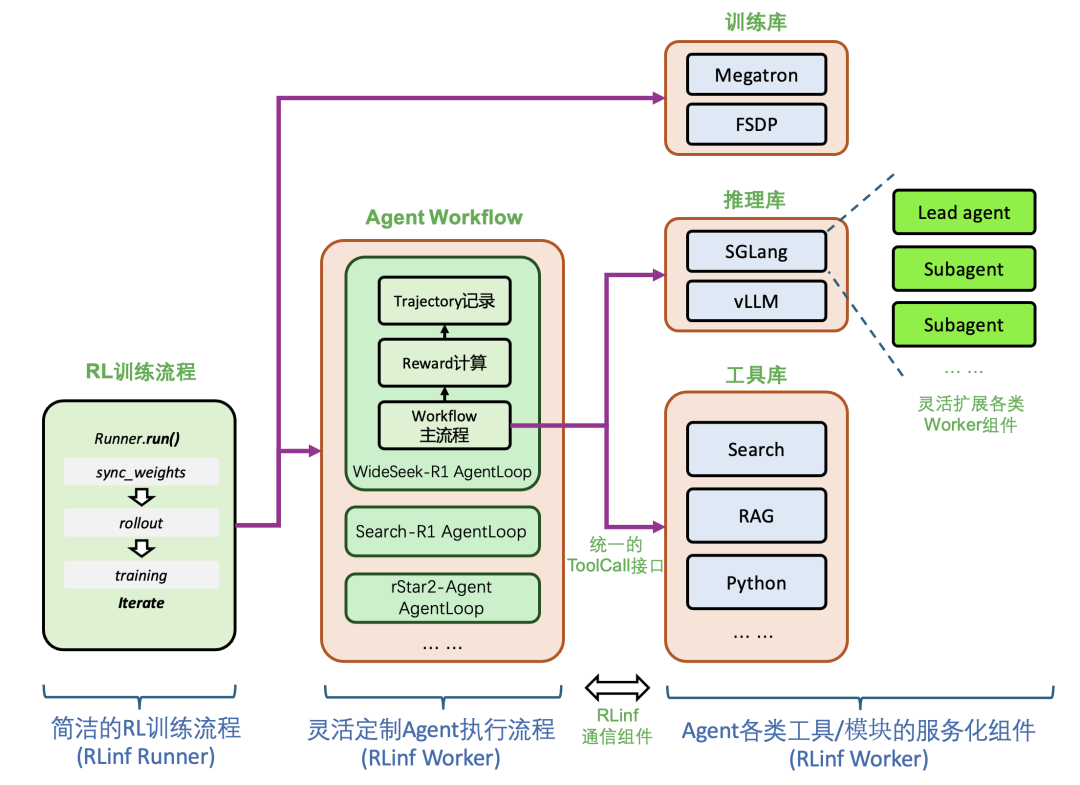
图6: RLinf 多智能体强化学习训练架构图
WideSeek-R1 传达的核心结论是:在广度信息搜索场景里, Width Scaling + MARL 确实能带来进一步收益。这一结论除了需要“算法层面”的创新,更需要“系统层面”的强力支撑。例如:多智能体的调度、多工具的统一接入与管理、多会话的调度与隔离、动态会话与长尾问题的缓解,以及训练与推理间的高效切换与资源分配等。
为应对上述系统挑战,团队将自研单智能体强化学习框架 RLinf 进一步扩展至多智能体强化学习场景。系统结构如图6所示,包含三个粒度:MARL 逻辑流、 Agent 工作流、以及工具库、推理库、训练库等服务化组件。 MARL 逻辑流包含 Rollout 、训练与权重同步,由 RLinf Runner 实现。相较单智能体,多智能体强化学习的复杂逻辑主要体现在 Rollout 部分, RLinf 新增 AgentLoop 模块负责执行多智能体核心推理逻辑,即各智能体基于大模型进行交替的推理与工具调用。最细粒度的服务组件均继承自 RLinf Worker ,从而可以灵活调用 RLinf 提供的通信接口,极大降低了开发复杂度。在多智能体场景中,如 lead-agent 与多个 Subagent ,可通过多个 SGLang 实例进行推理,仅需简单配置即可拉起整套多组件交互流程。
在训练效率方面,框架引入了多项优化:
-
样本打包(Sample Packing):将不同长度的样本动态打包,使训练 token 更集中于有效计算,减少 padding 开销,提升 GPU 利用率;在长序列、多轮 Agent 轨迹训练中,可显著减少无效算力消耗并缩短单步时间。
-
多轮前缀合并(Multi-Turn Prefix Merging):针对 Agent 多轮生成中后一轮 prompt 包含前一轮 prompt 与响应的结构特点,RLinf 可合并可复用前缀,避免重复前向与反向计算,在多轮工具调用场景中尤为有效。
-
面向Session的亲和性请求分发:在通信层实现基于亲和性的请求分发,保障多会话的合理调度。
-
高效权重同步:支持训练并行配置到推理并行配置的就地转换,结合 NCCL / CUDAIPC 高带宽同步路径,降低频繁同步的开销,同时减少冗余权重拼接与中间态内存占用,缓解同步阶段的性能瓶颈与 OOM 风险。
-
组件自动扩缩容:支持各组件的自动扩缩容,有效应对动态性与长尾问题。
系统性能效果:WideSeek-R1通过广度拓展有效拓展信息获取的范围,而广度的拓展是通过更多的并行subagents完成的。从下图实验数据可见,通过高效的系统实现与并发优化,拓展一倍的subagents的数量并没有带来明显的eval时间的增加,充分说明系统在scaling上的有效性。
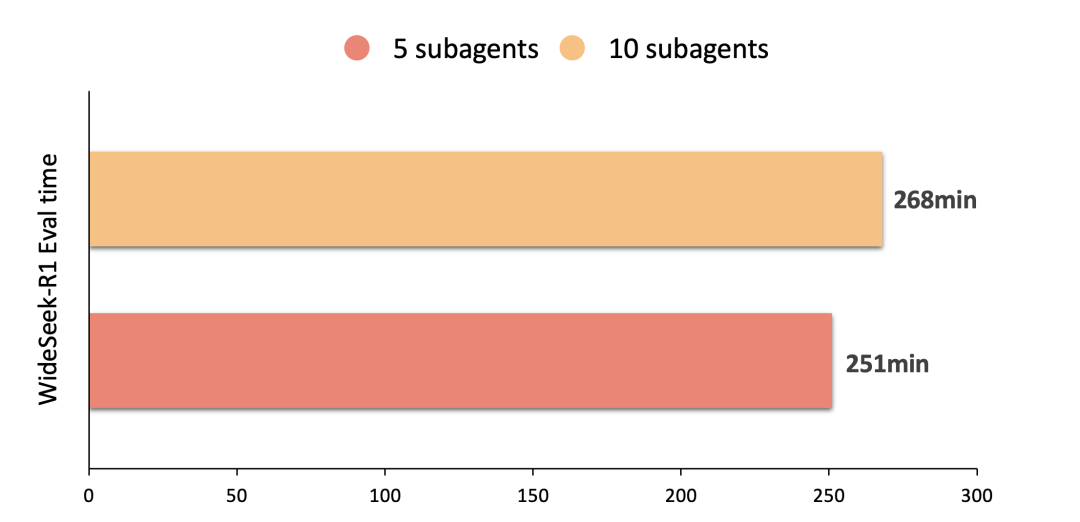
图7: Agent scaling性能对比
6. 结语
WideSeek-R1 表明搜索不仅要Deep,还要Wide,同时也表明新一代科研的形态需要“算法创新 + 系统支撑”双管齐下。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com